scrapy爬虫 快速入门
Scrapy
1. 简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy 使用了 Twisted异步网络库来处理网络通讯。
1.1.整体架构大致如下
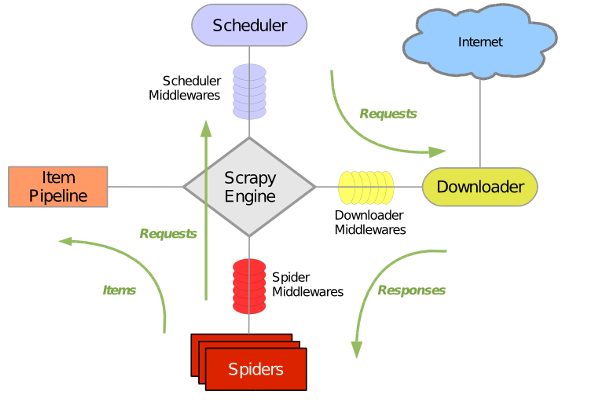
Scrapy主要包括了以下组件:
引擎(Scrapy)
用来处理整个系统的数据流, 触发事务(框架核心)
调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
1.2 运行流程
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
2 安装
安装wheel
pip install wheel
安装scrapy
pip install scrapy
3 Scrapy项目示例
此项目爬取豆瓣Top250 影视作品的信息 地址为http://movie.douban.com/top250
3.1 创建工程
创建工程 scrapy startproject XXXXX XXXXX代表你项目的名字
项目创建完会产生如下目录结构
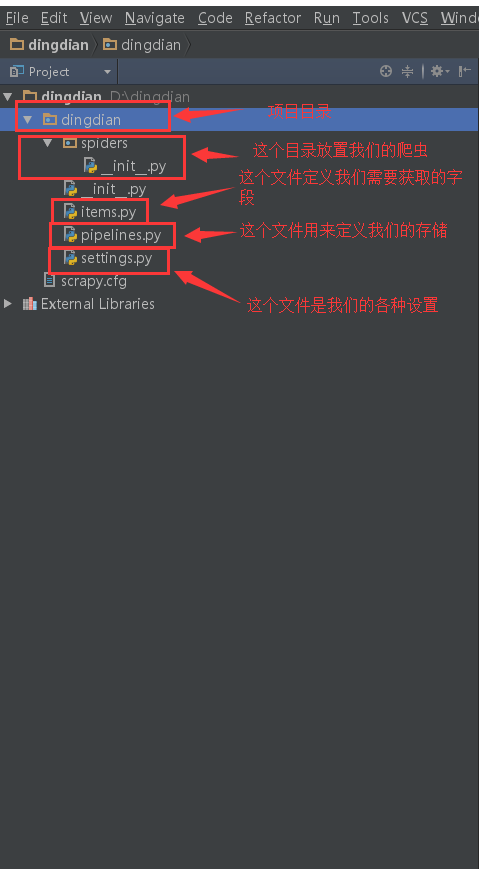
3.2 设置数据存储模板
设置储存模板 items.py
from scrapy import Item, Field class DoubanItem(Item): # define the fields for your item here like: # name = scrapy.Field() title = Field() movieInfo = Field() star = Field() quote = Field()
3.3编写爬虫
编写爬虫Sider 集成父类CrawSpider name 为到时执行爬虫的name
class Douban(CrawlSpider):
name = "douban"
start_urls = ['http://movie.douban.com/top250']
url = 'http://movie.douban.com/top250'
def parse(self, response):
# print response.body
item = DoubanItem()
selector = Selector(response)
# print selector
Movies = selector.xpath('//div[@class="info"]')
# print Movies
for eachMoive in Movies:
title = eachMoive.xpath('div[@class="hd"]/a/span/text()').extract()
# 把两个名称合起来
fullTitle = ''
for each in title:
fullTitle += each
movieInfo = eachMoive.xpath('div[@class="bd"]/p/text()').extract()
star = eachMoive.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract()[0]
quote = eachMoive.xpath('div[@class="bd"]/p[@class="quote"]/span/text()').extract()
# quote可能为空,因此需要先进行判断
if quote:
quote = quote[0]
else:
quote = ''
# print fullTitle
# print movieInfo
# print star
# print quote
item['title'] = fullTitle
item['movieInfo'] = ';'.join(movieInfo)
item['star'] = star
item['quote'] = quote
yield item
nextLink = selector.xpath('//span[@class="next"]/link/@href').extract()
# 第10页是最后一页,没有下一页的链接
if nextLink:
nextLink = nextLink[0]
print(nextLink)
yield Request(self.url + nextLink, callback=self.parse)
3.4 编写数据处理脚本
在这里可以对数据进行处理,或进行持久化保存到mysql,mongodb等数据库
from mongodb.dao import MONGO_CLIENT, DB_NAME,COLLECTION_NAME
class Douban250Pipeline(object):
def process_item(self, item, spider):
collection = MONGO_CLIENT[DB_NAME][COLLECTION_NAME]
collection.insert_one({
'title': item['title'],
'movieInfo': item['movieInfo'],
'star': item['star'],
'quote': item['quote']
})
print(item)
return item
3.5 修改配置文件
修改PIPELINES ITEM_PIPELINES={ 'douban250.pipelines.Douban250Pipeline':300, }
伪造身份 USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5'
3.6 执行爬虫
scrapy crawl douban
#执行结果
scrapy爬虫 快速入门的更多相关文章
- Scrapy爬虫快速入门
安装Scrapy Scrapy是一个高级的Python爬虫框架,它不仅包含了爬虫的特性,还可以方便的将爬虫数据保存到csv.json等文件中. 首先我们安装Scrapy. pip install sc ...
- Scrapy框架-scrapy框架快速入门
1.安装和文档 安装:通过pip install scrapy即可安装. Scrapy官方文档:http://doc.scrapy.org/en/latest Scrapy中文文档:http://sc ...
- Scrapy 爬虫框架入门案例详解
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~ 作者:崔庆才 Scrapy入门 本篇会通过介绍一个简单的项目,走一遍Scrapy抓取流程,通过这个过程,可以对 ...
- Python之Scrapy爬虫框架 入门实例(一)
一.开发环境 1.安装 scrapy 2.安装 python2.7 3.安装编辑器 PyCharm 二.创建scrapy项目pachong 1.在命令行输入命令:scrapy startproject ...
- scrapy爬虫框架入门教程
scrapy安装请参考:安装指南. 我们将使用开放目录项目(dmoz)作为抓取的例子. 这篇入门教程将引导你完成如下任务: 创建一个新的Scrapy项目 定义提取的Item 写一个Spider用来爬行 ...
- 【python】Scrapy爬虫框架入门
说明: 本文主要学习Scrapy框架入门,介绍如何使用Scrapy框架爬取页面信息. 项目案例:爬取腾讯招聘页面 https://hr.tencent.com/position.php?&st ...
- [Python] Scrapy爬虫框架入门
说明: 本文主要学习Scrapy框架入门,介绍如何使用Scrapy框架爬取页面信息. 项目案例:爬取腾讯招聘页面 https://hr.tencent.com/position.php?&st ...
- scrapy爬虫框架入门实例(一)
流程分析 抓取内容(百度贴吧:网络爬虫吧) 页面: http://tieba.baidu.com/f?kw=%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB&ie=ut ...
- scrapy爬虫 简单入门
1. 使用cmd+R命令进入命令行窗口,并进入你需要创建项目的目录 cd 项目地址 2. 创建项目 scrapy startproject <项目名> cd <项目名> 例如 ...
随机推荐
- ansj原子切分和全切分
ansj第一步会进行原子切分和全切分,并且是在同时进行的.所谓原子,是指短句中不可分割的最小语素单位.例如,一个汉字就是一个原子.全切分,就是把一句话中的所有词都找出来,只要是字典中有的就找出来.例如 ...
- Spring-Security-OAuth2调用微信API
import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.an ...
- Spring Cloud authentication with JWT service
@RequestMapping(value = "/authenticate", method = RequestMethod.POST) public ResponseEntit ...
- 基于Jmeter+maven+Jenkins构建性能自动化测试平台
一.目的: 为能够将相关系统性能测试做为常规化测试任务执行,且可自动无人值守定时执行并输出性能测试结果报告及统计数据,因此基于Jmeter+maven+Jenkins构建了一套性能自动化测试平台 ...
- Jenkins持续集成项目搭建与实践——基于Python Selenium自动化测试(自由风格)
Jenkins简介 Jenkins是Java编写的非常流行的持续集成(CI)服务,起源于Hudson项目.所以Jenkins和Hudson功能相似. Jenkins支持各种版本的控制工具,如CVS.S ...
- BZOJ_1146_[CTSC2008]网络管理Network_主席树+树状数组
BZOJ_1146_[CTSC2008]网络管理Network_主席树 Description M公司是一个非常庞大的跨国公司,在许多国家都设有它的下属分支机构或部门.为了让分布在世界各地的N个 部门 ...
- Linux文件系统选择
通过综合使用多种标准文件系统Benchmarks对Ext3, Ext4, Reiserfs, XFS, JFS, Reiser4的性能测试对比,对不同应用选择合适的文件系统给出以下方案,供大家参考.文 ...
- 【毕业原版】-《伦敦艺术大学毕业证书》UAL一模一样原件
☞伦敦艺术大学毕业证书[微/Q:865121257◆WeChat:CC6669834]UC毕业证书/联系人Alice[查看点击百度快照查看][留信网学历认证&博士&硕士&海归& ...
- 学习攻略丨如何进阶为一名Web安全高手?
学习Web安全的小伙伴很多,但是能成为Web安全高手却很少,很多人都是从入门到放弃,是真的太难还是学习方法不对? 对于基础薄弱的人来说,一般都是从XSS.SQL注入等简单的漏洞研究入门的.除了了解各种 ...
- 【JVM虚拟机】(5)---深入理解JVM-Class中常量池
深入理解Class---常量池 一.概念 1.jvm生命周期 启动:当启动一个java程序时,一个jvm实例就诞生了,任何一个拥有main方法的class都可以作为jvm实例运行的起点. 运行:mai ...