Spark DataFrame写入HBase的常用方式
Spark是目前最流行的分布式计算框架,而HBase则是在HDFS之上的列式分布式存储引擎,基于Spark做离线或者实时计算,数据结果保存在HBase中是目前很流行的做法。例如用户画像、单品画像、推荐系统等都可以用HBase作为存储媒介,供客户端使用。
因此Spark如何向HBase中写数据就成为很重要的一个环节了。本文将会介绍三种写入的方式,其中一种还在期待中,暂且官网即可...
代码在spark 2.2.0版本亲测
1. 基于HBase API批量写入
第一种是最简单的使用方式了,就是基于RDD的分区,由于在spark中一个partition总是存储在一个excutor上,因此可以创建一个HBase连接,提交整个partition的内容。
大致的代码是:
rdd.foreachPartition { records =>
val config = HBaseConfiguration.create
config.set("hbase.zookeeper.property.clientPort", "2181")
config.set("hbase.zookeeper.quorum", "a1,a2,a3")
val connection = ConnectionFactory.createConnection(config)
val table = connection.getTable(TableName.valueOf("rec:user_rec"))
// 举个例子而已,真实的代码根据records来
val list = new java.util.ArrayList[Put]
for(i <- 0 until 10){
val put = new Put(Bytes.toBytes(i.toString))
put.addColumn(Bytes.toBytes("t"), Bytes.toBytes("aaaa"), Bytes.toBytes("1111"))
list.add(put)
}
// 批量提交
table.put(list)
// 分区数据写入HBase后关闭连接
table.close()
}
这样每次写的代码很多,显得不够友好,如果能跟dataframe保存parquet、csv之类的就好了。下面就看看怎么实现dataframe直接写入hbase吧!
2. Hortonworks的SHC写入
由于这个插件是hortonworks提供的,maven的中央仓库并没有直接可下载的版本。需要用户下载源码自己编译打包,如果有maven私库,可以上传到自己的maven私库里面。具体的步骤可以参考如下:
2.1 下载源码、编译、上传
去官网github下载即可:https://github.com/hortonworks-spark/shc
可以直接按照下面的readme说明来,也可以跟着我的笔记走。
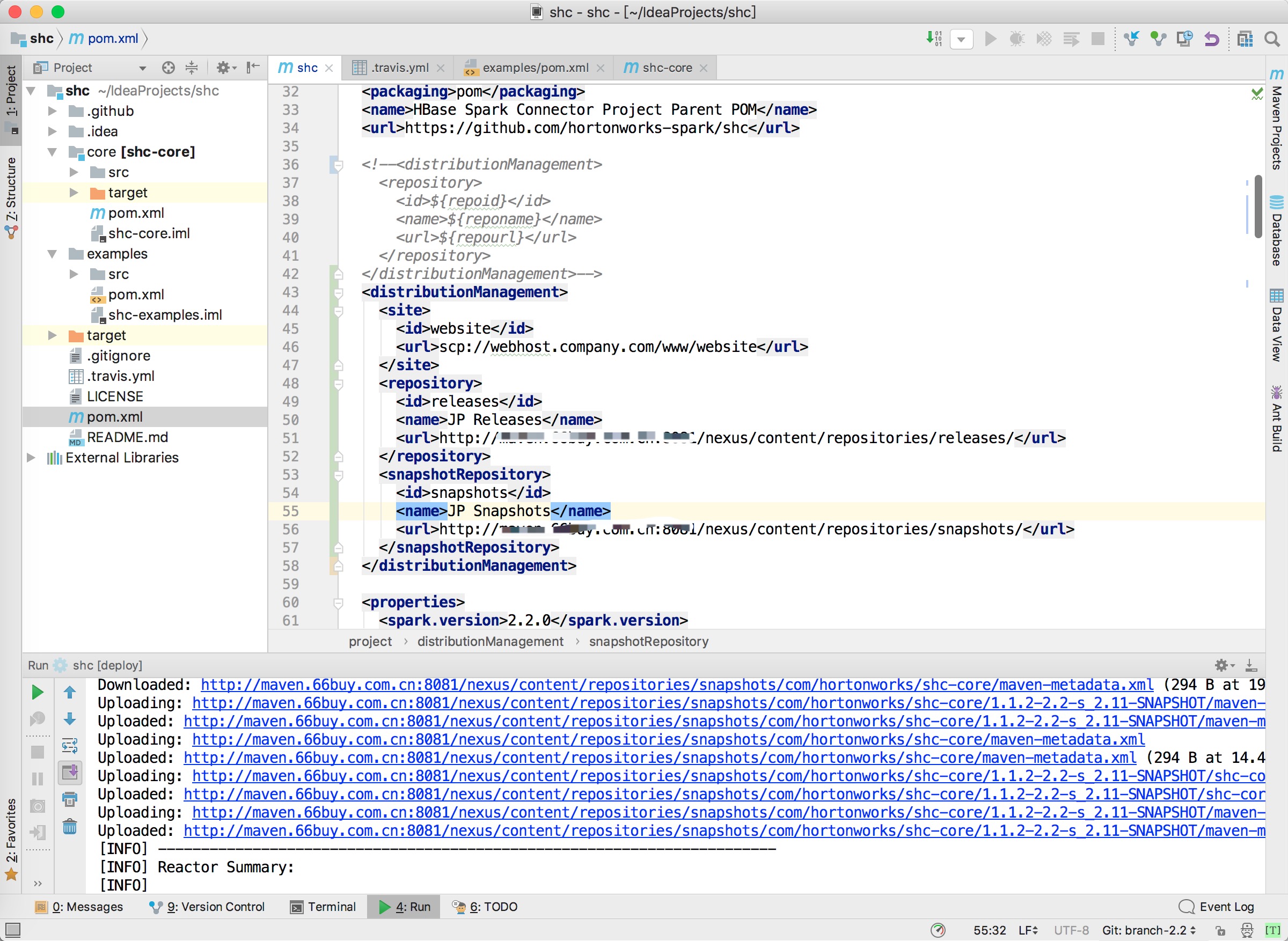
下载完成后,如果有自己的私库,可以修改shc中的distributionManagement。然后点击旁边的maven插件deploy发布工程,如果只想打成jar包,那就直接install就可以了。

2.2 引入
在pom.xml中引入:
<dependency>
<groupId>com.hortonworks</groupId>
<artifactId>shc-core</artifactId>
<version>1.1.2-2.2-s_2.11-SNAPSHOT</version>
</dependency>
2.3
首先创建应用程序,Application.scala
object Application {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local").appName("normal").getOrCreate()
spark.sparkContext.setLogLevel("warn")
val data = (0 to 255).map { i => HBaseRecord(i, "extra")}
val df:DataFrame = spark.createDataFrame(data)
df.write
.mode(SaveMode.Overwrite)
.options(Map(HBaseTableCatalog.tableCatalog -> catalog))
.format("org.apache.spark.sql.execution.datasources.hbase")
.save()
}
def catalog = s"""{
|"table":{"namespace":"rec", "name":"user_rec"},
|"rowkey":"key",
|"columns":{
|"col0":{"cf":"rowkey", "col":"key", "type":"string"},
|"col1":{"cf":"t", "col":"col1", "type":"boolean"},
|"col2":{"cf":"t", "col":"col2", "type":"double"},
|"col3":{"cf":"t", "col":"col3", "type":"float"},
|"col4":{"cf":"t", "col":"col4", "type":"int"},
|"col5":{"cf":"t", "col":"col5", "type":"bigint"},
|"col6":{"cf":"t", "col":"col6", "type":"smallint"},
|"col7":{"cf":"t", "col":"col7", "type":"string"},
|"col8":{"cf":"t", "col":"col8", "type":"tinyint"}
|}
|}""".stripMargin
}
case class HBaseRecord(
col0: String,
col1: Boolean,
col2: Double,
col3: Float,
col4: Int,
col5: Long,
col6: Short,
col7: String,
col8: Byte)
object HBaseRecord
{
def apply(i: Int, t: String): HBaseRecord = {
val s = s"""row${"%03d".format(i)}"""
HBaseRecord(s,
i % 2 == 0,
i.toDouble,
i.toFloat,
i,
i.toLong,
i.toShort,
s"String$i: $t",
i.toByte)
}
}
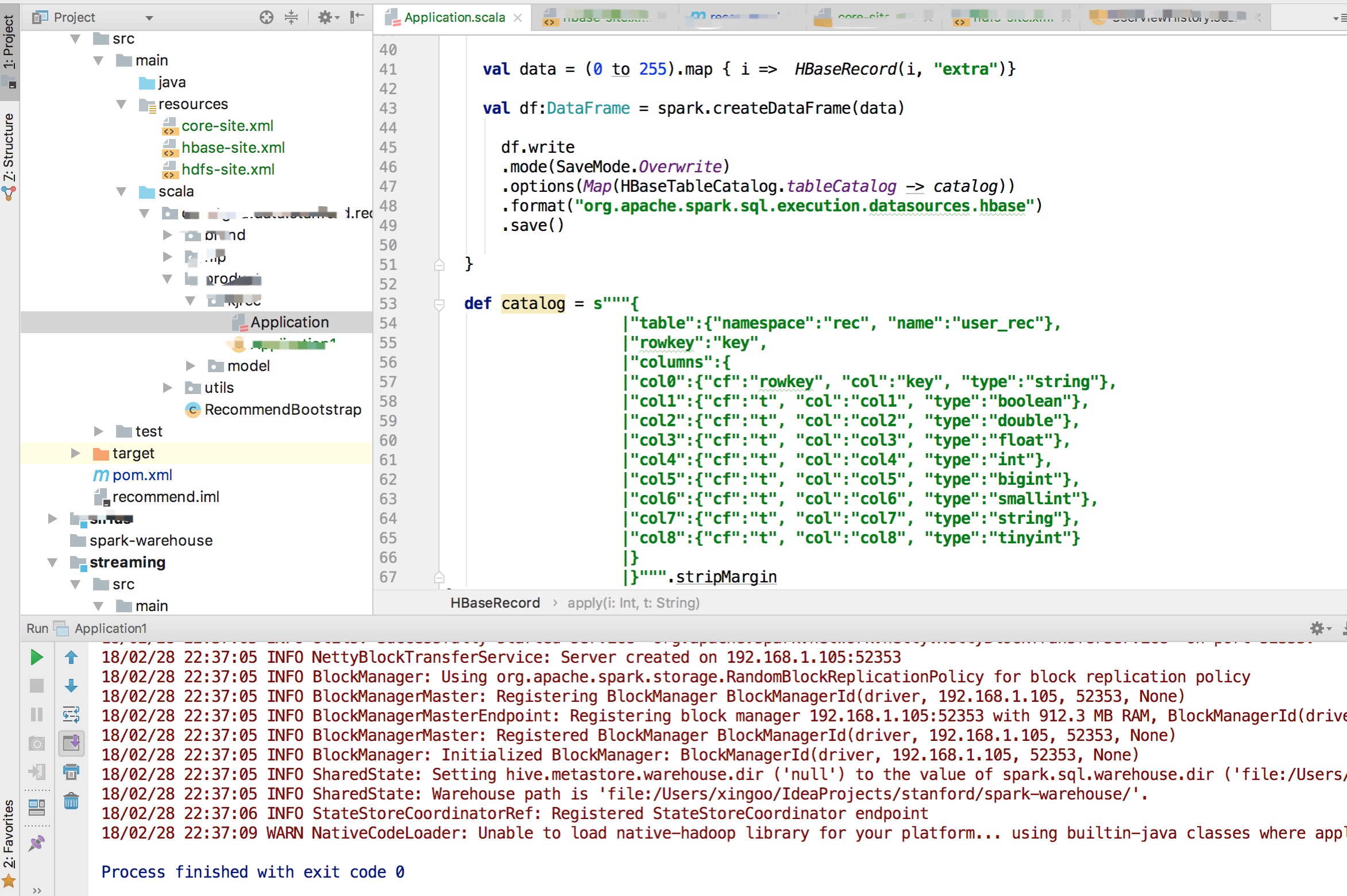
然后再resources目录下,添加hbase-site.xml、hdfs-site.xml、core-site.xml等配置文件。主要是获取Hbase中的一些连接地址。
3. HBase 2.x+即将发布的hbase-spark
如果有浏览官网习惯的同学,一定会发现,HBase官网的版本已经到了3.0.0-SNAPSHOT,并且早就在2.0版本就增加了一个hbase-spark模块,使用的方法跟上面hortonworks一样,只是format的包名不同而已,猜想就是把hortonworks给拷贝过来了。
另外Hbase-spark 2.0.0-alpha4目前已经公开在maven仓库中了。
http://mvnrepository.com/artifact/org.apache.hbase/hbase-spark
不过,内部的spark版本是1.6.0,太陈旧了!!!!真心等不起了...
期待hbase-spark官方能快点提供正式版吧。
参考
- hortonworks-spark/shc github:https://github.com/hortonworks-spark/shc
- maven仓库地址: http://mvnrepository.com/artifact/org.apache.hbase/hbase-spark
- Hbase spark sql/ dataframe官方文档:https://hbase.apache.org/book.html#_sparksql_dataframes
Spark DataFrame写入HBase的常用方式的更多相关文章
- Spark写入HBase(Bulk方式)
在使用Spark时经常需要把数据落入HBase中,如果使用普通的Java API,写入会速度很慢.还好Spark提供了Bulk写入方式的接口.那么Bulk写入与普通写入相比有什么优势呢? BulkLo ...
- spark踩坑——dataframe写入hbase连接异常
最近测试环境基于shc[https://github.com/hortonworks-spark/shc]的hbase-connector总是异常连接不到zookeeper,看下报错日志: 18/06 ...
- spark DataFrame的创建几种方式和存储
一. 从Spark2.0以上版本开始,Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载.转换.处理等功能.Sp ...
- Spark:DataFrame 写入文本文件
将DataFrame写成文件方法有很多最简单的将DataFrame转换成RDD,通过saveASTextFile进行保存但是这个方法存在一些局限性:1.将DataFrame转换成RDD或导致数据结构的 ...
- Spark如何写入HBase/Redis/MySQL/Kafka
一些概念 一个partition 对应一个task,一个task 必定存在于一个Executor,一个Executor 对应一个JVM. Partition 是一个可迭代数据集合 Task 本质是作用 ...
- spark运算结果写入hbase及优化
在Spark中利用map-reduce或者spark sql分析了数据之后,我们需要将结果写入外部文件系统. 本文,以向Hbase中写数据,为例,说一下,Spark怎么向Hbase中写数据. 首先,需 ...
- Spark:将DataFrame写入Mysql
Spark将DataFrame进行一些列处理后,需要将之写入mysql,下面是实现过程 1.mysql的信息 mysql的信息我保存在了外部的配置文件,这样方便后续的配置添加. //配置文件示例: [ ...
- 大数据学习day34---spark14------1 redis的事务(pipeline)测试 ,2. 利用redis的pipeline实现数据统计的exactlyonce ,3 SparkStreaming中数据写入Hbase实现ExactlyOnce, 4.Spark StandAlone的执行模式,5 spark on yarn
1 redis的事务(pipeline)测试 Redis本身对数据进行操作,单条命令是原子性的,但事务不保证原子性,且没有回滚.事务中任何命令执行失败,其余的命令仍会被执行,将Redis的多个操作放到 ...
- MapReduce和Spark写入Hbase多表总结
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 大家都知道用mapreduce或者spark写入已知的hbase中的表时,直接在mapreduc ...
随机推荐
- protobuf 编码实现解析(java)
一:protobuf编码基本数据类型 public enum FieldType { DOUBLE (JavaType.DOUBLE , WIRETYPE_FIXED64 ), FLOAT (Java ...
- Java hashtable和hastmap的区别
1. 继承和实现区别 Hashtable是基于陈旧的Dictionary类,完成了Map接口:HashMap是Java 1.2引进的Map接口的一个实现(HashMap继承于AbstractMap,A ...
- LINUX文档管理命令
body, table{font-family: 微软雅黑} table{border-collapse: collapse; border: solid gray; border-width: 2p ...
- Spring注解装配
Spring 自动装配的主机有 @Autowired.@Intect.@Resource @Autowired是byType的, @Resource是byName的.我们一般用@Atutowired. ...
- python_改变字符串中文本格式?
案例: 某软件的日志文件,其中日期格式为year-moth-day: 2016-04-21 10:50:30 python 2014-05-22 10:50:30 python 2017-06-23 ...
- CSS深入理解学习笔记之absolute
1.absolute和float 拥有相同的特性表现: ①包裹性(容器应用之后,可以包裹里面的内容): <!doctype html> <html> <head> ...
- java IO(三):字符流
*/ .hljs { display: block; overflow-x: auto; padding: 0.5em; color: #333; background: #f8f8f8; } .hl ...
- 【转】命令行浏览器 curl 命令详解,Linux中访问url地址
CURL --- 命令行浏览器 这东西现在已经是苹果机上内置的命令行工具之一了,可见其魅力之一斑 1)二话不说,先从这里开始吧! curl http://www.yahoo.com 回车之后,www. ...
- sqlserver数据库使用技巧(一)--限制数据库的大小
如何限制数据库的大小? 随着数据库的使用,他占用的空间会越来越大,为了便于资源的合理分配和管理,我们可以限制其最大的大小,这个建议只在测试环境使用 具体操作如下: 打开sqlserver数据库管理工具 ...
- 关于scanf,gets
1.用了gets后,假如你没有输入任何东西直接[enter],它将执行下一条命令 2.用了scanf后,直接按了[enter],它将换行并等待你的输入,直到你输入非[enter],再执行下一条命令. ...