Apache Hive (四)Hive的连接3种连接方式
转自:https://www.cnblogs.com/qingyunzong/p/8715925.html
一、CLI连接
进入到 bin 目录下,直接输入命令:
[hadoop@hadoop3 ~]$ hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apps/apache-hive-2.3.3-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/home/hadoop/apps/apache-hive-2.3.3-bin/lib/hive-common-2.3.3.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive> show databases;
OK
default
myhive
Time taken: 6.569 seconds, Fetched: 2 row(s)
hive>
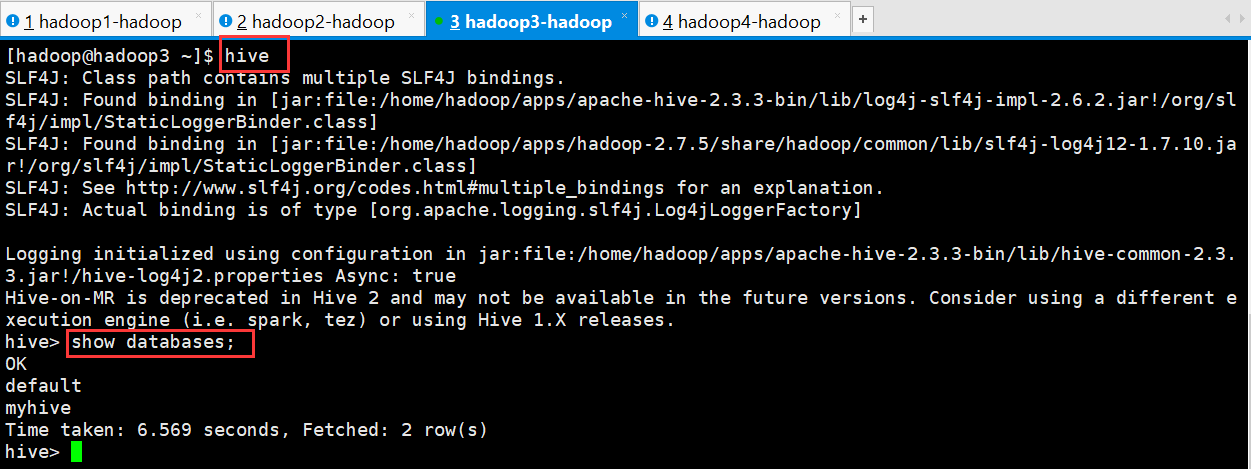
启动成功的话如上图所示,接下来便可以做 hive 相关操作
补充:
1、上面的 hive 命令相当于在启动的时候执行:hive --service cli
2、使用 hive --help,可以查看 hive 命令可以启动那些服务
3、通过 hive --service serviceName --help 可以查看某个具体命令的使用方式
二、HiveServer2/beeline
在现在使用的最新的 hive-2.3.3 版本中:都需要对 hadoop 集群做如下改变,否则无法使用
1、修改 hadoop 集群的 hdfs-site.xml 配置文件
加入一条配置信息,表示启用 webhdfs
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
2、修改 hadoop 集群的 core-site.xml 配置文件
加入两条配置信息:表示设置 hadoop 的代理用户
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
配置解析:
hadoop.proxyuser.hadoop.hosts 配置成*的意义,表示任意节点使用 hadoop 集群的代理用户 hadoop 都能访问 hdfs 集群,hadoop.proxyuser.hadoop.groups 表示代理用户的组所属
以上操作做好了之后(最好重启一下HDFS集群),请继续做如下两步:
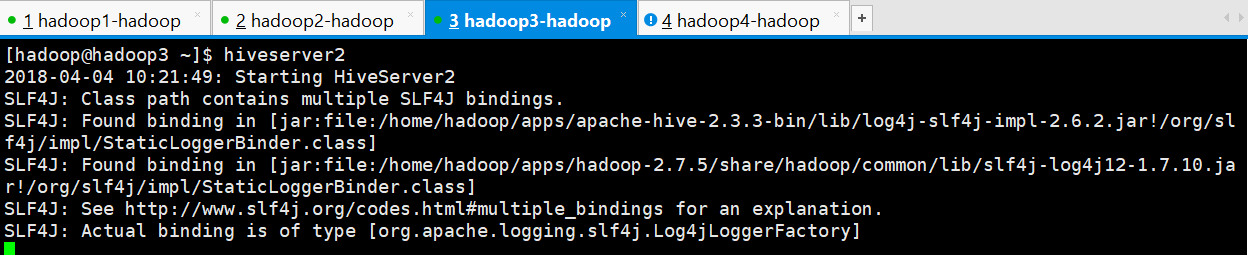
第一步:先启动 hiveserver2 服务
启动方式,(假如是在 hadoop3 上):
启动为前台:hiveserver2
[hadoop@hadoop3 ~]$ hiveserver2
2018-04-04 10:21:49: Starting HiveServer2
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apps/apache-hive-2.3.3-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
启动会多一个进程
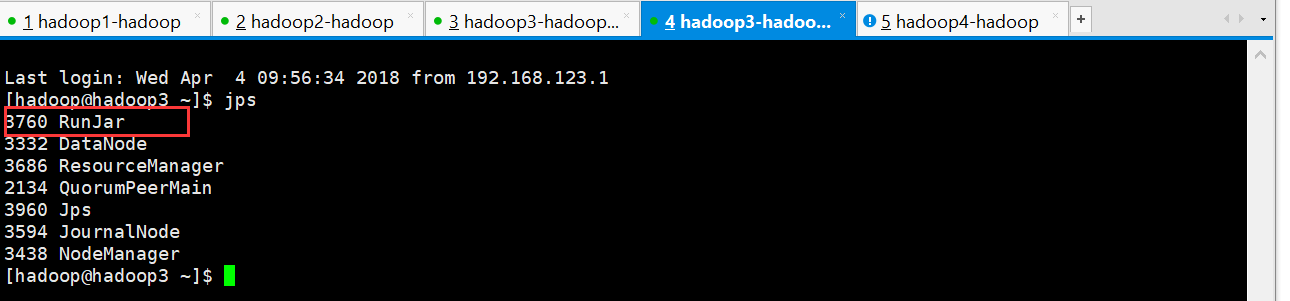
启动为后台:
nohup hiveserver2 1>/home/hadoop/hiveserver.log 2>/home/hadoop/hiveserver.err &
或者:nohup hiveserver2 1>/dev/null 2>/dev/null &
或者:nohup hiveserver2 >/dev/null 2>&1 &
以上 3 个命令是等价的,第一个表示记录日志,第二个和第三个表示不记录日志
命令中的 1 和 2 的意义分别是:
1:表示标准日志输出
2:表示错误日志输出 如果我没有配置日志的输出路径,日志会生成在当前工作目录,默认的日志名称叫做: nohup.xxx
[hadoop@hadoop3 ~]$ nohup hiveserver2 1>/home/hadoop/log/hivelog/hiveserver.log 2>/home/hadoop/log/hivelog/hiveserver.err &
[1] 4352
[hadoop@hadoop3 ~]$
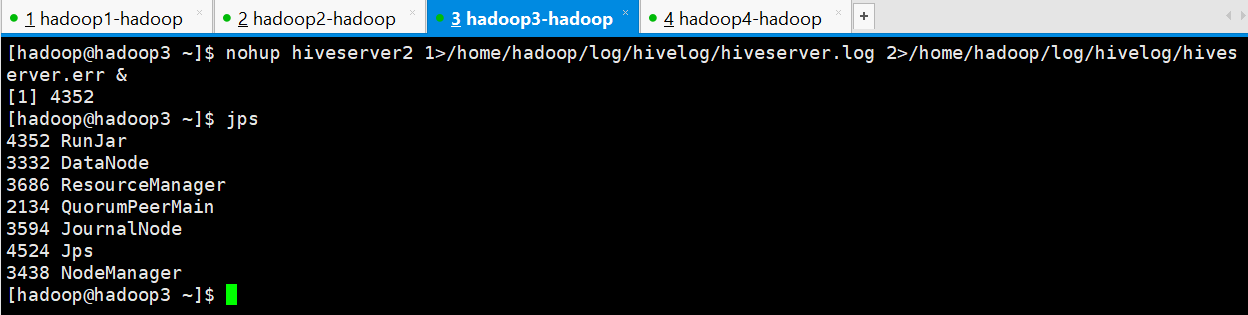
PS:nohup 命令:如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束, 那么可以使用 nohup 命令。该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。 nohup 就是不挂起的意思(no hang up)。 该命令的一般形式为:nohup command &
第二步:然后启动 beeline 客户端去连接:
执行命令:
[hadoop@hadoop3 ~]$ beeline -u jdbc:hive2//hadoop3:10000 -n hadoop
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apps/apache-hive-2.3.3-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
scan complete in 1ms
scan complete in 2374ms
No known driver to handle "jdbc:hive2//hadoop3:10000"
Beeline version 2.3.3 by Apache Hive
beeline>
-u : 指定元数据库的链接信息
-n : 指定用户名和密码
另外还有一种方式也可以去连接:
先执行 beeline
然后按图所示输入:!connect jdbc:hive2://hadoop02:10000
按回车,然后输入用户名,这个 用户名就是安装 hadoop 集群的用户名
[hadoop@hadoop3 ~]$ beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apps/apache-hive-2.3.3-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 2.3.3 by Apache Hive
beeline> !connect jdbc:hive2://hadoop3:10000
Connecting to jdbc:hive2://hadoop3:10000
Enter username for jdbc:hive2://hadoop3:10000: hadoop
Enter password for jdbc:hive2://hadoop3:10000: ******
Connected to: Apache Hive (version 2.3.3)
Driver: Hive JDBC (version 2.3.3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoop3:10000>
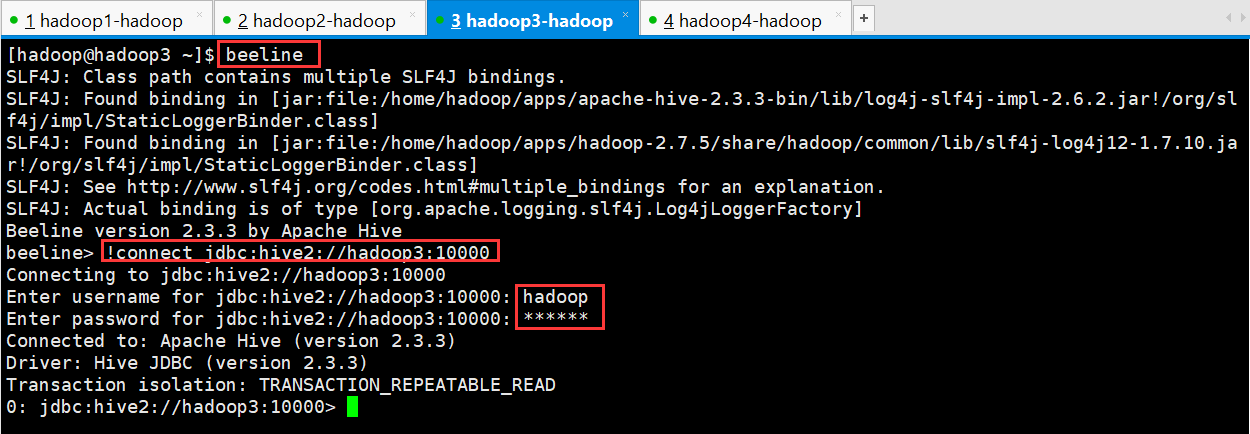
接下来便可以做 hive 操作
三、Web UI
1、 下载对应版本的 src 包:apache-hive-2.3.2-src.tar.gz
2、 上传,解压
tar -zxvf apache-hive-2.3.2-src.tar.gz
3、 然后进入目录${HIVE_SRC_HOME}/hwi/web,执行打包命令:
jar -cvf hive-hwi-2.3.2.war *
在当前目录会生成一个 hive-hwi-2.3.2.war
4、 得到 hive-hwi-2.3.2.war 文件,复制到 hive 下的 lib 目录中
cp hive-hwi-2.3.2.war ${HIVE_HOME}/lib/
5、 修改配置文件 hive-site.xml
<property>
<name>hive.hwi.listen.host</name>
<value>0.0.0.0</value>
<description>监听的地址</description>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
<description>监听的端口号</description>
</property>
<property>
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi-2.3.2.war</value>
<description>war 包所在的地址</description>
</property>
6、 复制所需 jar 包
1、cp ${JAVA_HOME}/lib/tools.jar ${HIVE_HOME}/lib
2、再寻找三个 jar 包,都放入${HIVE_HOME}/lib 目录:
commons-el-1.0.jar
jasper-compiler-5.5.23.jar
jasper-runtime-5.5.23.jar
不然启动 hwi 服务的时候会报错。
7、 安装 ant
1、 上传 ant 包:apache-ant-1.9.4-bin.tar.gz
2、 解压 tar -zxvf apache-ant-1.9.4-bin.tar.gz -C ~/apps/
3、 配置环境变量 vi /etc/profile 在最后增加两行: export ANT_HOME=/home/hadoop/apps/apache-ant-1.9.4 export PATH=$PATH:$ANT_HOME/bin 配置完环境变量别忘记执行:source /etc/profile
4、 验证是否安装成功

8、上面的步骤都配置完,基本就大功告成了。进入${HIVE_HOME}/bin 目录:
${HIVE_HOME}/bin/hive --service hwi
或者让在后台运行: nohup bin/hive --service hwi > /dev/null 2> /dev/null &
9、 前面配置了端口号为 9999,所以这里直接在浏览器中输入: hadoop02:9999/hwi
10、至此大功告成

Apache Hive (四)Hive的连接3种连接方式的更多相关文章
- [转]Apache HTTP Server 与 Tomcat 的三种连接方式介绍
首先我们先介绍一下为什么要让 Apache 与 Tomcat 之间进行连接.事实上 Tomcat 本身已经提供了 HTTP 服务,该服务默认的端口是 8080,装好 tomcat 后通过 8080 端 ...
- PostgreSQL EXPLAIN执行计划学习--多表连接几种Join方式比较
转了一部分.稍后再修改. 三种多表Join的算法: 一. NESTED LOOP: 对于被连接的数据子集较小的情况,嵌套循环连接是个较好的选择.在嵌套循环中,内表被外表驱动,外表返回的每一行都要在内表 ...
- Hive学习之路 (四)Hive的连接3种连接方式
一.CLI连接 进入到 bin 目录下,直接输入命令: [hadoop@hadoop3 ~]$ hive SLF4J: Class path contains multiple SLF4J bindi ...
- Apache HTTP Server 与 Tomcat 的三种连接方式介绍(转)
首先我们先介绍一下为什么要让 Apache 与 Tomcat 之间进行连接.事实上 Tomcat 本身已经提供了 HTTP 服务,该服务默认的端口是 8080,装好 tomcat 后通过 8080 端 ...
- Apache HTTP Server 与 Tomcat 的三种连接方式介绍
本文转载自IBM developer 首先我们先介绍一下为什么要让 Apache 与 Tomcat 之间进行连接.事实上 Tomcat 本身已经提供了 HTTP 服务,该服务默认的端口是 8080,装 ...
- 转自IBM:Apache HTTP Server 与 Tomcat 的三种连接方式介绍
http://www.ibm.com/developerworks/cn/opensource/os-lo-apache-tomcat/index.html 整合 Apache Http Server ...
- 【hive】——Hive四种数据导入方式
Hive的几种常见的数据导入方式这里介绍四种:(1).从本地文件系统中导入数据到Hive表:(2).从HDFS上导入数据到Hive表:(3).从别的表中查询出相应的数据并导入到Hive表中:(4).在 ...
- Hive四种数据导入方式介绍
问题导读 1.从本地文件系统中通过什么命令可导入数据到Hive表? 2.什么是动态分区插入? 3.该如何实现动态分区插入? 扩展: 这里可以和Hive中的三种不同的数据导出方式介绍进行对比? Hive ...
- Hive的三种安装方式(内嵌模式,本地模式远程模式)
一.安装模式介绍: Hive官网上介绍了Hive的3种安装方式,分别对应不同的应用场景. 1.内嵌模式(元数据保村在内嵌的derby种,允许一个会话链接,尝试多个会话链接时会报错) ...
随机推荐
- web 调试工具docker的安装使用
1. weinre 工具 docker run -d -p 8080:8080 beevelop/weinre 2. vorlonjs(不支持https) docker run --name v ...
- Rabbitmq的调度策略
Rabbitmq的调度策略是指Exchange在收到消息后依据什么规则把消息投到一个或多个队列中保存.它根两个因素相关:Exchange的类型和Exchange和Queue的绑定关系BindingKe ...
- 【转】一步一步教你在Ubuntu12.04搭建gstreamer开发环境
原文网址:http://blog.csdn.net/xsl1990/article/details/8333062 闲得蛋疼 无聊寂寞冷 随便写写弄弄 看到网上蛮多搭建gstreamer开 ...
- linux中控操作相关
1.首先生成无密码登陆密钥 一般使用rsa 2.编写shell脚本 work_dir=$(pwd) 3.远程拷贝 work_dir=$(pwd) ..} do ¥{host_prefix}$i:$ e ...
- J2EE项目在weblogic下的改动
1.struts所有配置文件放到classes根目录下 2〉java.lang.ClassCastException:weblogic.xml.jaxp.RegistryDocumentBuilder ...
- new String(tmp,1,nlen,"UTF8")
tmp是一个byte(字节)数组,如:['a','b','c'...],tmp[0]是去byte中的第一个,运算符&表示按位运算‘且’,就是前后值的二进制相同位有0取0,否则取1,如:2&am ...
- 如何用TortoiseSVN管理本地文档
1.安装(略) 2.搭建本地SVN版本管理数据库(服务器) (1)在本地磁盘上新建一个目录,例如E:\SVN,用来存储各种需要进行版本管理的文档:接着在该目录下再创建一个新的空目录,例如创建一个E:\ ...
- mysql innodb引擎事务的隔离级别
一.事务的基本要素(ACID) 1.原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节.事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有 ...
- ElasticSearch读取查询结果(search)
本文转载自:http://blog.csdn.net/wangxiaotongfan/article/details/46531729?locationNum=6 在es中所有的查询结果都会保存在Se ...
- Protobuff java 文件生成命令
protoc.exe -I./proto文件目录 --java_out=java文件目录 proto文件基于文件目录的全路径 protoc.exe -I./protoFolder --java_out ...