ArrayList 和 LinkedList 源码分析
List 表示的就是线性表,是具有相同特性的数据元素的有限序列。它主要有两种存储结构,顺序存储和链式存储,分别对应着 ArrayList 和 LinkedList 的实现,接下来以 jdk7 代码为例,对这两种实现的核心源码进行分析。
1. ArrayList 源码分析
ArrayList 是基于数组实现的可变大小的集合,底层是一个 Object[] 数组,可存储包括 null 在内的所有元素,默认容量为 10。元素的新增和删除,本质就是数组元素的移动。
1.1 add 操作
ArrayList 内部有一个 size 成员变量,记录集合内元素总数,add 操作的本质就是 elementData[size++] = e,为了保证插入成功,会按需对数组进行扩容,扩容代码如下:
private void grow(int minCapacity) {
// 有可能会溢出
int oldCapacity = elementData.length;
// 相当于 oldCapacity+(oldCapacity/2),扩大 1.5 倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 确保新容量不小于 minCapacity
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
// 检查扩充的最小容量是否溢出,如果溢出值会小于 0
newCapacity = hugeCapacity(minCapacity);
// 生成一个新数组,旧数组没有被引用会被垃圾回收
elementData = Arrays.copyOf(elementData, newCapacity);
}
add 操作还有一个指定位置的插入,来看具体实现(本文首发于微信公众号:顿悟源码,qq交流群:673986158):
public void add(int index, E element) {
// 检查下标是否有效
// 可能会抛出 IndexOutOfBoundsException 异常
rangeCheckForAdd(index);
// 确保足够的容量插入成功
ensureCapacityInternal(size + 1); // Increments modCount!!
// 把从 index 位置开始的所有元素后移一位
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
// 插入新元素
elementData[index] = element;
size++; // 总数加 1
}
1.2 remove 操作
remove 分为两种,按下标删除和按元素删除。按元素首先会遍历找到匹配元素的位置下标,然后按下标进行删除:
public E remove(int index) {
// 检查下标位置是否有效
rangeCheck(index);
// 更新列表结构的修改次数
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
// 将 index 后的所有元素前移一位
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
// 释放引用
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
1.3 遍历
常见的遍历代码如下:
for (int i=0; i<list.size(); i++) {
list.get(i); // do something
}
这种遍历方式的缺点是,在遍历过程中如果修改集合结构(比如调用 remove 或 add),没有任何异常,可能会导致意想不到的输出,另外一种遍历方式,比如:
for (T obj:list) {
// do something
}
遍历的过程中,如果使用不正当的删除操作(比如list.remove)就会抛出 ConcurrentModificationException,因为它默认使用的 Iterator 遍历方式。
Iterator 是 jdk 为所有集合遍历而设计,并且是 fail-fast 快速失败的。在 iterator 遍历过程中,如果 List 结构不是通过迭代器本身的 add/remove 方法而改变,那么就会抛出 ConcurrentModificationException。注意,在不同步修改的情况下,它不能保证会发生,它只是尽力检测并发修改的错误。
fail-fast 是通过一个 modCount 字段来实现的,这个字段记录了列表结构的修改次数,当调用 iterator() 返回迭代器时,会缓存 modCount 当前的值,如果这个值发生了不期望的变化,那么就会在 next, remove 操作中抛出异常,核心代码如下:
private class Itr implements Iterator<E> {
int cursor; // 下一个要返回的元素下标,初始为 0
// 最后一个返回的元素下标,-1 表示没有元素
int lastRet = -1;
// 缓存 modCount 的值
int expectedModCount = modCount;
// 是否还有元素可读
public boolean hasNext() {
return cursor != size;
}
public E next() {
// 检查 modCount 值是否变化
checkForComodification();
int i = cursor; // 元素下标
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
// 调用 iterator 自身的 remove
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
// 删除元素,此时 modCount 值改变
ArrayList.this.remove(lastRet);
// 移除会把lastRet后面的元素前移一位
cursor = lastRet; // 所以还是从 lastRet 开始读
lastRet = -1;
// 重置 modCount 期望值
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
final void checkForComodification() {
// 如果变化,检测到并发修改,抛出异常
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
2. LinkedList 源码分析
LinkedList 底层是一个双向链表,它不仅实现了 List 接口,还实现了 Deque 接口,所以既可以把它当作一般线性表,也可当作受限线性表主要是栈和队列。
双向链表的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点,LinkedList 中的节点定义如下:
private static class Node<E> {
E item;// 数据
Node<E> next; // 后继节点
Node<E> prev; // 前驱节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
它包含三个成员变量:
- int size = 0: 结点总数
- Node first: 头结点
- Node last: 尾结点
2.1 头插法和尾插法
链表插入时有两种插入方法,头插法和尾插法,关键操作就是正确的断链和续链。头插法的代码如下:
private void linkFirst(E e) {
// 使用临时变量指向头节点
final Node<E> f = first;
// 新节点前驱为 null,后继为 first
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null) // 链表为空,同时为最后一个节点
last = newNode;
else // 否则作为前驱节点
f.prev = newNode;
size++;
modCount++;
}
头插法的结果是逆序的,尾插法的结果是顺序的。尾插法的操作也比较简单,直接修改 last 引用即可:
void linkLast(E e) {
// 使用临时变量指向尾节点
final Node<E> l = last;
// 新节点前驱为 last,后继为 null
final Node<E> newNode = new Node<>(l, e, null);
// 重置 last 指向节点
last = newNode;
if (l == null)// 链表为空
first = newNode; // 第一个节点
else // 否则作为前一个的后继
l.next = newNode;
size++; // 更新列表总数和结构修改次数
modCount++;
}
头插和尾插都只修改了一个引用,比较复杂的是在中间某个位置插入,其原理和代码如下:
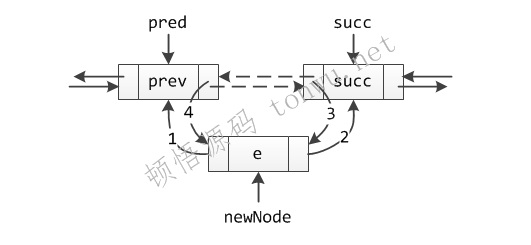
// 在非null节点succ之前插入元素e
void linkBefore(E e, Node<E> succ) {
// assert succ != null; 以下代码顺序不能变
// 记住 succ 的前驱节点
final Node<E> pred = succ.prev;
// 1-2 创建一个新节点,它的前驱指向 pred,后继指向 succ
final Node<E> newNode = new Node<>(pred, e, succ);
// 3 succ 前驱指向新节点
succ.prev = newNode;
if (pred == null) // 如果是第一个节点
first = newNode; // 让first也指向新节点
else // 4 否则作为 pred 的后继节点
pred.next = newNode;
size++; // 元素总数加1
modCount++; // 列表结构修改次数加1
}
2.2 删除节点
同样的删除也是分为从头或尾删除,头节点的删除,就是让 first 指向它的后继节点,代码如下:
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
// 为了返回元素的数据
final E element = f.item;
// 临时变量引用头节点的后继节点
final Node<E> next = f.next;
// 释放头节点,全部至 null
f.item = null;
f.next = null; // help GC
// 重置 first 引用
first = next;
// 如果删除的链表是最后一个节点
if (next == null)
last = null;
else // 头节点的前驱为 null
next.prev = null;
size--;
modCount++;
return element;
}
尾节点的删除,一样是修改 last 引用,让它指向它的前驱节点,与头节点删除逻辑差不多,可对照理解,代码如下:
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
如果在某个中间位置删除,就需要正确的操作了,主要是防止在断链的过程中导致整个链条断开,代码如下:
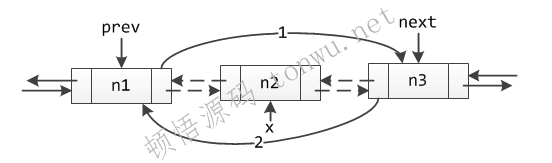
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
// 待删除元素的前驱和后继节点
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
// 链表为空
first = next;
} else {
// 1 前驱节点的后继指向 x 的后继节点
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
// 2 后继节点的前驱指向 x 的前驱节点
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
2.3 栈和队列
栈就是只能在栈顶操作,后进先出的受限线性表,LinkedList 提供的与栈相关的方法有:
- push(E e): 将元素插入栈顶,也就是插到列表的头,实际调用的是 linkFirst
- pop(): 从栈顶弹出一个元素,也就是删除并返回列表的第一个元素,实际调用的是 unlinkFirst
- peek(): 查看栈顶元素,不会删除
- peekFirst(),peekLast(): 分别是查看栈顶和栈尾元素
队列就是只能从一端插入,另一端删除的线性表,LinkedList 提供的与队列相关的方法:
- offer(E e): 入队列,将元素插入列表尾部,实际调用的是 linkLast
- offerFirst,offerLast: 分别是从头开始或从尾开始入队,当然了,确认在哪端就不要更改了
- remove(): 出队列,将列表头结点删除并返回
- removeFirst,removeLast: 与 offerFirst,offerLast 搭配使用
2.4 遍历
双链表有两种遍历方式:顺序遍历和逆序遍历,分别通过 ListItr 和 DescendingIterator 实现。同样这个 Iterator 也是快速失败的,其中 ListItr 分别提供了向前和向后的遍历方式,DescendingIterator 只是简单对 ListItr previous() 方法使用的封装,ListItr 核心代码如下:
private class ListItr implements ListIterator<E> {
private Node<E> lastReturned = null;// 最后返回的节点
private Node<E> next;// 下一个要读的节点
private int nextIndex;// 下一个要读的节点位置
// 缓存列表结构修改次数,检查并发修改
private int expectedModCount = modCount;
// 初始化开始遍历的位置,node(index) 会遍历找到这个节点
ListItr(int index) {
// assert isPositionIndex(index);
next = (index == size) ? null : node(index);
nextIndex = index;
}
// 顺序读时,判断是否还有更多的后继节点
public boolean hasNext() {
return nextIndex < size;
}
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next; // 移动 next 指向其后继节点
nextIndex++;
return lastReturned.item;
}
// 逆序读时,判断是否还有更多的前驱节点
public boolean hasPrevious() {
return nextIndex > 0;
}
public E previous() {
checkForComodification();
if (!hasPrevious())
throw new NoSuchElementException();
// 移动 next 指向其前驱节点
lastReturned = next = (next == null) ? last : next.prev;
nextIndex--;
return lastReturned.item;
}
public void remove() {
// 遍历过程中,提供删除操作
}
public void add(E e) {
// 遍历过程中,提供新增操作
}
// 检查是否存在并发修改
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
3. 非线程安全
ArrayList 和 LinkedList 都是非线程安全的,那为什么呢?
ArrayList 本质操作可分为以下两类,这也是线程竞争条件的所在:
- 对 size 变量的操作,size++ 和 --size
- System.arraycopy() 数组拷贝
size++ 其实是一个复合操作:取值、加1和赋值,不是原子操作,非线程安全;System.arraycopy 它也是非线程安全的,所以 ArrayList 不是线程安全的。
LinkedList 主要竞争条件就是断链和续链的操作,以尾插为例,假如线程 A 执行:
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
如果现在线程 A 被抢占,线程 B 也执行相同的代码,并且继续执行:
last = newNode;
不久后,线程 A 也执行上述代码,那么问题就出来了,线程 B 完成操作后,线程 A 就操作了一次,导致线程 B 的要插入的节点丢失,所以不是线程安全的。
当然了 JDK 提供了 Collections.synchronizedList(List) 方法可以把 ArrayList 和 LinkedList 变成线程安全的。
4. 性能
ArrayList 具备数组随机访问的特性,但增加和删除需要移动数组元素,效率较慢。在动态扩容时,涉及到了内存拷贝,所以适当增加初始容量或者在添加大量数据之前提前扩大容量,减少拷贝次数是有必要的。
相比 ArrayList,LinkedList 只能顺序或逆序访问,占用的内存稍微大点,因为节点还要维护两个前后引用,但是它的插入删除效率高。
5. 小结
这两个是很常用的数据结构,也比较容易理解,在阅读源码时,jdk里类的设计,编码方式也值得去重视。
ArrayList 和 LinkedList 源码分析的更多相关文章
- List中的ArrayList和LinkedList源码分析
List是在面试中经常会问的一点,在我们面试中知道的仅仅是List是单列集合Collection下的一个实现类, List的实现接口又有几个,一个是ArrayList,还有一个是LinkedLis ...
- ArrayList和LinkedList源码分析
ArrayList 非线程安全 ArrayList内部是以数组存储元素的.类有以下变量: /*来自于超类AbstractList,使用迭代器时可以通过该值判断集合是否被修改*/ protected t ...
- java基础解析系列(十)---ArrayList和LinkedList源码及使用分析
java基础解析系列(十)---ArrayList和LinkedList源码及使用分析 目录 java基础解析系列(一)---String.StringBuffer.StringBuilder jav ...
- Java集合之LinkedList源码分析
概述 LinkedLIst和ArrayLIst一样, 都实现了List接口, 但其内部的数据结构不同, LinkedList是基于链表实现的(从名字也能看出来), 随机访问效率要比ArrayList差 ...
- java集合系列之LinkedList源码分析
java集合系列之LinkedList源码分析 LinkedList数据结构简介 LinkedList底层是通过双端双向链表实现的,其基本数据结构如下,每一个节点类为Node对象,每个Node节点包含 ...
- Java入门系列之集合LinkedList源码分析(九)
前言 上一节我们手写实现了单链表和双链表,本节我们来看看源码是如何实现的并且对比手动实现有哪些可优化的地方. LinkedList源码分析 通过上一节我们对双链表原理的讲解,同时我们对照如下图也可知道 ...
- ArrayList详解-源码分析
ArrayList详解-源码分析 1. 概述 在平时的开发中,用到最多的集合应该就是ArrayList了,本篇文章将结合源代码来学习ArrayList. ArrayList是基于数组实现的集合列表 支 ...
- LinkedList 源码分析(JDK 1.8)
1.概述 LinkedList 是 Java 集合框架中一个重要的实现,其底层采用的双向链表结构.和 ArrayList 一样,LinkedList 也支持空值和重复值.由于 LinkedList 基 ...
- 集合之LinkedList源码分析
转载请注明出处:http://www.cnblogs.com/qm-article/p/8903893.html 一.介绍 在介绍该源码之前,先来了解一下链表,接触过数据结构的都知道,有种结构叫链表, ...
随机推荐
- istio收集Metrics和日志信息
1.切换到istio根目录 cd /data/istio/istio-0.7.1 2.安装prometheus kubectl apply -f install/kubernetes/addons/p ...
- Oracle12c中分区(Partition)新特性之TRUNCATEPARTITION和EXCHANGE PARTITION级联功能
TRUNCATE [SUB]PARTITION和EXCHANGE [SUB]PARTITION命令如今可以包括CASCADE子句,从而允许参照分区表向下级联这些操作.为确保该选项正常,相关外键也必须包 ...
- 杨老师课堂_Java核心技术下之控制台模拟微博用户注册案例
案例设计背景介绍: 编写一个新浪微博用户注册的程序,要求使用HashSet集合实现. 假设当用户输入用户名.密码.确认密码.生日(输入格式yyyy-mm-dd为正确).手机号码(手机长度为11位,并 ...
- Python_字符串之删除空白字符或某字符或字符串
''' strip().rstrip().lstrip()分别用来删除两端.右端.左端.连续的空白字符或字符集 ''' s='abc ' s2=s.strip() #删除空白字符 print(s2) ...
- mac的terminal快捷键
mac终端terminal快捷键: Command + K 清屏 Command + T 新建标签 Command +W 关闭当前标签页 Command + S 保存终端输出 Command + ...
- mysqldump+系统计划任务定时备份MySql数据
MYSQL 数据库备份有很多种(cp.tar.lvm2.mysqldump.xtarbackup)等等,具体使用哪一个还要看你的数据规模.下面给出一个表 #摘自<学会用各种姿态备份Mysql数据 ...
- Centos7搭建hadoop完全分布式
虽然说是完全分布式,但三个节点也都是在一台机器上.拿来练手也只能这样咯,将就下.效果是一样滴.这个我自己都忘了步骤,一起来回顾下吧. 必备知识: Linux基本命令 vim基本命令 准备软件: VMw ...
- EF生成模型出现异常:表“TableDetails“中列“IsPrimaryKey”的值为DBNull解决方法
Entity Framework连接MySQL时:由于出现以下异常,无法生成模型:"表"TableDetails"中列"IsPrimaryKey"的值 ...
- MyBatis-Spring中间件逻辑分析(怎么把Mapper接口注册到Spring中)
1. 文档介绍 1.1. 为什么要写这个文档 接触Spring和MyBatis也挺久的了,但是一直还停留在使用的层面上,导致很多时候光知道怎么用,而不知道其具体原理,这样就很难做一 ...
- 安装scrapy出错Failed building wheel for Twisted
用64位windows10的CMD命令安装pip install scrapy出错: Running setup.py bdist_wheel for Twisted ... error Failed ...