线性回归 Linear regression(2)线性回归梯度下降中学习率的讨论
这篇博客针对的AndrewNg在公开课中未讲到的,线性回归梯度下降的学习率进行讨论,并且结合例子讨论梯度下降初值的问题。
线性回归梯度下降中的学习率
上一篇博客中我们推导了线性回归,并且用梯度下降来求解线性回归中的参数。但是我们并没有考虑到学习率的问题。
我们还是沿用之前对于线性回归形象的理解:你站在山顶,环顾四周,寻找一个下山最快的方向走一小步,然后再次环顾四周寻找一个下山最快的方向走一小步,在多次迭代之后就会走到最低点。那么在这个理解中,学习率其实是什么呢?学习率就是你走的步子有多长。
所以太大的学习率可能会导致你一步跨的太大,直接跨过了我们想要的最小均值;太小的学习率又会造成你跨的步子太小,可能你走了好多步,其实离你目标点还有很大的距离。
学习率的调整是我们梯度下降算法的关键。
笔者在神经网络的相关书籍里看到,1996年Hayjin证明,只要学习率α满足下式,LMS算法就会收敛。(P.S.笔者暂时还没有阅读相关的论文所以只能暂时给出结论)
,其中
是输入向量x(n)组成的自相关矩阵R的最大特征值。由于
常常不可知,因此往往使用自相关矩阵R的迹(trace)表示。
,所以
,且tr(R)为各输入向量的均方值之和。
我们现在至少得到了学习率α的最大值,这个值能保证梯度下降收敛。
下面我自己写了一段程序分别用批量梯度下降,随机梯度下降对于学习率,梯度下降的初值进行了测试。
我利用了Mathematical Algorithms for Linear Regression, Academic Press, 1991, page 304,ISBN 0-12-656460-4.中的一组数据。
这组数据包括了30不同年龄的人的收缩压,每组数据包括4行
I, the index;
A0, 1,
A1, the age;
B, the systolic blood pressure.

其中x表示年龄,y表示对应的收缩压。
同时我们求得学习率
接下来我会对三种方法拟合出来的结果进行展示,其中:
红色的线表示批量梯度下降结果
绿色的线表示随机梯度下降结果
蓝色的线表示直接计算参数的结果
第一组测试数据是在初始值 学习率
的情况下,迭代10000次得到
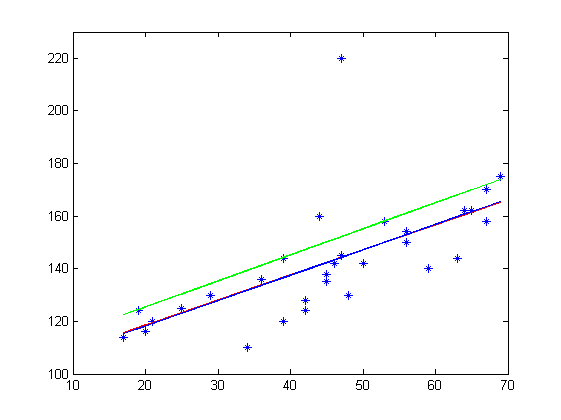
可以看出批量梯度下降,与直接得到参数基本吻合,可见批量梯度下降基本成功收敛到了mse的最小值,然而随机梯度下降的结果却不佳。
第二组测试数据是在初始值 学习率
的情况下,迭代10000次得到

可以看出此时批量梯度下降还未完全收敛,随机梯度下降基本完全收敛,而且与第一组测试数据得到的值差不多。
第二组测试数据是在初始值 学习率
的情况下,迭代10000次得到
这组测试数据由于学习率过大,θ不再收敛,而变得非常大了。
由此我们可以看到批量梯度下降与随机梯度下降优缺点。
批量梯度下降,优点:得到的参数非常准确,不太容易陷入局部最小值;
缺点:收敛速度慢
随机梯度下降,优点:收敛速度快
缺点:得到的参数不是非常准确,容易陷入局部最小值。
附代码(写matlab比较少,最后基本强行写成了c。。。)
%data
x(:,1)=1;
x(:,2)=a(:,1);
y=a(:,2);
b=figure;
set(b,'name','样本图像');
plot(x(:,2),y,'*');
axis([10,70,100,230]);
%求各输入向量的均方值之和。
mm=0;
for i=1:30
mm=x(i,1)^2+x(i,2)^2;
end
mm=2/(mm);
%批量梯度下降
mse=100;
m=0.1;
theta=[100,1];
alpha=0.0001;
times=0;
while mse>m && times<10000
times=times+1;
tot1=0;
tot2=0;
mse=0;
for i=1:30
tot1=tot1+(y(i)-(theta(1)*x(i,1)+theta(2)*x(i,2)))*x(i,1);
tot2=tot2+(y(i)-(theta(1)*x(i,1)+theta(2)*x(i,2)))*x(i,2);
mse=mse+(y(i)-(theta(1)*x(i,1)+theta(2)*x(i,2)))^2/2;
end
theta(1)=theta(1)+alpha*tot1/30*2;
theta(2)=theta(2)+alpha*tot2/30*2;
mse=mse/30;
end
hold on;
y=theta(1)+theta(2)*x;
plot(x,y,'Color',[1,0,0]);
%随机梯度下降
x(:,1)=1;
x(:,2)=a(:,1);
y=a(:,2);
mse=100;
m=0.1;
theta=[100,1];
alpha=0.0001;
times=0;
while mse>m && times<10000
times=times+1;
tot1=0;
tot2=0;
mse=0;
for i=1:30
tot1=0;
tot2=0;
tot1=tot1+(y(i)-(theta(1)*x(i,1)+theta(2)*x(i,2)))*x(i,1);
tot2=tot2+(y(i)-(theta(1)*x(i,1)+theta(2)*x(i,2)))*x(i,2);
theta(1)=theta(1)+alpha*tot1*2;
theta(2)=theta(2)+alpha*tot2*2;
end
for i=1:30
mse=mse+(y(i)-(theta(1)*x(i,1)+theta(2)*x(i,2)))^2/2;
end
mse=mse/30;
end
hold on;
y=theta(1)+theta(2)*x;
plot(x,y,'Color',[0,1,0]);
%公式法求theta
%data
x(:,1)=1;
x(:,2)=a(:,1);
y=a(:,2);
theta0=inv(x'*x)*x'*y;
hold on;
y=theta0(1)+theta0(2)*x;
plot(x,y,'Color',[0,0,1]);
线性回归 Linear regression(2)线性回归梯度下降中学习率的讨论的更多相关文章
- 线性回归 Linear regression(1)线性回归的基本算法与求解
本系列内容大部分来自Standford公开课machine learning中Andrew老师的讲解,附加自己的一些理解,编程实现和学习笔记. 第一章 Linear regression 1.线性回归 ...
- 线性回归 Linear regression(3) 线性回归的概率解释
这篇博客从一种方式推导了Linear regression 线性回归的概率解释,内容来自Standford公开课machine learning中Andrew老师的讲解. 线性回归的概率解释 在Lin ...
- [Machine Learning] 单变量线性回归(Linear Regression with One Variable) - 线性回归-代价函数-梯度下降法-学习率
单变量线性回归(Linear Regression with One Variable) 什么是线性回归?线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方 ...
- Stanford机器学习---第二讲. 多变量线性回归 Linear Regression with multiple variable
原文:http://blog.csdn.net/abcjennifer/article/details/7700772 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- Ng第二课:单变量线性回归(Linear Regression with One Variable)
二.单变量线性回归(Linear Regression with One Variable) 2.1 模型表示 2.2 代价函数 2.3 代价函数的直观理解 2.4 梯度下降 2.5 梯度下 ...
- 斯坦福第二课:单变量线性回归(Linear Regression with One Variable)
二.单变量线性回归(Linear Regression with One Variable) 2.1 模型表示 2.2 代价函数 2.3 代价函数的直观理解 I 2.4 代价函数的直观理解 I ...
- 机器学习方法:回归(一):线性回归Linear regression
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 开一个机器学习方法科普系列:做基础回顾之用,学而时习之:也拿出来与大家分享.数学水平有限,只求易懂,学习与工 ...
- 斯坦福CS229机器学习课程笔记 Part1:线性回归 Linear Regression
机器学习三要素 机器学习的三要素为:模型.策略.算法. 模型:就是所要学习的条件概率分布或决策函数.线性回归模型 策略:按照什么样的准则学习或选择最优的模型.最小化均方误差,即所谓的 least-sq ...
- 机器学习 (一) 单变量线性回归 Linear Regression with One Variable
文章内容均来自斯坦福大学的Andrew Ng教授讲解的Machine Learning课程,本文是针对该课程的个人学习笔记,如有疏漏,请以原课程所讲述内容为准.感谢博主Rachel Zhang的个人笔 ...
随机推荐
- Python 实现C语言 while(scanf("%d%d", &a, &b) != EOF) 语句功能
reference:Python 实现C语言 while(scanf("%d%d", &a, &b) != EOF) 语句功能 在python中,无法通过input ...
- 编译Python2.7.10
为了测试 mesos,搞了一个 centos7.1,使用最小化安装,然后自己安装了 net-tools,“开发工具”集.后来想装一下 DCOS Cli工具,结果发现 python 的 pip 不可用. ...
- 使用 Python 在 Caché 和 Sql Server 之间同步数据
任务目标:抽取 Caché 中的数据,导入 Sql Server 中. 遇到的问题: 1.UnicodeEncodeError: ‘ascii’ codec can’t encode characte ...
- 理解OAuth 2.0授权
一.什么是OAuth 二.什么场景下会用到OAuth授权 三.OAuth 2.0中的4个成员 四.OAuth 2.0授权流程 五.OAuth 2.0授权模式 1. authorization c ...
- HTML子页面保存关闭并刷新父页面
1.思路是子页面保存后,后台传递成功的js到前台. 2.js的原理是——子页面调用父页面的刷新 子页面 function Refresh() { window.parent.Re ...
- cJSON序列化工具解读一(结构剖析)
cJSON简介 JSON基本信息 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式.易于人阅读和编写.同时易于机器解析和生成.是一种很好地数据交换语言. 官方 ...
- 设计模式--抽象工厂模式C++实现
抽象工厂模式C++实现 1定义 为创建一组相关或者依赖的对象提供一个接口,且无需指定他们的具体类 2类图 3实现 class AbstractProduct { protected: Abstract ...
- 奇怪的表达式求值 (java实现)
题目参考:http://blog.csdn.net/fuxuemingzhu/article/details/68484749 问题描述; 题目描述: 常规的表达式求值,我们都会根据计算的优先级来计算 ...
- CUDA JPEG编码
基于英伟达的jpegNPP工程,分离实现独立的JPEG压缩. 由于原工程是直接把解码时的jpeg图片的信息直接作为编码时的信息,所以在做独立的JPEG编码时,需要自己来填充各种信息. 1.JPEG编码 ...
- Pandas 时间序列数据绘制X轴主要刻度和次要刻度
先上效果图吧(图中Tue表示周二): Pandas和matplotlib.dates都是使用matplotlib.units来定位刻度. matplotlib.dates可以方便的手动设置刻度,同时p ...