sqlserver 并发机制
一、事务四大属性
分别是原子性、一致性、隔离性、持久性。
1、原子性(Atomicity)
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
2、一致性(Consistency)
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。举例来说,假设用户A和用户B两者的钱加起来一共是1000,那么不管A和B之间如何转账、转几次账,事务结束后两个用户的钱相加起来应该还得是1000,这就是事务的一致性。
3、隔离性(Isolation)
隔离性是当多个用户并发访问数据库时,比如同时操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。关于事务的隔离性数据库提供了多种隔离级别,稍后会介绍到。
4、持久性(Durability)
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。例如我们在使用JDBC操作数据库时,在提交事务方法后,提示用户事务操作完成,当我们程序执行完成直到看到提示后,就可以认定事务已经正确提交,即使这时候数据库出现了问题,也必须要将我们的事务完全执行完成。否则的话就会造成我们虽然看到提示事务处理完毕,但是数据库因为故障而没有执行事务的重大错误。这是不允许的。
二、事务的隔离级别
1、为什么要设置隔离级别
https://blog.csdn.net/xiaokang123456kao/article/details/75268240
在数据库操作中,在并发的情况下可能出现如下问题:
脏读:一个事务读取到了另外一个事务没有提交的数据。
A修改了数据,随后B又读出该数据,但A因为某些原因取消了对数据的修改,数据恢复原值,此时B得到的数据就与数据库内的数据产生了不一致
幻读:同一事务中,用同样的操作读取两次,得到的记录数不相同。
A读取数据,随后B又插入了数据,此时A再读数据是发现前后两次获取的数据行集不一致
不可重复读:在同一事务中,两次读取同一数据,得到内容不同。
A用户读取数据,随后B用户读出该数据并修改,此时A用户再读取数据时发现前后两次的值不一致
丢失更新:事务T1读取了数据,并执行了一些操作,然后更新数据。事务T2也做相同的事,则T1和T2更新数据时可能会覆盖对方的更新,从而引起错误。
A,B两个用户读同一数据并进行修改,其中一个用户的修改结果破坏了另一个修改的结果,比如订票系统
并发控制的主要方法是通过锁,在一段时间内禁止用户做某些操作以避免产生数据不一致
1. 更新丢失(Lost update)
如果多个线程操作,基于同一个查询结构对表中的记录进行修改,那么后修改的记录将会覆盖前面修改的记录,前面的修改就丢失掉了,这就叫做更新丢失。这是因为系统没有执行任何的锁操作,因此并发事务并没有被隔离开来。
第1类丢失更新:事务A撤销时,把已经提交的事务B的更新数据覆盖了。
第2类丢失更新:事务A覆盖事务B已经提交的数据,造成事务B所做的操作丢失。
解决方法:对行加锁,只允许并发一个更新事务。
2. 脏读(Dirty Reads)
脏读(Dirty Read):A事务读取B事务尚未提交的数据并在此基础上操作,而B事务执行回滚,那么A读取到的数据就是脏数据。
解决办法:如果在第一个事务提交前,任何其他事务不可读取其修改过的值,则可以避免该问题。
3. 不可重复读(Non-repeatable Reads)
一个事务对同一行数据重复读取两次,但是却得到了不同的结果。事务T1读取某一数据后,事务T2对其做了修改,当事务T1再次读该数据时得到与前一次不同的值。
解决办法:如果只有在修改事务完全提交之后才可以读取数据,则可以避免该问题。
4. 幻象读
指两次执行同一条 select 语句会出现不同的结果,第二次读会增加一数据行,并没有说这两次执行是在同一个事务中。一般情况下,幻象读应该正是我们所需要的。但有时候却不是,如果打开的游标,在对游标进行操作时,并不希望新增的记录加到游标命中的数据集中来。隔离级别为 游标稳定性 的,可以阻止幻象读。例如:目前工资为1000的员工有10人。那么事务1中读取所有工资为1000的员工,得到了10条记录;这时事务2向员工表插入了一条员工记录,工资也为1000;那么事务1再次读取所有工资为1000的员工共读取到了11条记录。
解决办法:如果在操作事务完成数据处理之前,任何其他事务都不可以添加新数据,则可避免该问题。
2、事务的隔离级别
为了解决数据库并发问题,数据库提供了几种隔离级别。以下隔离级别由低到高。
Read uncommitted(未授权读取、读未提交): 如果一个事务已经开始写数据,则另外一个事务则不允许同时进行写操作,但允许其他事务读此行数据。该隔离级别可以通过“排他写锁”实现。这样就避免了更新丢失,却可能出现脏读。也就是说事务B读取到了事务A未提交的数据。 Read committed(授权读取、读提交): 读取数据的事务允许其他事务继续访问该行数据,但是未提交的写事务将会禁止其他事务访问该行。该隔离级别避免了脏读,但是却可能出现不可重复读。事务A事先读取了数据,事务B紧接了更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变。 Repeatable read(可重复读取): 可重复读是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,即使第二个事务对数据进行修改,第一个事务两次读到的的数据是一样的。这样就发生了在一个事务内两次读到的数据是一样的,因此称为是可重复读。读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务。这样避免了不可重复读取和脏读,但是有时可能出现幻象读。(读取数据的事务)这可以通过“共享读锁”和“排他写锁”实现。 Serializable(序列化): 提供严格的事务隔离。它要求事务序列化执行,事务只能一个接着一个地执行,但不能并发执行。如果仅仅通过“行级锁”是无法实现事务序列化的,必须通过其他机制保证新插入的数据不会被刚执行查询操作的事务访问到。序列化是最高的事务隔离级别,同时代价也花费最高,性能很低,一般很少使用,在该级别下,事务顺序执行,不仅可以避免脏读、不可重复读,还避免了幻像读。 隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。对于多数应用程序,可以优先考虑把数据库系统的隔离级别设为Read Committed。它能够避免脏读取,而且具有较好的并发性能。尽管它会导致不可重复读、幻读和第二类丢失更新这些并发问题,在可能出现这类问题的个别场合,可以由应用程序采用悲观锁或乐观锁来控制。大多数数据库的默认级别就是Read committed,比如Sql Server , Oracle。MySQL的默认隔离级别就是Repeatable read。 --------------------- 作者:想作会飞的鱼 来源:CSDN 原文:https://blog.csdn.net/xiaokang123456kao/article/details/75268240 版权声明:本文为博主原创文章,转载请附上博文链接!


* 为什么需要锁?
在并发环境下,如果多个客户端访问同一条数据,此时就会产生数据不一致的问题,如何解决,通过加锁的机制,常见的有两种锁,乐观锁和悲观锁,可以在一定程度上解决并发访问。SQLSERVER通过锁来提供ACID属性,处理并发访问.
* 什么是悲观锁?
悲观锁,正如其名,具有强烈的独占和排他特性。它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。
悲观锁主要包含共享锁和排他锁。
共享锁:又称读锁/S锁,共享锁是在执行select操作时使用的锁机制。共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
排他锁:又称写锁/X锁,排它锁是在执行update,delete等对数据有修改操作时使用的锁。排他锁就是不能与其他锁并存,如一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁,包括共享锁和排他锁,但是获取排他锁的事务是可以对数据就行读取和修改。
共享锁(S锁):用于读取资源所加的锁。拥有共享锁的资源不能被修改。共享锁默认情况下是读取了资源马上被释放。
排他锁(X锁): 和其它任何锁都不兼容,包括其它排他锁。排它锁用于数据修改,当资源上加了排他锁时,其他请求读取或修改这个资源的事务都会被阻塞,知道排他锁被释放为止。
共享锁:
T1: select * from A;(加共享锁A)
T2: select * from A;(加共享锁B)
* 什么是乐观锁?
乐观锁机制采取了更加宽松的加锁机制。乐观锁是相对悲观锁而言,也是为了避免数据库幻读、业务处理时间过长等原因引起数据处理错误的一种机制,但乐观锁不会刻意使用数据库本身的锁机制,而是依据数据本身来保证数据的正确性。
实现乐观锁一般来说有以下2种方式:
a. 使用版本号
使用数据版本(Version)记录机制实现,这是乐观锁最常用的一种实现方式。一般是在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version值会加一。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据。
b. 使用时间戳
乐观锁定的第二种实现方式和第一种差不多,同样是在需要乐观锁控制的table中增加一个字段,字段类型使用时间戳(timestamp), 和上面的version类似,也是在更新提交的时候检查当前数据库中数据的时间戳和自己更新前取到的时间戳进行对比,如果一致则OK,否则就是版本冲突。
* 悲观锁与乐观锁区别与联系?
* 悲观锁与乐观锁的使用场景?
悲观锁:比较适合写入操作比较频繁的场景,如果出现大量的读取操作,每次读取的时候都会进行加锁,这样会增加大量的锁的开销,降低了系统的吞吐量。
乐观锁:比较适合读取操作比较频繁的场景,如果出现大量的写入操作,数据发生冲突的可能性就会增大,为了保证数据的一致性,应用层需要不断的重新获取数据,这样会增加大量的查询操作,降低了系统的吞吐量。
实际生产环境里边,如果并发量不大且不允许脏读,完全可以使用悲观锁定的方法,这种方法使用起来非常方便和简单。但是如果系统的并发非常大的话,悲观锁定会带来非常大的性能问题,所以就要选择乐观锁定的方法。
悲观锁假定其他用户企图访问或者改变你正在访问、更改的对象的概率是很高的,因此在悲观锁的环境中,在你开始改变此对象之前就将该对象锁住,并且直到你提交了所作的更改之后才释放锁。悲观的缺陷是不论是页锁还是行锁,加锁的时间可能会很长,这样可能会长时间的限制其他用户的访问,也就是说悲观锁的并发访问性不好。
乐观锁则认为其他用户企图改变你正在更改的对象的概率是很小的,因此乐观锁直到你准备提交所作的更改时才将对象锁住,当你读取以及改变该对象时并不加锁。可见乐观锁加锁的时间要比悲观锁短,乐观锁可以用较大的锁粒度获得较好的并发访问性能。但是如果第二个用户恰好在第一个用户提交更改之前读取了该对象,那么当他完成了自己的更改进行提交时,数据库就会发现该对象已经变化了,这样,第二个用户不得不重新读取该对象并作出更改。这说明在乐观锁环境中,会增加并发用户读取对象的次数。
乐观锁例子:
T1:(用户A) begin tran1
T1:(用户A) select * from user where id = 3; (version=1)
T2:(用户B) begin tran2
T2:(用户B) select * from user where id = 3; (version=1)
T1:(用户A) update user set name='amy', version=version+1 where id = 3 and version = 1;(受影响的行: 1)
T2:(用户B) update user set name='tom', version=version+1 where id = 3 and version = 1;(受影响的行: 0)
T1:(用户A) end tran1
T2:(用户B) end tran2
如何查看锁
1、使用sys.dm_tran_locks这个DMV
SELECT l.request_session_id,
2 DB_NAME(l.resource_database_id),OBJECT_NAME(p.object_id),
3 l.resource_description,l.request_type,
4 l.request_status,request_mode
5 FROM sys.dm_tran_locks AS l
6 LEFT JOIN sys.partitions AS p
7 ON l.resource_associated_entity_id=p.hobt_id
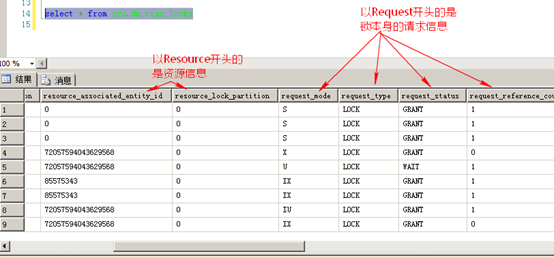
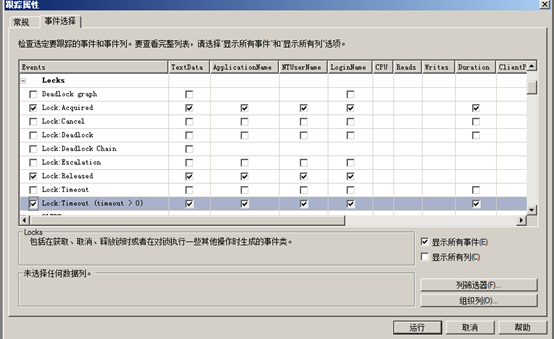
2、使用Profiler来捕捉锁信息
如何查看死锁
问题再现:使用SQL Server2008数据库,右键点击tempdb数据库,查看属性。
 步骤阅读
步骤阅读- 2
有时会弹出错误提示框:已超过了锁请求超时时段。 (Microsoft SQL Server,错误: 1222)
- 3
通过SQL命令行,查看是否有死锁进程,具体命令如图所示,其中【tempdb】是要访问的数据库名。经过查询,得知存在一个死锁进程【2973】,占用了资源,使正常的请求无法得到及时响应。
- 4
执行Kill进程命令,解锁进程,释放资源,具体代码如图所示。
- 5
执行完kill进程命令后,再查询一次进程,发现无死锁进程。数据库访问恢复正常。

 步骤阅读
步骤阅读 步骤阅读
步骤阅读 步骤阅读
步骤阅读

三、死锁的预防与优化
预防死锁
预防死锁就是破坏四个必要条件中的某一个和几个,使其不能形成死锁。有如下几种办法:
1)破坏互斥条件
破坏互斥条件有比较严格的限制,在SQL Server中,如果业务逻辑上允许脏读,则可以通过将隔离等级改为未提交读或使用索引提示。这样使得读取不用加S锁,从而避免了和其它查询所加的与S锁不兼容的锁互斥,进而减少了死锁出现的概率。
2)破坏请求和等待条件
这点由于事务存在原子性,是不可破坏的,因为解决办法是尽量的减少事务的长度,事务内执行的越快越好。这也可以减少死锁出现的概率。
3)破坏不剥夺条件
由于事务的原子性和一致性,不剥夺条件同样不可破坏。但我们可以通过增加资源和减少资源占用两个角度来考虑。
增加资源:比如说通过建立非聚集索引,使得有了额外的资源,查询很多时候就不再索要锁基本表,转而锁非聚集索引,如果索引能够"覆盖(Cover)"查询,那更好不过。因此索引Include列不仅仅减少书签查找来提高性能,还能减少死锁。
减少资源占用:比如说查询时,能用select col1,col2这种方式,就不要用select * .这有可能带来不必要的书签查找
最大限度减少死锁的方法
- 按同一顺序访问对象: 按同一顺序访问对象也就是:第一个事务提交或回滚后,第二个事务继续进行,这样不会发生死锁。
- 避免事务中的用户交互: 避免编写包含用户交互的事务,因为运行没有用户交互的批处理的速度要远远快于用户手动响应查询的速度,例如答复应用程序请求参数的提示。例如,如果事务正在等待用户输入,而用户去吃午餐了或者甚至回家过周末了,则用户将此事务挂起使之不能完成。这样将降低系统的吞吐量,因为事务持有的任何锁只有在事务提交或回滚时才会释放。即使不出现死锁的情况,访问同一资源的其它事务也会被阻塞,等待该事务完成。
- 保持事务简短并在一个批处理中: 在同一数据库中并发执行多个需要长时间运行的事务时通常发生死锁。事务运行时间越长,其持有排它锁或更新锁的时间也就越长,从而堵塞了其它活动并可能导致死锁。 保持事务在一个批处理中,可以最小化事务的网络通信往返量,减少完成事务可能的延迟并释放锁。
- 使用低隔离级别: 确定事务是否能在更低的隔离级别上运行,执行提交读取允许事务读取另一个事务已读取(未修改)的数据,而不必等待第一个事务完成。使用较低的隔离级别(例如提交读取)而不使用较高的隔离级别(例如可串行读)可以缩短持有共享锁的时间,从而降低了锁定争夺。
- 使用绑定连接: 使用绑定连接使同一应用程序所打开的两个或多个连接可以相互合作。次级连接所获得的任何锁可以象由主连接获得的锁那样持有,反之亦然,因此不会相互阻塞。
按照同一顺序访问数据库资源,上述例子就不会发生死锁啦
- 保持是事务的简短,尽量不要让一个事务处理过于复杂的读写操作。事务过于复杂,占用资源会增多,处理时间增长,容易与其它事务冲突,提升死锁概率。
- 尽量不要在事务中要求用户响应,比如修改新增数据之后在完成整个事务的提交,这样延长事务占用资源的时间,也会提升死锁概率。
- 尽量减少数据库的并发量。
- 尽可能使用分区表,分区视图,把数据放置在不同的磁盘和文件组中,分散访问保存在不同分区的数据,减少因为表中放置锁而造成的其它事务长时间等待。
- 避免占用时间很长并且关系表复杂的数据操作。
- 使用较低的隔离级别,使用较低的隔离级别比使用较高的隔离级别持有共享锁的时间更短。这样就减少了锁争用。
优化死锁的一些建议
(1)对于查询频繁的表尽量使用聚集索引;
(2)设法避免一次性影响大量记录的SQL语句,特别是INSERT和UPDATE语句;
(3)设法让UPDATE和DELETE语句使用合适的索引;
(4)使用嵌套事务时,避免提交和回退冲突;
(5)对数据一致性要求不高的查询使用 WITH(NOLOCK)
(6)减小事务的体积,事务应最晚开启,最早关闭,所有不是必须使用事务的操作必须放在事务外。
(7)查询只返回你需要的列,不建议使用 SELECT * FROM 这种写法。
参考文章: http://www.matools.com/blog/190438028
---------------------
作者:想作会飞的鱼
来源:CSDN
原文:https://blog.csdn.net/xiaokang123456kao/article/details/75268240
版权声明:本文为博主原创文章,转载请附上博文链接!
sqlserver 并发机制的更多相关文章
- (第二章)Java并发机制的底层实现原理
一.概述 Java代码在编译后会变成Java字节码,字节码被类加载器加载到JVM里,JVM执行字节码,最终需要转化为汇编指令在CPU上执行,Java中所使用的并发机制依赖于JVM的实现和CPU的指令. ...
- storm的并发机制
storm的并发机制 storm计算支持在多台机器上水平扩容,通过将计算切分为多个独立的tasks在集群上并发执行来实现. 一个task可以简单地理解:在集群某节点上运行的一个spout或者bolt实 ...
- 【Java基础】线程和并发机制
前言 在Java中,线程是一个很关键的名词,也是很高频使用的一种资源.那么它的概念是什么呢,是如何定义的,用法又有哪些呢?为何说Android里只有一个主线程呢,什么是工作线程呢.线程又存在并发,并发 ...
- Go语言并发机制初探
Go 语言相比Java等一个很大的优势就是可以方便地编写并发程序.Go 语言内置了 goroutine 机制,使用goroutine可以快速地开发并发程序, 更好的利用多核处理器资源.这篇文章学习 g ...
- Storm并发机制详解
本文可作为 <<Storm-分布式实时计算模式>>一书1.4节的读书笔记 在Storm中,一个task就可以理解为在集群中某个节点上运行的一个spout或者bolt实例. 记住 ...
- 第二十节: 深入理解并发机制以及解决方案(锁机制、EF自有机制、队列模式等)
一. 理解并发机制 1. 什么是并发,并发与多线程有什么关系? ①. 先从广义上来说,或者从实际场景上来说. 高并发通常是海量用户同时访问(比如:12306买票.淘宝的双十一抢购),如果把一个用户看做 ...
- 《Java并发编程的艺术》Java并发机制的底层实现原理(二)
Java并发机制的底层实现原理 1.volatile volatile相当于轻量级的synchronized,在并发编程中保证数据的可见性,使用 valotile 修饰的变量,其内存模型会增加一个 L ...
- python进阶(一) 多进程并发机制
python多进程并发机制: 这里使用了multprocessing.Pool进程池,来动态增加进程 #coding=utf-8 from multiprocessing import Pool im ...
- 那些年读过的书《Java并发编程的艺术》一、并发编程的挑战和并发机制的底层实现原理
一.并发编程的挑战 1.上下文切换 (1)上下文切换的问题 在处理器上提供了强大的并行性就使得程序的并发成为了可能.处理器通过给不同的线程分配不同的时间片以实现线程执行的自动调度和切换,实现了程序并行 ...
随机推荐
- 实践作业4:Web测试----细化分工DAY1.
会议时间:2017年12月23日 会议地点:东九教学楼教师休息室 主持人:吴辉 参会人员:吴辉.刘思佳.郜昌磊.王俊杰.吴慧杰 记录人:刘思佳 会议议题:本次作业的分工以及初期安排 工具选择 软件测试 ...
- ios7 - Custom UItabbar has a gap in the bottom
3down votefavorite Im trying to create a custom UITabbar using images for the selected and unselec ...
- 编写高质量代码改善C#程序的157个建议——建议79:使用ThreadPool或BackgroundWorker代替Thread
建议79:使用ThreadPool或BackgroundWorker代替Thread 使用线程能极大地提升用户体验度,但是作为开发者应该注意到,线程的开销是很大的. 线程的空间开销来自: 1)线程内核 ...
- 《FilthyRichClients》读书笔记(一)-SwingのEDT
<FilthyRichClients>读完了前几个章节,现将我的体会结合工作以来从事Swing桌面开发的经验,对本书的一些重要概念进行一次 分析,对书中的一些遗漏与模糊的地方及时补充,同时 ...
- 解决Hbuilder打包的apk文件按手机返回键直接退出软件
问题描述:Hbuilder打包的app如果点击手机返回键,app会直接退出,返回不了上一页. 写在公共js文件中,每个页面均引入该js,代码如下: document.addEventListener( ...
- EasyUI combobox动态增加选择项
有需求需要动态的为combobox增加可选项,后来解决方案如下 html如下 <select id="workerList"></select> js 如下 ...
- Verilog MIPS32 CPU(一)-- PC寄存器
Verilog MIPS32 CPU(一)-- PC寄存器 Verilog MIPS32 CPU(二)-- Regfiles Verilog MIPS32 CPU(三)-- ALU Verilog M ...
- Backup--清理MSDB中的备份记录
每次数据库备份或日志备份,都会向msdb中多多张表插入数据,如果备份比较频繁的话,需要定期清理. 使用sp_delete_backuphistory来清理以下表中数据: backupfile back ...
- 2018.11-2019.1的随记|NOIP的考后随记
就是日记吧?(这里就是写一些乱七八糟的东西qwq,当作自己的零散想念吧 1.24 今天跟着BLUESKY他们的视频一起领略了一下远在广州的CCF冬令营开幕式,看着ljh的拍的照片也体验了一下RM冬令营 ...
- 【OCP-12c】CUUG最新考试原题整理及答案(071-11)
11.(5-8) choose the best answer: Examine the structure of the BOOKS_TRANSACTIONS table. You want to ...