geodocker-geomesa安装指南
最近研究geopyspark原本以为大数据研究能告一段落,因为。。。


开玩笑的,还要一起建设社会主义呢!!
### 背景
geotrellis作为一个处理遥感数据的框架,对于遥感数据支持的很棒,但是对于矢量数据却有些不足,首先它的样式选择单一,不能像geoserver使用sld自定义出各种样式,其二就是对与矢量的支持稍弱。那为啥么要用geomesa呢?这个框架资料还是比较多的,支持矢量操作,geoserver支持,能提供WFS、WMS服务,所以还是比较看好的。
### 操作
我们直接看看github地址,按照提示一步步来安装。下载项目,到geodocker-accumulo-geomesa,运行docker-compose(需要自行安装),下载数据(如http://data.gdeltproject.org/events/20170710.export.CSV.zip),拷贝数据到docker上,进入容器环境,执行导入数据命令,数据导入后会自动解析出geom,并建立索引
```
git clone https://github.com/geodocker/geodocker-geomesa.git
cd geodocker-accumulo-geomesa;
docker-compose up
docker ps
docker cp 2016.export.csv geodocker-accumulo-geomesa_accumulo-master_1:/tmp/2016.export.CSV
docker exec -ti geodockeraccumulogeomesa_accumulo-master_1 /usr/bin/bash
cd /opt/geomesa/bin
$ ./geomesa-accumulo ingest -C example-csv -c example -u root -p GisPwd -s example-csv ../examples/ingest/csv/example.csv
```
按照github的说明就能成功了,然后打完收工。。。好吧事实没有那么理想,官网的镜像有坑,按照他们的方法会发现,根本导不进去数据,出现如下错误,缺jar了

原因是导入脚本有问题识别zookeeper.jar出现问题,会把指向具体zookeeper.jar的软连接和原来的zookeeper.jar识别出来(我也是请教了官方大佬才知道)
cd /opt/geomesa/bin执行后,使用vi geomesa-accumulo修改
```
ZOOKEEPER_JAR="$(find -L $ZOOKEEPER_HOME -maxdepth 1 -type f -name *zookeeper*jar)"
```
为
```
ZOOKEEPER_JAR="$(find -L $ZOOKEEPER_HOME -maxdepth 1 -type f -name *zookeeper*jar | head -n 1)"
```
接着就导入成功了

最后就是使用geoserver发布服务(http://localhost:9090/geoserver/web,admin:geoserver),根据以下的设置设置数据源,并发布服务。
* accumulo.instance.id = accumulo
* accumulo.zookeepers = zookeeper
* accumulo.user = root
* accumulo.password = GisPwd
* accumulo.catalog = geomesa.ingest
### 最后成果
我分别使用了三份数据,数据量分别是88w、122w、288w,访问wms服务分别需要的时间为4.79s、6.04s、7.27s,速度还是很可观的,还有很大优化空间(目前是单机)。
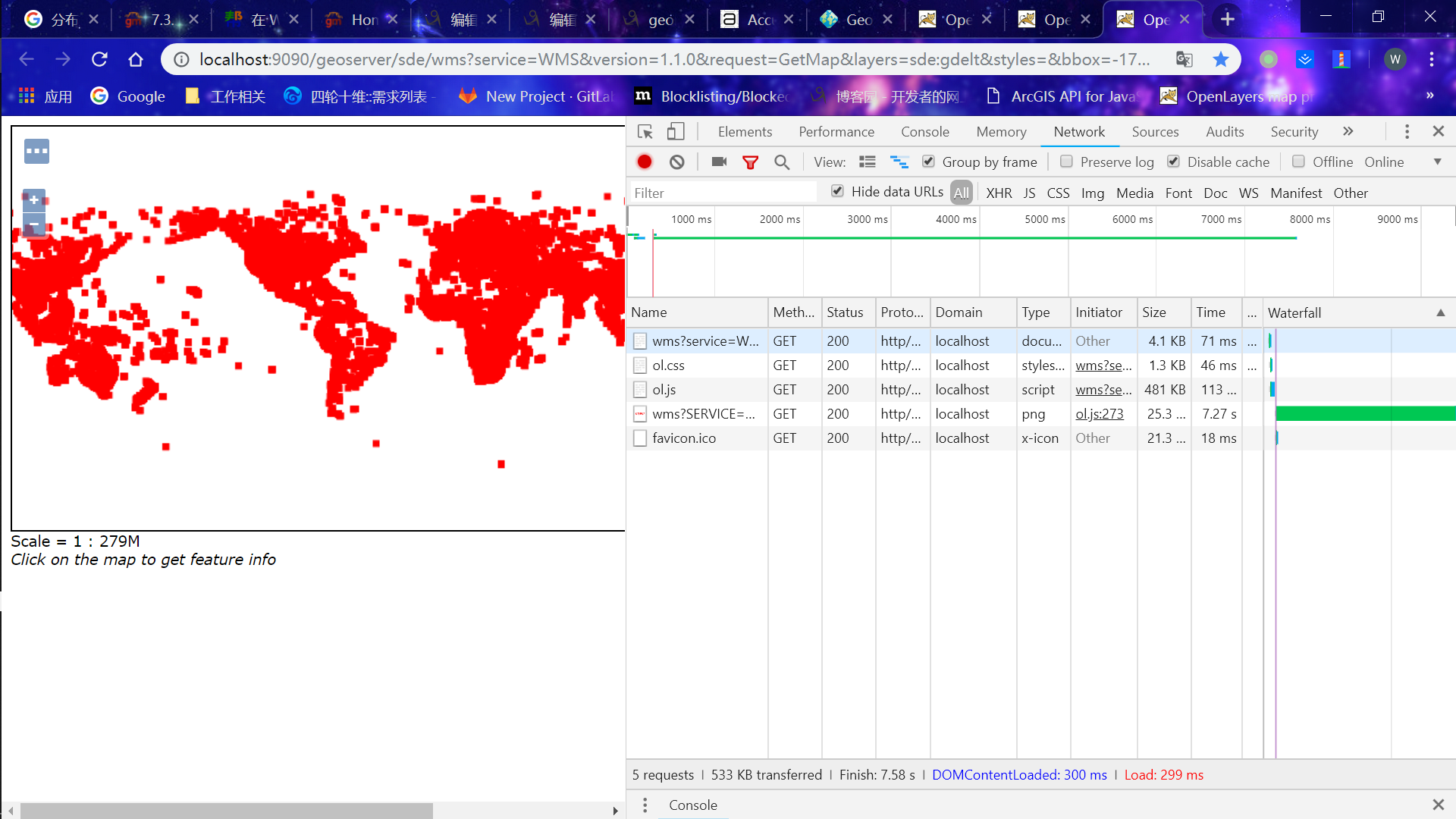
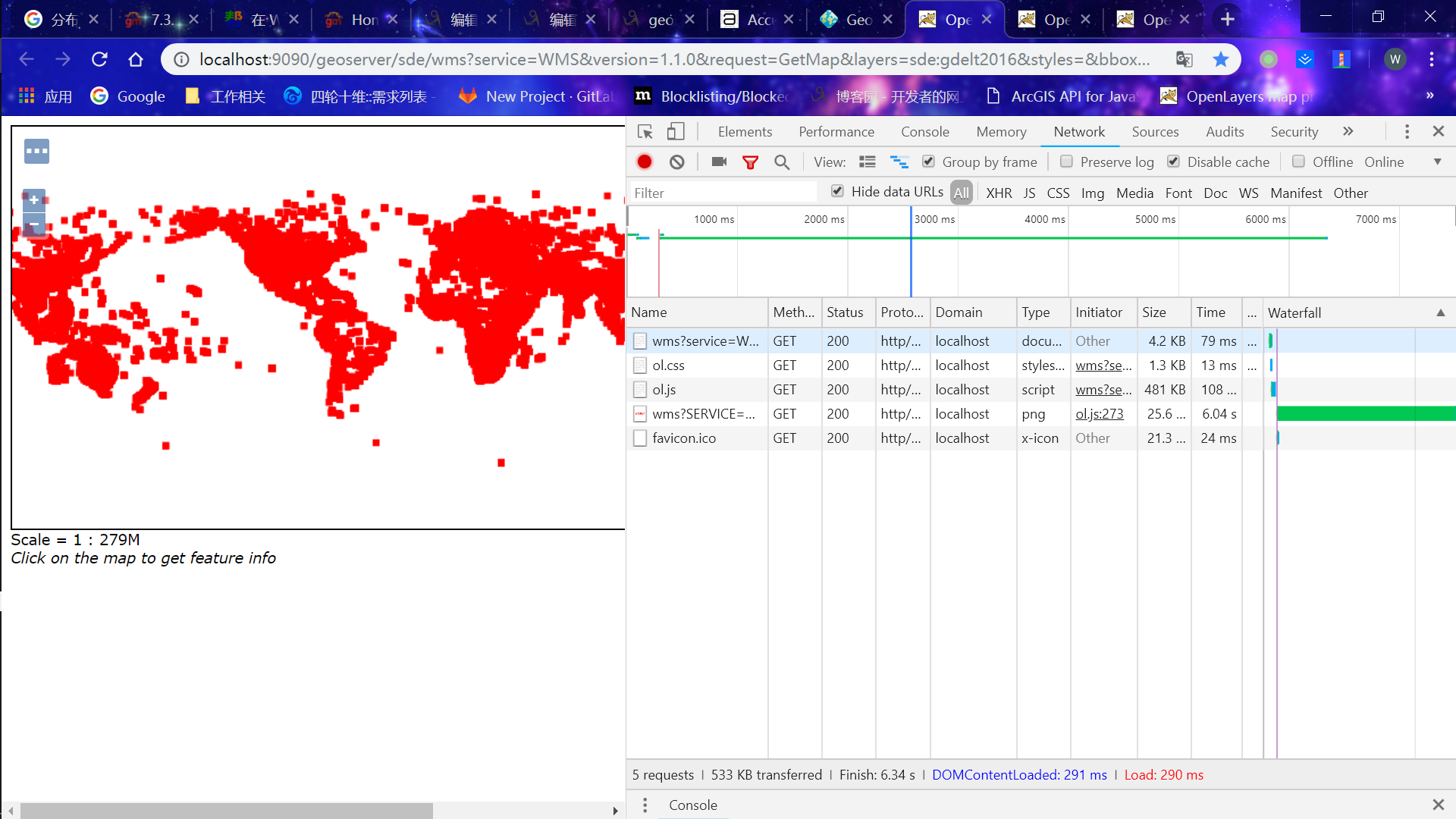

PS:如果你是用linux导入数据可能会出现超时的现象,需要添加zookeeper超时设置,延长时间(https://github.com/geodocker/geodocker-geomesa/issues/8)
```
instance.zookeeper.timeout
15000
timeout limit for zookeeper
```
参考链接:
https://github.com/geodocker/geodocker-geomesa
http://planet.qgis.org/planet/tag/geomesa/
https://www.geomesa.org/documentation/tutorials/geodocker-geomesa/geodocker-geomesa-local.html
geodocker-geomesa安装指南的更多相关文章
- nGrinder安装指南
NGrinder 由两个模块组成,其运行环境为 Oracle JDK 1.6 nGrinder controller web 应用程序,部署在Tomcat 6.x 或更高的版本 nGrinder A ...
- postgresql pgsql最新版安装指南及数据存储路径更改及主从配置
postgresql pgsql最新版安装指南及数据存储路径更改及主从配置 安装指南 首先在apt的list添加你当前系统版本对应的apt列表 目前官网有16.04,14.04,12.04 分别对应下 ...
- 全新 Mac 安装指南(编程篇)(环境变量、Shell 终端、SSH 远程连接)
注:本文专门用于指导对计算机编程与设计(尤其是互联网产品开发与设计)感兴趣的 Mac 新用户,如何在 Mac OS X 系统上配置开发与上网环境,另有<全新 Mac 安装指南(通用篇)>作 ...
- 全新 Mac 安装指南(通用篇)(推荐设置、软件安装、推荐软件)
注:本文将会不定期维护与更新,有需要的朋友请在 Github 上订阅该条 Issues:<全新 Mac 安装指南(通用篇)>. 在 Mac 电脑上只用 Windows 操作系统的同学请看到 ...
- ArchLinux安装指南
将ArchLinux作为进阶Linux发行版,主要看重滚动更新和深入理解Linux的安装过程. 由于是新手,所以先选择在公司电脑上用VMware来安装.然后渐进到借助U盘在win10笔记本上安装双系统 ...
- Linux环境中Openfire安装指南
Linux环境中Openfire安装指南 安装环境: 安装软件:Openfire 4_1_0 http://download.igniterealtime.org/openfire/openfire_ ...
- scrapy3_ 安装指南
安装指南 安装Scrapy 注解 请先阅读 平台安装指南. 下列的安装步骤假定您已经安装好下列程序: Python 2.7 Python Package: pip and setuptools. 现在 ...
- storm 原理简介及单机版安装指南——详细版【转】
storm 原理简介及单机版安装指南 本文翻译自: https://github.com/nathanmarz/storm/wiki/Tutorial 原文链接自:http://www.open-op ...
- mac osx 系统 brew install hadoop 安装指南
mac osx 系统 brew install hadoop 安装指南 brew install hadoop 配置 core-site.xml:配置hdfs文件地址(记得chmod 对应文件夹 ...
随机推荐
- JSON Patch
1.前言 可以这么说的是,任何一种非强制性约束同时也没有"标杆"工具支持的开发风格或协议(仅靠文档是远远不够的),最终的实现上都会被程序员冠上"务实"的名头,而 ...
- QT5:C++实现基于multimedia的音乐播放器(二)
今天接着上一篇来实现播放器的槽函数. 先来实现播放模式,槽函数如下: //播放模式 void Music::musicPlayPattern() { //z=++z%3; ) { //顺序播放 pla ...
- [Kali_Metasploit]db_connect创建连接时无法连接的解决方案
问题1复现路径: postgresql selected, no connection 第一步: db_connect postgres:toor@127.0.0.1/msfbook 连接成功不需要进 ...
- Linux Vim配置
用过很多vim配置的版本,怎么说,想轻量级就不要胡加乱七八糟的功能:如果不在乎反应是不是快速,侧重功能是否强大,可以参考vim大神的配置策略(spf13-vim)https://github.com/ ...
- 3.python元类编程
1.1.propety动态属性 在面向对象编程中,我们一般把名词性的东西映射成属性,动词性的东西映射成方法.在python中他们对应的分别是属性self.xxx和类方法.但有时我们需要的属性需要根据 ...
- PHP访问数据库配置通用方法
提取一种对数据库配置的通用方式 目的是通过通用类访问配置文件的方式,提供对数据库连接的动态获取和设置,使开发时和生产应用时都能够提供灵活的.简化的.解耦的操作方式.比如在配置文件中配置好两套数据库访问 ...
- 你不知道的JavaScript--Item1 严格模式
本文转自[阮一峰博客]:http://www.ruanyifeng.com/blog/2013/01/javascript_strict_mode.html 一.概述 除了正常运行模式,ECMAscr ...
- Python web简约表白网页源码分享,时光不老,我们不散!
演示站:c.lmz8.cn打开js/4.js,复制到工具箱的js代码整理那,先解密,方便查看.工具箱:tool.lmz8.cnjs代码整理.在线解码 这个便是文字,只不过呗转码了,所以要用到解码工具. ...
- stats.go
, len(c.clients)) for _, client := range c.clients { clients = append(cl ...
- 【构造】UVa 11387 The 3-Regular Graph
Description 输入n,构造一个n个点的无向图,使得每个点的度数都为3.不能有重边和自环,输出图或确定无解. Solution 如果n为奇数,奇数*3=奇数,度数为奇,必无解. 考虑我们怎么构 ...