[数据结构]Splay简介
Splay树,又叫伸展树,可以实现快速分裂合并一个序列,几乎可以完成平衡树的所有操作。其中最重要的操作是将指定节点伸展到指定位置,
节点定义
一棵普通的splay并不需要什么太多的附加数据,就像下面这样就好:
template<typename T>
class SplayNode {
public:
T data;
SplayNode* next[];
SplayNode* father;
SplayNode(){
memset(next, , sizeof(next));
}
SplayNode(T data, SplayNode* father):data(data), father(father){
memset(next, , sizeof(next));
}
int cmp(T a){
if(a == data) return -;
return (a > data) ? () : ();
}
};
伸展操作
伸展操作有三种情况,分为单旋转(一种情况)和双旋转(二种情况)
当伸展的节点的父节点为目标位置,那么只需要一次旋转就可以完成。和这个方向相反(如果为左子树,就右旋)
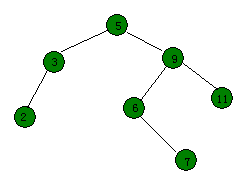
例如将开篇那张图中键值为3的点,伸展到根。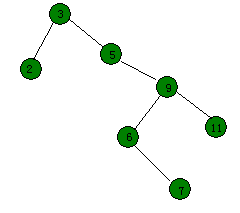
- 要伸展的节点的父节点和祖父节点共线,则先将父节点转上去,再将该节点转上去,例如上图,将键值为9的节点伸展到根。
- 第三种情况是要伸展的节点的父节点和祖父节点不共线(呈"之"字),此时先将该节点连续旋转两次达到祖父节点的位置。例如将第一张图的键值为6的节点伸展到根。

基本所有题目的数据范围都不至于使一次单旋转或双旋转就能够解决,所以实际中是通过三种情况组合进行伸展。
比如说将某个深度较深的节点伸展到根,会发现不光是这个节点的深度更小了(更浅),很多其它节点也有所受益。最坏的情况是O(n)(从小到大的数据中最小的一个伸展到根),最好的情况O(1)(刚好是父节点的直接的某个子树),平均是O(log2n)(我也不知道怎么算的,反正实际用起来绝对比这个慢,或者说常数很大,因为Splay不像AVL树和红黑树那样特别平衡)。
您可以考虑在插入、查找的过程中把结果伸展到根。
下面是代码:
inline void splay(SplayNode<T>* node, SplayNode<T>* father){
while(node->father != father){
SplayNode<T>* f = node->father;
int fd = f->cmp(node->data);
SplayNode<T>* ff = f->father;
if(ff == father){
rotate(f, fd ^ );
break;
}
int ffd = ff->cmp(f->data);
if(ffd == fd){
rotate(ff, ffd ^ );
rotate(f, fd ^ );
}else{
rotate(f, fd ^ );
rotate(ff, ffd ^ );
}
}
if(father == NULL)
root = node;
}
插入操作
Splay的插入操作很简单,按照BST的性质插进去,然后伸展到根。
//实际过程
static SplayNode<T>* insert(SplayNode<T>*& node, SplayNode<T>* father, T data){
if(node == NULL){
node = new SplayNode<T>(data, father);
return node;
}
int d = node->cmp(data);
if(d == -) return NULL;
return insert(node->next[d], node, data);
} //用户调用
inline SplayNode<T>* insert(T data){
SplayNode<T>* res = insert(root, NULL, data);
if(res != NULL) splay(res, NULL);
return res;
}
删除操作
虽然Treap的删除貌似在这也可以借鉴一下,但是还是希望用到splay函数。
比如开始那张图,要删除键值为7的节点,那么先把它伸展到根:
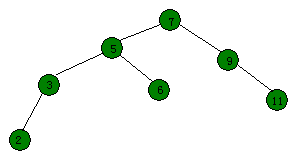
如果某棵子树为空,那么直接删掉就好了,然后改下root。
先假设键值为6的节点不存在,那么直接用键值为5的节点来代替根节点就好了。可是事实上有键值为6的节点。那么想一种情况根节点的左子树的右子树为空的情况。很巧根据BST的性质(设根节点为x,根节点的左子树为y,y的右子树为z),那么x > z > y。如果不存在z,也就是说y是x的前驱(小于x且最大的数)。
根据前驱的定义,可以写出一下找根节点的前驱的代码。
SplayNode<T>* maxi = re->next[];
while(maxi->next[] != NULL) maxi = maxi->next[];
找到前驱然后伸展到根节点的左子树。最后的结果图:

实际应用时通常会加入永远都不可能被删掉的最小的一个节点(哨兵节点),这样根就不存在要删的节点的左子树为空的情况。所以可以省下一些代码。
代码:
inline boolean remove(T data){
SplayNode<T>* re = find(data);
if(re == NULL) return false;
SplayNode<T>* maxi = re->next[];
if(maxi == NULL){
root = re->next[];
if(re->next[] != NULL) re->next[]->father = NULL;
delete re;
return true;
}
while(maxi->next[] != NULL) maxi = maxi->next[];
splay(maxi, re);
maxi->next[] = re->next[];
if(re->next[] != NULL) re->next[]->father = maxi;
maxi->father = NULL;
delete re;
root = maxi;
return true;
}
前驱后继操作
首先把要求前驱或后继的节点伸展到根。然后很容易就想到。
inline SplayNode<T>* findPre(SplayNode<T>* node) {
if(node != root) splay(node, NULL);
SplayNode<T>* s = node->next[];
while(s != NULL && s->next[] != NULL) s = s->next[];
return s;
}
inline SplayNode<T>* findSuf(SplayNode<T>* node) {
if(node != root) splay(node, NULL);
SplayNode<T>* s = node->next[];
while(s != NULL && s->next[] != NULL) s = s->next[];
return s;
}
如果不是该树内的节点,后继用upper_bound,前驱就用自创的less_bound。思路和upper_bound差不多。
static SplayNode<T>* less_bound(SplayNode<T>*& node, T val){
if(node == NULL) return node;
int to = node->cmp(val);
if(val == node->data) to = ;
SplayNode<T>* ret = less_bound(node->next[to], val);
return (ret == NULL && node->data < val) ? (node) : (ret);
}
SplayNode<T>* less_bound(T data){
SplayNode<T>* p = less_bound(root, data);
if(p != NULL)
splay(p, NULL);
return p;
}
可重Splay
·节点定义
既然让Splay支持重复的内容,那么就要加入一个count。因为根据BST的性质,新加入的重复的节点,放哪都会破坏性质(因为都是大于或小于),所以只好加在原先节点的头上
template<typename T>
class SplayNode {
public:
T data;
int count; //这里
SplayNode* next[];
SplayNode* father;
SplayNode(){
9 memset(next, , sizeof(next));
}
SplayNode(T data, SplayNode* father):data(data), father(father), count(){
memset(next, , sizeof(next));
}
int cmp(T a){
if(a == data) return -;
return (a > data) ? () : ();
}
void addCount(int val){ //这里
this->count += val;
}
};
·插入 & 删除操作
插入特判是否有重复的键值,删除特判count为0.(即是否需要移除节点)
名次操作
要进行名次操作(K小值和x的排名)对于一个节点,要做到O(log2n) 就要想办法通过某些手段不做一些无用的访问。这时可以考虑加入一个s(size)附加数据,记录该子树上的节点(数据,包括重复的内容)个数。
而且旋转后某些节点的s需要改变,所以需要一个维护s的函数
template<typename T>
class SplayNode {
public:
T data;
int s; //这里
int count;
SplayNode* next[];
SplayNode* father;
//.......
void maintain(){ //这里
s = count;
for(int i = ; i < ; i++)
if(next[i] != NULL)
s += next[i]->s;
}
void addCount(int val){
this->s += val;
this->count += val; //这里
}
};
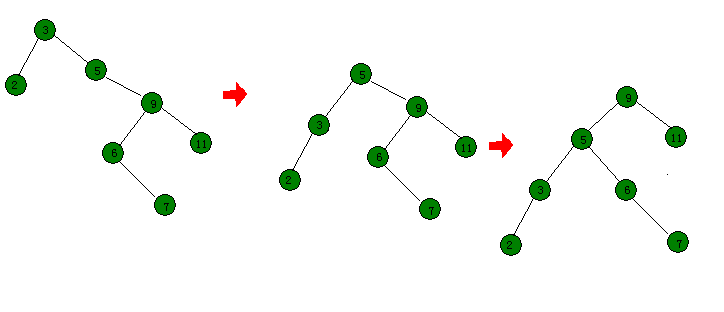
旋转时,如何确定待维护节点?先看一下下图(怎么感觉两张图都有在树链剖分)

由此可以得出规律,旧的"根节点"和新的"根节点"需要维护。
inline static void rotate(SplayNode<T>*& node, int d){
//.......
node->maintain();
node->father->maintain();
}
首先来说求K小值吧,从根节点开始访问(这不是废话吗),然后确定左子树的个数ls,如果左子树为空,那么就记为0。
很容易就能想到一个节点的左子树的个数为ls个,那么以这个节点为根的树上,根的排名是(ls + 1)名。于是我们可以得出递归的边界(写成while也行)
if(k >= ls + && k <= ls + node->count) return node;
如果访问左子树(k <= ls),那么没有什么特别的。但是如果访问右子树,你现在要求的右子树上的第某小值,而k是对于当前的node来说,所以应该减去s和node->count。
K小值代码:
static SplayNode<T>* findKth(SplayNode<T>*& node, int k){
int ls = (node->next[] != NULL) ? (node->next[]->s) : ();
if(k >= ls + && k <= ls + node->count) return node;
if(k <= ls) return findKth(node->next[], k);
return findKth(node->next[], k - ls - node->count);
}
inline SplayNode<T>* findKth(int k){
if(k <= || k > root->s) return NULL;
SplayNode<T>* p = findKth(root, k);
splay(p, NULL);
return p;
}
求x的排名就很简单了。还是访问,比当前节点小,访问左子树,相等返回r + 1,否则访问右子树,r加上当前节点的左子树的大小和count。如果访问到了NULL,返回r + 1。
为什么返回的都是r + 1呢?
因为加的左子树的大小等都是确定比它小的节点的个数。
下面是代码:
inline int rank(T data){
SplayNode<T>* p = root;
int r = ;
while(p != NULL){
int ls = (p->next[] != NULL) ? (p->next[]->s) : ();
if(p->data == data) return r + ls + ;
int d = p->cmp(data);
if(d == ) r += ls + p->count;
p = p->next[d];
}
return r + ;
}
区间操作
·split(int from, int end)
从原树中分离出一段区间[from, end]。
和之前删除的思想一样,调用splay函数使某个(没错,就是一个)特定的子树就是这一个区间。这里不好想,我就直接说吧。
/*
* 先找到第(end + 1)名,然后伸展到根,然后找到(from - 1)名,伸展到根的左子树。然后根的左子树的右子树就是这个区间了。
* 当然(end + 1)和(from - 1)都不一定会存在,所以特判或者加入哨兵节点。
*/
SplayNode<T>* split(int from, int end){
if(from > end) return NULL;
if(from == && end == root->s){
findKth(, NULL);
return this->root;
}
if(from == ){
findKth(end + , NULL);
findKth(from, root);
return root->next[];
}
if(end == root->s){
findKth(from - , NULL);
findKth(end, root);
return root->next[];
}
findKth(end + , NULL);
findKth(from - , root);
return root->next[]->next[];
}
分离区间
不过通常都需要用Splay来处理字符串等,这些是按照数组下标来建立Splay。翻转也是家常便饭,因此只能靠访问的顺序来当成"下标"(翻转后很难修改记录的下标)。
至于翻转操作就打lazy标记,然后建立一个pushDown()函数
void pushDown(){
swap(next[], next[]);
for(int i = ; i < ; i++)
if(next[i] != NULL)
next[i]->lazy ^= ;
lazy = false;
}
就像这样,很多区间操作都可以做。
[数据结构]Splay简介的更多相关文章
- [数据结构]Treap简介
[写在前面的话] 如果想学Treap,请先了解BST和BST的旋转 二叉搜索树(BST)(百度百科):[here] 英文好的读者可以戳这里(维基百科) 自己的博客:关于旋转(很水,顶多就算是了解怎么旋 ...
- 省选算法学习-数据结构-splay
于是乎,在丧心病狂的noip2017结束之后,我们很快就要迎来更加丧心病狂的省选了-_-|| 所以从写完上一篇博客开始到现在我一直深陷数据结构和网络流的漩涡不能自拔 今天终于想起来写博客(只是懒吧.. ...
- Python数据分析 Pandas模块 基础数据结构与简介(一)
pandas 入门 简介 pandas 组成 = 数据面板 + 数据分析工具 poandas 把数组分为3类 一维矩阵:Series 把ndarray强大在可以存储任意数据类型可以专门处理时间数据 二 ...
- 数据结构(Splay平衡树):HDU 1890 Robotic Sort
Robotic Sort Time Limit: 6000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Tota ...
- 数据结构(Splay平衡树):COGS 339. [NOI2005] 维护数列
339. [NOI2005] 维护数列 时间限制:3 s 内存限制:256 MB [问题描述] 请写一个程序,要求维护一个数列,支持以下 6 种操作:(请注意,格式栏 中的下划线‘ _ ’表示实际 ...
- redis的5种数据结构的简介
5种数据结构 1.字符串 Redis 字符串是一个字节序列.在 Redis 中字符串是二进制安全的,这意味着它们没有任何特殊终端字符来确定长度,所以可以存储任何长度为 512 兆的字符串. 示例 12 ...
- Splay简介
Splay树,又叫伸展树,可以实现快速分裂合并一个序列,几乎可以完成平衡树的所有操作.其中最重要的操作是将指定节点伸展到指定位置, 目录 节点定义 旋转操作 伸展操作 插入操作 删除操作 lower_ ...
- 基本数据结构 -- 栈简介(C语言实现)
栈是一种后进先出的线性表,是最基本的一种数据结构,在许多地方都有应用. 一.什么是栈 栈是限制插入和删除只能在一个位置上进行的线性表.其中,允许插入和删除的一端位于表的末端,叫做栈顶(top),不允许 ...
- Python数据分析 Pandas模块 基础数据结构与简介(二)
重点方法 分组:groupby('列名') groupby(['列1'],['列2'........]) 分组步骤: (spiltting)拆分 按照一些规则将数据分为不同的组 (Applying)申 ...
随机推荐
- 【Machine Learning in Action --1】机器学习入门指南
摘自:http://www.jianshu.com/p/c3634a7f2320 机器学习算法 Coursera 上面 Stanford 的 机器学习 课程是优质的算法相关入门课程.Andrew Ng ...
- Linux系统的时区和时间调整
linux调整系统时区: 1)tzselect命令 找到相应的时区文件/usr/share/zoneinfo/Asia/Shanghai,用这个文件替换当前的/etc/localtime文件. 或者 ...
- linux expr命令参数及用法详解
expr用法 expr命令一般用于整数值,但也可用于字符串.一般格式为: #expr argument operator argument expr也是一个手工命令行计数器. #$expr 10 + ...
- kafuka常用的shell命令
kafka常用shell命令: ------------------------------------ 1.创建topic bin/kafka-topics.sh --create --zookee ...
- iOS \'The sandbox is not sync with the Podfile.lock\'问题解决
iOS \'The sandbox is not sync with the Podfile.lock\'问题解决 HUANGDI 发表于 2015-02-27 09:51:13 问题描述: gith ...
- springMVC中ajax的运用于注意事项
ajax的运用: 注意事项: dataType:"json"在ajax中可写可不写(ajax能够自动识别返回值类型),写了更加规范,可以在ajax识别错误返回值类型的时候,指定返回 ...
- WPF中CheckBox三种状态打勾打叉和滑动效果
本文分为两个demo, 第一个demo实现checkBox的打叉或打勾的效果: 第二个demo部分实现checkBox的滑动效果. Demo1: wpf的CheckBox支持三种状态,但是美中不足的是 ...
- Openlays 3 绘制基本图形
<body> <div id="menu"> <label>几何图形类型:</label> <select id=" ...
- How to Iterate Over a Map in Java?(如何遍历Map)
1.Iterate through the "entrySet" like so: public static void printMap(Map mp) { Iterator i ...
- Object对象
1.Object类:所有类的根类.是不断抽取而来的,具备所有对象都具有的共性内容.其中的方法,任何对象都可以调用.继承而来的. equals()方法: Object类的equals源码:比较两个对象是 ...