hand first python 选读(1)
列表(list)
基本操作
比如说我要整理一个近期热映的电影列表:
movies = ["venom", "My Neighbor Totor", "Aquaman"]
print(movies)
# ['venom', 'My Neighbor Totor', 'Aquaman']
print(len(movies))
# 3
print(movies[1])
# My Neighbor Totor
列表很像数组,但功能超越数组。列表都是从0开始的,python中列表无需事先声明类型。
从列表后面加上一个新的元素,比如说加个“无名之辈”,是append方法。
movies.append('A Cool Fish')
print(movies)
# ['venom', 'My Neighbor Totor', 'Aquaman','A Cool Fish']
删除列表最后一个元素:pop方法。
movies.pop()
print(movies)
# ['venom', 'My Neighbor Totor']
两个列表相衔接,用的是extend方法。
movies.extend(['Dying To Survive', 'Detective Conan'])
print(movies)
# ['venom', 'My Neighbor Totor', 'Aquaman', 'Dying To Survive', 'Detective Conan']
我想在某个条件下删除一个元素,同时加上一个元素,涉及remove和insert方法。
movies.remove('venom')
print(movies)
# ['My Neighbor Totor', 'Aquaman']
movies.insert(len(movies),'venom')
print(movies)
# ['My Neighbor Totor', 'Aquaman','venom']
python中列表可以放任何类型的数据。
循环
处理列表需要各种迭代方法。是时候用for...in循环了
for movie in movies:
print(movie)
# venom
# My Neighbor Totor
# Aquaman
同理while循环也是可以的
count=0
while count<len(movies):
print(movies[count])
count+=1
一般都推荐for循环
列表当然也能嵌套,我们可以用isinstance方法检测之:
movies = ["venom", ["My Neighbor Totor", "Aquaman"]]
print(isinstance(movies,list))
# True
if else
如果我想把这个嵌套列表单独打印出来,可以这么操作
movies = ["venom", ["My Neighbor Totor", "Aquaman"]]
for movie in movies:
if isinstance(movie, list):
for _movie in movie:
print(_movie)
else:
print(movie)
# venom
# My Neighbor Totor
# Aquaman
函数与递归:多层嵌套的扁平化
给这个列表再加一层:
movies = ["venom", ["My Neighbor Totor", ["Aquaman"]]]
用上节来处理多层嵌套,会导致大量重复而不优雅的代码。
首先使用函数让代码更加优雅:
movies = ["venom", ["My Neighbor Totor", ["Aquaman"]]]
def flatten(_list):
if(isinstance(_list, list)):
for _item in _list:
flatten(_item)
else:
print(_list)
flatten(movies)
为了巩固所学:再举一个通过递归生成斐波拉契数列第N项的例子:
斐波那契数列(Fibonacci sequence),指的是这样一个数列:1、1、2、3、5、8、13、21、34、……在数学上,斐波纳契数列以如下被以递推的方法定义:F(1)=1,F(2)=1, F(3)=2,F(n)=F(n-1)+F(n-2)(n>=4,n∈N*)
def fib(n):
if n < 1:
return 'error'
if n == 1 or n == 2:
return 1
else:
return fib(n-1)+fib(n-2)
print(fib(6))
# 8
虽然很简洁,但是n>100就报错了。因为python的递归支持100层
函数
模块化开发
把上一章的flatten函数单独用base.py存起来,它就打包为一个模块。
除了之前提到的,用#注释,还可以用三重"""作为python的注释。
再同一个命名文件夹下重新创建一个app.py文件:
import base as util
movies = ["venom", ["My Neighbor Totor", ["Aquaman"]]]
print(util.flatten(movies))
# 预期结果
列表更多的内置方法
先学习以下内置的方法(BIF)
- list() :工厂函数,创建一个新的列表
- next() : 返回一个迭代结构(如列表)中的下一项
- id() :返回一个数据对象的唯一标识(内存地址)
>>> id(b)
140588731085608
- int() :将一个字符串如
'5'转化为5 - range() :返回一个迭代器,根据需要生成一个指定范围的数字
>>>range(10) # 从 0 开始到 10
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> range(1, 11) # 从 1 开始到 11
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> range(0, 10, 3) # 步长为 3 , 迭代终点不超过10
[0, 3, 6, 9]
- enumerate() :把单个数组创建为带有索引号的成对列表
>>>seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1)) # 下标从 1 开始
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
升级你的模块:参数
扁平化打印只能看到每个数组最小的元素,考虑用缩进来体现彼此的关系。那怎么做呢?
提示:用range方法实现。
事实上在打印时只需要知道每次迭代的深度,就好处理了。因此需要引入第二个参数
# base.py
def flatten(_list,level=0):
if(isinstance(_list, list)):
for _item in _list:
flatten(_item,level+1)
else:
for step in range(level):
print("\t", end='')
print(_list)
# app.py
import base as util
movies = ["venom", ["My Neighbor Totor", ["Aquaman"]],
["My Neighbor Totor", ['000',["Aquaman"]]], 'aaa', ['Aquaman'],'sadas']
print(util.flatten(movies))
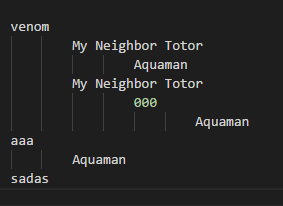
效果出来了。但还有不满意的地方。如果要兼容过去的写法怎么办?
def flatten(_list, count=False, level=0):
if(isinstance(_list, list)):
for _item in _list:
flatten(_item,count,level+1)
else:
if count:
for step in range(level):
print("\t", end='')
print(_list)
else:
print(_list)
调用时默认就是不缩进。
hand first python 选读(1)的更多相关文章
- head first python选读(5)
python web 开发 犯了低级错误,这本书看了一半了才知道书名应为<head first python>,不是hand first.. 现在开始一个web应用. 总算是熟悉的内容了. ...
- hand first python 选读(2)
文件读取与异常 文件读取与判断 os模块是调用来处理文件的. 先从最原始的读取txt文件开始吧! 新建一个aaa.txt文档,键入如下英文名篇: Li Lei:"Hello,Han Meim ...
- python之进程与线程
什么是操作系统 可能很多人都会说,我们平时装的windows7 windows10都是操作系统,没错,他们都是操作系统.还有没有其他的? 想想我们使用的手机,Google公司的Androi ...
- python之面相对象程序设计
一 面向对象的程序设计的由来 面向对象设计的由来见概述:http://www.cnblogs.com/linhaifeng/articles/6428835.html 面向对象的程序设计:路飞学院版 ...
- Python 中的实用数据挖掘
本文是 2014 年 12 月我在布拉格经济大学做的名为‘ Python 数据科学’讲座的笔记.欢迎通过 @RadimRehurek 进行提问和评论. 本次讲座的目的是展示一些关于机器学习的高级概念. ...
- Python基础-week06 面向对象编程基础
一.面向对象编程 1.面向过程 与 面向对象编程 面向过程的程序设计: 核心是 过程二字,过程指的是解决问题的步骤,即先干什么再干什么......面向过程的设计就好比精心设计好一条流水线,是一种机械式 ...
- 送书福利| Python 完全自学手册
前言 这里不讨论「能不能学,要不要学,应不应该学 Python」的问题,这里只会告诉你怎么学. 首先需要强调的是,如果 Python 都学不会,那么我建议你考虑别的行业,因为 Python 之简单,令 ...
- Python 爬虫系列
爬虫简介 网络爬虫 爬虫指在使用程序模拟浏览器向服务端发出网络请求,以便获取服务端返回的内容. 但这些内容可能涉及到一些机密信息,所以爬虫领域目前来讲是属于灰色领域,切勿违法犯罪. 爬虫本身作为一门技 ...
- Python中的多进程与多线程(一)
一.背景 最近在Azkaban的测试工作中,需要在测试环境下模拟线上的调度场景进行稳定性测试.故而重操python旧业,通过python编写脚本来构造类似线上的调度场景.在脚本编写过程中,碰到这样一个 ...
随机推荐
- SAP Idoc 事务码
SALE Display ALE Customizing SM59 RFC Destinations (Display/Maintain) BD64 Maintenance of Distributi ...
- void指针意义、Const、volatile、#define、typedef、接续符
1.C语言规定只有相同类型的指针才可以相互赋值. Void*指针作为左值用于接收任意类型的指针, void*指针作为右值赋给其他指针时需要强制类型转换. 2.在C语言中Const修饰的变量是只读的,本 ...
- PAT 1118 Birds in Forest [一般]
1118 Birds in Forest (25 分) Some scientists took pictures of thousands of birds in a forest. Assume ...
- python全栈开发从入门到放弃之推导式详解
variable = [out_exp_res for out_exp in input_list if out_exp == 2] out_exp_res: 列表生成元素表达式,可以是有返回值的函数 ...
- 函数对象[条款18]---《C++必知必会》
有时需要一些行为类似于函数指针的东西,但函数指针显得笨拙.危险而且过时(让我们承认这一点).通常最佳方式是使用函数对象(function object)取代函数指针. 与智能指针一样,函数对象也是一个 ...
- windows计划任务定时运行synctoy的坑
每次设置好synctoy之后,需要让synctoy运行一次,windows的计划任务才能成功执行,如果变更了synctoy的设置,而没有让synctoy成功执行过,windows计划任务将执行失败,坑 ...
- HDU 1532 Drainage Ditches(网络流模板题)
题目大意:就是由于下大雨的时候约翰的农场就会被雨水给淹没,无奈下约翰不得不修建水沟,而且是网络水沟,并且聪明的约翰还控制了水的流速, 本题就是让你求出最大流速,无疑要运用到求最大流了.题中m为水沟数, ...
- php的正则表达式完全手册
前言 正则表达式是烦琐的,但是强大的,学会之后的应用会让你除了提高效率外,会给你带来绝对的成就感.只要认真去阅读这些资料,加上应用的时候进行一定的参考,掌握正则表达式不是问题. 索引 1._引子 2. ...
- vultr VPS安装BBR
1.安装 wget --no-check-certificate https://github.com/teddysun/across/raw/master/bbr.sh chmod +x bbr.s ...
- JS时间和字符串的相互转换 Date+String
1.js字符串转换成时间 1.1方法一:输入的时间格式为yyyy-MM-dd function convertDateFromString(dateString) { if (dateString) ...