2015 CCC - 02 找不匹配
照例传送门CNUOJ - 0385:http://oj.cnuschool.org.cn/oj/home/problem.htm?problemID=355
题目分析:首先感谢”数据结构与算法“群群友的支持与鼓励,没有你们的点拨&鼓励我不可能搞出来的。
这道题如果是暴力枚举循环节的话,可能数据会坑你一下……(只有一个循环节即两数互质= =)那就挂了……暴力好像也能拿30分吧。
这道题算法的雏形是Kael大神弄出来的,他是这么跟我说的:
假设是|T|>|S|,因为|A|=|B|,所以S与T的比较周期有|T|个,再检查S中的每个字符与T中字符不一样的个数,就得到所有周期比较完后的个数,然后把S中每个字符的个数加起来就是答案,如果|A|大于了|T|和|S|的最小公倍数,就把答案乘以M/|T|,M/|T|又是新一轮周期。
为什么S与T的比较周期有|T|个呢?通俗的说就是S中的每个字符都会跟T中的每个字符进行对位一次,而再次当S第一个字符与T第一个字符对位时,就是进行了|T|个周期了。
看不懂是吧?知道你也不会好好看,我来给你分析一下= =
比如这两个长度互质的串:
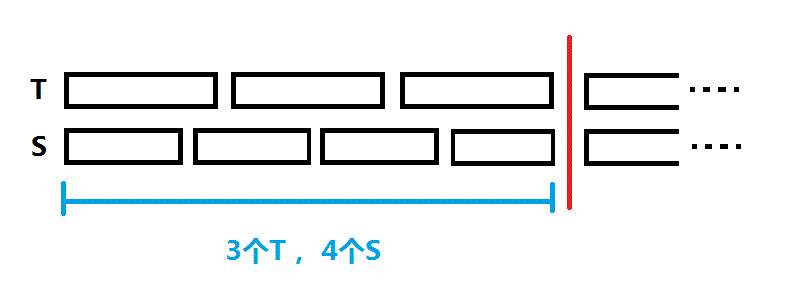
把长度标上后,让我们关注一下S串头元素进行了哪几次比较:
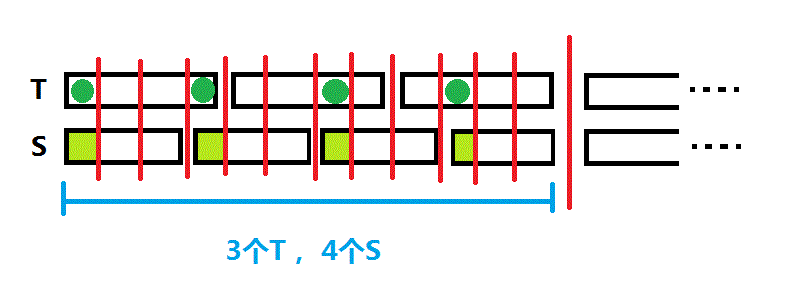
可以看到共有4次比较(用深绿色圆圈表示),我们发现这不就是T串里的4个元素吗?
好,那我们看看在T串上S的头元素是怎么比较的:
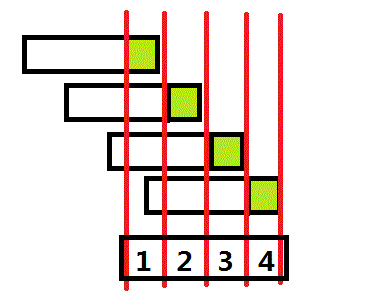
上面四个是S串,底下的是T串。我们来举一个例子:
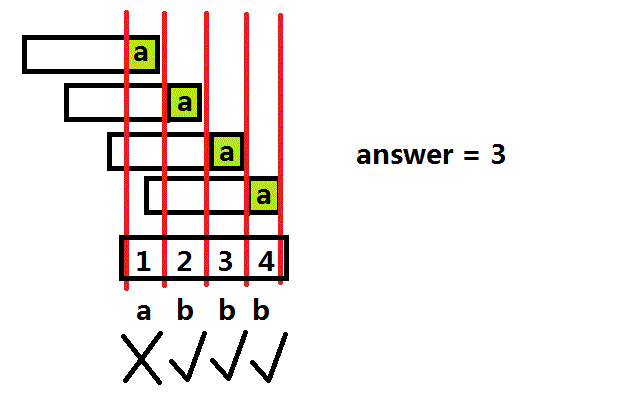
所以说头元素贡献了3份答案。
那么显而易见,不仅S串头元素会全都比较T串的四个元素,第二个、第三个元素也会比较,我们再画一个清晰的图:
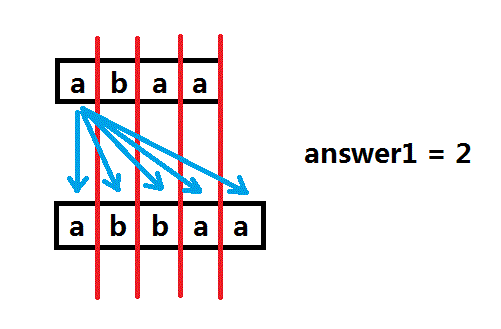
上面是S串,下面是T串,先让上面最左边的”a“进行一次全部比较,可以看到有2个答案。
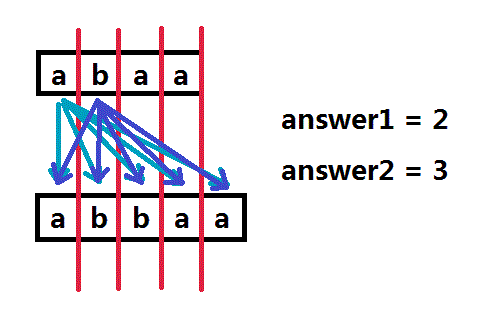
第二个元素同理有三个答案。
第三、第四个S串里的”a“元素答案一定和answer1是一样的(想一想,为什么?)
最后根据加法、乘法原理,答案应该是:3 * answer1 + 1 * answer2 = 3 * 2 + 1 * 3 = 9;
画回最原始的图再看一眼:
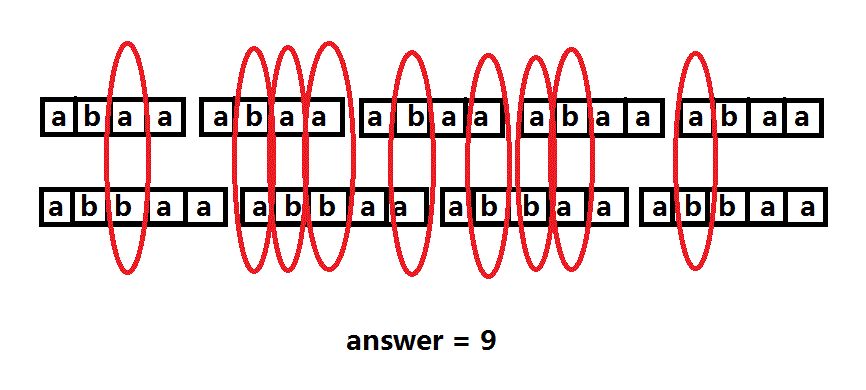
答案正确。此输入应该是:5 4 abaa abbaa 输出是:9
那如果输入的是10 8 abaa abbaa呢?
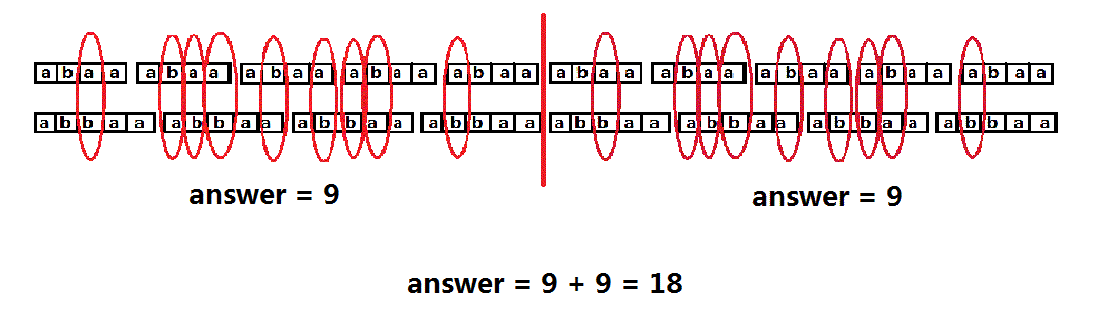
那么就应该有两个循环节了,答案是18。
那么至此为止,两字串长度互质的情况我们已经会算了,可以用两个哈希表vis_S[27], vis_T[27]分别表示26个小写字母在S串和T串中分别出现了几次。
程序不难写出,建议读者好好看一眼哈希表的使用,为下边打好基础:
- #include <iostream>
- #include <cstdio>
- #include <algorithm>
- using namespace std;
- void read(int& x)
- {
- x = ;
- int sig = ;
- char ch = getchar();
- while(!isdigit(ch))
- {
- if(ch == '-') sig = -;
- ch = getchar();
- }
- while(isdigit(ch))
- {
- x = x * + ch - '';
- ch = getchar();
- }
- return ;
- }
- int tot;
- long long ans;
- const int maxn = + ;
- char S[maxn], T[maxn];
- int T1, T2;
- int vis[][];
- int read_str1()
- {
- char tmp = getchar();
- while(!isalpha(tmp)) tmp = getchar();
- tot = ;
- while(isalpha(tmp))
- {
- S[tot++] = tmp;
- vis[][tmp - 'a']++;
- tmp = getchar();
- }
- S[tot] = '\0';
- return tot;
- }
- int read_str2()
- {
- char tmp = getchar();
- while(!isalpha(tmp)) tmp = getchar();
- tot = ;
- while(isalpha(tmp))
- {
- T[tot++] = tmp;
- vis[][tmp - 'a']++;
- tmp = getchar();
- }
- T[tot] = '\0';
- return tot;
- }
- void vis_init()
- {
- long long tmp;
- for(int i = ; i < ; i++)
- {
- tmp = ;
- for(int j = ; j < ; j++)
- {
- if(i == j) continue;
- tmp += vis[][j];
- }
- ans += vis[][i] * tmp;
- }
- return ;
- }
- int main()
- {
- read(T1);
- read(T2);
- int s1 = read_str1();
- int s2 = read_str2();
- vis_init();
- ans = (long long)((double)ans * ((double)T1 / (double)s2));
- //记得是同时约了一个s1
- printf("%lld\n", ans);
- return ;
- }
好,那么我们来看看非互质的情况:
先来说一下为啥互质与非互质不同,感谢路人们贡献的反例:
比如 3 2 abac ababac:

如果用互质法来解答案应该是:2 * 3 + 1 * 4 + 1 * 5 = 15 (想想都觉得多= =)
正解看下图:
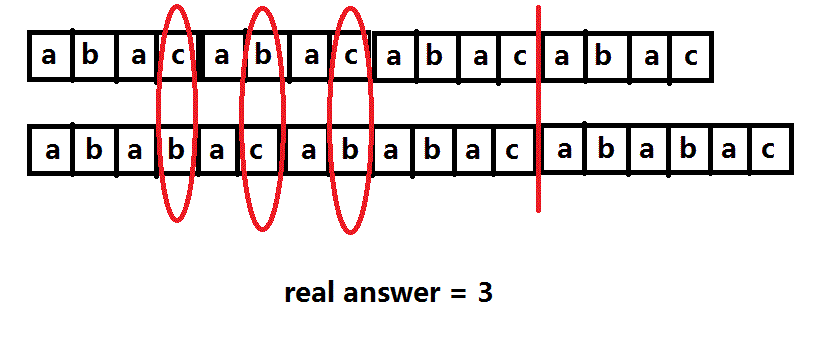
正解是3,少了一大堆,那为啥一不互质就不行了呢?
先来看以前那个图:
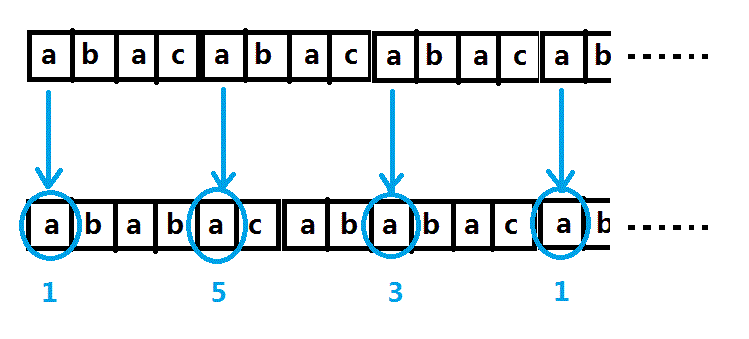
可以看到,上面的S串的头元素(还记得吗?)与下面的T串全都进行了比较。但是在非互质情况里则不一定,我们来看一眼刚才那个例子:
S串头元素与T串的1,3,5进行比较(注意不是全部元素了!)
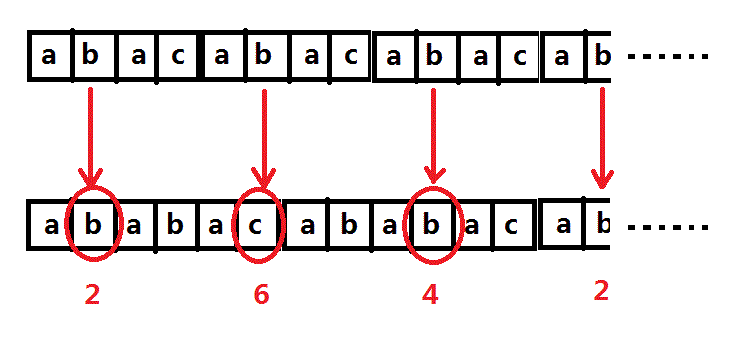
S串第二元素元素与T串的2,4,6进行比较:(S和T老忘了打你们将就看吧……)
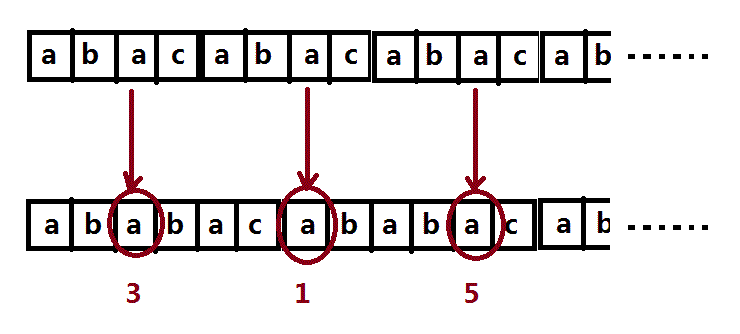
S串第三元素元素与T串的1,3,5进行比较:
(插:你们写博客一定要随时保存,刚才一断网后面写的全没了TAT,还有插图一定要随时保存TAT)
那么我们来看,对于S串的元素来说,他们都和T串的一个子串相对应(在这里就是1,3,5 和 2,4,6)
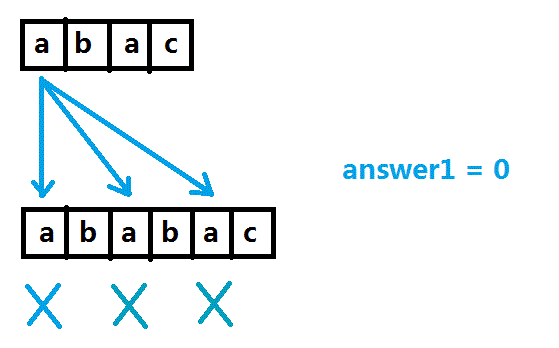
把S串的每一个元素单独分析,对于S串第一个元素a,在第一个子串(以后讲为什么叫做“第一个”)中进行询问,答案是0。
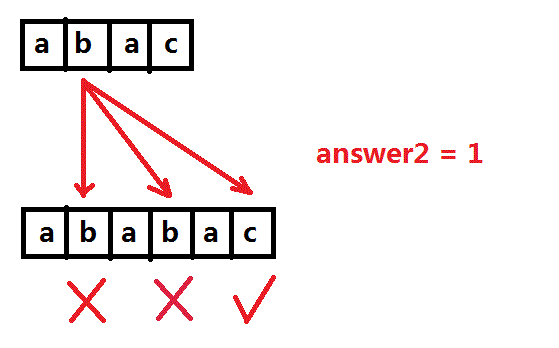
对于S串第二个元素b,在第二个子串中进行询问,答案是1。
同理,对于S串第三、四个元素a、c,分别在第一、二个子串中进行询问,答案是0和2。
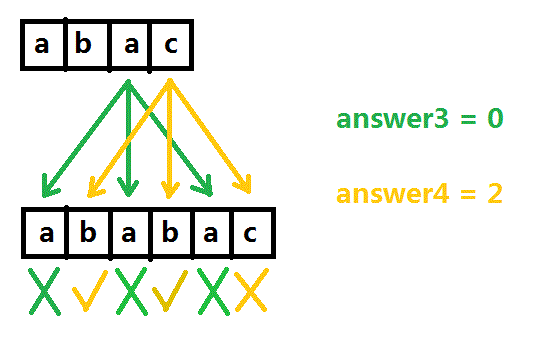
与互质算法同理,得到最后的答案0 + 1 + 0 + 2 = 3
在分析过程中我们为了区分不同的T串的子串所以给他们分别表上了号,待会会再说这个编号。
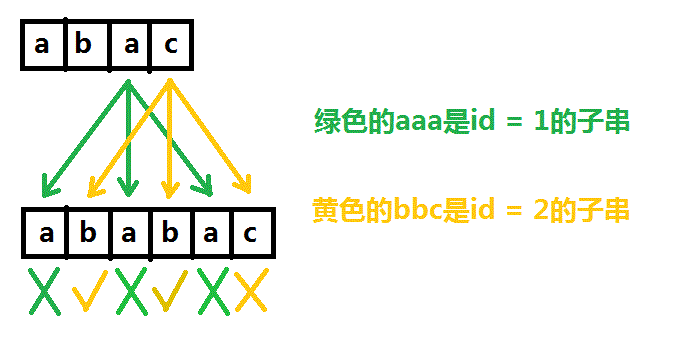
那么这些字串有什么规律呢?首先可以看出来他们是穿插的,其次发现他们每个串的“间隔”是一样的,比如看上面的图:绿色的1号子串aaa中每个a都差了2个格(我们定义相邻为差了一个空格),黄色的2号子串bbc中每个元素也都差了2个格。这个2有什么特殊含义呢?请读者自己画一画下面两个数据的子串。
1. 4 2 ab abac
2. 9 3 ab ababac
不难发现(这四个字会不会伤了很多人的心…),两个字串长度的最大公约数即是子串元素间的间隔长度 以及子串的个数
那我们可以借此规律为子串标号,还是上图,绿色的就叫1号,黄色的就叫2号。因此我们将T串分成了许多个相互穿插的子串,每一部分都可以用互质算法进行求解,不再赘述。
还有很关键的一点是:如何存放这些子串的信息?原来存放一个T串我们用了只一个哈希表,那么现在我们可以用标号造一大堆哈希表分别对应每一个子串。说白了,就是在vis前面再多一维度。
我们用vis1[id][i]表示S串内第id个串中字母i出现的次数(这里是字母编号),相应的,用vis2[id][i]表示T串内第id个串中字母i出现的次数。
下面给出代码,请读者留意哈希表id的运用。
- #include <iostream>
- #include <cstdio>
- #include <algorithm>
- using namespace std;
- void read(int& x)
- {
- x = ;
- int sig = ;
- char ch = getchar();
- while(!isdigit(ch))
- {
- if(ch == '-') sig = -;
- ch = getchar();
- }
- while(isdigit(ch))
- {
- x = x * + ch - '';
- ch = getchar();
- }
- return ;
- }
- int gcd(int a, int b)
- {
- return b == ? a: gcd(b, a % b);
- }
- int tot;
- long long ans;
- const int maxn = + ;
- char S[maxn], T[maxn];
- int T1, T2;
- int vis1[maxn/][]; //放maxn内存超限,具体情况看下文分析。
- int vis2[maxn/][];
- int HASH;
- int s1, s2;
- int read_str1()
- {
- char tmp = getchar();
- while(!isalpha(tmp)) tmp = getchar();
- tot = ;
- while(isalpha(tmp))
- {
- S[tot++] = tmp;
- tmp = getchar();
- }
- S[tot] = '\0';
- return tot;
- }
- int read_str2()
- {
- char tmp = getchar();
- while(!isalpha(tmp)) tmp = getchar();
- tot = ;
- while(isalpha(tmp))
- {
- T[tot++] = tmp;
- tmp = getchar();
- }
- T[tot] = '\0';
- return tot;
- }
- void solve()
- {
- for(int i = ; i < s1; i++)
- vis1[i % HASH][S[i] - 'a']++;
- for(int i = ; i < s2; i++)
- vis2[i % HASH][T[i] - 'a']++;
- return ;
- }
- void vis_init()
- {
- long long tmp;
- for(int id = ; id < HASH; id++)
- {
- for(int i = ; i < ; i++)
- {
- tmp = ;
- for(int j = ; j < ; j++)
- {
- if(i == j) continue;
- tmp += vis2[id][j];
- }
- ans += vis1[id][i] * tmp;
- }
- }
- return ;
- }
- int main()
- {
- read(T1);
- read(T2);
- s1 = read_str1();
- s2 = read_str2();
- HASH = gcd(s1, s2);
- solve();
- vis_init();
- printf("%lld\n", ans);
- return ;
- }
还有一个小问题,就是第41行开哈希表的时候,由于内存不够,我们这里用的是maxn/4,数据通常不会给两个长度相同或呈二倍关系的子串吧?这分就这么到手了。如果要写出完美解答,可以事先加一个判断:如果两字串长度相等或呈2倍关系就直接暴力循环节也行。(此代码略,感兴趣的读者可写一遍)
最后我们来比较一下暴力循环节法和这种数学方法的优劣:
当两字串长度极为接近或互质,那么几乎没有循环节,此数学方法反而效率极高且十分省内存(哈希表成一维了),而暴力循环节绝对会爆掉。
当两字串公共因子极多时,可能会出现大量循环节,这时暴力循环节发效率增高,而此数学方法内存会一下多出很多(效率是不变的,请读者尝试证明)。
所以说,两种方法各有优劣,但综合来看数学方法更加稳定且效率高。如果追求完美,可以尝试一半用暴力一半用数学,程序一秒就能高大上,带你逗逼带你飞~。
2015 CCC - 02 找不匹配的更多相关文章
- 阅读OReilly.Web.Scraping.with.Python.2015.6笔记---找出网页中所有的href
阅读OReilly.Web.Scraping.with.Python.2015.6笔记---找出网页中所有的href 1.查找以<a>开头的所有文本,然后判断href是否在<a> ...
- 890. Find and Replace Pattern找出匹配形式的单词
[抄题]: You have a list of words and a pattern, and you want to know which words in words matches the ...
- 使用c#正则验证关键字并找出匹配项
在.net里,使用类Regex可以正则验证一些关键字并取出匹配项. 1.使用Regex.IsMatch(string input, string pattern, RegexOptions ...
- iOS 学习笔记 九 (2015.04.02)IOS8中使用UIAlertController创建警告窗口
1.IOS8中使用UIAlertController创建警告窗口 #pragma mark - 只能在IOS8中使用的,警告窗口- (void)showOkayCancelAlert{ NSSt ...
- 2015 CCC - 01 统计数对
源:CNUOJ-0384 http://oj.cnuschool.org.cn/oj/home/problem.htm?problemID=354 题目分析:当时拿到这道题第一个想法就是排序后n^2暴 ...
- Sql Server 在数据库中所有表所有栏位 找出匹配某个值的脚本(转)
转自: http://blog.csdn.net/chenghaibing2008/article/details/11891419 (下面代码稍有修改,将要查找的内容直接作为参数传人,并且使用=而不 ...
- Deepin 2015 安装后找不到win10 启动选项的解决办法
#sudo vi /boot/grub/grub.cfg 在export linux_gfx_mode后面加 menuentry "Windows 10 (loader)" --c ...
- AC日记——找第一个只出现一次的字符 openjudge 1.7 02
02:找第一个只出现一次的字符 总时间限制: 1000ms 内存限制: 65536kB 描述 给定一个只包含小写字母的字符串,请你找到第一个仅出现一次的字符.如果没有,输出no. 输入 一个字符串 ...
- [leetcode] 230. Kth Smallest Element in a BST 找出二叉搜索树中的第k小的元素
题目大意 https://leetcode.com/problems/kth-smallest-element-in-a-bst/description/ 230. Kth Smallest Elem ...
随机推荐
- poj 1849 Two
/*poj 1849 two 思考一下会发现 就是求直径 直径上的中点就是两个人分开的地方(不再有交集)*/ #include<cstdio> #define maxn 100010 us ...
- python 学习笔记(一)
在Windows上安装Python 首先,从Python的官方网站www.python.org下载最新的2.7.9版本,地址是这个: http://www.python.org/ftp/python/ ...
- web前端:js
内嵌样式<script></script> alert(“123”)弹出对话框 document.write(“test”) 引入方式 <title></ti ...
- object转化为string
package common; import java.util.ArrayList; import java.util.List; public class DataZh { public stat ...
- JS打开窗口问题
语法 window.open(URL,name,features,replace) URL:一个可选的字符串,声明了要在新窗口中显示的文档的 URL.如果省略了这个参数,或者它的值是空字符串,那么新窗 ...
- HTML5 文件域+FileReader 分段读取文件(四)
一.分段读取txt文本 HTML: <div class="container"> <div class="panel panel-default&qu ...
- PV、UV、IP的区别
网站推广需要一个网站访问统计工具,常用的统计工具有百度统计.51la.量子恒道统计等.网站访问量常用的指标为PV.UV.IP.那么什么是PV.UV和IP,PV.UV.IP的区别是什么? --首先来看看 ...
- 移动端touchstar、touchmove、touchend 事件如果页面有滚动时不让触发 touchend 事件。
/*仅适用于内容中点击元素.对于拖动等元素,需要自行在页面处理. * 主要是绑定touchstart和touchmove事件,并判断用户按下之后手指移动了多少像素. * 如果手指移动距离小于10像素, ...
- 安卓学习之ListView和GridView
ListView 和 GridView是安卓中显示信息的两个很基本也最常用的控件.他们的用法很相似,但是他俩也是有区别的. ListView显示的数据会将他的item放在一行显示,而且根据内容给出it ...
- 关于DM的一点总结[ZZ]
用IBM的IM做过一段时间的电信客户挖掘由于时间不是很长,做的挖掘模型效果还有待提高应朋友要求简单总结几点(水平有限,也希望经验丰富的朋友给些建议): 1.挖掘工具主要分商业数据产品和集成数据挖掘产品 ...