(二) Keras 非线性回归
视频学习来源
https://www.bilibili.com/video/av40787141?from=search&seid=17003307842787199553
笔记
Keras 非线性回归
import keras import numpy as np import matplotlib.pyplot as plt #Sequential按序列构成的模型 from keras.models import Sequential #Dense全连接层 from keras.layers import Dense
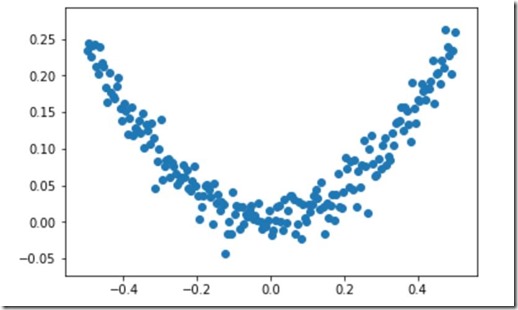
#使用numpy生成200个随机点 x_data=np.linspace(-0.5,0.5,200) #均匀分布 noise=np.random.normal(0,0.02,x_data.shape) #均值为0,方差为0.02 y_data=np.square(x_data)+noise #显示随机点 plt.scatter(x_data,y_data) plt.show()
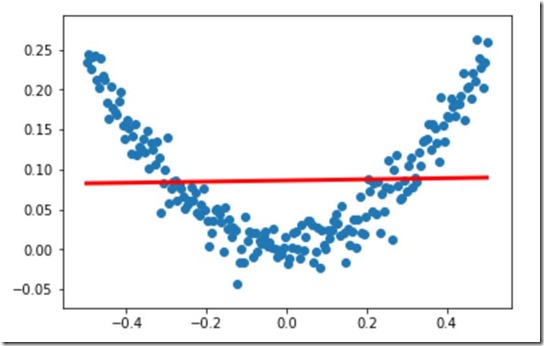
#构建一个顺序模型
model=Sequential()
#在模型中添加一个全连接层
model.add(Dense(units=1,input_dim=1)) #sgd:stochastic gradient descent 随机梯度下降算法
#mse:mean square error 均方误差
model.compile(optimizer='sgd',loss='mse') #训练3000次
for step in range(3000):
#每次训练一个批次
cost=model.train_on_batch(x_data,y_data)
#每500个batch打印一次cost值
if step%500==0:
print('cost:',cost) #x_data输入网络中,得到预测值y_pred
y_pred=model.predict(x_data) #显示随机点
plt.scatter(x_data,y_data)
#显示预测结果
plt.plot(x_data,y_pred,'r-',lw=3)
plt.show()
cost: 0.018438313
cost: 0.006655791
cost: 0.0058503654
cost: 0.0057009794
cost: 0.0056732716
cost: 0.005668133
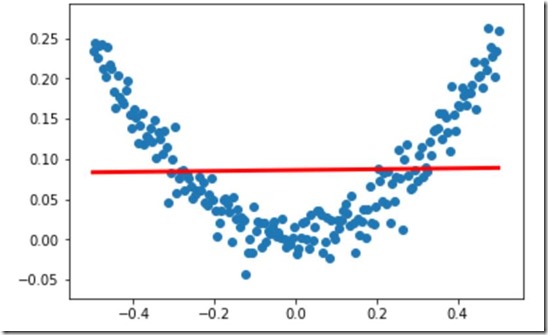
加入隐藏层
#导入SGD,(后面要修改SGD的值)
from keras.optimizers import SGD
#构建一个顺序模型
model=Sequential()
#在模型中添加 1-10-1 ,一个输入,一个输出,中间10个隐藏层
model.add(Dense(units=10,input_dim=1)) #1-10部分
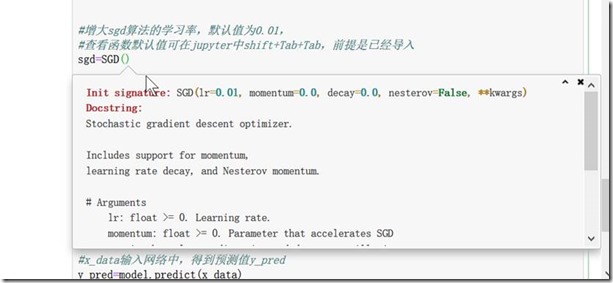
model.add(Dense(units=1)) #10-1部分 等效 model.add(Dense(units=1,input_dim=10)) #增大sgd算法的学习率,默认值为0.01,
#查看函数默认值可在jupyter中shift+Tab+Tab,前提是已经导入
sgd=SGD(lr=0.3) #学习速率0.3 #sgd:stochastic gradient descent 随机梯度下降算法
#mse:mean square error 均方误差
model.compile(optimizer=sgd,loss='mse') #和上面不同的是没有引号 #训练3000次
for step in range(3000):
#每次训练一个批次
cost=model.train_on_batch(x_data,y_data)
#每500个batch打印一次cost值
if step%500==0:
print('cost:',cost) #x_data输入网络中,得到预测值y_pred
y_pred=model.predict(x_data) #显示随机点
plt.scatter(x_data,y_data)
#显示预测结果
plt.plot(x_data,y_pred,'r-',lw=3)
plt.show()
cost: 0.1012776
cost: 0.005666962
cost: 0.005666963
cost: 0.0056669624
cost: 0.005666963
cost: 0.005666963
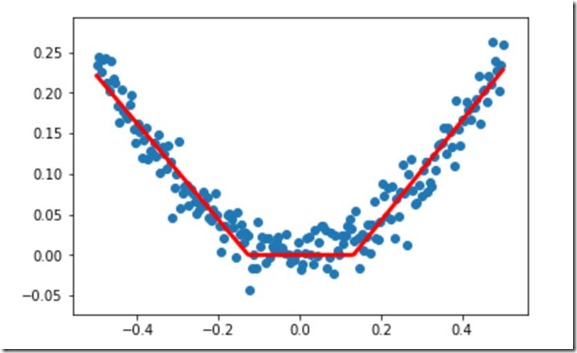
设置激活函数
#设置激活函数,默认的激活函数为none也就是输入=输出,线性
from keras.layers import Dense,Activation
#设置激活函数方式1
#激活函数为tanh #构建一个顺序模型
model=Sequential()
#在模型中添加 1-10-1 ,一个输入,一个输出,中间10个隐藏层
model.add(Dense(units=10,input_dim=1)) #1-10部分 model.add(Activation('tanh')) #双曲正切函数 model.add(Dense(units=1)) #10-1部分 等效 model.add(Dense(units=1,input_dim=10)) model.add(Activation('tanh')) #双曲正切函数 #增大sgd算法的学习率,默认值为0.01,
#查看函数默认值可在jupyter中shift+Tab+Tab,前提是已经导入
sgd=SGD(lr=0.3) #学习速率0.3 #sgd:stochastic gradient descent 随机梯度下降算法
#mse:mean square error 均方误差
model.compile(optimizer=sgd,loss='mse') #和上面不同的是没有引号 #训练3000次
for step in range(3000):
#每次训练一个批次
cost=model.train_on_batch(x_data,y_data)
#每500个batch打印一次cost值
if step%500==0:
print('cost:',cost) #x_data输入网络中,得到预测值y_pred
y_pred=model.predict(x_data) #显示随机点
plt.scatter(x_data,y_data)
#显示预测结果
plt.plot(x_data,y_pred,'r-',lw=3)
plt.show()
cost: 0.049393196
cost: 0.003914159
cost: 0.0011130853
cost: 0.00090270495
cost: 0.00040989672
cost: 0.00045533947

#设置激活函数方式2
#激活函数为relu #jupyter中 注释为 ctrl+/ #构建一个顺序模型
model=Sequential()
#在模型中添加 1-10-1 ,一个输入,一个输出,中间10个隐藏层
model.add(Dense(units=10,input_dim=1,activation='relu')) #1-10部分 model.add(Dense(units=1,activation='relu'))#10-1部分 等效 model.add(Dense(units=1,input_dim=10)) #增大sgd算法的学习率,默认值为0.01,
#查看函数默认值可在jupyter中shift+Tab+Tab,前提是已经导入
sgd=SGD(lr=0.3) #学习速率0.3 #sgd:stochastic gradient descent 随机梯度下降算法
#mse:mean square error 均方误差
model.compile(optimizer=sgd,loss='mse') #和上面不同的是没有引号 #训练3000次
for step in range(3000):
#每次训练一个批次
cost=model.train_on_batch(x_data,y_data)
#每500个batch打印一次cost值
if step%500==0:
print('cost:',cost) #x_data输入网络中,得到预测值y_pred
y_pred=model.predict(x_data) #显示随机点
plt.scatter(x_data,y_data)
#显示预测结果
plt.plot(x_data,y_pred,'r-',lw=3)
plt.show()
cost: 0.0066929995
cost: 0.0004892901
cost: 0.00047061846
cost: 0.00046780292
cost: 0.00046706214
cost: 0.00046700903
shift+Tab+Tab 效果如下
(二) Keras 非线性回归的更多相关文章
- Keras 构建DNN 对用户名检测判断是否为非法用户名(从数据预处理到模型在线预测)
一. 数据集的准备与预处理 1 . 收集dataset (大量用户名--包含正常用户名与非法用户名) 包含两个txt文件 legal_name.txt ilegal_name.txt. 如下图所 ...
- 在Keras模型中one-hot编码,Embedding层,使用预训练的词向量/处理图片
最近看了吴恩达老师的深度学习课程,又看了python深度学习这本书,对深度学习有了大概的了解,但是在实战的时候, 还是会有一些细枝末节没有完全弄懂,这篇文章就用来总结一下用keras实现深度学习算法的 ...
- 文本分类:Keras+RNN vs传统机器学习
摘要:本文通过Keras实现了一个RNN文本分类学习的案例,并详细介绍了循环神经网络原理知识及与机器学习对比. 本文分享自华为云社区<基于Keras+RNN的文本分类vs基于传统机器学习的文本分 ...
- 几个可用于数据挖掘和统计分析的java库
http://itindex.net/blog/2015/01/09/1420751820000.html WEKA:WEKA是一个可用于数据挖掘任务的机器学习算法集合.该算法可以直接应用到数据集或从 ...
- Java第三方工具库/包汇总
一.科学计算或矩阵运算库 科学计算包: JMathLib是一个用于计算复杂数学表达式并能够图形化显示计算结果的Java开源类库.它是Matlab.Octave.FreeMat.Scilab的一个克隆, ...
- 深度学习:Keras入门(二)之卷积神经网络(CNN)
说明:这篇文章需要有一些相关的基础知识,否则看起来可能比较吃力. 1.卷积与神经元 1.1 什么是卷积? 简单来说,卷积(或内积)就是一种先把对应位置相乘然后再把结果相加的运算.(具体含义或者数学公式 ...
- keras实现简单性别识别(二分类问题)
keras实现简单性别识别(二分类问题) 第一步:准备好需要的库 tensorflow 1.4.0 h5py 2.7.0 hdf5 1.8.15.1 Keras 2.0.8 opencv-p ...
- keras系列︱Application中五款已训练模型、VGG16框架(Sequential式、Model式)解读(二)
引自:http://blog.csdn.net/sinat_26917383/article/details/72859145 中文文档:http://keras-cn.readthedocs.io/ ...
- 1.keras实现-->自己训练卷积模型实现猫狗二分类(CNN)
原数据集:包含 25000张猫狗图像,两个类别各有12500 新数据集:猫.狗 (照片大小不一样) 训练集:各1000个样本 验证集:各500个样本 测试集:各500个样本 1= 狗,0= 猫 # 将 ...
随机推荐
- Thymeleaf【快速入门】
前言:突然发现自己给自己埋了一个大坑,毕设好难..每一个小点拎出来都能当一个小题目(手动摆手..),没办法自己选的含着泪也要把坑填完..先一点一点把需要补充的知识学完吧.. Thymeleaf介绍 稍 ...
- DSAPI中TCP、UDP、HTTP的选择
在DSAPI中,网络通讯主要有以下几种:1 [TCP] TCP服务端 TCP客户端 2 [UDP] UDP服务端 UDP客户端 UDP指令版服务端 UDP指令版客户端 3 [HTTP] HTTP服务端 ...
- 内部类、异常以及 LeetCode 每日一题
1 内部类 内部类的作用: 内部类提供了更好的封装,可以把内部类隐藏于外部类之内,不允许同一个包中的其他类访问该类.(例如给“牛”这个类组合一个“牛腿”,则可以把牛腿定义成内部类,因为牛腿脱离了牛没有 ...
- UiPath如何实现暂停功能?
照理说一个无人值守的机器人原本是不应该有人工操作介入的,也就不会提供暂停功能.但客户可能出于业务需要,或者风险管控的考虑,会需要机器人具备暂停功能.通常,会希望在机器人运行时,用户摁下快捷键,机器人就 ...
- 编程心法 之 敏捷开发(新架构)Agile Team Organization Squads, Chapters, Tribes and Guilds
Agile Team 参考 一般情况下,一个小组有以下功能分布: Squads 每个主要的功能的开发属于一个Squad,比如说QQ这个应用,可以分为QQ空间小组.QQ会员小组等等, 每一个Squad有 ...
- LNMP shell
#!/bin/bash #set -x #date: 2018-12-13 #Description: 一键安装LNMP环境 or LAMP 环境 #Version: 0.4 #Author: sim ...
- Linux 桌面玩家指南:02. 以最简洁的方式打造实用的 Vim 环境
特别说明:要在我的随笔后写评论的小伙伴们请注意了,我的博客开启了 MathJax 数学公式支持,MathJax 使用$标记数学公式的开始和结束.如果某条评论中出现了两个$,MathJax 会将两个$之 ...
- 经典排序算法 — C#版本(中)
归并排序比较适合大规模得数据排序,借鉴了分治思想. 归并排序原理 自古以来,分久必合合久必分. 我们可以这样理解归并排序,分-分到不能分为止,然后合并. 使用递归将问题一点一点分解,最后进行合并. 分 ...
- Hadoop系列005-Hadoop运行模式(下)
本人微信公众号,欢迎扫码关注! Hadoop运行模式(下) 2.3.完全分布式部署Hadoop 1)分析: 1)准备3台客户机(关闭防火墙.静态ip.主机名称) 2)安装jdk 3)配置环境变量 4) ...
- 用ASP.NET Core 2.0 建立规范的 REST API -- DELETE, UPDATE, PATCH 和 Log
本文所需的一些预备知识可以看这里: http://www.cnblogs.com/cgzl/p/9010978.html 和 http://www.cnblogs.com/cgzl/p/9019314 ...