《深入理解Java虚拟机》学习笔记(一)
JDK是支持Java程序开发的最小环境集,JRE是支持Java程序运行的标准环境,JRE是JDK的一部分。
Java 1.0版本诞生于1995年,其使用的虚拟机是Sun Classisc VM,这款虚拟机已经不再使用。JDK1.3时,HotSpot VM成为了默认的虚拟机。其他较为出名的Java虚拟机还包括JRockit、J9等。
JDK1.5中的java.util.concurrent包实现了一个粗粒度的并发框架,JDK1.7中的java.util.concurrent.forkjoin包则是对该框架的一次重要扩充。Fork/Join是处理并行的一个经典的方法,能够轻松地利用多个CPU,利用Fork/Join模式,我们可以顺利地过渡到多核时代。
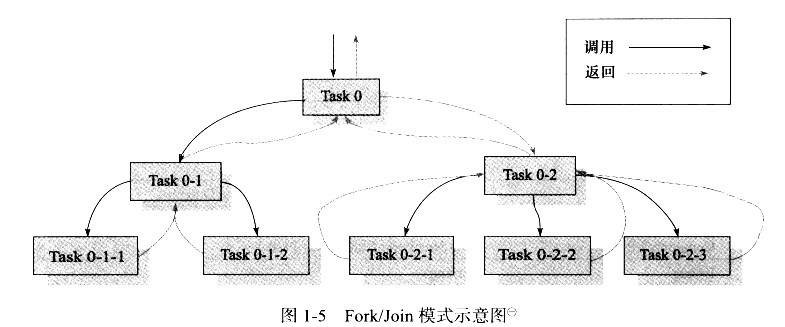
Java 8中,将会提供对lamda的支持,函数式编程将会得到很好地支持,而函数式编程的一个重要特点就是适合并行运算。
由于指针膨胀和各种数据类型对齐补白等原因,64位的Java虚拟机的效率要比32位的Java虚拟机效率低。企业级J2EE经常需要4GB以上的内存,目前很多仍采用虚拟集群方式在32位虚拟机中运行,迫切需要64位虚拟机的支持。
Java虚拟机在运行Java程序时会将它所管理的内存划分为若干不同的区域。这些区域有着各自的用途,以及创建和销毁时间。根据《Java虚拟机规范(Java SE7版)》的规定,Java虚拟机将会把它所管理的内存划分为下面的几个区域:

我们可以看到运行时数据区中的方法区和堆是由所有的线程所共享的,其余的如虚拟机栈、本地方法栈、程序计数器都是线程间隔离的。
程序计数器,可以看做当前线程所执行的字节码的行号指示器。字节码解释器通过程序计数器中的值来选取下一条下一条需要执行的字节码指令。循环、跳转、异常都需要依赖于程序计数器来完成。
执行多线程的程序时,为了确保线程切换后能恢复到正确的执行位置,每个线程都需要一个独立的程序计数器。
此区域是唯一一个在Java虚拟机规范中没有规定OutOfMemoryError的区域。
Java虚拟机栈,Java虚拟机栈是线程私有的,它的生命周期和线程相同。Java虚拟机栈包含的信息包括:局部变量、操作数栈、动态链接、方法出口等。
Java虚拟机中针对这块内存定义了2种异常,如果线程请求的栈深度大于虚拟机所允许的深度,将会抛出StackOverflowError异常,如果虚拟机栈无法申请到足够的内存,就会抛出OutOfMemoryError异常。
本地方法栈,本地方法栈和Java虚拟机栈的作用很相似,只是本地方法栈是为Java虚拟机的Native方法服务的。很多的虚拟机(例如HotSpot)就直接将本地方法栈和Java虚拟机栈合二为一。
Java堆,Java堆的目的是存放对象实例。Java堆是垃圾回收管理器管理的主要区域,Java堆可以分为新生代和老生代,再具体一点可以分为Eden空间、From Survivor、To Survivor等。
Java堆可以是物理上不连续的空间,只要是逻辑上连续即可。
主流Java虚拟机中的Java堆都是可变的,通过-Xmx和-Xms来控制。
Java堆上无法申请内存时也会抛出OutOfMemoryError异常。
方法区和Java堆一样,也是线程间共享的内存区域。方法区主要用于存储类信息、常量、静态变量等数据。
对应HotSpot虚拟机而言,方法区可以被看做是永生代。但并非数据进入了方法区就不会被回收,方法区的回收主要是常量池的回收和类型的卸载。
对应HotSpot虚拟机而言,方法区可以被看做是永生代。但并非数据进入了方法区就不会被回收,方法取得回收主要是常量池的回收和对类型的卸载。
static是静态变量,在每次赋值的时候保留最后一个值·是属于类变量,通过类或者对象可以修改,而final是属于常量,赋值一次,不可以再次重新赋值。
对象的内存布局:
在HotSpot虚拟机中,对象在内存中所占空间可以分为3部分:对象头、实例数据和对象填充。
对象头用于存储对象的状态数据,如对象的哈希码,GC分代年龄,锁状态,持有的锁,偏向线程ID,偏向时间戳等。这部分的数据在32位和64位的虚拟机中所占的内存大小为32bit和64bit。
实例数据将会记录父类和该类中存储的有效信息,相同长度的变量会被放在一起,例如long型和double型的数据。
对象填充的目的是保证对象所占内存的大小是8个字节的大小。
对象的访问定位:
目前主流的对象定位方式有2种:句柄方式和直接指针方式。
句柄方式时,reference中存储的是句柄的地址,句柄中则包含了具体数据的信息。
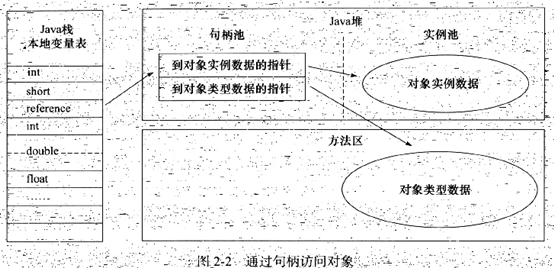
直接指针方式,reference中存储的就是对象内存地址的信息。

使用句柄方式的好处是,对象被移动时(垃圾回收内存重新分配地址)只会改变句柄中实例的指针,而reference不需要做修改。
使用直接指针方式的好处是,节省了一次指针定位的时间开销。HotSpot虚拟机使用的是直接指针方式来访问对象。
指针是指向内存中的一个物理地址,可运行该物理地址的内容;而句柄则是一个四字节的整数(由操作系统管理),应用程序靠句柄来找到要引用的对象,但操作系统可以对句柄做统一的管理。
Java内存溢出的例子
首先是Java堆内存溢出的例子
public class HeapOOM {
static class OOMObject{
}
public static void main(String [] args){
List<OOMObject> list = new ArrayList<OOMObject>();
while(true){
list.add(new OOMObject());
}
}
}
eclipse中debug参数中设置:
-Xmx20m -Xms20m -XX:+HeapDumpOnOutOfMemoryError
打印异常信息:
Dumping heap to java_pid6480.hprof ...
Heap dump file created [22080307 bytes in 0.473 secs]
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
解决这部分的异常,一般的手段就是通过内存映射工具(如JVisualVM)对Dump出来的堆进行分析,看看到底是内存泄露还是内存溢出。
Java栈内存溢出:
由于HotSpot虚拟机并不区分本地方法栈和虚拟机栈,所以栈容量的大小只能由-Xss参数来控制。
操作系统分配给每个进程的内存大小是有限制的,比如32位的windows的就是2GB,减去堆的最大内存Xmx,再减去方法区的内存MaxPermSize,计数器的内存忽略,虚拟机进程的内存不计,剩下的就是本地方法栈和虚拟机栈的空间。每个线程分配的内存越大,可以建立的线程数就越小。
如果是建立的线程数过多导致的内存溢出,在不能减少线程数和更换为64位虚拟机的前提下,只有通过减少单个线程的内存来增加可支持的线程的数目
public class JavaVMStackSOF {
private int stackLength = 1;
public void stackLeak(){
stackLength = stackLength + 1;
System.out.println(stackLength);
stackLeak();
}
public static void main(String [] args){
JavaVMStackSOF sof = new JavaVMStackSOF();
sof.stackLeak();
}
}
eclipse中debug参数中设置:-Xss128k
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程栈大小为1M,以前每个线程栈大小为256K。根据应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一 个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
方法区和运行时常量池溢出
JDK1.7之后将逐步地去除永生代。但是在JDK1.6及之前,常量池也被分配在永生代中。我们可以通过-XX:PermSize和-XX:MaxPermSize来限制方法区的大小,间接地限制常量池的大小,从而观察其溢出的情况。
public class ConstantPoolOOM {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
int i =0;
while(true){
list.add(String.valueOf(i++).intern());
}
}
}
Exception in thread "main" java.lang.OutOfMemoryError: PermGen space
参数的设置格式为:-XX:PermSize=10M -XX:MaxPermSize=10M
String的intern方法的作用是如果常量池中存在该字符串则返回,否则将字符串放到常量池中。
JDK7之后的intern代码做了修改,上面的代码则可以一致运行下去。
方法区存放的是Class的相关信息,如类名,修饰符,常量,方法描述,字段描述等。该内存区域的溢出,可以采用构造大量的类去填满方法区。
需要注意的是使用CGlib来生成的动态类越多,方法区就需要越大的内存来载入Class信息。随着CGLib越来越多的使用,方法区溢出的可能性也会越来越大。
《深入理解Java虚拟机》学习笔记(一)的更多相关文章
- 《Hadoop》大数据技术开发实战学习笔记(二)
搭建Hadoop 2.x分布式集群 1.Hadoop集群角色分配 2.上传Hadoop并解压 在centos01中,将安装文件上传到/opt/softwares/目录,然后解压安装文件到/opt/mo ...
- 《Hadoop大数据技术开发实战》学习笔记(一)
基于CentOS7系统 新建用户 1.使用"su-"命令切换到root用户,然后执行命令: adduser zonkidd 2.执行以下命令,设置用户zonkidd的密码: pas ...
- 超人学院Hadoop大数据技术资源分享
超人学院Hadoop大数据技术资源分享 http://bbs.superwu.cn/forum.php?mod=viewthread&tid=807&fromuid=645 很多其它精 ...
- java大数据最全课程学习笔记(1)--Hadoop简介和安装及伪分布式
Hadoop简介和安装及伪分布式 大数据概念 大数据概论 大数据(Big Data): 指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发 ...
- hadoop大数据技术架构详解
大数据的时代已经来了,信息的爆炸式增长使得越来越多的行业面临这大量数据需要存储和分析的挑战.Hadoop作为一个开源的分布式并行处理平台,以其高拓展.高效率.高可靠等优点越来越受到欢迎.这同时也带动了 ...
- 除Hadoop大数据技术外,还需了解的九大技术
除Hadoop外的9个大数据技术: 1.Apache Flink 2.Apache Samza 3.Google Cloud Data Flow 4.StreamSets 5.Tensor Flow ...
- 大数据技术之_09_Flume学习_Flume概述+Flume快速入门+Flume企业开发案例+Flume监控之Ganglia+Flume高级之自定义MySQLSource+Flume企业真实面试题(重点)
第1章 Flume概述1.1 Flume定义1.2 Flume组成架构1.2.1 Agent1.2.2 Source1.2.3 Channel1.2.4 Sink1.2.5 Event1.3 Flum ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- 大数据技术之_16_Scala学习_01_Scala 语言概述
第一章 Scala 语言概述1.1 why is Scala 语言?1.2 Scala 语言诞生小故事1.3 Scala 和 Java 以及 jvm 的关系分析图1.4 Scala 语言的特点1.5 ...
- 大数据技术之_16_Scala学习_04_函数式编程-基础+面向对象编程-基础
第五章 函数式编程-基础5.1 函数式编程内容说明5.1.1 函数式编程内容5.1.2 函数式编程授课顺序5.2 函数式编程介绍5.2.1 几个概念的说明5.2.2 方法.函数.函数式编程和面向对象编 ...
随机推荐
- [bzoj3048] [Usaco2013 Jan]Cow Lineup
一开始一脸懵逼.. 后来才想到维护一左一右俩指针l和r..表示[l,r]这段内不同种类的数字<=k+1种. 显然最左的.合法的l随着r的增加而不减. 顺便离散化,记一下各个种类数字出现的次数就可 ...
- Open-air shopping malls(二分半径,两元交面积)
http://acm.hdu.edu.cn/showproblem.php?pid=3264 Open-air shopping malls Time Limit: 2000/1000 MS (Jav ...
- java实现死锁的demo
死锁 只有当t1线程占用o1且正好也需要o2,t2此时占用o2且正好也需要o1的时候才会出现死锁,(类似于2个人拿着两个筷子吃饭,都是需要对方的一根筷子才能吃) 以下代码t1线程占用o1,并且获取到o ...
- memcached集群和一致性哈希算法
场景 由于memcached集群各节点之间都是独立的,互不通信,集群的负载均衡是基于客户端来实现的,因此需要客户端用户设计实现负载均衡算法. 取模算法 N个节点,从0->N-1编号,key对N ...
- 织梦首页、列表页调用文章body内容的两种方法
http://blog.csdn.net/langyu1021/article/details/52261411 关于首页.列表页调用文章body内容的两种方法,具体方法如下: 第一种方法: {ded ...
- 跟我一起读postgresql源码(十四)——Executor(查询执行模块之——Join节点(下))
3.HashJoin 节点 postgres=# explain select a.*,b.* from test_dm a join test_dm2 b on a.xxx = b.xxx; QUE ...
- 使用异步方法在XAML中绑定系统时间
最近的工作需要在程序界面上显示实时的系统时间,网上查了查大部分都是用Timer或者线程来实现. 个人非常不喜欢用Timer,感觉这东西有点太耗资源,然后思考了下觉得更好的方法应该是使用异步的方法在委托 ...
- Python+Selenium安装及环境配置
一.Python安装 Window系统下,python的安装很简单.访问python.org/download,下载最新版本,安装过程与其他windows软件类似.记得下载后设置path环境变量,然后 ...
- 2017-07-09(tar who last)
tar gzip ,bzip2对于文件目录压缩支持有限,所以出现了tar命令 tar [选项] 打包文件名 源文件 -c 打包 -v 显示过程 -f 指定打包文件名 -x 解包 -z 压缩成.ta ...
- BFC(块级格式上下文)
BFC的生成 满足下列css声明之一的元素便会生成BFC 根元素 float的值不为none overflow的值不为visible display的值为inline-block.table-cell ...