【Python3爬虫】为什么你的博客没人看呢?
我相信对于很多爱好和习惯写博客的人来说,如果自己的博客有很多人阅读和评论的话,自己会非常开心,但是你发现自己用心写的博客却没什么人看,多多少少会觉得有些伤心吧?我们今天就来看一下为什么你的博客没人看呢?
一、页面分析
首先进入博客园首页,可以看到一页有20篇博客简介,然后有200页,也就是说总共有20*200=4000篇博客。这时我们点击下一页,可以看到网页上的链接变成了https://www.cnblogs.com/#p2,看起来好像很简单--只需要改变#p后面的数字就好了,真的是这样吗?打开开发者工具,刷新页面,可以找到如下链接:
所携带的参数是这样的:
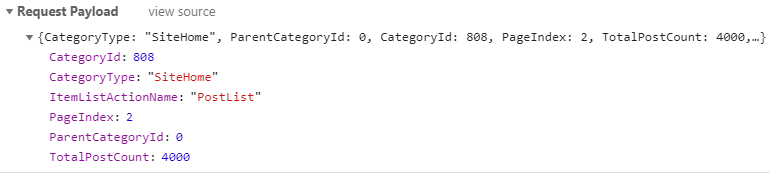
我们很容易就知道只需要改变PageIndex的数值就能实现翻页了。
二、解析网页
返回的结果如下图:

我们可以很方便的使用xpath来解析,相关代码如下:
et = etree.HTML(html)
title_list = et.xpath('//*[@class="post_item_body"]/h3/a/text()') # 标题
author_list = et.xpath('//*[@class="post_item_foot"]/a/text()') # 作者
time_list = et.xpath('//*[@class="post_item_foot"]/text()') # 发布时间
read_list = et.xpath('//*[@class="post_item_foot"]/span[2]/a/text()') # 阅读数
comment_list = et.xpath('//*[@class="post_item_foot"]/span[1]/a/text()') # 评论数
这里得到的数据都是”发布于 2019-01-23 14:16“、”评论(0)“、”阅读(86)“这种,这样显然不利于我们对数据进行分析,所以还需要进行一下处理,相关代码如下:
# 处理数据
time_list = [i.strip().lstrip('发布于 ') for i in time_list if i.strip() != '']
comment_list = [int(i.strip().strip('评论(').rstrip(')')) for i in comment_list]
read_list = [int(i.strip().strip('阅读(').rstrip(')')) for i in read_list]
三、存储数据
这次我使用的数据库是MySQL数据库,首先创建一个数据表blogs,SQL代码如下:
create table if not exists blogs(
title varchar(100) not null,
author varchar(30) not null,
rtime varchar(30) not null,
readnum int(6) not null,
commentnum int(6) not null);
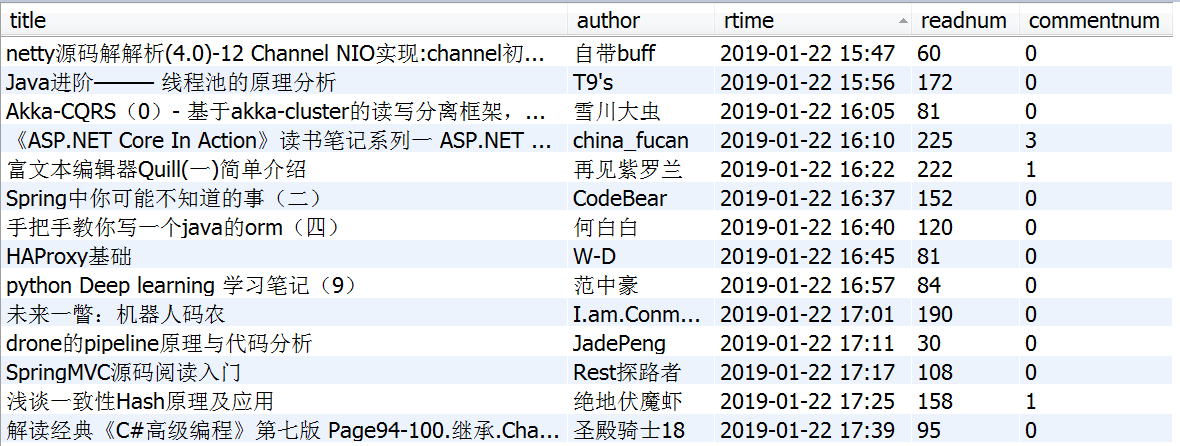
然后就可以把爬取的数据都保存到数据库里,最后进入数据库查看一下:
四、数据分析
大家都是几点写博客的呢?什么时候写的博客会被更多人看到呢?这里我们可以建一个字典dic1,一个数字代表一个小时,其对应的值就是这个小时里发布的博客的数量之和,如下:
dic1 = {
0: 0, 1: 0, 2: 0, 3: 0, 4: 0, 5: 0, 6: 0, 7: 0, 8: 0, 9: 0, 10: 0, 11: 0, 12: 0,
13: 0, 14: 0, 15: 0, 16: 0, 17: 0, 18: 0, 19: 0, 20: 0, 21: 0, 22: 0, 23: 0,
}同理还可以建立一个一样的字典dic2,但是dic2中每个键的值是这个小时里发布的博客的阅读量之和。
由于一天的数据量比较小,也不能说明问题,然后通过查看数据库中的数据,可以知道最近的一篇博客是2019年1月22日写的,而最早的一篇的博客是2018-11-22日写的,所以我们可以把2018年12月整个月的数据提取出来进行分析,这样的话数据量不算少,得到的结果也就更有说服力。相关代码如下:
# 查看2018年12月的数据
day_list = ["2018-12-{}".format(str(i).zfill(2)) for i in range(1, 32)]
for day in day_list:
results = [i for i in all_data if day in i[0]]
for result in results:
t = int(result[0].split(' ')[1].split(':')[0])
dic1[t] += 1
dic2[t] += result[1]
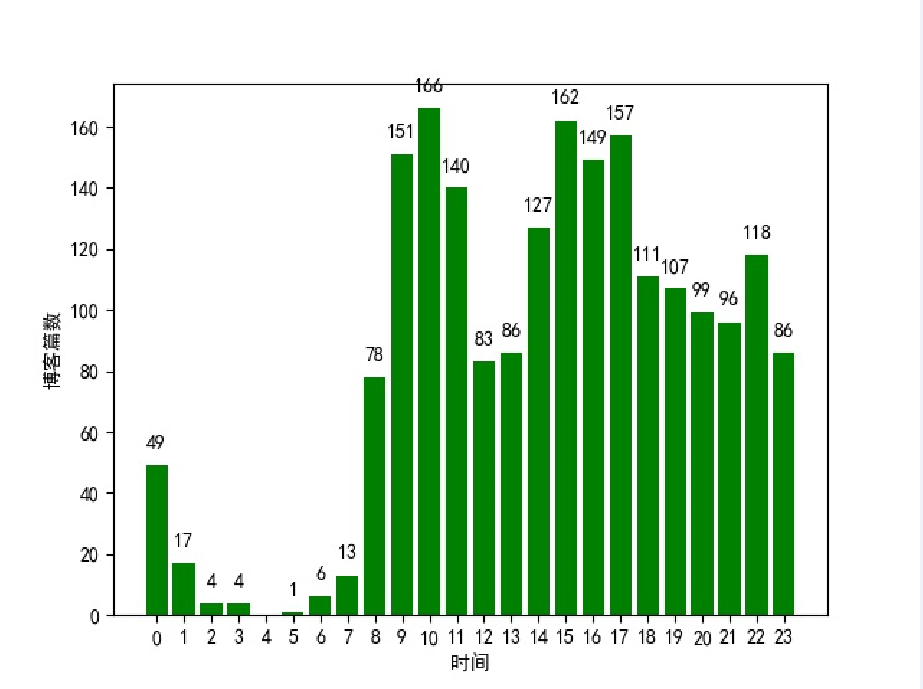
最后根据结果绘制柱状图。
每小时发布的博客篇数:
每小时发布的博客阅读数:
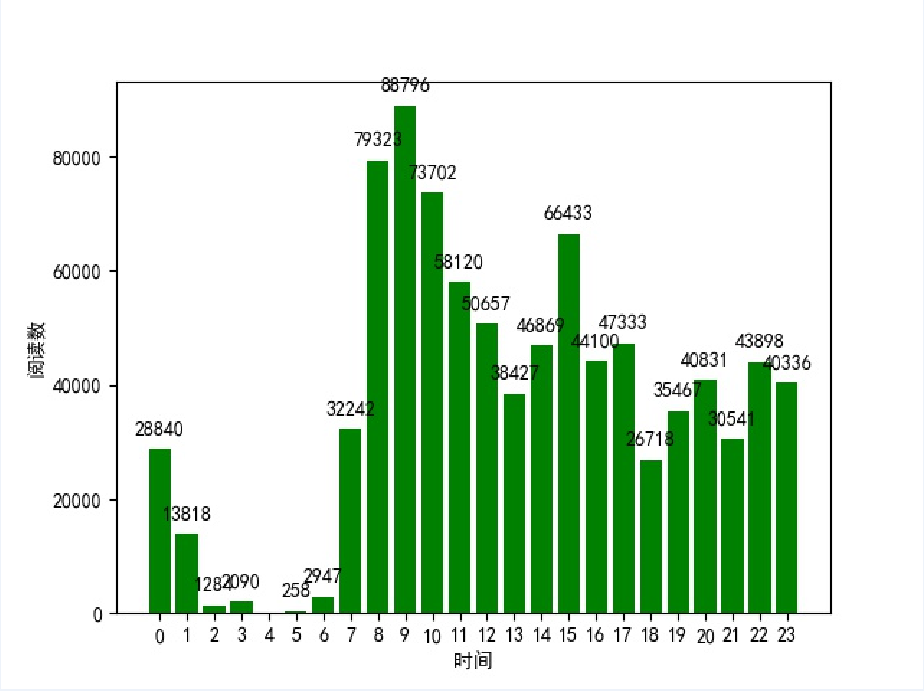
从第一张图可以看到在早上9点-11点和下午3点-5点是发布博客的高峰期,在中晚饭时段也有不少人发博客,还有很多人选择在晚上下班之后写博客,比较意外的是凌晨三四点的时候也有人写博客,可以说是很厉害了。根据第二张图可以知道在早上8点-10点发的博客比较容易得到高阅读量,下午2点-5点也是比较不错的写博客的时间,而凌晨写博客的话就比较难被大家看到了,毕竟这个时候大多数人还在梦乡之中。要想你的博客被更多人看到和喜欢,除了选择一个合适的写博客的时间,最重要的就是用心写出一篇好的博客!
完整代码已上传到GitHub!
【Python3爬虫】为什么你的博客没人看呢?的更多相关文章
- c#代码 天气接口 一分钟搞懂你的博客为什么没人看 看完python这段爬虫代码,java流泪了c#沉默了 图片二进制转换与存入数据库相关 C#7.0--引用返回值和引用局部变量 JS直接调用C#后台方法(ajax调用) Linq To Json SqlServer 递归查询
天气预报的程序.程序并不难. 看到这个需求第一个想法就是只要找到合适天气预报接口一切都是小意思,说干就干,立马跟学生沟通价格. 不过谈报价的过程中,差点没让我一口老血喷键盘上,话说我们程序猿的人 ...
- 【java爬虫】---爬虫+jsoup轻松爬博客
爬虫+jsoup轻松爬博客 最近的开发任务主要是爬虫爬新闻信息,这里主要用到技术就是jsoup,jsoup 是一款 Java的HTML解析器,可直接解析某个URL地址.HTML文本内容.它提供了一套非 ...
- Python爬虫简单实现CSDN博客文章标题列表
Python爬虫简单实现CSDN博客文章标题列表 操作步骤: 分析接口,怎么获取数据? 模拟接口,尝试提取数据 封装接口函数,实现函数调用. 1.分析接口 打开Chrome浏览器,开启开发者工具(F1 ...
- 没人看系列-----html随笔
<!DOCTYPE> 目录 没人看系列-----html/css详解 前言 不多说这段时间写了好多好多前端的东西,以至于自己重新返回看了一遍前端的所有技术.故此做个总结,准备学东西的请绕行 ...
- 没人看系列----css 随笔
目录 没人看系列----css 随笔 没人看系列----html随笔 前言 没什么要说的就是自己总结,学习用的如果想学点什么东西,请绕行. CSS (Cascading Style Sheets)层叠 ...
- 写博客没高质量配图?python爬虫教你绕过限制一键搜索下载图虫创意图片!
目录 前言 分析 理想状态 爬虫实现 其他注意 效果与总结 @(文章目录) 前言 在我们写文章(博客.公众号.自媒体)的时候,常常觉得自己的文章有些老土,这很大程度是因为配图没有选好. 笔者也是遇到相 ...
- JAVA爬虫挖取CSDN博客文章
开门见山,看看这个教程的主要任务,就去csdn博客,挖取技术文章,我以<第一行代码–安卓>的作者为例,将他在csdn发表的额博客信息都挖取出来.因为郭神是我在大学期间比较崇拜的对象之一.他 ...
- 博客没内容可写了怎么办?找BD!
博客写了一段时间可能会感觉没内容可以写了,或者说同一个领域的内容写多了感觉有点千篇一律,这时要考虑扩展自己的写作领域,怎么去扩展呢?利用关键词工具可以衍生很多长尾词,当然这个有点牵强,有点为优化而优化 ...
- “希希敬敬对”团队--‘百度贴吧小爬虫’Alpha版本展示博客
希希敬敬对的 Alpha阶段测试报告 随笔链接地址 https://www.cnblogs.com/xiaoyoushang/p/10078826.html Alpha版本发布说明 随笔链接地址 ...
随机推荐
- 关于MySQL死锁
最近项目中遇到一个问题,使用Spring事务嵌套时,导致MySQL死锁.记录一下,时刻提醒自己. 场景如下, 事务嵌套, 最外层有默认事务, 嵌套一个独立事务, 独立事务和外部事务同时操作一张表.
- 在MFC中对Excel的一些操作
首先要在程序中加载CExcel.h和CExcel.cpp文件,这里面包装了很多函数和对Excel文件的操作,下面所有程序中的m_excel都是类CExcel的对象,如: private: _Appli ...
- SDOI2017 BZOJ 4820 硬币游戏 解题报告
写在前面 此题网上存在大量题解,但本人太菜了,看了不下10篇均未看懂,只好自己冷静分析了.本文将严格详细地论述算法(避免一切意会和玄学),因此可能会比其它题解更加理论化一些,希望能对像我一样看了其它题 ...
- ACM——八大输出方式总结
个人做题总结,希望能够帮助到未来的学弟学妹们的学习! 永远爱你们的 ----新宝宝 1: 题目描述 Your task is to Calculate a + b. Too easy?! Of cou ...
- 事务处理中如何获取同一个connection 对象
运用线程内部的map属性,将对象绑定到ThreadLocal中: 具体实现: 1.新建一个绑定Connection对象的单例类 public class ConnectionBind { privat ...
- 读书笔记--Android Gradle权威指南(下)
前言 最近看了一本书<Android Gradle 权威指南>,收获挺多,就想着来记录一些读书笔记,方便后续查阅. 本篇内容是基于上一篇:读书笔记--Android Gradle权威指南( ...
- MongoDB面试题
1.什么是MongoDB MongoDB是一个文档数据库,提供好的性能,领先的非关系型数据库.采用BSON存储文档数据.BSON()是一种类json的一种二进制形式的存储格式,简称Binary JSO ...
- Bug的严重等级和优先级别与分类
一. Bug的严重等级定义: 1. Blocker 即系统无法执行.崩溃或严重资源不足.应用模块无法启动或异常退出.无法测试.造成系统不稳定. 严重花屏 内存泄漏 用户数据丢失或破坏 系统崩溃/死机/ ...
- Spark学习之Spark调优与调试(一)
一.使用SparkConf配置Spark 对 Spark 进行性能调优,通常就是修改 Spark 应用的运行时配置选项.Spark 中最主要的配置机制是通过 SparkConf 类对 Spark 进行 ...
- 一个C#程序员学习微信小程序的笔记
客户端打开小程序的时候,就将代码包下载到本地进行解析,首先找到了根目录的 app.json ,知道了小程序的所有页面. 在这个Index页面就是我们的首页,客户端在启动的时候,将首页的代码装载进来,通 ...