使用DBOutputFormat把MapReduce产生的结果集导入到mysql中
数据在HDFS和关系型数据库之间的迁移,主要有以下两种方式
1、按照数据库要求的文件格式生成文件,然后由数据库提供的导入工具进行导入
2、采用JDBC的方式进行导入
MapReduce默认提供了DBInputFormat和DBOutputFormat,分别用于数据库的读取和数据库的写入
1、需求
下面使用DBOutputFormat,将MapReduce处理后的学生信息导入到mysql中
2、数据集
张明明 45
李成友 78
张辉灿 56
王露 56
陈东明 67
陈果 31
李华明 32
张明东 12
李明国 34
陈道亮 35
陈家勇 78
陈旻昊 13
陈潘 78
陈学澄 18
3、实现
package com.buaa; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; /**
* @ProjectName DBOutputormatDemo
* @PackageName com.buaa
* @ClassName MysqlDBOutputormatDemo
* @Description TODO
* @Author 刘吉超
* @Date 2016-05-06 09:15:57
*/
@SuppressWarnings({ "unused", "deprecation" })
public class MysqlDBOutputormatDemo extends Configured implements Tool {
/**
* 实现DBWritable
*
* TblsWritable需要向mysql中写入数据
*/
public static class TblsWritable implements Writable, DBWritable {
String tbl_name;
int tbl_age; public TblsWritable() {
} public TblsWritable(String name, int age) {
this.tbl_name = name;
this.tbl_age = age;
} @Override
public void write(PreparedStatement statement) throws SQLException {
statement.setString(1, this.tbl_name);
statement.setInt(2, this.tbl_age);
} @Override
public void readFields(ResultSet resultSet) throws SQLException {
this.tbl_name = resultSet.getString(1);
this.tbl_age = resultSet.getInt(2);
} @Override
public void write(DataOutput out) throws IOException {
out.writeUTF(this.tbl_name);
out.writeInt(this.tbl_age);
} @Override
public void readFields(DataInput in) throws IOException {
this.tbl_name = in.readUTF();
this.tbl_age = in.readInt();
} public String toString() {
return new String(this.tbl_name + " " + this.tbl_age);
}
} public static class StudentMapper extends Mapper<LongWritable, Text, LongWritable, Text>{
@Override
protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException {
context.write(key, value);
}
} public static class StudentReducer extends Reducer<LongWritable, Text, TblsWritable, TblsWritable> {
@Override
protected void reduce(LongWritable key, Iterable<Text> values,Context context) throws IOException, InterruptedException {
// values只有一个值,因为key没有相同的
StringBuilder value = new StringBuilder();
for(Text text : values){
value.append(text);
} String[] studentArr = value.toString().split("\t"); if(StringUtils.isNotBlank(studentArr[0])){
/*
* 姓名 年龄(中间以tab分割)
* 张明明 45
*/
String name = studentArr[0].trim(); int age = 0;
try{
age = Integer.parseInt(studentArr[1].trim());
}catch(NumberFormatException e){
} context.write(new TblsWritable(name, age), null);
}
}
} public static void main(String[] args) throws Exception {
// 数据输入路径和输出路径
String[] args0 = {
"hdfs://ljc:9000/buaa/student/student.txt"
};
int ec = ToolRunner.run(new Configuration(), new MysqlDBOutputormatDemo(), args0);
System.exit(ec);
} @Override
public int run(String[] arg0) throws Exception {
// 读取配置文件
Configuration conf = new Configuration(); DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver",
"jdbc:mysql://172.26.168.2:3306/test", "hadoop", "123"); // 新建一个任务
Job job = new Job(conf, "DBOutputormatDemo");
// 设置主类
job.setJarByClass(MysqlDBOutputormatDemo.class); // 输入路径
FileInputFormat.addInputPath(job, new Path(arg0[0])); // Mapper
job.setMapperClass(StudentMapper.class);
// Reducer
job.setReducerClass(StudentReducer.class); // mapper输出格式
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class); // 输入格式,默认就是TextInputFormat
// job.setInputFormatClass(TextInputFormat.class);
// 输出格式
job.setOutputFormatClass(DBOutputFormat.class); // 输出到哪些表、字段
DBOutputFormat.setOutput(job, "student", "name", "age"); // 添加mysql数据库jar
// job.addArchiveToClassPath(new Path("hdfs://ljc:9000/lib/mysql/mysql-connector-java-5.1.31.jar"));
// DistributedCache.addFileToClassPath(new Path("hdfs://ljc:9000/lib/mysql/mysql-connector-java-5.1.31.jar"), conf);
//提交任务
return job.waitForCompletion(true)?0:1;
}
}
mr程序很简单,只是读取文件内容,在这里我们主要关注的是怎么将mr处理后的结果集导入mysql中的
数据库中表是student,为student表编写对应的bean类TblsWritable,该类需要实现Writable接口和DBWritable接口。
1、Writable接口
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(this.tbl_name);
out.writeInt(this.tbl_age);
} @Override
public void readFields(DataInput in) throws IOException {
this.tbl_name = in.readUTF();
this.tbl_age = in.readInt();
}
上面两个方法对应着Writable接口,用对象序列化,这里不再多说,前面文章有介绍
2、DBWritable接口
@Override
public void write(PreparedStatement statement) throws SQLException {
statement.setString(1, this.tbl_name);
statement.setInt(2, this.tbl_age);
} @Override
public void readFields(ResultSet resultSet) throws SQLException {
this.tbl_name = resultSet.getString(1);
this.tbl_age = resultSet.getInt(2);
}
上面两个方法对应着DBWriteable接口。readFields方法负责从结果集中读取数据库数据(注意ResultSet的下标是从1开始的),一次读取查询SQL中筛选的某一列。Write方法负责将数据写入到数据库,将每一行的每一列依次写入。
最后进行Job的一些配置,具体如下面代码所示
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://172.26.168.2:3306/test", "hadoop", "123")
上面的配置主要包括以下几项:
1、数据库驱动的名称:com.mysql.jdbc.Driver
2、数据库URL:jdbc:mysql://172.26.168.2:3306/test
3、用户名:hadoop
4、密码:123
还有以下几项需要配置
1、数据库表以及每列的名称:DBOutputFormat.setOutput(job, "student", "name", "age");
2、输出格式改为:job.setOutputFormatClass(DBOutputFormat.class);
需要提醒的是DBOutputFormat以MapReduce的方式运行,会并行的连接数据库。在这里需要合适的设置map、reduce的个数,以便将并行连接的数量控制在合理的范围之内
4、运行效果
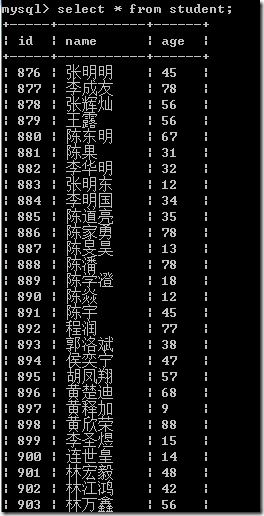
5、注意事项
运行项目可能会报如下错误

解决方法:
共有3种解决方法,但我喜欢第三种
1、在每个节点下的${HADOOP_HOME}/lib下添加该包。重启集群,一般是比较原始的方法。
2、把jar包传到集群上,命令如下
hadoop fs -put mysql-connector-java-5.1.31.jar /lib/mysql
在mr程序提交job前,添加如下两个语句中一个就行
(1)DistributedCache.addFileToClassPath(new Path(“hdfs://ljc:9000/lib/mysql/mysql-connector-java-5.1.31.jar”), conf);
这条语句不推荐使用了,建议使用下面这条语句
(2)job.addArchiveToClassPath(new Path("hdfs://ljc:9000/lib/mysql/mysql-connector-java-5.1.31.jar"));
注意:用这种方式,在本地运行,依然报“java.io.IOException: com.mysql.jdbc.Driver”,但放到hadoop运行环境就可以啦
3、把依赖的jar打到项目中,然后配置MANIFEST.MF文件中Class-Path选项

具体配置,请参考“通过指定manifest.mf文件的打包”
使用DBOutputFormat把MapReduce产生的结果集导入到mysql中的更多相关文章
- [MapReduce_add_1] Windows 下开发 MapReduce 程序部署到集群
0. 说明 Windows 下开发 MapReduce 程序部署到集群 1. 前提 在本地开发的时候保证 resource 中包含以下配置文件,从集群的配置文件中拷贝 在 resource 中新建 ...
- 【原创】MapReduce程序如何在集群上执行
首先了解下资源调度管理框架Yarn. Yarn的结构(如图): Resource Manager (rm)负责调度管理整个集群上的资源,而每一个计算节点上都会有一个Node Manager(nm)来负 ...
- mysql集群之MYSQL CLUSTER
1. 参考文档 http://xuwensong.elastos.org/2014/01/13/ubuntu-%E4%B8%8Bmysql-cluster%E5%AE%89%E8%A3%85%E5%9 ...
- Oracle存储过程实现返回多个结果集 在构造函数方法中使用 dataset
原文 Oracle存储过程实现返回多个结果集 在构造函数方法中使用 dataset DataSet相当你用的数据库: DataTable相当于你的表.一个 DataSet 可以包含多个 DataTab ...
- Hadoop集群搭建过程中ssh免密码登录(二)
一.为什么设置ssh免密码登录 在集群中,Hadoop控制脚本依赖SSH来执行针对整个集群的操作.例如,某个脚本能够终止并重启集群中的所有守护进程.所以,需要安装SSH,但是,SSH远程登陆的时候,需 ...
- Spring整合Quartz定时任务 在集群、分布式系统中的应用(Mysql数据库环境)
Spring整合Quartz定时任务 在集群.分布式系统中的应用(Mysql数据库环境) 转载:http://www.cnblogs.com/jiafuwei/p/6145280.html 单个Q ...
- hadoop集群搭建过程中遇到的问题
在安装配置Hadoop集群的过程中遇到了很多问题,有些是配置导致的,有些是linux系统本身的问题造成的,现在总结如下. 1. hdfs namenode -format出现错误:hdfs namen ...
- Mysql中各种与字符编码集(character_set)有关的变量含义
mysql涉及到各种字符集,在此做一个总结. 字符集的设置是通过环境变量来设置的,环境变量和linux中的环境变量是一个意思.mysql的环境变量分为两种:session和global.session ...
- 服网LNMP集群 w/ MySQL PaaS-1.0
平台: arm 类型: ARM 模板 软件包: haproxy linux mysql nginx application server arm basic software fuwang infra ...
随机推荐
- mvc验证码
public string CreateValidateCode(int length) { int[] randMembers = new int[length]; int[] validateNu ...
- EasyPHP的Apache报错
今天安装了最新版本的软件:EasyPHP-DevServer-14.1VC11-install.exe 启动报错: 打开Cport软件: 可见80端口被系统占用,导致Apache不能启动. (1)手动 ...
- 000webhost找不到文件自定义错误
1.新建一个名为.htaccess的文本文件:2.在文件中输入如下代码:ErrorDocument 404 /404.php3.保存文件,将.htaccess上传到域名的根目录,再验证,呵呵,成功了! ...
- 彻底理解ThreadLocal(转)
ThreadLocal是什么 早在JDK 1.2的版本中就提供java.lang.ThreadLocal,ThreadLocal为解决多线程程序的并发问题提供了一种新的思路.使用这个工具类可以很简洁地 ...
- Spring MVC 解读——View,ViewResolver(转)
上一篇文章(1)(2)分析了Spring是如何调用和执行控制器方法,以及处理返回结果的,现在我们就分析下Spring如何解析返回的结果生成响应的视图. 一.概念理解 View ---View接口表示一 ...
- Git遇到的一点错误
[背景] 折腾: [记录]将googlecode上面的crifanLib迁移到Github上 期间出错: ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 1 ...
- 标量子查询优化(用group by 代替distinct)
标量子查询优化 当使用另外一个SELECT 语句来产生结果中的一列的值的时候,这个查询必须只能返回一行一列的值.这种类型的子查询被称为标量子查询 在某些情况下可以进行优化以减少标量子查询的重复执行,但 ...
- .classpath 和.project文件含义
.classpath文件是在建立eclipse工程时创建的描述工程配置情况的文件,包括: * 源码路径 * 编译结果的输出路径 * 所使用的外部库的路径 -----------------下面是 ...
- poj1637
混合图欧拉回路首先先明确基本概念连通的无向图存在欧拉回路当且仅当不存在奇点连通的有向图当且仅当每个点入度=出度这道题我们显然应该当作连通的有向图来做这个问题的困难之处在于我不知道应该从无向边的什么方向 ...
- poj3519
凡是差分约束系统的题目都是转化为d[j]-d[i]<=w[i,j]的形式然后我们建立边i-->j 边权为w[i,j]对于这道题,要求d[n]-d[1]尽可能的大设d[i]为相对差,d[1] ...