C++实现最基本的LRUCache服务器缓存
目录:
后台开发必备知识,不过我不是搞这个的,只是因为很久以前就想写这些东西,事情多,拖到现在。写的过程里面发现很多问题,不会全部说,最后会顺带提一提。
注意,本篇笔记只是对接口写法做了记录,并没有进行更严格的设计和限制,包括更严密的封装,这里只是学习它实现的原理。
不过有些idea还是要知道的,系统定时对缓存进行清除并加入满足条件的新数据,是根据:访问时间,访问次数,可用缓存容量(分配到的内存)等因素决定的,实际设计其实很多东西需要考虑。
一、介绍:
LRU,Least Recently Used,最近最少使用,服务器缓存常用算法的一种。
比如说一些系统登录的操作,不可能每次你访问系统都去调用数据库的东西,如果能划出一些空间来,比如说500M,用来缓存这些东西,这样用户访问的时候先在缓存里找,找不到,再去访问数据库,同时把被访问的内容放到缓存里面(我们可以假设这些东西还会经常被访问)。然而,我们分配用来做缓存(Cache)的空间肯定是有限的,总不可能从数据库读的东西全部放到缓存里,所以,当缓存里的内容达到上限值的时候,我们就要把最少使用的东西写回数据库,再将新的访问内容从数据库暂存到缓存里面。
二、数据结构:
最常用的数据结构实现方式是hash_map和Double-Linked List,hash_map只是为了实现键值key-value对应,这样就避免了每次寻找特定值都要在双线链表里面顺序查找,服务器是没办法负担这种低效率的查找方法的。
我们可以为链表节点写一个结构体,用来定义节点的类型;然后专门写一个类用来组织缓存信息的存放——以双链表的形式。
template<class K, class T>
struct Node
{
K key;
T data;
Node *next;
Node *prev;
};
template<class K,class T>
class LRUCache
{
public:
LRUCache(size_t size); //typedef unsigned int size_t
~LRUCache();
void Put(K key,T data);
T Get(K key);
private:
void Attach(Node<K,T>* node);
void Detach(Node<K,T>* node);
private:
hash_map<K,Node<K,T>*> hashmap;
vector<Node<K,T>*> linkedList;
Node<K,T>* head;
Node<K,T>* tail;
Node<K,T>* entries; //temp nodes
};
看代码太枯燥,我画了个UML图:

三、主要的两个函数接口Put()和Get():
最基本的,不是存,就是取。那修改呢?合并到存里面去了,通过键值key查找一个hash_map对应的value,如果value不是NULL,那么更新value的内容即可。其实服务器缓存比较多作的是读多写少的东西。
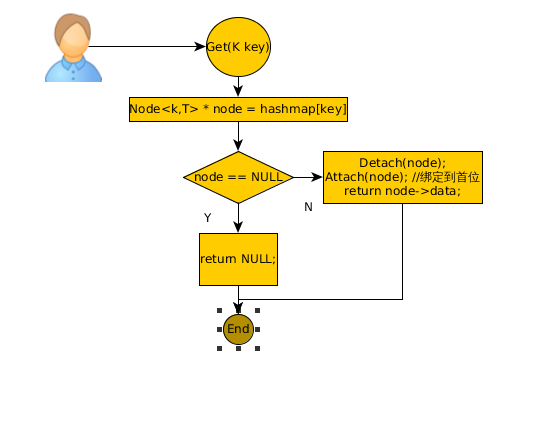
因为代码实在是太枯燥了,所以针对Put函数和Get函数画了两张流程图:
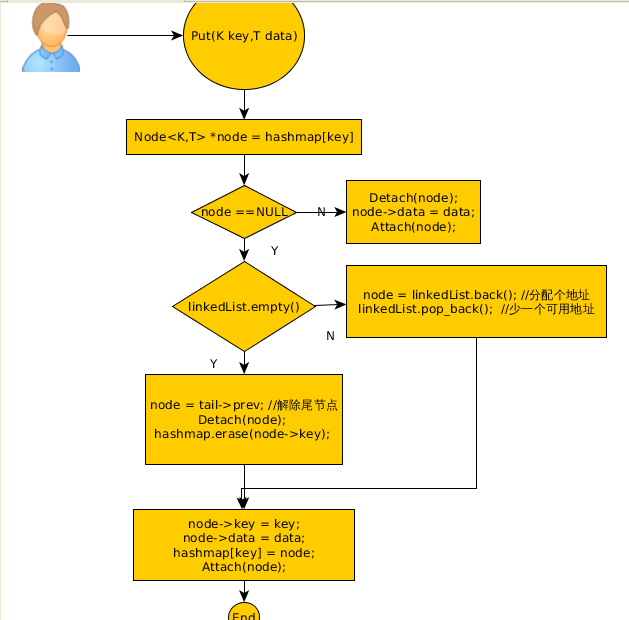
其中,Detach(node)表示将这个节点从双链表中解出,成为一个独立的节点;Attach(node)表示将node插入到头节点head后面(表示它可能再次被用到),这样的话,如果自己再设计一个GetFirst()函数,就能直接获取上次的访问结果,这种访问连hash_map都不需要用到。
流程讲解:
在上述Put函数流程图中,注意第一个判断“node==NULL”,这个node地址是通过hashmap映射而来的:1、如果不是NULL,说明这个节点已经存在,那么将该节点的数据data重写以后加到链表头;
2、如果是NULL,还要进行第二个判断“分配地址的linkedList是不是已经空了”:
2.1、如果空了,说明全部可用地址已经分配完了,那么,将原链表的最后一个节点踢出链表(应写入数据库),然后将被踢出点的hashmap中对应的key-value擦除,然后再加入新节点,并在hashmap中对应好新节点的key-value;
2.2、如果不空,那么从linkedList中分配个新地址给这个节点,同时linkedList要弹出分配完的地址,然后再将新节点加入链表中,对应好hashmap中的key-value。
要注意,hashmap用来对应key-value,这里是方便查找;而vector变量linkedList也只是在初始化的时候存储了一块连续地址,用来分配地址,它们两者都不是用来直接构建链表的,链表是你自己建立的。
Get()函数就比较简单了:
四、C++代码实现:
代码不是我原创的(后面给出原文地址),不过理清思路之后我自己实现了一遍,测试的过程实在是各种奇葩和辛苦(因为一个不注意的小地方)。
代码实现里用到了hash_map,注意,这个不是C++标准的一部分,所以你要自己去库文件里找找,一般来说库文件都是在/usr/include下面的了,cd到这个文件夹,然后用grep找一下:
cd /usr/include
grep -R "hash_map"
最后你会发现是这个头文件:<ext/hash_map>,用文本文档打开来看一下,因为是限制了命名空间的,会发现有两个可用的命名空间,其中一个是__gnu_cxx。
代码我一开始是用Qt写的,不过后来发现Qt没法调试(后面再说),于是最后使用Eclipse完成了调试和测试,下面先给出代码:
#include <iostream>
#include<ext/hash_map>
#include<vector>
#include<assert.h>
#include<string>
#include<stdlib.h>
#include<stdio.h>
#include<iomanip>
using namespace std;
//grep -R "hash_map" /usr/include . Find the file and you will know what the namespace is.
using namespace __gnu_cxx; template<class K, class T>
struct Node
{
K key;
T data;
Node *next;
Node *prev;
}; template<class K,class T>
class LRUCache
{
public:
LRUCache(size_t size) //typedef unsigned int size_t
{
entries = new Node<K,T>[size];
assert(entries!=NULL);
for(int i = ; i < size; i++)
{
linkedList.push_back(entries+i); //Store the addr.
}
//Initial the double linklist
head = new Node<K,T>;
tail = new Node<K,T>;
head->prev = NULL;
head->next = tail;
tail->next = NULL;
tail->prev = head;
}
~LRUCache()
{
delete head;
delete tail;
delete []entries;
}
void Put(K key,T data)
{
Node<K,T> *node = hashmap[key];
if(node == NULL) //node == NULL means it doesn't exist
{
if(linkedList.empty()) //linkedList is empty means all avaliable space have been allocated
{
node = tail->prev; //Detach the last code
Detach(node);
hashmap.erase(node->key);
}
else
{
node = linkedList.back(); //Allocate an addr to the node
linkedList.pop_back(); //Pop the addr mentioned above
}
node->key = key;
node->data = data;
hashmap[key] = node;
Attach(node);
}
else
{
Detach(node);
node->data = data;
Attach(node);
}
} T Get(K key)
{
Node<K,T> * node = hashmap[key];
if(node)
{
Detach(node);
Attach(node); //Attach the node to the fisrt place
return node->data;
}
else
{
return T();
/*U can write some codes to test it:
*void main()
*{
*char c = int();
cout<<c<<endl;
int i = char();
cout<<i<<endl;
cout<<char()<<endl;
cout<<int()<<endl;
}*/
}
}
private:
void Attach(Node<K,T>* node)
{
assert(node != NULL);
node->next = head->next;
node->next->prev = node;
node->prev = head;
head->next = node;
}
void Detach(Node<K,T>* node)
{
assert(node != NULL);
node->prev->next = node->next;
node->next->prev = node->prev;
} private:
hash_map<K,Node<K,T>*> hashmap;
vector<Node<K,T>*> linkedList;
Node<K,T>* head;
Node<K,T>* tail;
Node<K,T>* entries; //temp nodes }; int main()
{
cout << "Hello World!" << endl;
LRUCache<int,string> cache();
/*
string str = "test";
char buffer[10];
int i = 1;
//itoa(1,c,10); //Not existing in the ANSI-C or C++.
sprintf(buffer,"%d",i); //The alternative to the code above.
str.append(buffer);
cout<<str<<endl;
*/
cache.Put(,"test1");
cout<<cache.Get()<<endl;
if(cache.Get()=="")
{
cout<<"Node doesn't exist!"<<endl;
}
cache.Put(,"test0");
cache.Put(,"test3");
cache.Put(,"test_1_again");
cache.Put(,"test12");
cache.Put(,"test56");
cout<<cache.Get()<<endl;
/*Error code. And I don't know why!!!!
string str="test";
char buffer[10];
for(int i = 0 ; i < 14; i++)
{
if(sprintf(buffer,"%d",i)<10)
{
str.append(buffer);
cache.Put(i,str);
str="test";
}
}
for(int i =0; i < 14; i++)
{
if(!(i/5))
{
cout<<cache.Get(i)<<setw(4);
}
cout<<endl;
}*/
return ;
}
LRUCache
调试的时候我发现了一个问题:
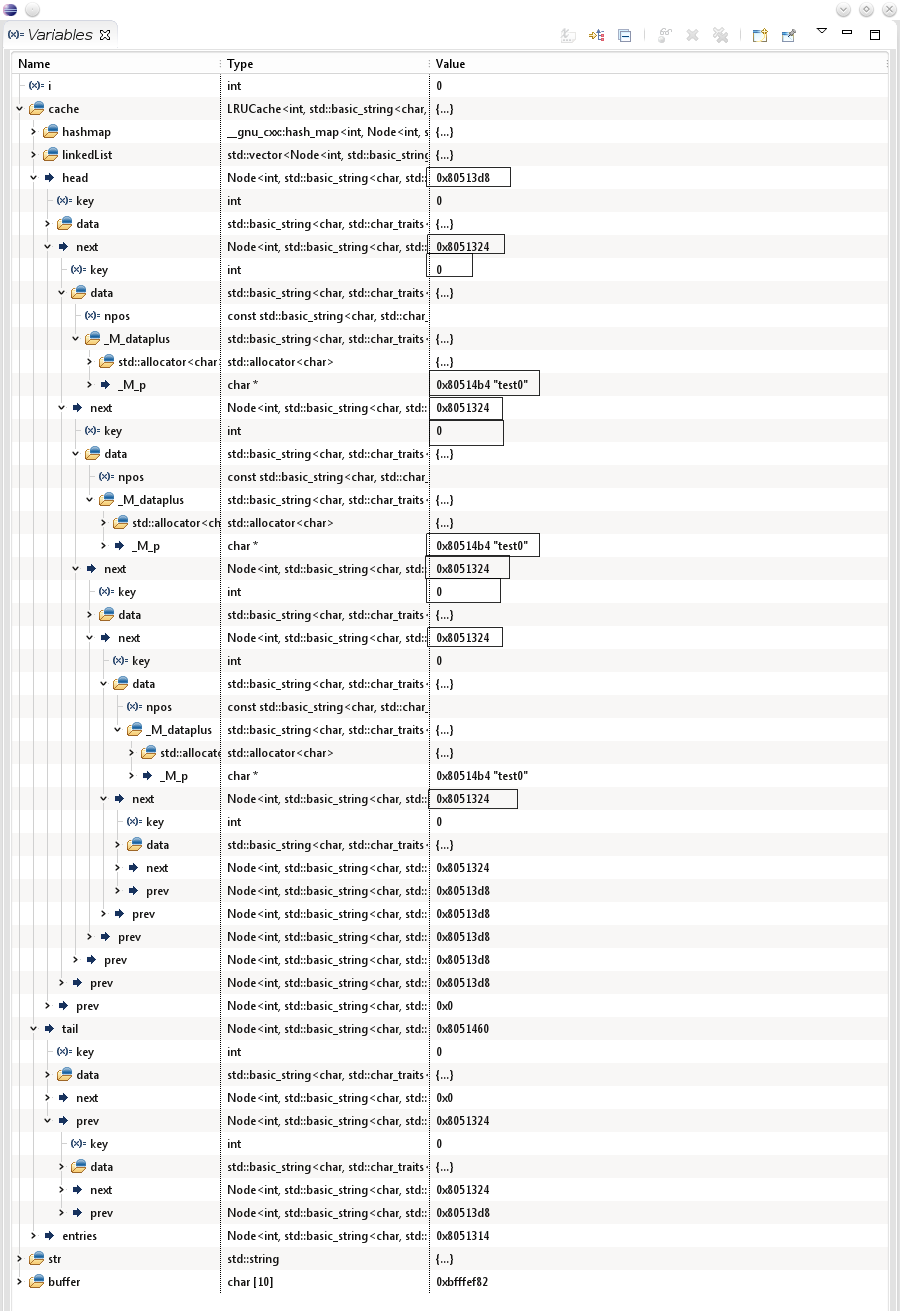
坑爹了,全部节点的next指针全部都指向自己,这样的话链表长得像什么样子呢?应该是这样:
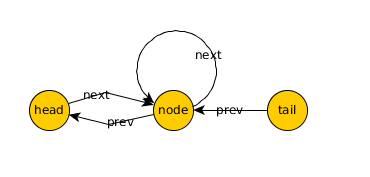
这个错误到底是怎么来的?
我反复地看代码,节点的链入(Attach)和取出(Detach)都是没有问题的,而且,插入新节点的时候,已经插入过的节点为什么没有了?Attach方法既然是正确的,那为什么节点的next为什么会指向自己?
综合上面两个问题,我突然意识到:那只能是分配地址的时候出现问题了!
所以回到构造函数分配地址的部分,我发现在for循环里面,本应是:
linkedList.push_back(entries+i);
这样就能顺序存储分配好的地址。
但我竟然把i写成了1,所以每个地址都成了同一个!吐血的经历。
最后代码更正之后即可正确运行:
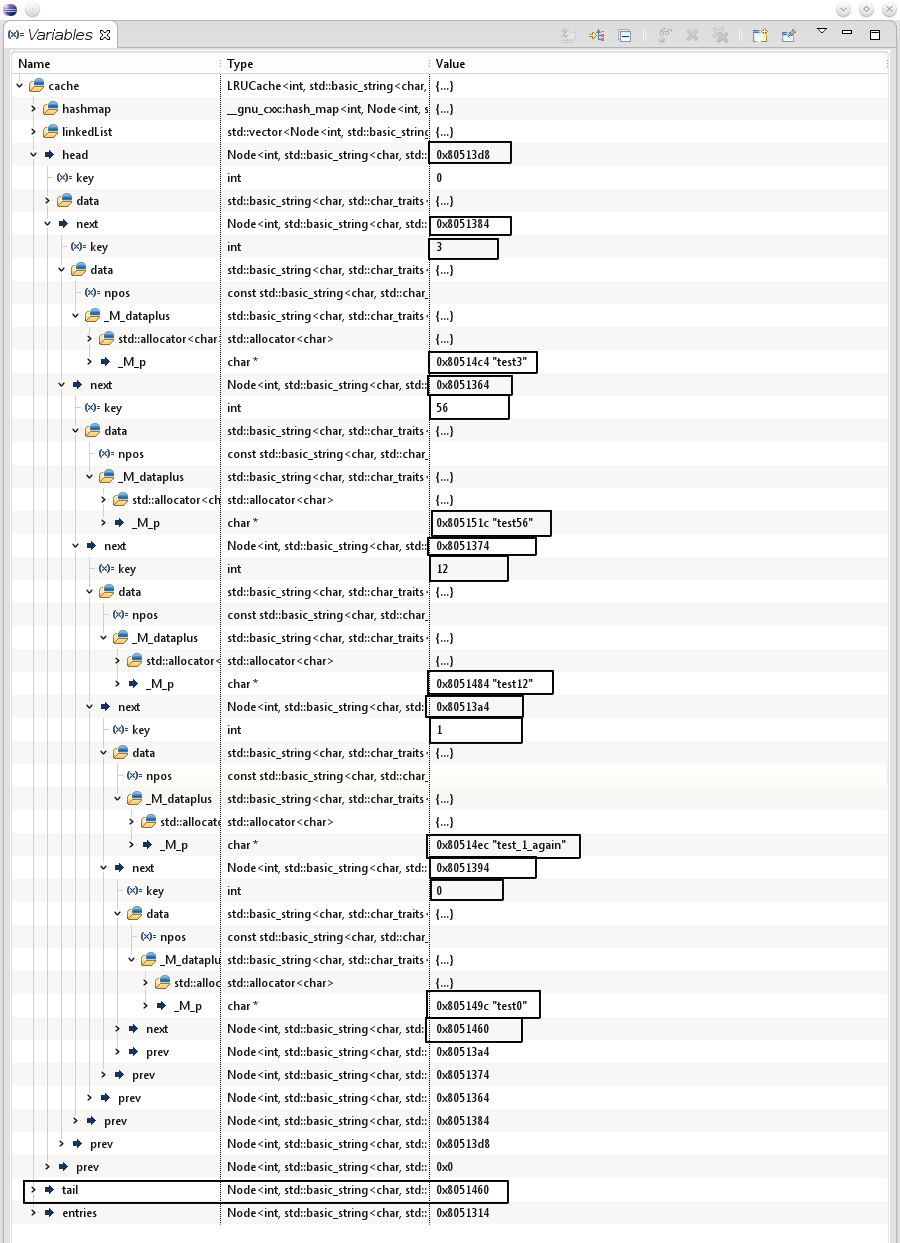
对应的测试代码为:

最后一笔带过编写过程中遇到的三个主要问题:
1、make install 源码包安装的软件怎么卸载(最好用--prefix=""指定安装路径,这样你卸载的时候直接卸载那个安装路径的文件夹);
2、QtCreator调试的时候为什么不显示变量(因为你用的python版本是3.0以上的,Qt的gdb调试器不支持,自己重新装一个2.X版本的,参考链接:http://blog.hostilefork.com/qtcreator-debugger-no-locals-ubuntu/);
3、测试代码的时候出现一点小错误,搞了很久但还是不知道为什么(在main函数中注释的最后一段代码,有兴趣的可以自己调试一下)。
参考文章:
1、http://www.cs.uml.edu/~jlu1/doc/codes/lruCache.html
2、http://blog.csdn.net/xiaofei_hah0000/article/details/8993617
C++实现最基本的LRUCache服务器缓存的更多相关文章
- 强制JSP页面刷新,防止被服务器缓存(可用于静态include强制刷新)
对于jsp页面,为了防止页面被服务器缓存.始终返回同样的结果. 通常的做法是在客户端的url后面加上一个变化的参数,比如加一个当前时间. 我现在使用的方法是在jsp头部添加以下代码: <% ...
- 缓存:前端页面缓存、服务器缓存(依赖SQL)MVC3
缓存依赖数据库 第一步 1通过vs里面带的命令提示窗口. 2或者.NET Framework 版本 4(64 位系统)条件,%windir%\Microsoft.NET\Framework64\v4. ...
- 清理tomcat服务器缓存
据悉,2014年最流行的应用服务器排行榜揭晓Tomcat仍然处于领先位置.41%的部署使用的是Tomcat,和2013年的43%的市场份额数据一 致.下面还是我们的热门选择Jetty和JBoss/Wi ...
- LruCache DiskLruCache 缓存 简介 案例 MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- .Net Core 跨平台开发实战-服务器缓存:本地缓存、分布式缓存、自定义缓存
.Net Core 跨平台开发实战-服务器缓存:本地缓存.分布式缓存.自定义缓存 1.概述 系统性能优化的第一步就是使用缓存!什么是缓存?缓存是一种效果,就是把数据结果存在某个介质中,下次直接重用.根 ...
- LruCache的缓存策略
一.Android中的缓存策略 一般来说,缓存策略主要包含缓存的添加.获取和删除这三类操作.如何添加和获取缓存这个比较好理解,那么为什么还要删除缓存呢?这是因为不管是内存缓存还是硬盘缓存,它们的缓存大 ...
- Nginx 针对上游服务器缓存
L:99 nginx缓存 : 定义存放缓存的载体 proxy_cache 指令 Syntax: proxy_cache zone | off; Default: proxy_cache off; Co ...
- nginx做rails项目web服务器缓存配置方法
nginx作为Web服务器.或反向代理服务器都可以使用缓存 一.作为Web服务器 nginx可以通过 expires 指令来设置响应头的过期时间,实现浏览器缓存(Browser Caching),即浏 ...
- eclipse中Tomcat服务器缓存位置,以及清理Tomcat缓存
在Eclipse中进行Web开发,一般都会将项目直接在Eclipse中的Tomcat服务器运行,有时候修改了程序和页面之后,运行结果还是原来的 tomcat服务器中缓存的程序或者页面,需要清理缓存之后 ...
随机推荐
- c#使用FastReports打印
private void btnprint_Click(object sender, EventArgs e) { //报表路径 string path = Application.StartupPa ...
- C/C++编译过程
C/C++编译过程 C/C++编译过程主要分为4个过程 1) 编译预处理 2) 编译.优化阶段 3) 汇编过程 4) 链接程序 一.编译预处理 (1)宏定义指令,如#define Name Token ...
- mysql覆盖索引
话说有这么一个表: CREATE TABLE `user_group` ( `id` int(11) NOT NULL auto_increment, `uid` int(11) NOT NU ...
- vue中获取客户端IP地址(不需要额外引入三方文件)
之前看了几种方法 ,都是引入腾讯,新浪,搜狐等的三方js文件来查询IP地址,但是我自己测试的时候IP地址不准确,所以就找了找,发现了这个方法,准确的获取到了IP地址和cmd的ipconfig获取到的I ...
- Docker中安装配置Oracle数据库
本文使用的OS是Ubuntu([16.04.1_server][1])[注:Ubuntu是安装在vmware虚拟机上的]. 其他的Oracle连接工具:[sqldeveloper-4.1.5.21.7 ...
- Spring源码解析(一)开篇
前言 Spring源码继承结构比较复杂,看过以后经常会忘记.因此,记录一下源码分析的过程,方便以后回顾.本次分析的Spring源码版本为3.2.15. 另外,一提Spring就是IOC.DI等等,我们 ...
- 基于nodejs的websocket通信程序设计
网络程序设计无疑是nodejs + html最好用 一.nodejs的安装 1.在ubuntu上的安装 sudo apt install nodejs-legacy sudo apt install ...
- Python中的None与Null(空字符)的区别
参考自 Python中的None与空字符(NULL)的区别 - CSDN博客 http://blog.csdn.net/crisschan/article/details/70312764 首先了解p ...
- matplotlib绘制饼状图
源自http://blog.csdn.net/skyli114/article/details/77508430?ticket=ST-41707-PzNbUDGt6R5KYl3TkWDg-passpo ...
- Xcode插件开发案例教程
引言 在平时开发过程中我们使用了很多的Xcode插件,虽然官方对于插件制作没有提供任何支持,但是加载三方的插件,默认还是被允许的.第三方的插件,存放在 ~/Library/Application Su ...