【自然语言处理】--视觉问答(Visual Question Answering,VQA)从初始到应用
一、前述
视觉问答(Visual Question Answering,VQA),是一种涉及计算机视觉和自然语言处理的学习任务。这一任务的定义如下: A VQA system takes as input an image and a free-form, open-ended, natural-language question about the image and produces a natural-language answer as the output[1]。 翻译为中文:一个VQA系统以一张图片和一个关于这张图片形式自由、开放式的自然语言问题作为输入,以生成一条自然语言答案作为输出。简单来说,VQA就是给定的图片进行问答。
VQA系统需要将图片和问题作为输入,结合这两部分信息,产生一条人类语言作为输出。针对一张特定的图片,如果想要机器以自然语言来回答关于该图片的某一个特定问题,我们需要让机器对图片的内容、问题的含义和意图以及相关的常识有一定的理解。VQA涉及到多方面的AI技术(图1):细粒度识别(这位女士是白种人吗?)、 物体识别(图中有几个香蕉?)、行为识别(这位女士在哭吗?)和对问题所包含文本的理解(NLP)。综上所述,VQA是一项涉及了计算机视觉(CV)和自然语言处理(NLP)两大领域的学习任务。它的主要目标就是让计算机根据输入的图片和问题输出一个符合自然语言规则且内容合理的答案。
二、具体步骤
2.1 第一步,生成答案
2.2 第二步,处理输⼊源数据
2.2.1 处理输⼊源数据:图⽚
卷积CNN结合VGG-16模型
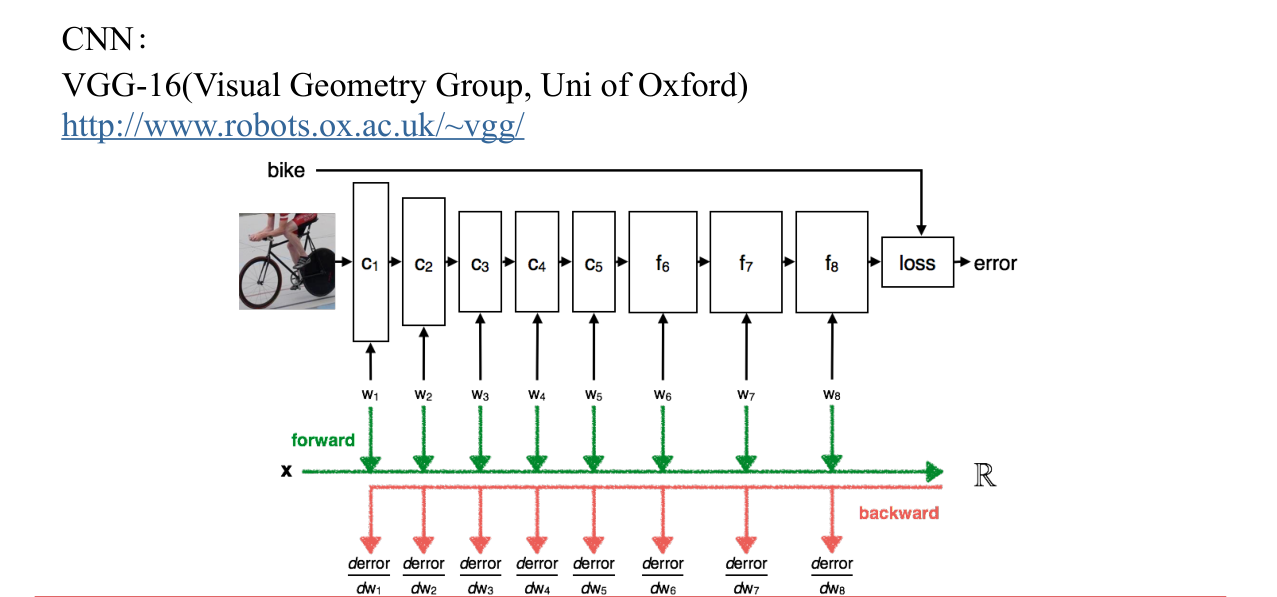
VGG-16的标准构造 (keras)
def VGG_16(weights_path=None):
model = Sequential()
model.add(ZeroPadding2D((1,1),input_shape=(3,224,224)))
model.add(Convolution2D(64, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(64, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(128, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(128, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000, activation='softmax'))
if weights_path:
model.load_weights(weights_path)
return model
2.2.2 处理输⼊源数据:⽂字
2.3 第三步, 选取VQA模型-MLP
2.3.1 选取VQA模型-MLP
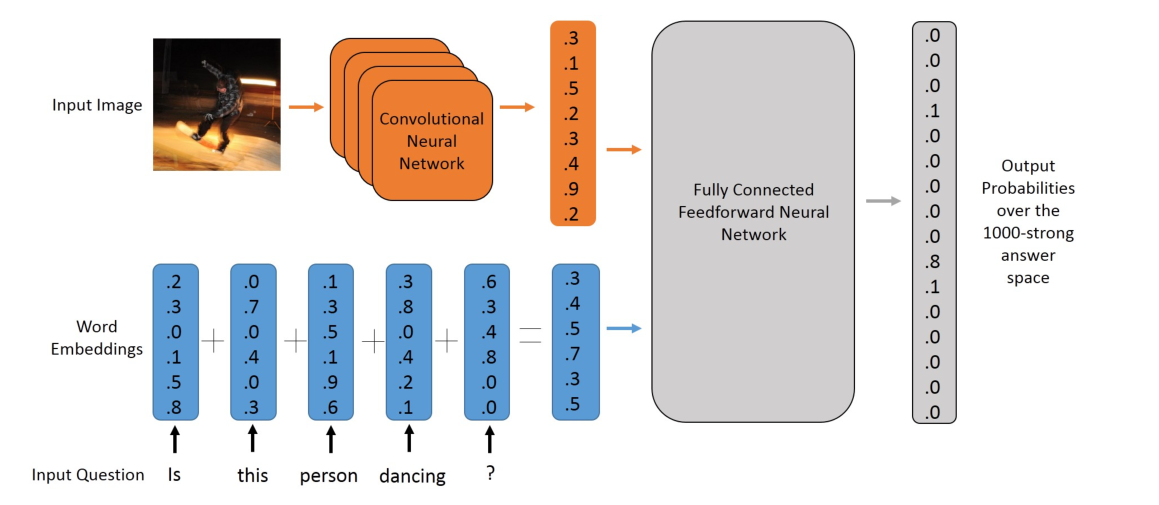
2.3.2 选取VQA模型-LSTM

【自然语言处理】--视觉问答(Visual Question Answering,VQA)从初始到应用的更多相关文章
- Hierarchical Question-Image Co-Attention for Visual Question Answering
Hierarchical Question-Image Co-Attention for Visual Question Answering NIPS 2016 Paper: https://arxi ...
- Visual Question Answering with Memory-Augmented Networks
Visual Question Answering with Memory-Augmented Networks 2018-05-15 20:15:03 Motivation: 虽然 VQA 已经取得 ...
- 第八讲_图像问答Image Question Answering
第八讲_图像问答Image Question Answering 课程结构 图像问答的描述 具备一系列AI能力:细分识别,物体检测,动作识别,常识推理,知识库推理..... 先要根据问题,判断什么任务 ...
- 论文笔记:Visual Question Answering as a Meta Learning Task
Visual Question Answering as a Meta Learning Task ECCV 2018 2018-09-13 19:58:08 Paper: http://openac ...
- 论文阅读:Learning Visual Question Answering by Bootstrapping Hard Attention
Learning Visual Question Answering by Bootstrapping Hard Attention Google DeepMind ECCV-2018 2018 ...
- Learning Conditioned Graph Structures for Interpretable Visual Question Answering
Learning Conditioned Graph Structures for Interpretable Visual Question Answering 2019-05-29 00:29:4 ...
- VQA视觉问答基础知识
本文记录简单了解VQA的过程,目的是以此学习图像和文本的特征预处理.嵌入以及如何设计分类loss等等. 参考资料: https://zhuanlan.zhihu.com/p/40704719 http ...
- 论文:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering-阅读总结
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering-阅读总结 笔记不能简单的抄写文中 ...
- 【论文小综】基于外部知识的VQA(视觉问答)
我们生活在一个多模态的世界中.视觉的捕捉与理解,知识的学习与感知,语言的交流与表达,诸多方面的信息促进着我们对于世界的认知.作为多模态领域的一个典型场景,VQA旨在结合视觉的信息来回答所提出的问题 ...
随机推荐
- Java集合排序及java集合类详解--(Collection, List, Set, Map)
1 集合框架 1.1 集合框架概述 1.1.1 容器简介 到目前为止,我们已经学习了如何创建多个不同的对象,定义了这些对象以后,我们就可以利用它们来做一 ...
- 我的Python之旅第三天
一 编码操作 1 编码 enconde() 英文字符编码为"utf-8"时,一个字符占一个字节. s1='abcdef' b1=s1.encode('utf-8') print(b ...
- centos系统查看系统版本、内核版本、系统位数、cpu个数、核心数、线程数
centos查看系统版本 cat /etc/redhat-release CentOS Linux release 7.2.1511 (Core) 1)查看centos内核的版本: [root@loc ...
- git本地克隆时失败: SSL certificate problem
问题描述 将git包在本地克隆时出现这个错误. 解决办法 找到.gitconfig文件,在http项添加 sslVerify = false. 注: 上面这个是针对单一库的,如果希望对所有库都关闭ss ...
- Go 1.9 sync.Map揭秘
Go 1.9 sync.Map揭秘 目录 [−] 有并发问题的map Go 1.9之前的解决方案 sync.Map Load Store Delete Range sync.Map的性能 其它 在Go ...
- 记录一波由会话堵塞导致tomcat应用故障事件
一.故障基本信息 发生时间 消除时间 故障历时 故障类别 影响 2018-5-17 18:14:30 2018-05-18 08:58:15 16小时 应用故障 业务瘫痪,用户投诉 二.故障现象 AP ...
- BZOJ_4756_[Usaco2017 Jan]Promotion Counting_树状数组
BZOJ_4756_[Usaco2017 Jan]Promotion Counting_树状数组 Description n只奶牛构成了一个树形的公司,每个奶牛有一个能力值pi,1号奶牛为树根. 问对 ...
- Python数据结构应用5——排序(Sorting)
在具体算法之前,首先来看一下排序算法衡量的标准: 比较:比较两个数的大小的次数所花费的时间. 交换:当发现某个数不在适当的位置时,将其交换到合适位置花费的时间. 冒泡排序(Bubble Sort) 这 ...
- linux 挂载共享文件夹
1.背景 通常会有这样的场景,开发人员在Windows编写代码,然后放在linux环境编译,我们通过mount命令就可以实现将代码直接挂到linux环境上去,使Windows上的共享文件夹就像linu ...
- 【原创】分布式之redis复习精讲
引言 为什么写这篇文章? 博主的<分布式之消息队列复习精讲>得到了大家的好评,内心诚惶诚恐,想着再出一篇关于复习精讲的文章.但是还是要说明一下,复习精讲的文章偏面试准备,真正在开发过程中, ...