UTF-8文件的Unicode签名BOM(Byte Order Mark)问题记录(EF BB BF)
背景
楼主测试的批量发送信息功能上线之后,后台发现存在少量的ERROR日志,日志内容为手机号码格式不正确。
此前测试过程中没有出现过此类问题,从运营人员拿到的发送列表的TXT,号码是符合规则的,且格式是要求的UTF-8,未发现异常。
因为博主还有别的需求,所以直接反馈给了开发,让开发定位。
定位过程
两天之后,开发给了我两个文件,问我有没有办法找出这两个文件的不同。我看了一下,文件内容完全相同。
后来使用软件beyond compare进行十六进制对比终于发现了区别,
其中一个第一行多了三个字节“EF BB BF”,如下图

原因
多方查证得知是UTF-8有无BOM的区别。
BOM(Byte Order Mark),是UTF编码方案里用于标识编码的标准标记,在UTF-16里本来是FF FE,变成UTF-8就成了EF BB BF。这个标记是可选的,因为UTF8字节没有顺序,所以它可以被用来检测一个字节流是否是UTF-8编码的。微软做这种检测,但有些软件不做这种检测, 而把它当作正常字符处理。
微软在自己的UTF-8格式的文本文件之前加上了EF BB BF三个字节, windows上面的notepad等程序就是根据这三个字节来确定一个文本文件是ASCII的还是UTF-8的, 然而这个只是微软暗自作的标记, 其它平台上并没有对UTF-8文本文件做个这样的标记。
也 就是说一个UTF-8文件可能有BOM,也可能没有BOM
解决方法
使用Notepad++编辑,转换为UTF-8无BOM格式即可
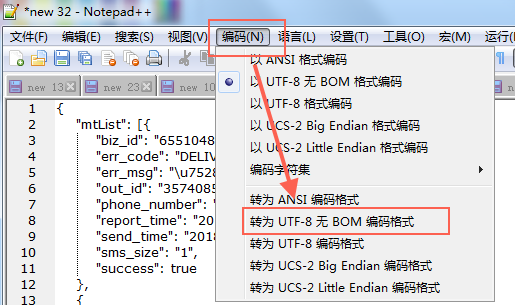
参考资料:EF BB BF
UTF-8文件的Unicode签名BOM(Byte Order Mark)问题记录(EF BB BF)的更多相关文章
- LITTLE-ENDIAN(小字节序、低字节序) BOM——Byte Order Mark 字节序标记 数据在内存中的存放顺序
总结: 1. endian 字节存放次序 字节序,顾名思义字节的顺序,再多说两句就是大于一个字节类型的数据在内存中的存放顺序(一个字节的数据当然就无需谈顺序的问题了). 2. LITTLE-ENDIA ...
- 字节顺序标记——BOM,Byte Order Mark
定义 BOM(Byte Order Mark),字节顺序标记,出现在文本文件头部,Unicode编码标准中用于标识文件是采用哪种格式的编码. 介绍 UTF-8 不需要 BOM,尽管 Unico ...
- 文本编辑BOM标记(Byte Order Mark)
微软的自带记事本程序notepad.exe会给UTF-8编码的文件头加入三个隐藏的字节(即BOM).这是一种很愚蠢的做法.就是为了让编辑器不去猜测文件本身是ASCII码还是UTF-8. 什么是BOM ...
- StreamWriter结合UTF-8编码使用不当,会造成BOM(Byte Order Mark )问题生成乱码(转载)
问: I was using HttpWebRequest to try a rest api in ASP.NET Core MVC.Here is my HttpWebRequest client ...
- UTF-8 BOM(EF BB BF)
原标题:link标签和script标签跑到body下面,网页顶部有空白,出现“锘匡豢”乱码,UTF-8 BOM,EF BB BF 来自:http://tunps.com/link-and-script ...
- 关于bom ef+bb+bf的问题
今天在商品详细页头部出现了一行空白,各种尝试无果,最后怀疑是不是bom头的问题,经过断点跟踪调试逐步缩小范围,果然最后发现是一个语言包文件的开头有 ef bb bf样式的字节,用ultraedit另存 ...
- [Ubuntu] Remove Byte Order Mark (BOM) from files recursively [Forward article]
Original article: http://www.yiiframework.com/wiki/570/remove-byte-order-mark-bom-from-files-recursi ...
- PHP 下载文件时自动添加bom头的方法
首先弄清楚,什么是bom头?在Windows下用记事本之类的程序将文本文件保存为UTF-8格式时,记事本会在文件头前面加上几个不可见的字符(EF BB BF),就是所谓的BOM(Byte order ...
- 用PHP去掉文件头的Unicode签名(BOM)
<?php //此文件用于快速测试UTF8编码的文件是不是加了BOM,并可自动移除 //By Bob Shen $basedir="."; //修改此行为需要检测的目录,点表 ...
随机推荐
- spring 自定义事物同步器(一): TransactionSynchronizationManager 解析
一..JPA 获取 Hibernate的session try { session = entityManager.unwrap(Session.class); } catch (Exception ...
- Java编程:将具有父子关系的数据库表数据转换为树形结构,支持无限层级
在平时的开发工作中,经常遇到这样一个场景,在数据库中存储了具有父子关系的数据,需要将这些数据以树形结构的形式在界面上进行展示.本文的目的是提供了一个通用的编程模型,解决将具有父子关系的数据转换成树形结 ...
- 增强MyEclipse的代码自动提示功能
一般在Eclipse ,MyEclipse代码里面,打个foreach,switch等 这些,是无法得到代码提示的(不信自己试试),其他的就更不用说了,而在Microsoft Visual Stu ...
- 文件传输(xmodem协议)
https://www.menie.org/georges/embedded/ 需要移植如下两个基础的硬件读写函数 int _inbyte(unsigned short timeout); void ...
- Linux系统——特殊符号、通配符及正则表达式
特殊符号 | 管道符号,将管道符左边的命令的执行结果以字符串的形式通过 管道符传送到管道符右边命令末尾,作为管道符右边命令的执行 范围 > 输出重定向 >> 追加输出重定向 < ...
- arya使用流程
1.github中的项目clone到本地(路径在最后),然后将arya文件夹复制到你的django工程中作为一个独立的app,该app实现了RBAC(基于角色的权限访问控制Role-Based Acc ...
- DevStore分享:月薪3万的程序员都避开了哪些坑
程序员薪水有高有低,有的人一个月可能拿30K.50K,有的人可能只有2K.3K.同样有五年工作经验的程序员,可能一个人每月拿20K,一个拿5K.是什么因素导致了这种差异?我特意总结了容易导致薪水低的九 ...
- iClap的名字是怎么来的,clap是有什么特殊的意义么?
iClap的名字来源于:Clap中文是鼓掌的意思,鼓掌代表合拍,一个团队的价值观以及工作方式合拍,是最重要的,当项目启动时,大家对产品认可,鼓掌开始实施:当项目成功上线,团队也会以鼓掌的形式庆祝:当我 ...
- TOSCA自动化测试工具--建立测试用例
1.测试链接 demowebshop.tricentis.com 测试login 2.检查元素 3.Modules模块,建立自己的文件夹,右键Scan Application , Desktop 4. ...
- doc命令下查看java安装路径
在doc窗口下使用命令:set java_home 即可查看.