SQL Server将一列的多行内容拼接成一行的问题讨论
转自http://blog.csdn.net/rolamao/article/details/7745972
昨天遇到一个SQL Server的问题:需要写一个储存过程来处理几个表中的数据,最后问题出在我想将一个表的一个列的多行内容拼接成一行
比如表中有两列数据 :
ep_classes ep_name
AAA 企业1
AAA 企业2
AAA 企业3
BBB 企业4
BBB 企业5
我想把这个表变成如下格式:
ep_classes ep_name
AAA 企业1,企业2,企业3
BBB 企业4,企业5
一开始挺头疼的(会了的肯定没有这种感觉,不会那必须是头疼啊(*^__^*) ),从网上找了点资料,算是找到一种比较简单方便的方法吧,现在大体总结一下,供大家共同学习。
原先的表名为:ep_detail。
实现代码如下:
- select ep_classes, ep_name = (stuff((select ',' + ep_name from ep_detail where ep_classes =
- a.ep_classes for xml path('')),1,1,'')) from ep_detail a group by ep_classes
这里使用了SQL Server 2005版本以后加入的stuff以及for xml path,先说下在上面这句sql中的作用,然后再详细的说明一下这两个的用法。
- for xml path('')
这句是把得到的内容以XML的形式显示。
- stuff((select ',' + ep_name from ep_detail where ep_classes = a.ep_classes for xml path('')),1,1,'')
这句是把拼接的内容的第一个“,”去掉。
好了,现在开始具体说一下用法:
①stuff:
1、作用
stuff(param1, startIndex, length, param2)
将param1中自startIndex(SQL中都是从1开始,而非0)起,删除length个字符,然后用param2替换删掉的字符。
2、参数
param1
一个字符数据表达式。param1可以是常量、变量,也可以是字符列或二进制数据列。
startIndex
一个整数值,指定删除和插入的开始位置。如果 startIndex或 length 为负,则返回空字符串。如果startIndex比param1长,则返回空字符串。startIndex可以是
bigint 类型。
length
一个整数,指定要删除的字符数。如果 length 比param1长,则最多删除到param1
中的最后一个字符。length 可以是 bigint 类型。
3、返回类型
如果param1是受支持的字符数据类型,则返回字符数据。如果param1是一个受支持的
binary 数据类型,则返回二进制数据。
4、备注
如果结果值大于返回类型支持的最大值,则产生错误。
eg:
- select STUFF('abcdefg',1,0,'1234') --结果为'1234abcdefg'
- select STUFF('abcdefg',1,1,'1234') --结果为'1234bcdefg'
- select STUFF('abcdefg',2,1,'1234') --结果为'a1234cdefg'
- select STUFF('abcdefg',2,2,'1234') --结果为'a1234defg'
通过以上4个小例子,应该能明白stuff的用法了。
②for xml path:
for xml path有的人可能知道有的人可能不知道,其实它就是将查询结果集以XML形式展现,有了它我们可以简化我们的查询语句实现一些以前可能需要借助函数活存储过程来完成的工作。那么以一个实例为主.
我们还是通过列子引入:
假设有个表存放着学生的选课情况(stu_courses):
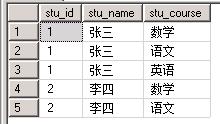
接下来我们来看应用FOR XML PATH的查询结果语句如下:
- select stu_name,stu_course from stu_courses for xml path;
结果如下:
- <row>
- <stu_name>张三</stu_name>
- <stu_course>数学</stu_course>
- </row>
- <row>
- <stu_name>张三</stu_name>
- <stu_course>语文</stu_course>
- </row>
- <row>
- <stu_name>张三</stu_name>
- <stu_course>英语</stu_course>
- </row>
- <row>
- <stu_name>李四</stu_name>
- <stu_course>数学</stu_course>
- </row>
- <row>
- <stu_name>李四</stu_name>
- <stu_course>语文</stu_course>
- </row>
由此可以看出 FOR XML PATH 可以将查询结果根据行输出成XML各式!而且我们还可以改变XML行节点的名称,代码如下:
- select stu_name,stu_course from stu_courses for xml path('course');
看显示结果,原来的行节点<row> 变成了我们在PATH后面括号()中自定义的名称<course>:
- <course>
- <stu_name>张三</stu_name>
- <stu_course>数学</stu_course>
- </course>
- <course>
- <stu_name>张三</stu_name>
- <stu_course>语文</stu_course>
- </course>
- <course>
- <stu_name>张三</stu_name>
- <stu_course>英语</stu_course>
- </course>
- <course>
- <stu_name>李四</stu_name>
- <stu_course>数学</stu_course>
- </course>
- <course>
- <stu_name>李四</stu_name>
- <stu_course>语文</stu_course>
- </course>
其实我们还可以改变列节点,还记的给列起别名的关键字AS吗?就是用它!代码如下:
- select stu_name as MyName,stu_course as MyCourse from stu_courses for xml path('course');
显示结果:
- <course>
- <MyName>张三</MyName>
- <MyCourse>数学</MyCourse>
- </course>
- <course>
- <MyName>张三</MyName>
- <MyCourse>语文</MyCourse>
- </course>
- <course>
- <MyName>张三</MyName>
- <MyCourse>英语</MyCourse>
- </course>
- <course>
- <MyName>李四</MyName>
- <MyCourse>数学</MyCourse>
- </course>
- <course>
- <MyName>李四</MyName>
- <MyCourse>语文</MyCourse>
- </course>
我们还可以构建我们喜欢的输出方式,看代码:
- select '['+stu_name+','+stu_course+']' from stu_courses for xml path('');
显示结果:
- [张三,数学][张三,语文][张三,英语][李四,数学][李四,语文]
好了,通过上面的说明,估计大家就可以明白开始问题中的sql语句了!
当然,关于开始的问题还有其他的解决办法,比如:游标、自定义函数等等,那些以后再做补充吧。
以上仅作抛砖引玉之用,如果有问题或者其他的简便方法,希望提出大家共同讨论学习!
SQL Server将一列的多行内容拼接成一行的问题讨论的更多相关文章
- 关于SQL Server将一列的多行内容拼接成一行的问题讨论
http://blog.csdn.net/rolamao/article/details/7745972 昨天遇到一个SQL Server的问题:需要写一个储存过程来处理几个表中的数据,最后问题出在我 ...
- 关于SQL Server将一列的多行内容拼接成一行的问题讨论【转】
原文链接:https://blog.csdn.net/rolamao/article/details/7745972 比如表中有两列数据 : ep_classes ep_name AAA ...
- SQL Server将一列的多行内容拼接成一行
昨天遇到一个SQL Server的问题:需要写一个储存过程来处理几个表中的数据,最后问题出在我想将一个表的一个列的多行内容拼接成一行 比如表中有两列数据 : ep_classes ep_name A ...
- 关于SQL Server将一列的多行内容拼接成一行,合并显示在另外表中
select '['+title_a+','+title_b +']' from A for xml path('') SELECT *, (select '['+title_a+','+titl ...
- sql2005 将一列的多行内容拼接成一行
select ID, Name = ( stuff ( ( select ',' + Name from Table_1 where ID = a.ID for xml path('') ),1,1, ...
- SQL不重复查找数据及把一列多行内容拼成一行
如下表: 表名:Test ID RowID Col1 Col2 1 1 A A 2 1 B A 3 1 A B 4 1 C B 1,查找表中字段重复的只查找一次 select distinct Col ...
- Oracle一列的多行数据拼成一行显示字符
Oracle一列的多行数据拼成一行显示字符 oracle 提供了两个函数WMSYS.WM_CONCAT 和 ListAgg函数. www.2cto.com 先介绍:WMSYS.WM_CO ...
- Sql Server 数据把列根据指定的内容拆分数据
今天由于工作需要,需要把数据把列根据指定的内容拆分数据 其中一条数据实例 select id , XXXX FROM BIZ_PAPER where id ='4af210ec675927fa016 ...
- ms sql server,oracle数据库实现拼接一列的多行内容
项目中要将查询出的一列的多行内容拼接成一行,如下图:ypmc列. ms sql server: 网上查到相关资料如下:http://blog.csdn.net/rolamao/article/deta ...
随机推荐
- 李洪强iOS开发之-环信05_EaseUI 使用指南
李洪强iOS开发之-环信05_EaseUI 使用指南 EaseUI 使用指南 简介 EaseUI 封装了 IM 功能常用的控件(如聊天会话.会话列表.联系人列表).旨在帮助开发者快速集成环信 SDK. ...
- javaweb学习总结(三十六)——使用JDBC进行批处理
在实际的项目开发中,有时候需要向数据库发送一批SQL语句执行,这时应避免向数据库一条条的发送执行,而应采用JDBC的批处理机制,以提升执行效率. JDBC实现批处理有两种方式:statement和pr ...
- QString内部仍采用UTF-16存储数据且不会改变(一共10种不同情况下的编码)
出处:https://blog.qt.io/cn/2012/05/16/source-code-must-be-utf-8-and-qstring-wants-it/ 但是注意,这只是QT运行(Run ...
- SQL Server 2008R2 数据库出现“可疑”导致无法访问
日常对Sql Server 2005关系数据库进行操作时,有时对数据库(如:Sharepoint网站配置数据库名Sharepoint_Config)进行些不正常操作如数据库在读写时而无故停止数据库,从 ...
- spring log4j.properties
log4j.properties log4j.rootLogger=info,appender2,appender3 #appender2\u914D\u7F6E FileAppender log4j ...
- htmlparser源码简单分析
Htmlparser源代码分析 一.根目录下的类 1.Attribute.java 属性类,四个field:mName,mAssignment,mValue,mQuote; 空白标签时:mName=n ...
- 在ASP.NET MVC中实现基于URL的权限控制
本示例演示了在ASP.NET MVC中进行基于URL的权限控制,由于是基于URL进行控制的,所以只能精确到页.这种权限控制的优点是可以在已有的项目上改动极少的代码来增加权限控制功能,和项目本身的耦合度 ...
- 浅谈MS-SQL锁机制
锁的概述 一. 为什么要引入锁 多个用户同时对数据库的并发操作时会带来以下数据不一致的问题: 丢失更新A,B两个用户读同一数据并进行修改,其中一个用户的修改结果破坏了另一个修改的结果,比如订票系统 脏 ...
- [King.yue]Grid列赋值文本,隐藏Value
例:public string InputFormat 加扩展属性:public string InputFormatText 构造函数中根据Key取到Value的值: var data = Data ...
- [原]loadrunner中数据库数据参数化
作者:liuheng123456 发表于2013-11-25 14:11:10 原文链接 阅读:228 评论:0 查看评论