Kafka - SQL 引擎
Kafka - SQL 引擎分享
1.概述
大多数情况下,我们使用 Kafka 只是作为消息处理。在有些情况下,我们需要多次读取 Kafka 集群中的数据。当然,我们可以通过调用 Kafka 的 API 来完成,但是针对不同的业务需求,我们需要去编写不同的接口,在经过编译,打包,发布等一系列流程。最后才能看到我们预想的结果。那么,我们能不能有一种简便的方式去实现这一部分功能,通过编写 SQL 的方式,来可视化我们的结果。今天,笔者给大家分享一些心得,通过使用 SQL 的形式来完成这些需求。
2.内容
实现这些功能,其架构和思路并不复杂。这里笔者将整个实现流程,通过一个原理图来呈现。如下图所示:

这里笔者给大家详述一下上图的含义,消息数据源存放与 Kafka 集群当中,开启低阶和高阶两个消费线程,将消费的结果以 RPC 的方式共享出去(即:请求者)。数据共享出去后,回流经到 SQL 引擎处,将内存中的数据翻译成 SQL Tree,这里使用到了 Apache 的 Calcite 项目来承担这一部分工作。然后,我们通过 Thrift 协议来响应 Web Console 的 SQL 请求,最后将结果返回给前端,让其以图表的实行可视化。
3.插件配置
这里,我们需要遵循 Calcite 的 JSON Models,比如,针对 Kafka 集群,我们需要配置一下内容:

{
version: '1.0',
defaultSchema: 'kafka',
schemas: [
{
name: 'kafka',
type: 'custom',
factory: 'cn.smartloli.kafka.visual.engine.KafkaMemorySchemaFactory',
operand: {
database: 'kafka_db'
}
}
]
}
另外,这里最好对表也做一个表述,配置内容如下所示:
[
{
"table":"Kafka",
"schemas":{
"_plat":"varchar",
"_uid":"varchar",
"_tm":"varchar",
"ip":"varchar",
"country":"varchar",
"city":"varchar",
"location":"jsonarray"
}
}
]
4.操作
下面,笔者给大家演示通过 SQL 来操作相关内容。相关截图如下所示:
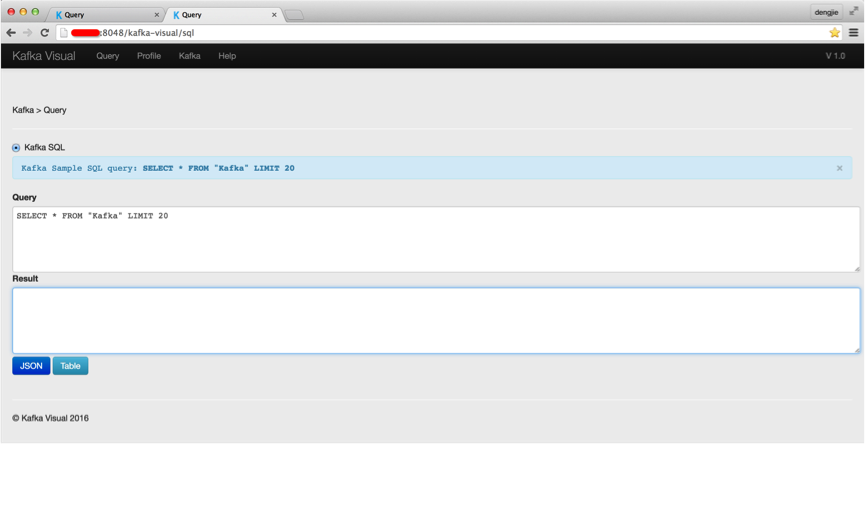
在查询处,填写相关 SQL 查询语句。点击 Table 按钮,得到如下所示结果:

我们,可以将获取的结果以报表的形式进行导出。
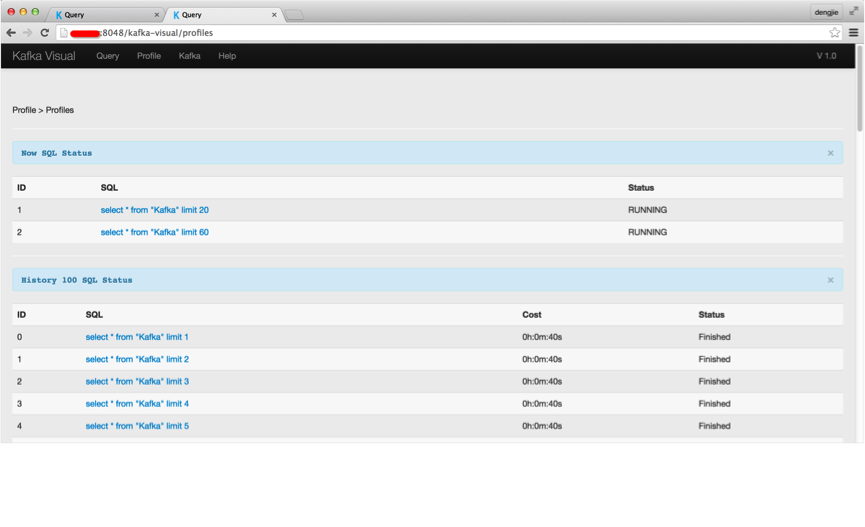
当然,我们可以在 Profile 模块下,浏览查询历史记录和当前正在运行的查询任务。至于其他模块,都属于辅助功能(展示集群信息,Topic 的 Partition 信息等)这里就不多赘述了。
5.总结
分析下来,整体架构和实现的思路都不算太复杂,也不存在太大的难点,需要注意一些实现上的细节,比如消费 API 针对集群消息参数的调整,特别是低阶消费 API,尤为需要注意,其 fetch_size 的大小,以及 offset 是需要我们自己维护的。在使用 Calcite 作为 SQL 树时,我们要遵循其 JSON Model 和标准的 SQL 语法来操作数据源。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
邮箱:smartdengjie@gmail.com
QQ群(Hadoop - 董的博客2):306184597 (已满)
QQ群(Hadoop - 交流社区1):424769183
温馨提示:请大家加群的时候写上加群理由(姓名+公司/学校),方便管理员审核,谢谢!
热爱生活,享受编程,与君共勉!
作者:哥不是小萝莉
Kafka - SQL 引擎的更多相关文章
- Kafka - SQL 引擎分享
1.概述 大多数情况下,我们使用 Kafka 只是作为消息处理.在有些情况下,我们需要多次读取 Kafka 集群中的数据.当然,我们可以通过调用 Kafka 的 API 来完成,但是针对不同的业务需求 ...
- Kafka - SQL 代码实现
1.概述 上次给大家分享了关于 Kafka SQL 的实现思路,这次给大家分享如何实现 Kafka SQL.要实现 Kafka SQL,在上一篇<Kafka - SQL 引擎分享>中分享了 ...
- 重磅开源 KSQL:用于 Apache Kafka 的流数据 SQL 引擎 2017.8.29
Kafka 的作者 Neha Narkhede 在 Confluent 上发表了一篇博文,介绍了Kafka 新引入的KSQL 引擎——一个基于流的SQL.推出KSQL 是为了降低流式处理的门槛,为处理 ...
- DRDS分布式SQL引擎—执行计划介绍
摘要: 本文着重介绍 DRDS 执行计划中各个操作符的含义,以便用户通过查询计划了解 SQL 执行流程,从而有针对性的调优 SQL. DRDS分布式SQL引擎 — 执行计划介绍 前言 数据库系统中,执 ...
- 六大主流开源SQL引擎
导读 本文涵盖了6个开源领导者:Hive.Impala.Spark SQL.Drill.HAWQ 以及Presto,还加上Calcite.Kylin.Phoenix.Tajo 和Trafodion.以 ...
- 六大主流开源SQL引擎总结
本文涵盖了6个开源领导者:Hive.Impala.Spark SQL.Drill.HAWQ 以及Presto,还加上Calcite.Kylin.Phoenix.Tajo 和Trafodion.以及2个 ...
- 大数据时代快速SQL引擎-Impala
背景 随着大数据时代的到来,Hadoop在过去几年以接近统治性的方式包揽的ETL和数据分析查询的工作,大家也无意间的想往大数据方向靠拢,即使每天数据也就几十.几百M也要放到Hadoop上作分析,只会适 ...
- Oracle 高性能SQL引擎剖析----执行计划
执行计划是指示Oracle如何获取和过滤数据.产生最终结果集,是影响SQL语句执行性能的关键因素.我们在深入了解执行计划之前,首先需要知道执行计划是在什么时候产生的,以及如何让SQL引擎为语句生成执行 ...
- 转:大数据时代快速SQL引擎-Impala
本文来自:http://blog.csdn.net/yu616568/article/details/52431835 如有侵权 可立即删除 背景 随着大数据时代的到来,Hadoop在过去几年以接近统 ...
随机推荐
- delphi中左右翻转窗体(修改EXStyle)
unit Unit1; interface uses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Form ...
- 基于visual Studio2013解决面试题之0602全排列
题目
- 基于visual Studio2013解决C语言竞赛题之1087数字变换
题目 解决代码及点评 /************************************************************************/ /* ...
- 通过判断浏览器的userAgent,用正则来判断是否是ios和Android客户端
<script type="text/javascript">var u = navigator.userAgent, app = navigator.appVersi ...
- 注解在android中的使用
注解在android程序中的使用 何为注解: 在Java其中,注解又叫做"元数据",它为我们在源码中加入信息提供了一种形式化的方法.让我们能在以后的某个时间方便的使用这些数据.更确 ...
- 也谈C#之Json,从Json字符串到类代码
原文:也谈C#之Json,从Json字符串到类代码 阅读目录 json转类对象 逆思考 从json字符串自动生成C#类 json转类对象 自从.net 4.0开始,微软提供了一整套的针对json进 ...
- 我是如何同时拿到阿里和腾讯offer的
前言 三月真是一个忙碌的季节,刚刚开学就需要准备各种面试和笔试(鄙视).幸运的是,在长达一个月的面试内推季之后,终于同时拿到了阿里和腾讯的offer,还是挺开心的.突而想起久未更新的博客,就冒昧学一学 ...
- sql语句查询添加自增列
SELECT Row_Number() over ( order by getdate() ) as '序号', * FROM T_Cod_XQ
- POJ 3321 Apple Tree DFS序+fenwick
题目大意:有一颗长满苹果的苹果树,有两个操作. 1.询问以一个点为根的子树中有多少个苹果. 2.看看一个点有没有苹果,假设没有苹果.那么那里就立即长出一个苹果(= =!):否则就把那个苹果摘下来. 思 ...
- mysql高可用架构方案之二(keepalived+lvs+读写分离+负载均衡)
mysql主从复制与lvs+keepalived实现负载高可用 文件夹 1.前言 4 2.原理 4 2.1.概要介绍 4 2.2.工作原理 4 2.3.实际作用 4 3方 ...