Scrapy爬虫框架第八讲【项目实战篇:知乎用户信息抓取】--本文参考静觅博主所写
思路分析:
(1)选定起始人(即选择关注数和粉丝数较多的人--大V)
(2)获取该大V的个人信息
(3)获取关注列表用户信息
(4)获取粉丝列表用户信息
(5)重复(2)(3)(4)步实现全知乎用户爬取
实战演练:
(1)、创建项目:scrapy startproject zhijutest
(2)、创建爬虫:cd zhihutest -----scrapy genspider zhihu www.zhihu.com
(3)、选取起始人(这里我选择了以下用户)
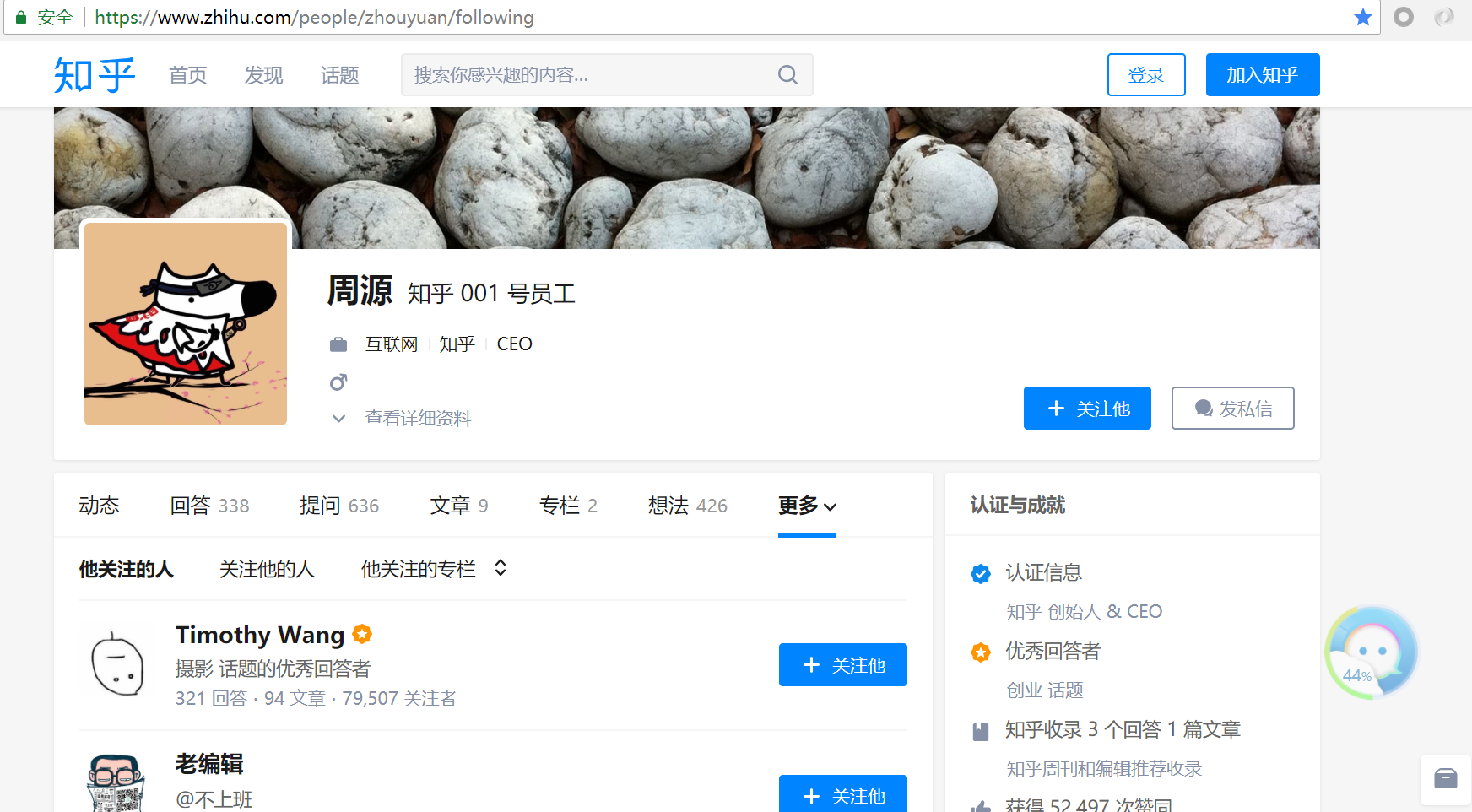
我们可以看到他关注的人和关注他的人,这些内容是我们(3)(4)步需要获取的
(3)、更改settings.py

代码分析:这里我们设置了不遵守robots协议
robots协议:网络爬虫协议,它用来告诉用户那些内容可以爬取,那些内容禁止爬取,一般我们运行爬虫项目,首先会访问网站的robots.txt页面,它告诉爬虫那些是你可以获取的内容,这里我们为了方便,即不遵守robots协议。

代码分析:这里我们设置了User-Agent和authorization字段(这是知乎对请求头的限制了,即反爬),而这里我们通过设置模拟了在没有登陆的前提下伪装成浏览器去请求知乎
(4)、页面初步分析
右击鼠标打开chrome开发者工具选项,并选中如下箭头所指,将鼠标放在黄色标记上,我们可以发现右侧加载出了一个ajax请求
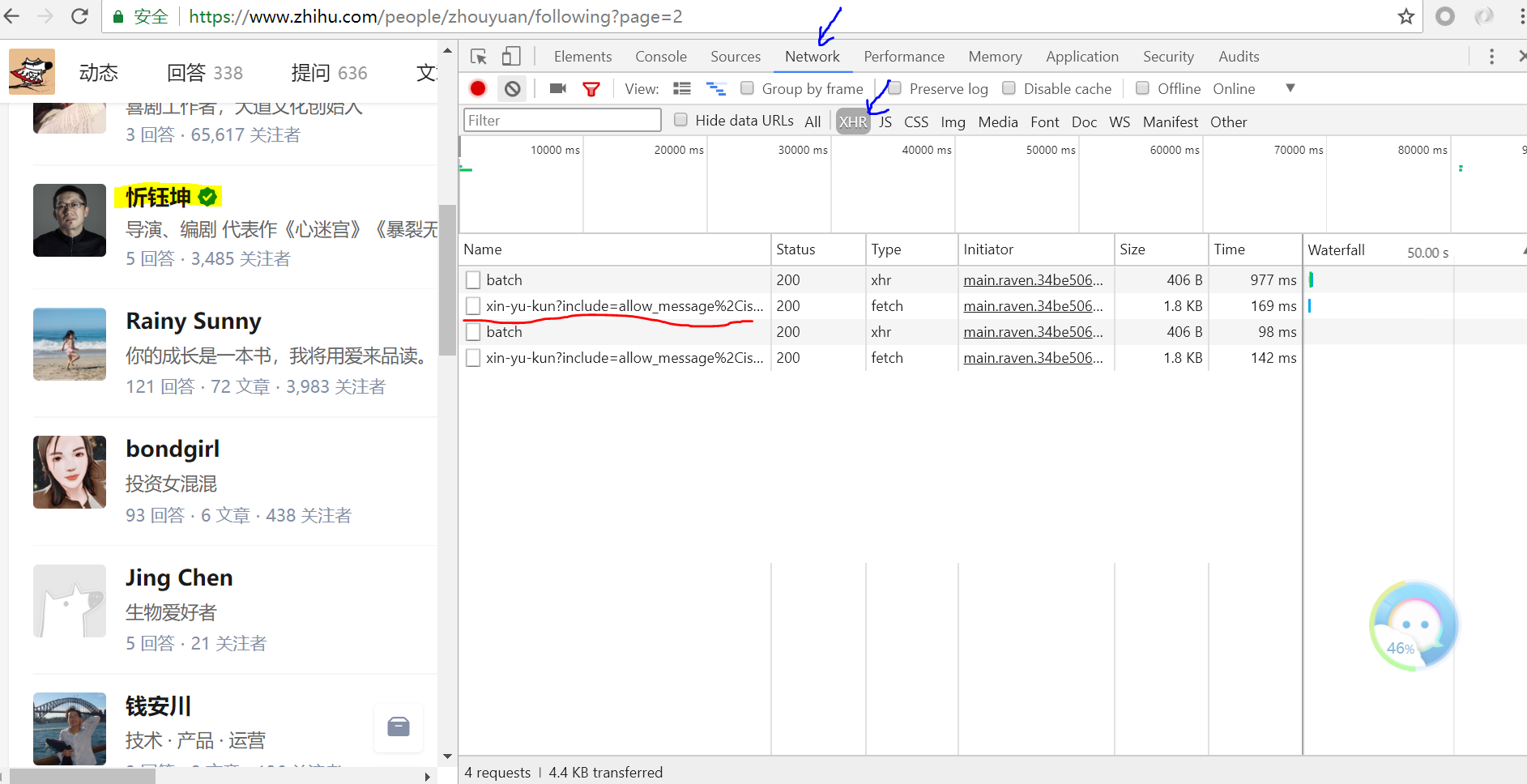
单击该ajax请求,得到如下页面:我们可以看见黄色部分为每位用户的详细信息的url,它包含多个参数用来存储信息
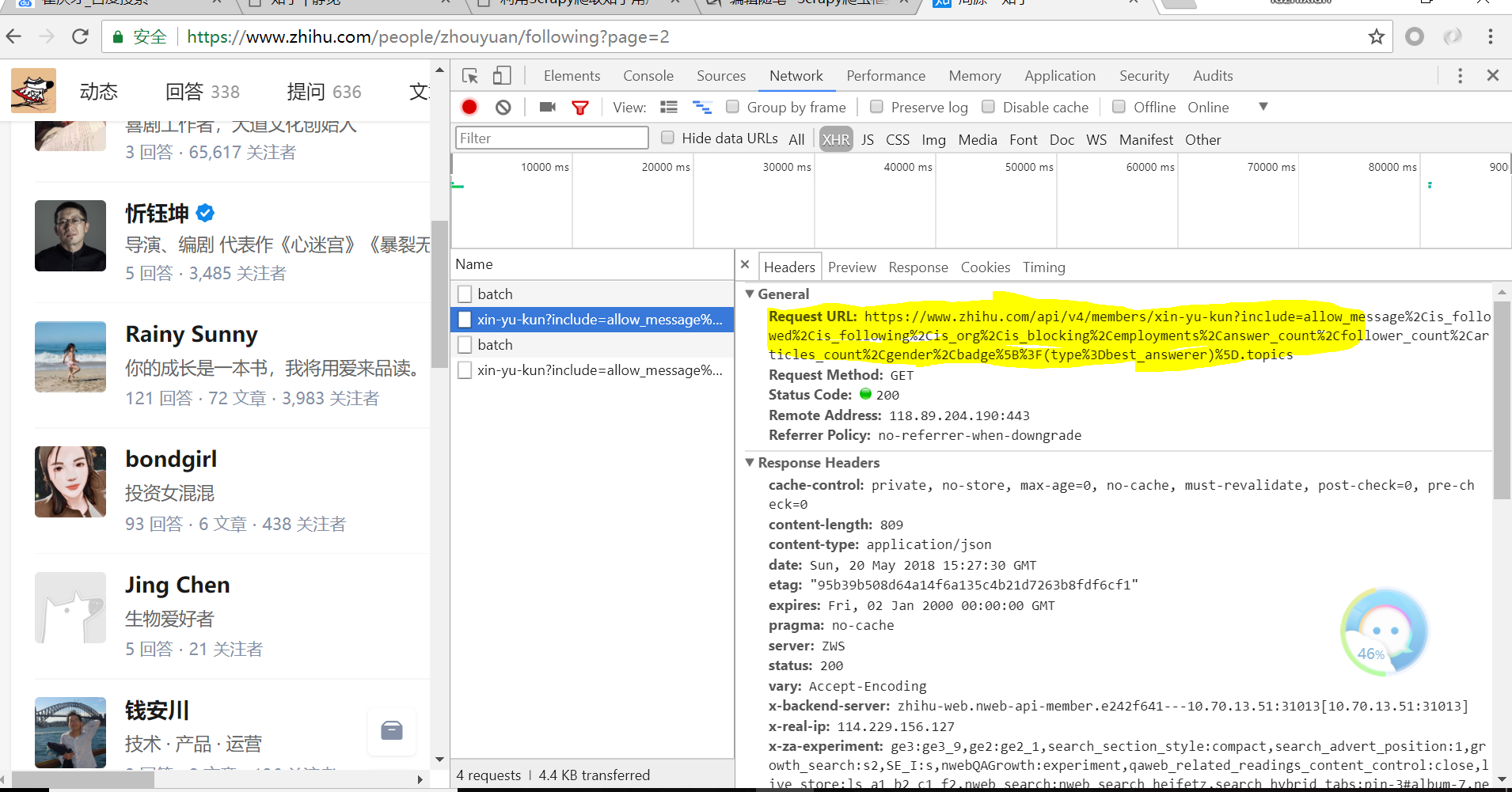
此时再将页面下滑可以看到如下信息:

该字段为上面参数的字段详情(Query String Parameters,英文好的小伙伴应该一眼发现)
(5)、更改items.py
承接上面将页面点击左侧并翻页,可以看出右侧出现了新的Ajax请求:followees:......这就是他关注者信息,通过点击Preview我们获取了网页源代码,可以发现包含了每一页的用户信息,小伙伴们可以核对下,发现信息能匹配上,我们可以从中发现每页包含20条他的关注者信息,而黑框部分就是包含每一位用户详细信息的参数,我们通过它们来定义item.py(即爬什么???)
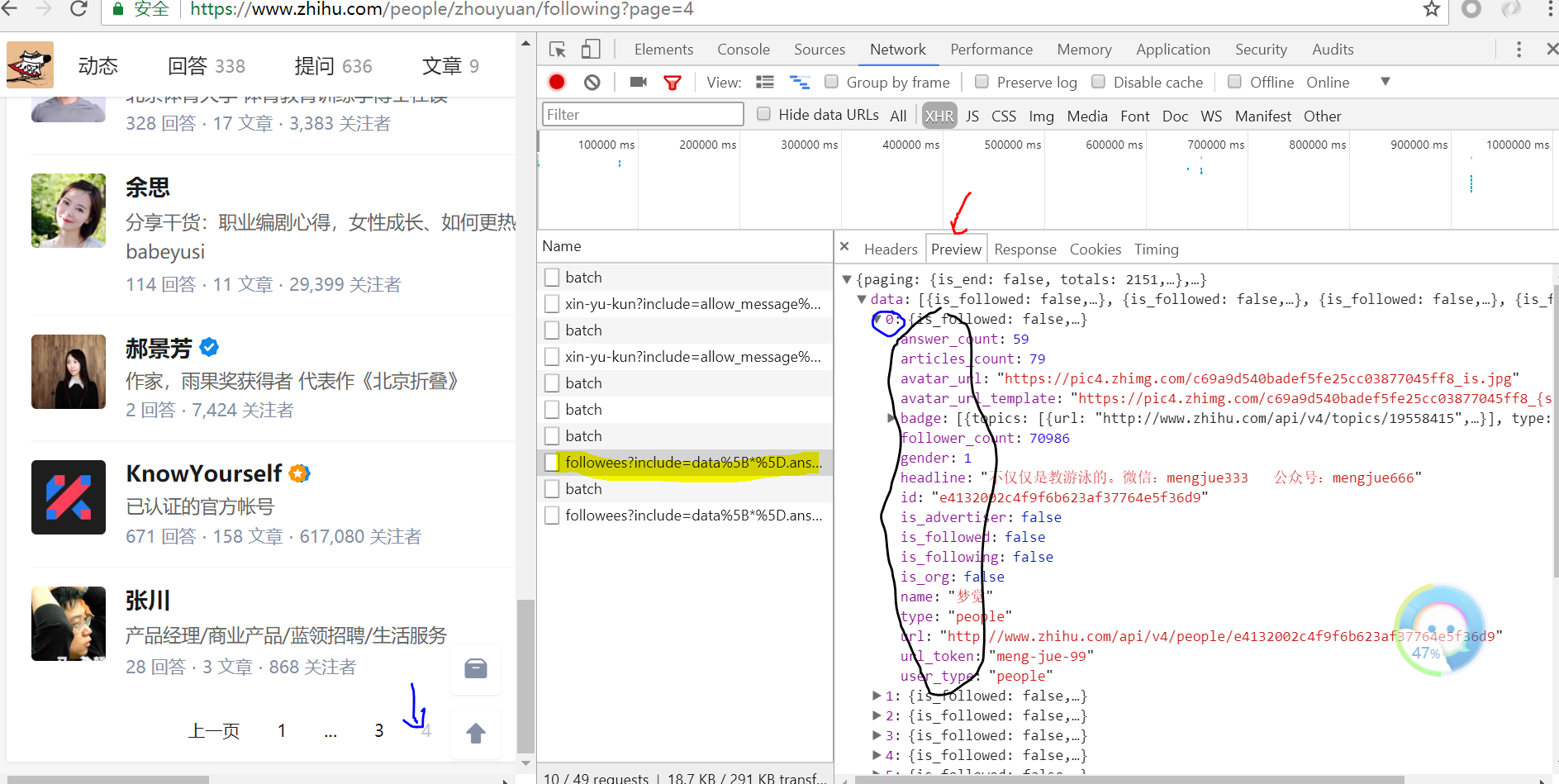
修改items.py如下:
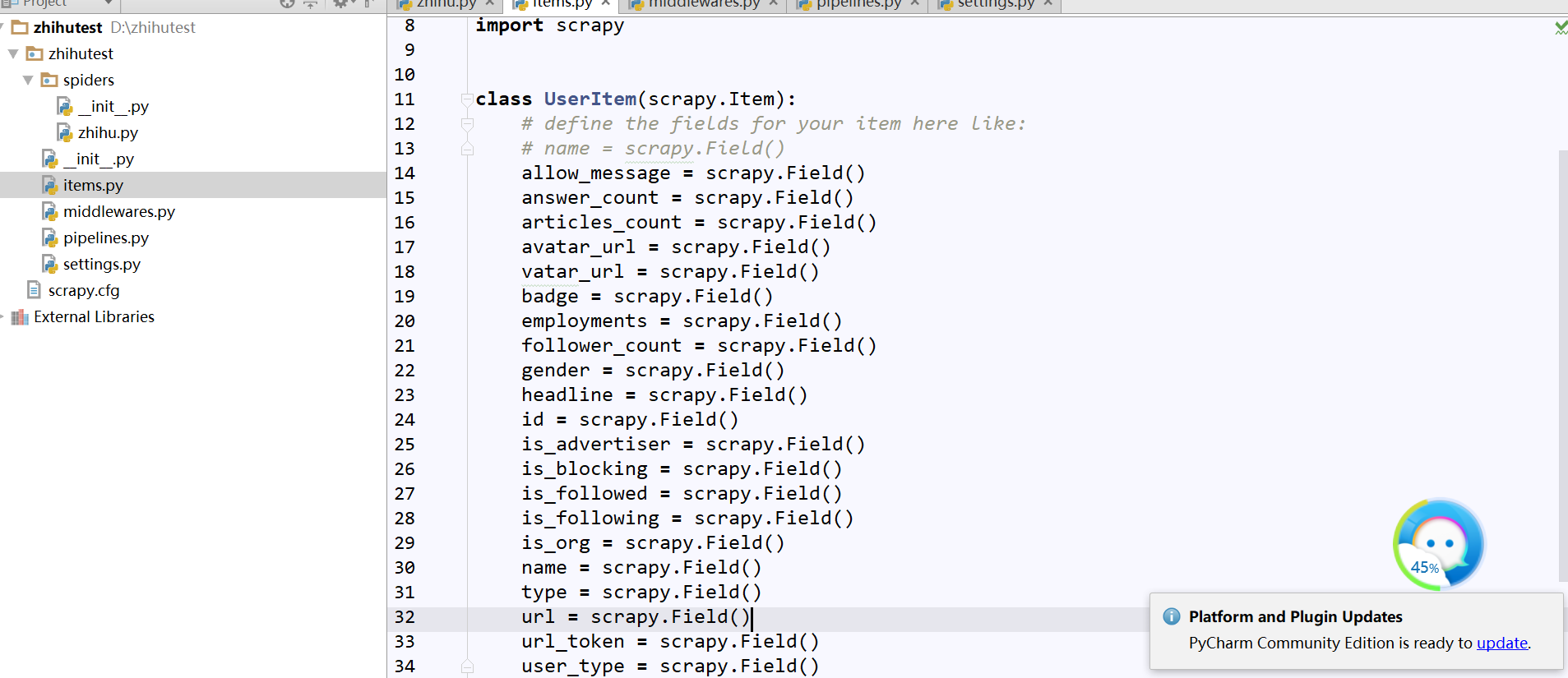
(6)、更改zhihu.py
第一步:模块导入
# -*- coding: utf-8 -*-
import json import scrapy from ..items import UserItem class ZhihuSpider(scrapy.Spider):
name = 'zhihu'
allowed_domains = ['zhihu.com']
start_urls = ['http://zhihu.com/'] #设定起始爬取人,这里我们通过观察发现与url_token字段有关
start_user = 'zhouyuan' #选取起始爬取人的页面详情信息,这里我们传入了user和include参数方便对不同的用户进行爬取
user_url = 'https://www.zhihu.com/api/v4/members/{user}?include={include}'
#用户详情参数即包含在include后面的字段
user_query = 'allow_message,is_followed,is_following,is_org,is_blocking,employments,answer_count,follower_count,articles_count,gender,badge[?(type=best_answerer)].topics' #这是他的关注者的url,这里包含了每位他的关注者的url,同样我们传入了user和include参数方便对不同用户进行爬取
follows_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}'
#他的每位关注者详情参数,即包含在include后面的字段
follows_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics' #这是他的粉丝的url,这里包含了每位他的关注者的url,同样我们传入了user和include参数方便对不同用户进行爬取
followers_url = 'https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}'
#他的每位粉丝的详情参数,即包含在include后面的字段
followers_query = 'data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics' #重新定义起始爬取点的url
def start_requests(self):
#这里我们传入了将选定的大V的详情页面的url,并指定了解析函数parseUser
yield scrapy.Request(self.user_url.format(user=self.start_user, include=self.user_query), callback=self.parseUser)
#这里我们传入了将选定的大V他的关注者的详情页面的url,并指定了解析函数parseFollows
yield scrapy.Request(self.follows_url.format(user=self.start_user, include=self.follows_query, offset=0, limit=20), callback=self.parseFollows)
#这里我们传入了将选定的大V的粉丝的详情页面的url,并指定了解析函数parseFollowers
yield scrapy.Request(self.followers_url.format(user=self.start_user, include=self.followers_query, offset=0, limit=20), callback=self.parseFollowers) #爬取每一位用户详情的页面解析函数
def parseUser(self, response):
#这里页面上是json字符串类型我们使用json.loads()方法将其变为文本字符串格式
result = json.loads(response.text)
item = UserItem() #这里我们遍历了items.py中定义的字段并判断每位用户的详情页中的keys是否包含该字段,如包含则获取
for field in item.fields:
if field in result.keys():
item[field] = result.get(field)
yield item
#定义回调函数,爬取他的关注者与粉丝的详细信息,实现层层迭代
yield scrapy.Request(self.follows_url.format(user=result.get('url_token'), include=self.follows_query, offset=0, limit=20), callback=self.parseFollows)
yield scrapy.Request(self.followers_url.format(user=result.get('url_token'), include=self.followers_query, offset=0, limit=20), callback=self.parseFollowers) #他的关注者的页面解析函数
def parseFollows(self, response):
results = json.loads(response.text)
#判断data标签下是否含有获取的文本字段的keys
if 'data' in results.keys():
for result in results.get('data'):
yield scrapy.Request(self.user_url.format(user=result.get('url_token'), include=self.user_query), callback=self.parseUser)
#判断页面是否翻到了最后
if 'paging' in results.keys() and results.get('paging').get('is_end') == False:
next_page = results.get('paging').get('next')
yield scrapy.Request(next_page, callback=self.parseFollows) #他的粉丝的页面解析函数
def parseFollowers(self, response):
results = json.loads(response.text) if 'data' in results.keys():
for result in results.get('data'):
yield scrapy.Request(self.user_url.format(user=result.get('url_token'), include=self.user_query), callback=self.parseUser) if 'paging' in results.keys() and results.get('paging').get('is_end') == False:
next_page = results.get('paging').get('next')
yield scrapy.Request(next_page, callback=self.parseFollowers)
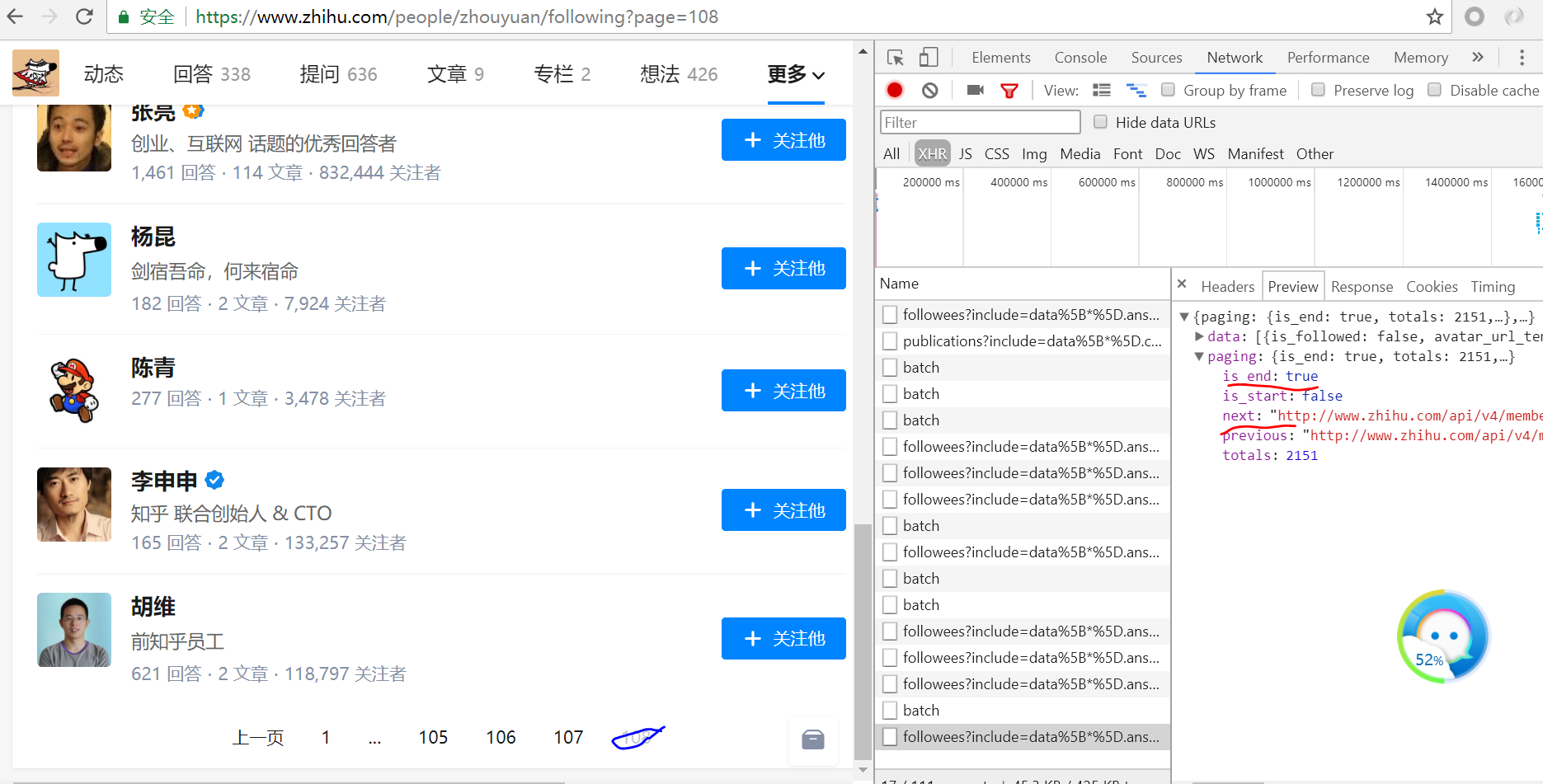
我们可以看到当我们翻到了最后is_end字段变为了True,而next字段就是下一个页面的url
(7)、运行下程序,可以看见已经在爬取了

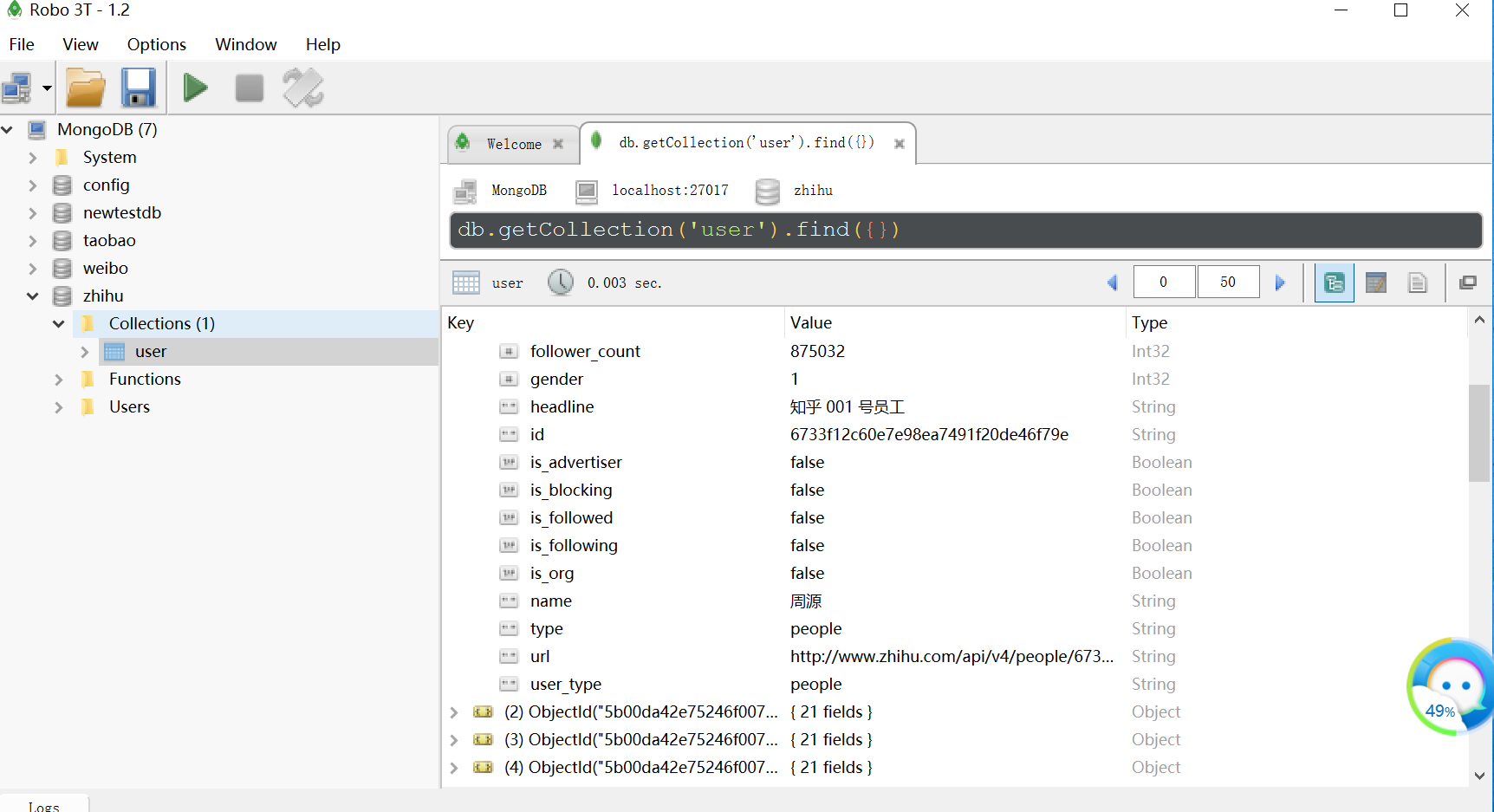
(8)、将结果存入Mongodb数据库
重写pipelines.py
import pymongo
class MongoPipeline(object):
collection_name = 'user'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db['user'].update({'url_token' :item['url_token']},{'$set':item},True)
代码分析:
我们创建了名为user的集合
重写了__init__方法指定了数据库的链接地址和数据库名称
并修改了工厂类函数(具体参见上讲ITEM PIPLELIEN用法)
打开数据库并插入数据并以url_token字段对重复数据执行了更新操作
最后我们关闭了数据库
再配置下settings.py


再次运行程序,可以看见我们的数据就到了数据库了
Scrapy爬虫框架第八讲【项目实战篇:知乎用户信息抓取】--本文参考静觅博主所写的更多相关文章
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- Scrapy爬虫框架第七讲【ITEM PIPELINE用法】
ITEM PIPELINE用法详解: ITEM PIPELINE作用: 清理HTML数据 验证爬取的数据(检查item包含某些字段) 去重(并丢弃)[预防数据去重,真正去重是在url,即请求阶段做] ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(下)
前几天小编带大家学会了如何在Scrapy框架下创建属于自己的第一个爬虫项目(上),今天我们进一步深入的了解Scrapy爬虫项目创建,这里以伯乐在线网站的所有文章页为例进行说明. 在我们创建好Scrap ...
- python 手机App数据抓取实战二抖音用户的抓取
前言 什么?你问我国庆七天假期干了什么?说出来你可能不信,我爬取了cxk坤坤的抖音粉丝数据,我也不知道我为什么这么无聊. 本文主要记录如何使用appium自动化工具实现抖音App模拟滑动,然后分析数据 ...
- Scrapy爬虫框架第四讲(Linux环境)
下面我们来学习Selector的具体使用:(参考文档:http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/selectors.html) Selecto ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
随机推荐
- Select、Poll与Epoll比较
(1)select select最早于1983年出现在4.2BSD中,它通过一个select()系统调用来监视多个文件描述符的数组,当select()返回后,该数组中就绪的文件描述符便会被内核修改标志 ...
- UML类图中连接线与箭头的含义(转)
UML类图是描述类之间的关系 概念 类(Class):使用三层矩形框表示. 第一层显示类的名称,如果是抽象类,则就用斜体显示. 第二层是字段和属性. 第三层是类的方法. 注意前面的符号,'+'表示pu ...
- IOS常用第三方库《转》
UI 动画 网络相关 Model 其他 数据库 缓存处理 PDF 图像浏览及处理 摄像照相视频音频处理 响应式框架 消息相关 版本新API的Demo 代码安全与密码 测试及调试 AppleWatch ...
- <mate name="viewport">移动端设置详解
<meta name="viewport" content="width=device-width,height=device-height,initial-sca ...
- 树的广度优先遍历和深度优先遍历(递归非递归、Java实现)
在编程生活中,我们总会遇见树性结构,这几天刚好需要对树形结构操作,就记录下自己的操作方式以及过程.现在假设有一颗这样树,(是不是二叉树都没关系,原理都是一样的) 1.广度优先遍历 英文缩写为BFS即B ...
- 关于Django升级的一些联想
刚刚阅读完django1.11的release note,从django1.4一直用到django1.11,以及即将到来的大版本django2.0,Django的版本升级策略和国内的技术现状对比称得上 ...
- ImageMagick
http://blog.csdn.net/lan861698789/article/details/7738383 1.官网 http://www.imagemagick.org/script/ind ...
- 绕过校园网WEB认证_iodine实现
这篇文章是对我的上一篇文章"绕过校园网WEB认证_dns2tcp实现"的补充,在那篇文章中,我讲述了绕过校园网WEB认证的原理,并介绍了如何在windows系统下绕过校园网WEB认 ...
- unity零基础开始学习做游戏(四)biu~biu~biu发射子弹打飞机
-------小基原创,转载请给我一个面子 主角都能移动了,那不得做点什么伸张正义,守护世界和平的事嘛,拿起家伙biu~biu~biu~ 首先得做一个好人和一个坏人 老规矩,Canvas下创建两个Im ...
- var $this = $(this)是什么意思?
var $this = $(this) 声明一个变量,$this 是变量名,加$说明是jquery对象. 给声明的变量赋值,赋的值是将this元素转换为jQuery对象.