AI带你省钱旅游!精准预测民宿房源价格!

作者:韩信子@ShowMeAI
数据分析实战系列:https://www.showmeai.tech/tutorials/40
机器学习实战系列:https://www.showmeai.tech/tutorials/41
本文地址:https://www.showmeai.tech/article-detail/316
声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容

大家出去旅游最关心的问题之一就是住宿,在国外以 Airbnb 为代表的民宿互联网模式彻底改变了酒店业,很多游客更喜欢预订 Airbnb 而不是酒店,而在国内的美团飞猪等平台,也有大量的民宿入驻。
在现在这个信息透明开放的互联网时代,我们能否收集数据信息,开发一个机器学习模型来预测房源价格,为自己的出行提供更智能化的信息呢?肯定是可以的,下面ShowMeAI以Airbnb在大曼彻斯特地区的房源数据为例(截至 2022 年 3 月),来演示数据分析与挖掘建模的全过程,同样的方法模式可以应用在大家熟悉的国内平台上。

下面的项目业务和 Airbnb民宿数据 来源于 Inside Airbnb,包含有关 Airbnb 对住宅社区影响的数据和宣传。数据源可以在上述链接中获取,大家也可以访问ShowMeAI的百度网盘地址,获取我们为大家存储好的项目数据。
实战数据集下载(百度网盘):公众号『ShowMeAI研究中心』回复『实战』,或者点击 这里 获取本文 [22]基于Airbnb数据的民宿房价预测模型 『Airbnb民宿数据』
ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub
业务问题
一般我们需要在开始挖掘和建模之前,深入了解我们的业务场景和数据情况,我们先总结了一些在这个业务场景下我们关心的一些业务问题,我们将通过数据分析挖掘来完成这些业务问题的理解。
- 哪些地区或城镇的 Airbnb 房源最多?
- 最受欢迎的房型是什么?
- 大曼彻斯特地区的 Airbnb 房源价格特点是什么?
- 房源与房东的分布情况?
- 大曼彻斯特地区有哪些房型可供选择?
- 机器学习模型预测该地区 Airbnb 房源价格的思路是什么样的?
- 在预测大曼彻斯特地区 Airbnb 房源的价格时,哪些特征更重要?
数据读取与初探
我们先导入本次需要使用到的分析挖掘与建模工具库
import numpy as np
import pandas as pd
from tqdm.notebook import tqdm, trange
import seaborn as sb
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, mean_squared_error
from sklearn.preprocessing import StandardScaler
import statsmodels.api as sm
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline, FeatureUnion
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import GradientBoostingRegressor
from statsmodels.stats.outliers_influence import variance_inflation_factor
from sklearn.inspection import permutation_importance
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
接下来我们读取大曼彻斯特地区的房源数据
gm_listings = pd.read_csv('gm_listings-2.csv')
gm_calendar = pd.read_csv('calendar-2.csv')
gm_reviews = pd.read_csv('reviews-2.csv')
查看数据的基础信息如下
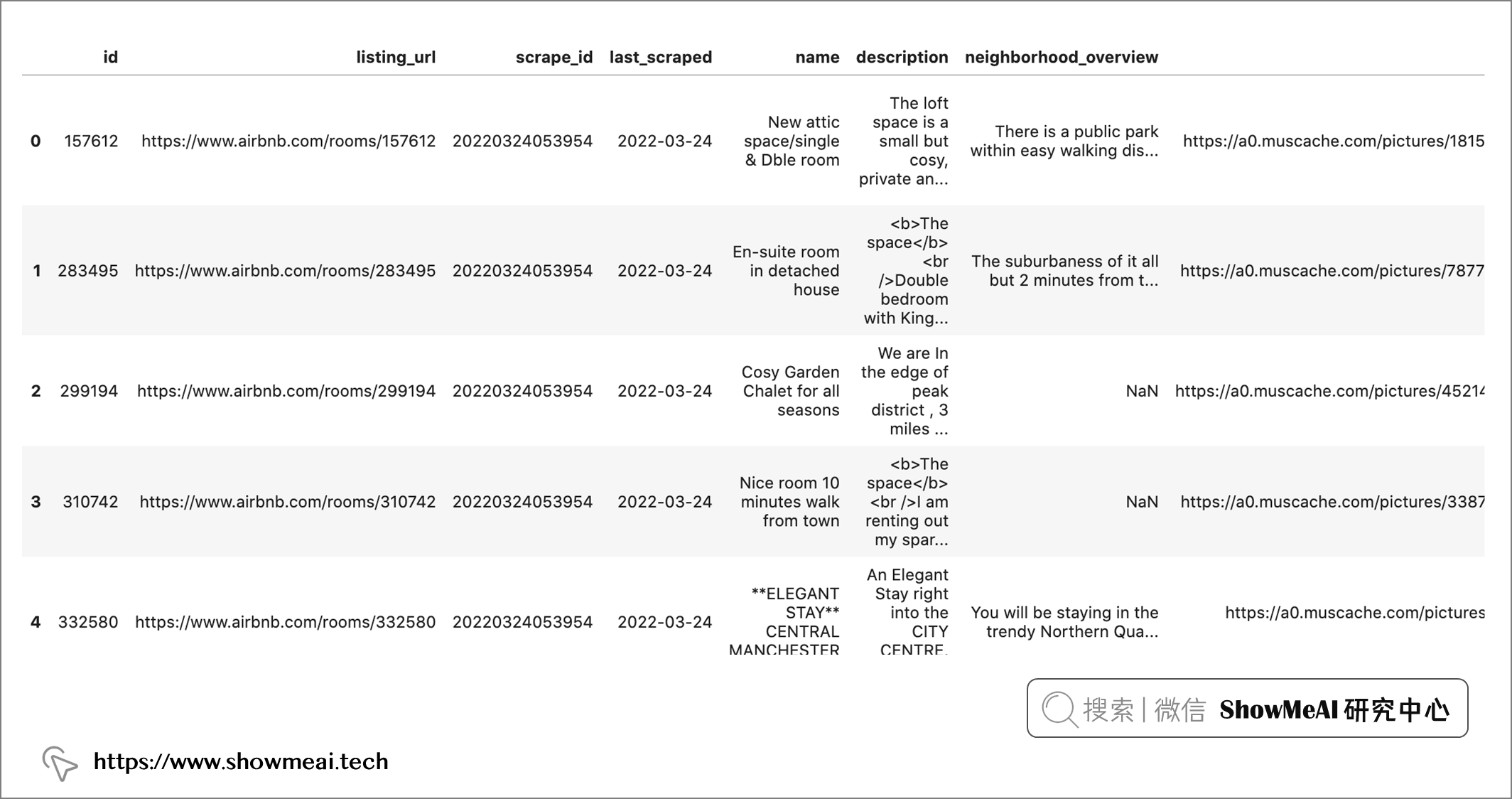
gm_listings.head()
gm_listings.shape
# (3584, 74)
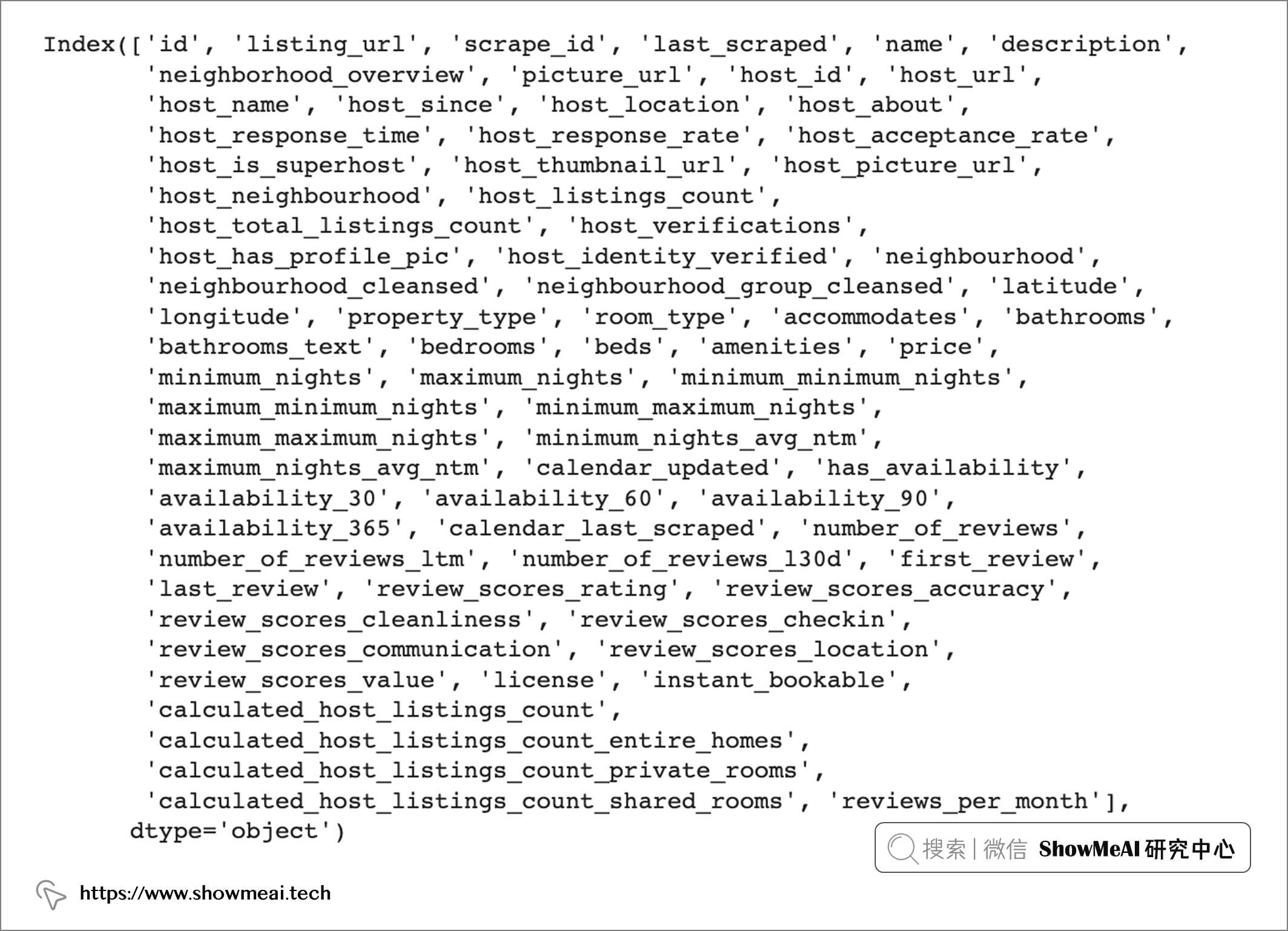
gm_listings.columns
gm_calendar.head()
gm_reviews.head()
我们对数据的初览可以看到,大曼彻斯特地区的房源数据集包含 3584 行和 78 列,包含有关房东、房源类型、区域和评级的信息。
数据清洗

数据清洗是机器学习建模应用的【特征工程】阶段的核心步骤,它涉及的方法技能欢迎大家查阅ShowMeAI对应的教程文章,快学快用。
字段清洗
因为数据中的字段众多,有些字段比较乱,我们需要做一些数据清洗的工作,数据包含一些带有URL的列,对最后的预测作用不大,我们把它们清洗掉。
# 删除url字段
def drop_function(df):
df = df.drop(columns=['listing_url', 'description', 'host_thumbnail_url', 'host_picture_url', 'latitude', 'longitude', 'picture_url', 'host_url', 'host_location', 'neighbourhood', 'neighbourhood_cleansed', 'host_about', 'has_availability', 'availability_30', 'availability_60', 'availability_90', 'availability_365', 'calendar_last_scraped'])
return df
gm_df = drop_function(gm_listings)
删除过后的数据如下,干净很多
缺失值处理
数据中也包含了一些缺失值,我们对它们进行分析处理:
# 查看缺失值百分比
(gm_df.isnull().sum()/gm_df.shape[0])* 100
得到如下结果
id 0.000000
scrape_id 0.000000
last_scraped 0.000000
name 0.000000
neighborhood_overview 41.266741
host_id 0.000000
host_name 0.000000
host_since 0.000000
host_response_time 10.212054
host_response_rate 10.212054
host_acceptance_rate 5.636161
host_is_superhost 0.000000
host_neighbourhood 91.657366
host_listings_count 0.000000
host_total_listings_count 0.000000
host_verifications 0.000000
host_has_profile_pic 0.000000
host_identity_verified 0.000000
neighbourhood_group_cleansed 0.000000
property_type 0.000000
room_type 0.000000
accommodates 0.000000
bathrooms 100.000000
bathrooms_text 0.306920
bedrooms 4.687500
beds 2.120536
amenities 0.000000
price 0.000000
minimum_nights 0.000000
maximum_nights 0.000000
minimum_minimum_nights 0.000000
maximum_minimum_nights 0.000000
minimum_maximum_nights 0.000000
maximum_maximum_nights 0.000000
minimum_nights_avg_ntm 0.000000
maximum_nights_avg_ntm 0.000000
calendar_updated 100.000000
number_of_reviews 0.000000
number_of_reviews_ltm 0.000000
number_of_reviews_l30d 0.000000
first_review 19.810268
last_review 19.810268
review_scores_rating 19.810268
review_scores_accuracy 20.089286
review_scores_cleanliness 20.089286
review_scores_checkin 20.089286
review_scores_communication 20.089286
review_scores_location 20.089286
review_scores_value 20.089286
license 100.000000
instant_bookable 0.000000
calculated_host_listings_count 0.000000
calculated_host_listings_count_entire_homes 0.000000
calculated_host_listings_count_private_rooms 0.000000
calculated_host_listings_count_shared_rooms 0.000000
reviews_per_month 19.810268
dtype: float64
我们分几种不同的比例情况对缺失值进行处理:
高缺失比例的字段,如license、calendar_updated、bathrooms、host_neighborhood等包含90%以上的NaN值,包括neighborhood overview是41%的NaN,并且包含文本数据。我们会直接剔除这些字段。
数值型字段,缺失不多的情况下,我们用字段平均值进行填充。这保证了这些值的分布被保留下来。这些列包括bedrooms、beds、review_scores_rating、review_scores_accuracy和其他打分字段。
类别型字段,像bathrooms_text和host_response_time,我们用众数进行填充。
# 剔除高缺失比例字段
def drop_function_2(df):
df = df.drop(columns=['license', 'calendar_updated', 'bathrooms', 'host_neighbourhood', 'neighborhood_overview'])
return df
gm_df = drop_function_2(gm_df)
# 均值填充
def input_mean(df, column_list):
for columns in column_list:
df[columns].fillna(value = df[columns].mean(), inplace=True)
return df
column_list = ['review_scores_rating', 'review_scores_accuracy', 'review_scores_cleanliness',
'review_scores_checkin', 'review_scores_communication', 'review_scores_location',
'review_scores_value', 'reviews_per_month',
'bedrooms', 'beds']
gm_df = input_mean(gm_df, column_list)
# 众数填充
def input_mode(df, column_list):
for columns in column_list:
df[columns].fillna(value = df[columns].mode()[0], inplace=True)
return df
column_list = ['first_review', 'last_review', 'bathrooms_text', 'host_acceptance_rate',
'host_response_rate', 'host_response_time']
gm_df = input_mode(gm_df, column_list)
字段编码
host_is_superhost 和 has_availability 等列对应的字符串含义为 true 或 false,我们对其编码替换为0或1。
gm_df = gm_df.replace({'host_is_superhost': 't', 'host_has_profile_pic': 't', 'host_identity_verified': 't', 'has_availability': 't', 'instant_bookable': 't'}, 1)
gm_df = gm_df.replace({'host_is_superhost': 'f', 'host_has_profile_pic': 'f', 'host_identity_verified': 'f', 'has_availability': 'f', 'instant_bookable': 'f'}, 0)
我们查看下替换后的数据分布
gm_df['host_is_superhost'].value_counts()

字段格式转换
价格相关的字段,目前还是字符串类型,包含“$”等符号,我们对其处理并转换为数值型。
def string_to_int(df, column):
# 字符串替换清理
df[column] = df[column].str.replace("$", "")
df[column] = df[column].str.replace(",", "")
# 转为数值型
df[column] = pd.to_numeric(df[column]).astype(int)
return df
gm_df = string_to_int(gm_df, 'price')
列表型字段编码
像host_verifications和amenities这样的字段,取值为列表格式,我们对其进行编码处理(用哑变量替换)。
# 查看列表型取值字段
gm_df_copy = gm_df.copy()
gm_df_copy['amenities'].head()

gm_df_copy['host_verifications'].head()

# 哑变量编码
gm_df_copy['amenities'] = gm_df_copy['amenities'].str.replace('"', '')
gm_df_copy['amenities'] = gm_df_copy['amenities'].str.replace(']', "")
gm_df_copy['amenities'] = gm_df_copy['amenities'].str.replace('[', "")
df_amenities = gm_df_copy['amenities'].str.get_dummies(sep = ",")
gm_df_copy['host_verifications'] = gm_df_copy['host_verifications'].str.replace("'", "")
gm_df_copy['host_verifications'] = gm_df_copy['host_verifications'].str.replace(']', "")
gm_df_copy['host_verifications'] = gm_df_copy['host_verifications'].str.replace('[', "")
df_host_ver = gm_df_copy['host_verifications'].str.get_dummies(sep = ",")
编码后的结果如下所示
df_amenities.head()
df_host_ver.head()
# 删除原始字段
gm_df = gm_df.drop(['host_verifications', 'amenities'], axis=1)
数据探索
下一步我们要进行更全面一些的探索性数据分析。
EDA数据分析部分涉及的工具库,大家可以参考ShowMeAI制作的工具库速查表和教程进行学习和快速使用。
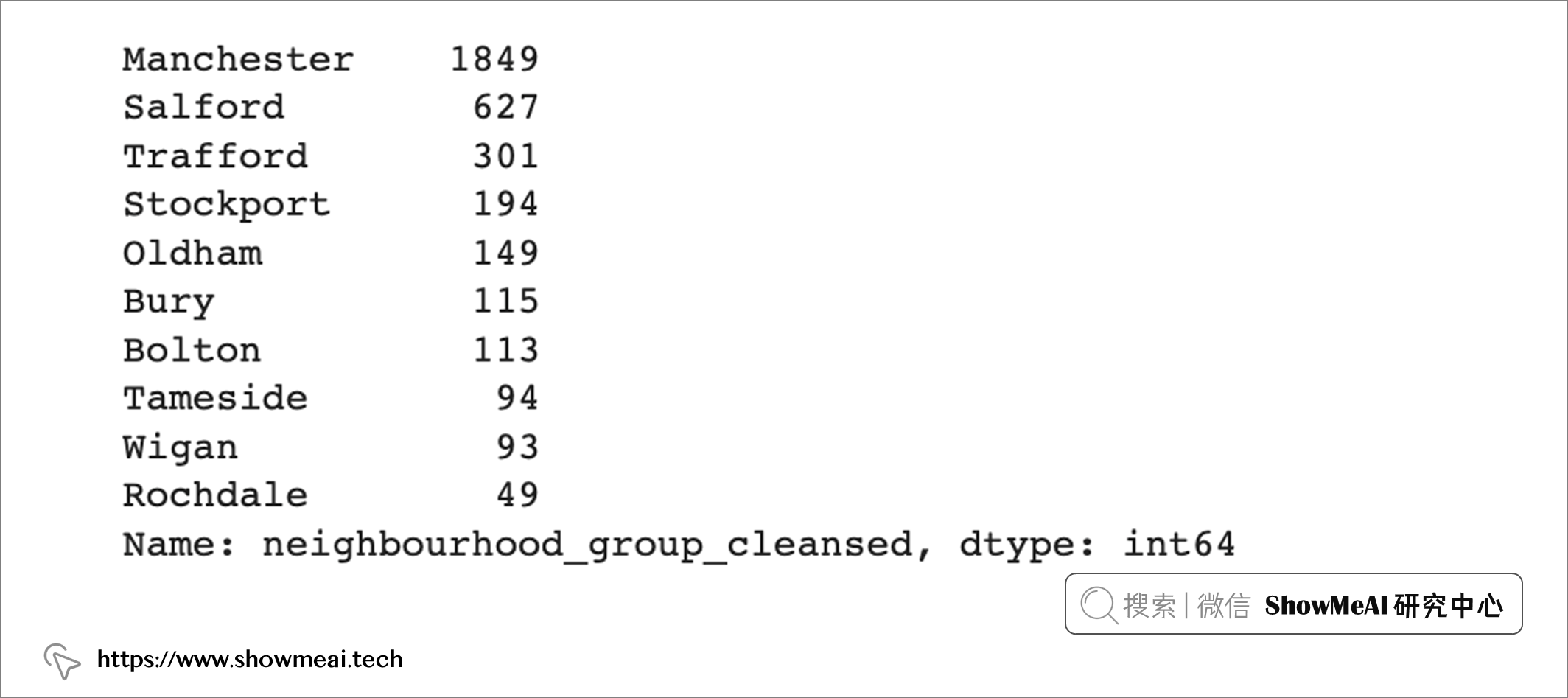
哪些街区的房源最多?
gm_df['neighbourhood_group_cleansed'].value_counts()
bar_data = gm_df['neighbourhood_group_cleansed'].value_counts().sort_values()
# 从bar_data构建新的dataframe
bar_data = pd.DataFrame(bar_data).reset_index()
bar_data['size'] = bar_data['neighbourhood_group_cleansed']/gm_df['neighbourhood_group_cleansed'].count()
# 排序
bar_data.sort_values(by='size', ascending=False)
bar_data = bar_data.rename(columns={'index' : 'Towns', 'neighbourhood_group_cleansed' : 'number_of_listings',
'size':'fraction_of_total'})
#绘图展示
#plt.figure(figsize=(10,10));
bar_data.plot(kind='barh', x ='Towns', y='fraction_of_total', figsize=(8,6))
plt.title('Towns with the Most listings');
plt.xlabel('Fraction of Total Listings');
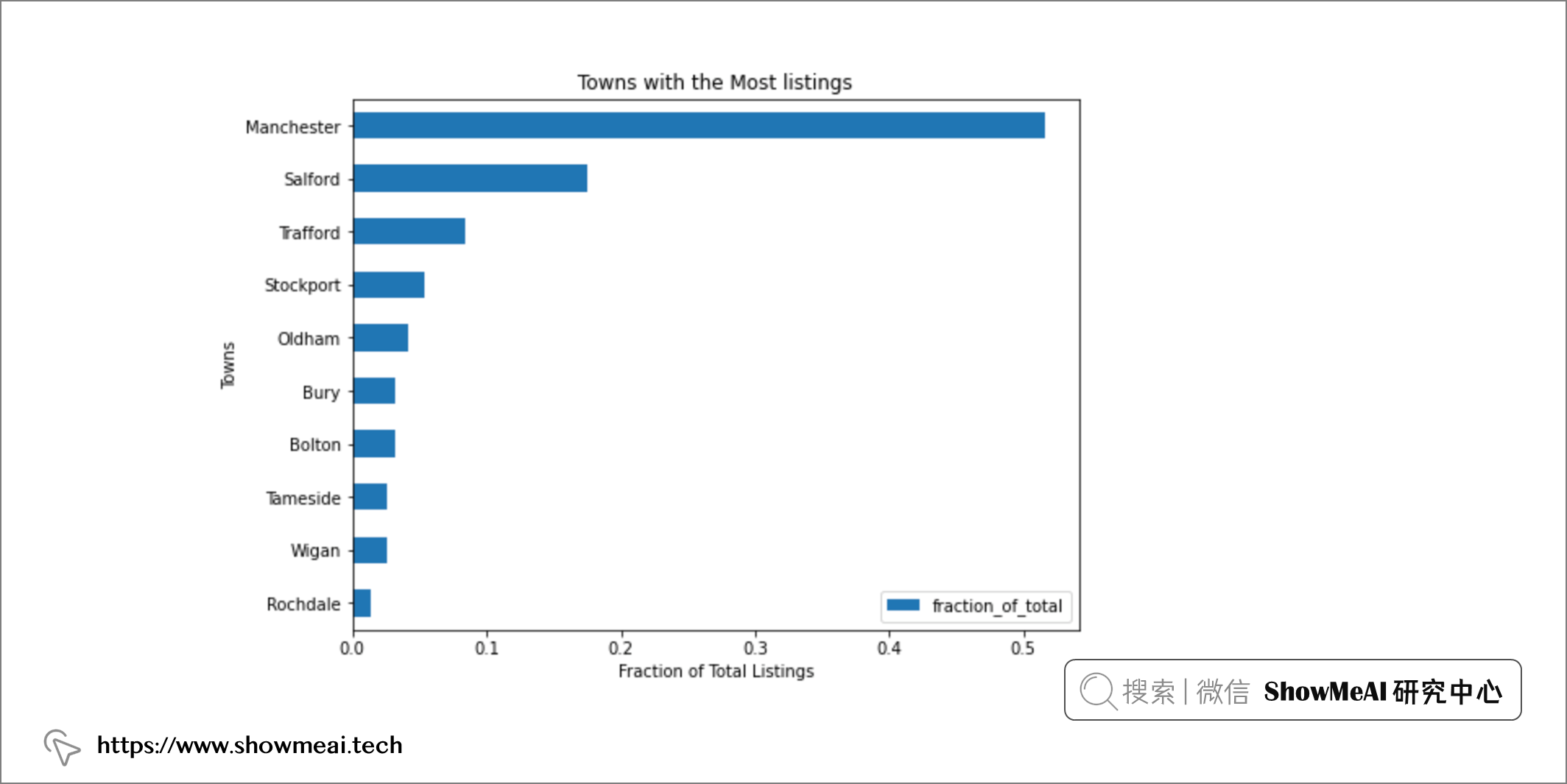
曼彻斯特镇拥有大曼彻斯特地区的大部分房源,占总房源的 53% (1849),其次是索尔福德,占总房源的 17% ;特拉福德,占总房源的 9%。
大曼彻斯特地区的 Airbnb 房源价格分布
gm_df['price'].mean(), gm_df['price'].min(), gm_df['price'].max(),gm_df['price'].median()
# (143.47600446428572, 8, 7372, 79.0)
Airbnb 房源的均价为 143 美元,中位价为 79 美元,数据集中观察到的最高价格为 7372 美元。
# 划分价格档位区间
labels = ['$0 - $100', '$100 - $200', '$200 - $300', '$300 - $400', '$400 - $500', '$500 - $1000', '$1000 - $8000']
price_cuts = pd.cut(gm_df['price'], bins = [0, 100, 200, 300, 400, 500, 1000, 8000], right=True, labels= labels)
# 从价格档构建dataframe
price_clusters = pd.DataFrame(price_cuts).rename(columns={'price': 'price_clusters'})
# 拼接原始dataframe
gm_df = pd.concat([gm_df, price_clusters], axis=1)
# 分布绘图
def price_cluster_plot(df, column, title):
plt.figure(figsize=(8,6));
yx = sb.histplot(data = df[column]);
total = float(df[column].count())
for p in yx.patches:
width = p.get_width()
height = p.get_height()
yx.text(p.get_x() + p.get_width()/2.,height+5, '{:1.1f}%'.format((height/total)*100), ha='center')
yx.set_title(title);
plt.xticks(rotation=90)
return yx
price_cluster_plot(gm_df, column='price_clusters',
title='Price distribution of Airbnb Listings in the Greater Manchester Area');
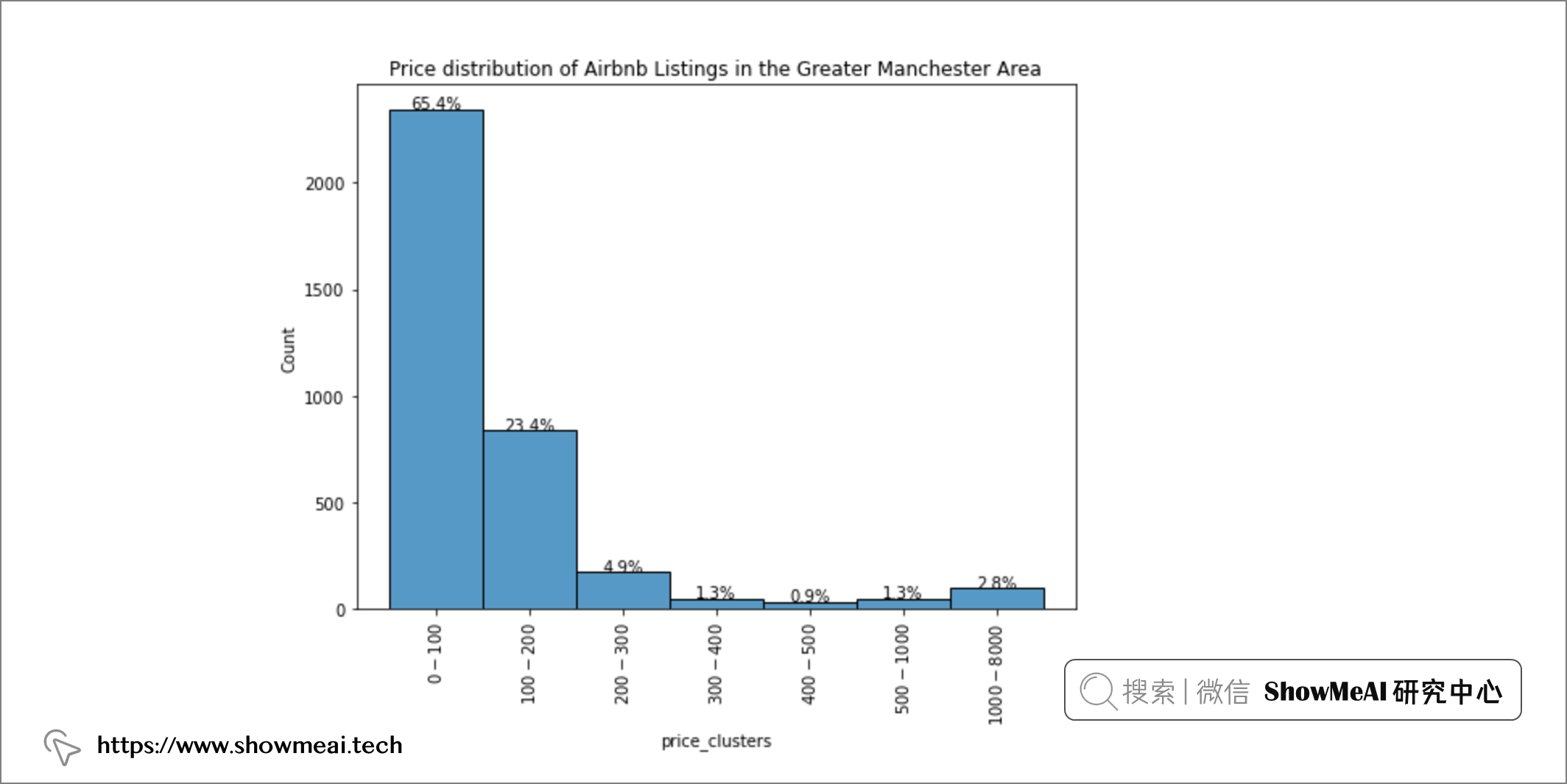
从上面的分析和可视化结果可以看出,65.4% 的总房源价格在 0-100 美元之间,而价格在 100-200 美元的房源占总房源的 23.4%。不过我们也观察到数据分布有很明显的长尾特性,也可以把特别高价的部分视作异常值,它们可能会对我们的分析有一些影响。
最受欢迎的房型是什么
# 基于评论量统计排序
ax = gm_df.groupby('property_type').agg(
median_rating=('review_scores_rating', 'median'),number_of_reviews=('number_of_reviews', 'max')).sort_values(
by='number_of_reviews', ascending=False).reset_index()
ax.head()
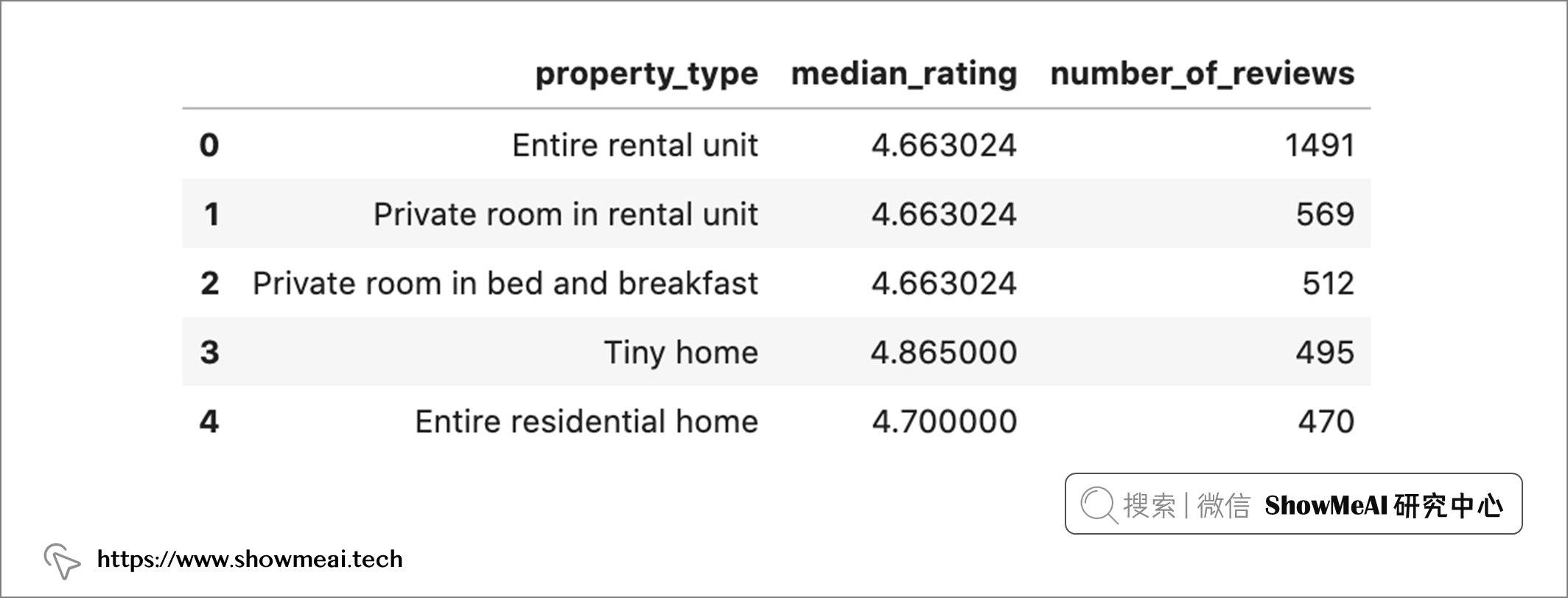
在评论最多的前 10 种房产类型中, Entire rental unit 评论数量最多,其次是Private room in rental unit。
# 可视化
bx = ax.loc[:10]
bx =sb.boxplot(data =bx, x='median_rating', y='property_type')
bx.set_xlim(4.5, 5)
plt.title('Most Enjoyed Property types');
plt.xlabel('Median Rating');
plt.ylabel('Property Type')
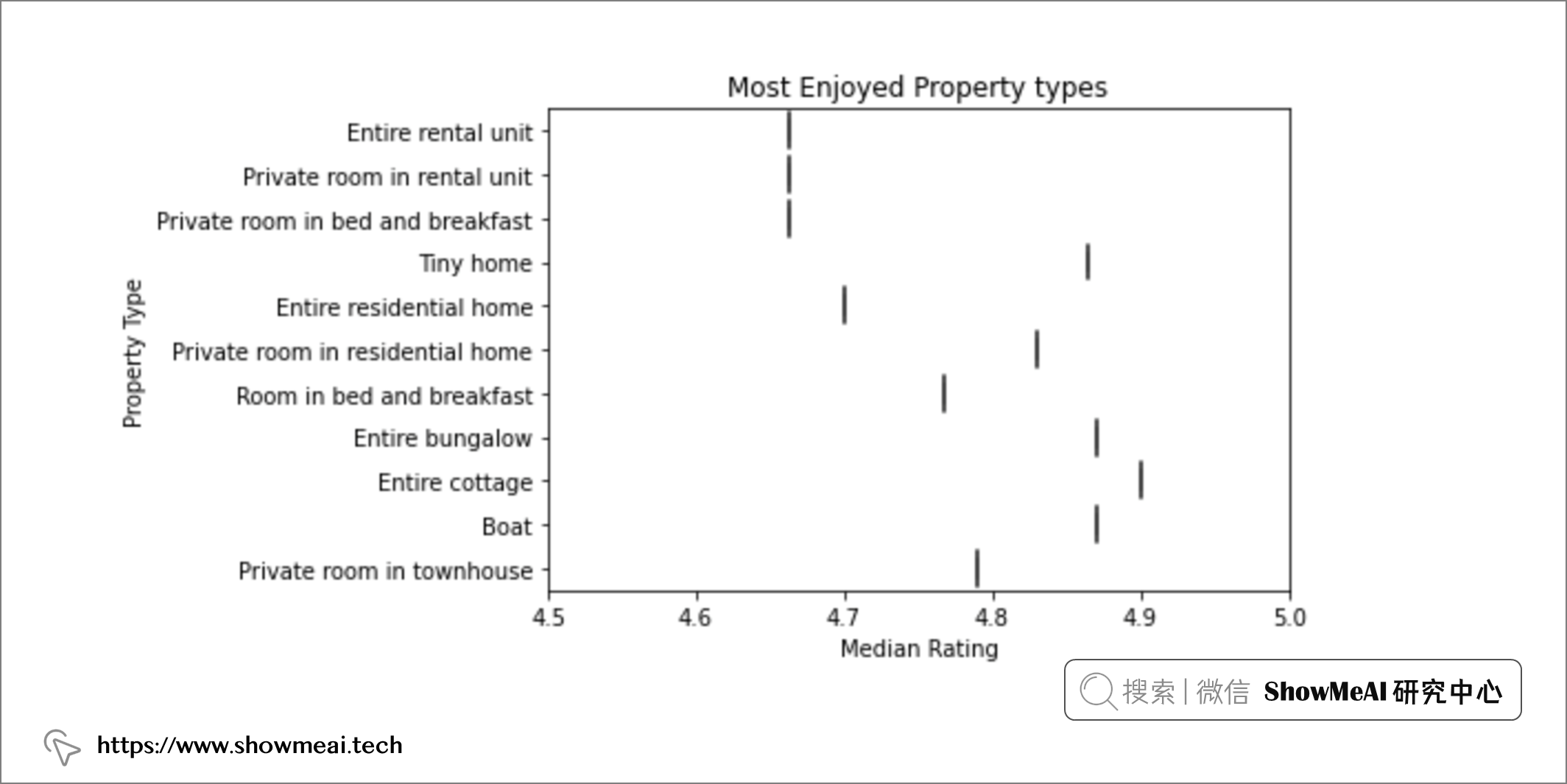
房东与房源分布
# 持有房源最多的房东
host_df = pd.DataFrame(gm_df['host_name'].value_counts()/gm_df['host_name'].count() *100).reset_index()
host_df = host_df.rename(columns={'index':'name', 'host_name':'perc_count'})
host_df.head(10)
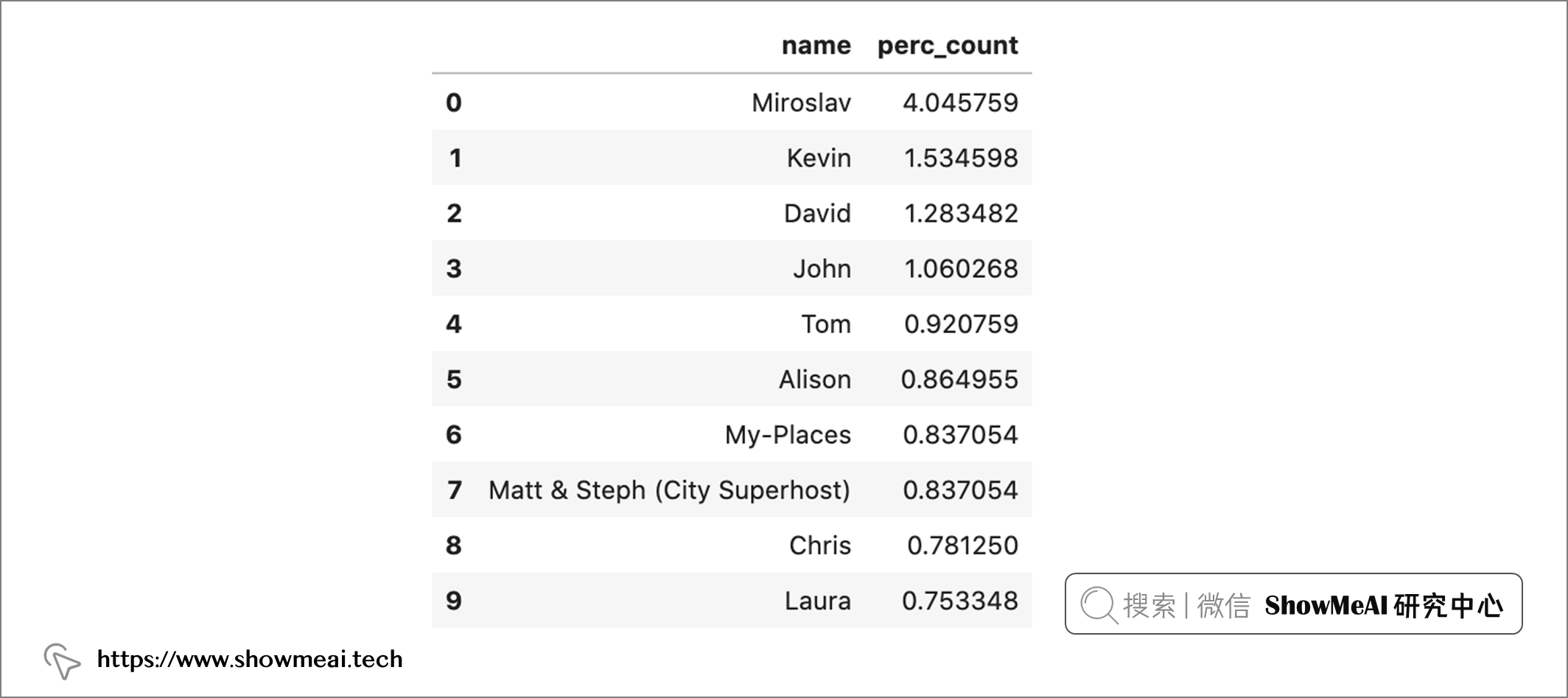
host_df['perc_count'].loc[:10].sum()
从上述分析可以看出,房源最多的前 10 名房东占房源总数的 13.6%。
大曼彻斯特地区提供的客房类型分布
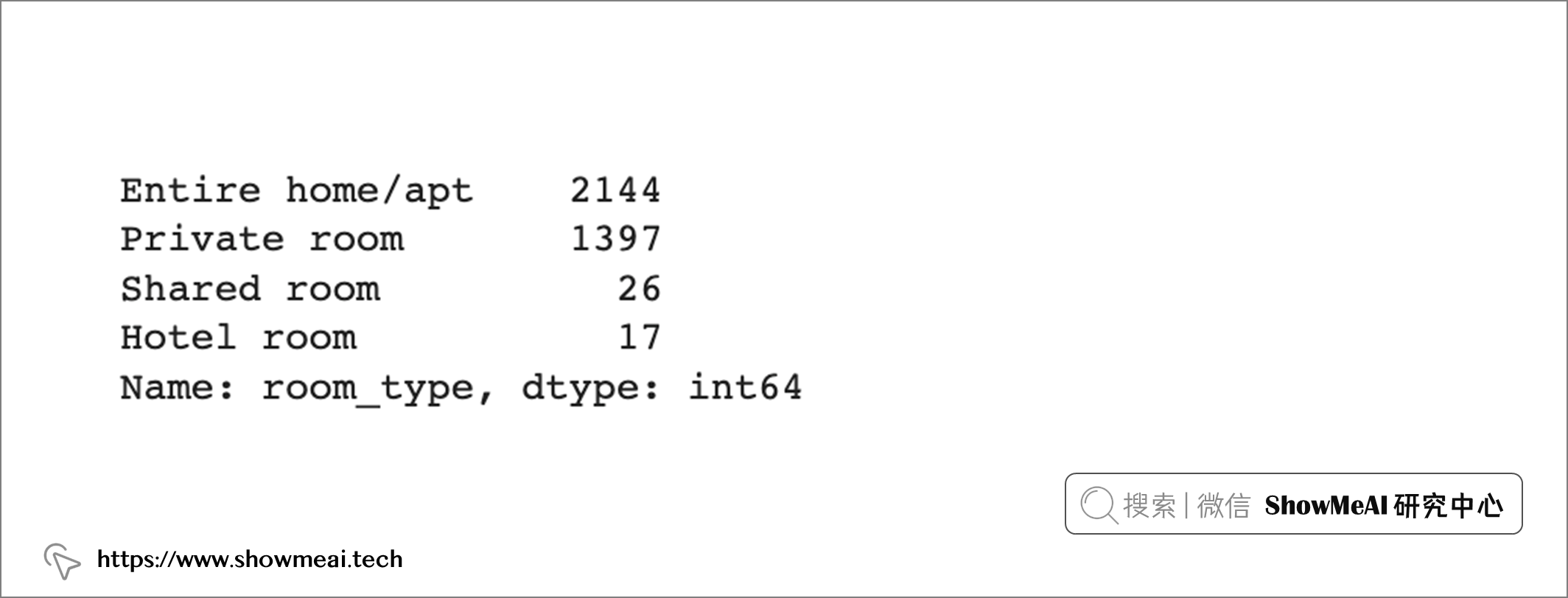
gm_df['room_type'].value_counts()
# 分布绘图
zx = sb.countplot(data=gm_df, x='room_type')
total = float(gm_df['room_type'].count())
for p in zx.patches:
width = p.get_width()
height = p.get_height()
zx.text(p.get_x() + p.get_width()/2.,height+5, '{:1.1f}%'.format((height/total)*100), ha='center')
zx.set_title('Plot showing different type of rooms available');
plt.xlabel('Room')
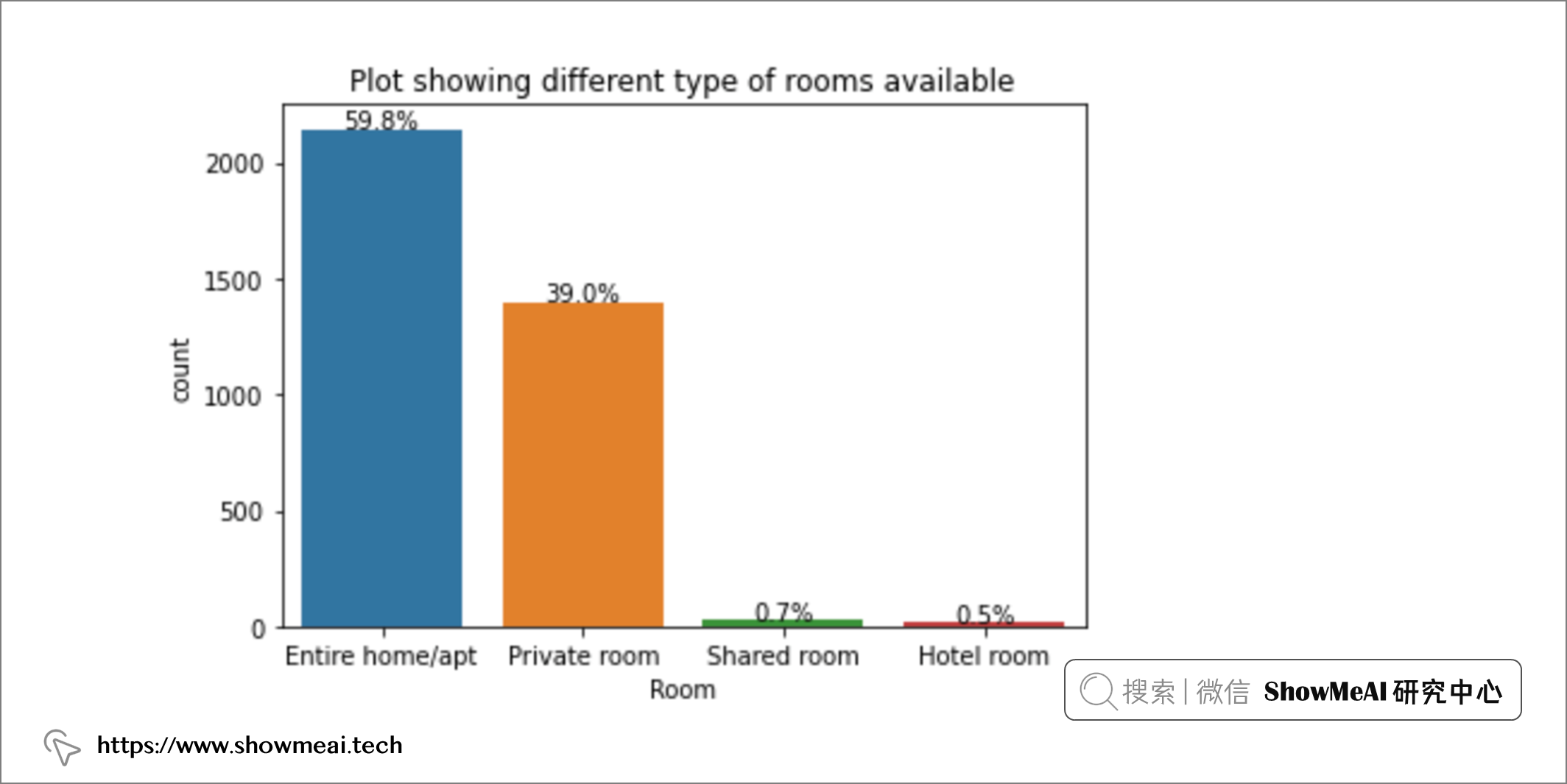
大部分客房是 整栋房屋/公寓 ,占房源总数的 60%,其次是私人客房,占房源总数的 39%,共享房间 和 酒店房间 分别占房源的 0.7% 和 0.5%。
机器学习建模
下面我们使用回归建模方法来对民宿房源价格进行预估。
特征工程
关于特征工程,欢迎大家查阅ShowMeAI对应的教程文章,快学快用。
我们首先对原始数据进行特征工程,得到适合建模的数据特征。
# 查看此时的数据集
gm_df.head()
# 回归数据集
gm_regression_df = gm_df.copy()
# 剔除无用字段
gm_regression_df = gm_regression_df.drop(columns=['id', 'scrape_id', 'last_scraped', 'name', 'host_id', 'host_since', 'first_review', 'last_review', 'price_clusters', 'host_name'])
# 再次查看数据
gm_regression_df.head()
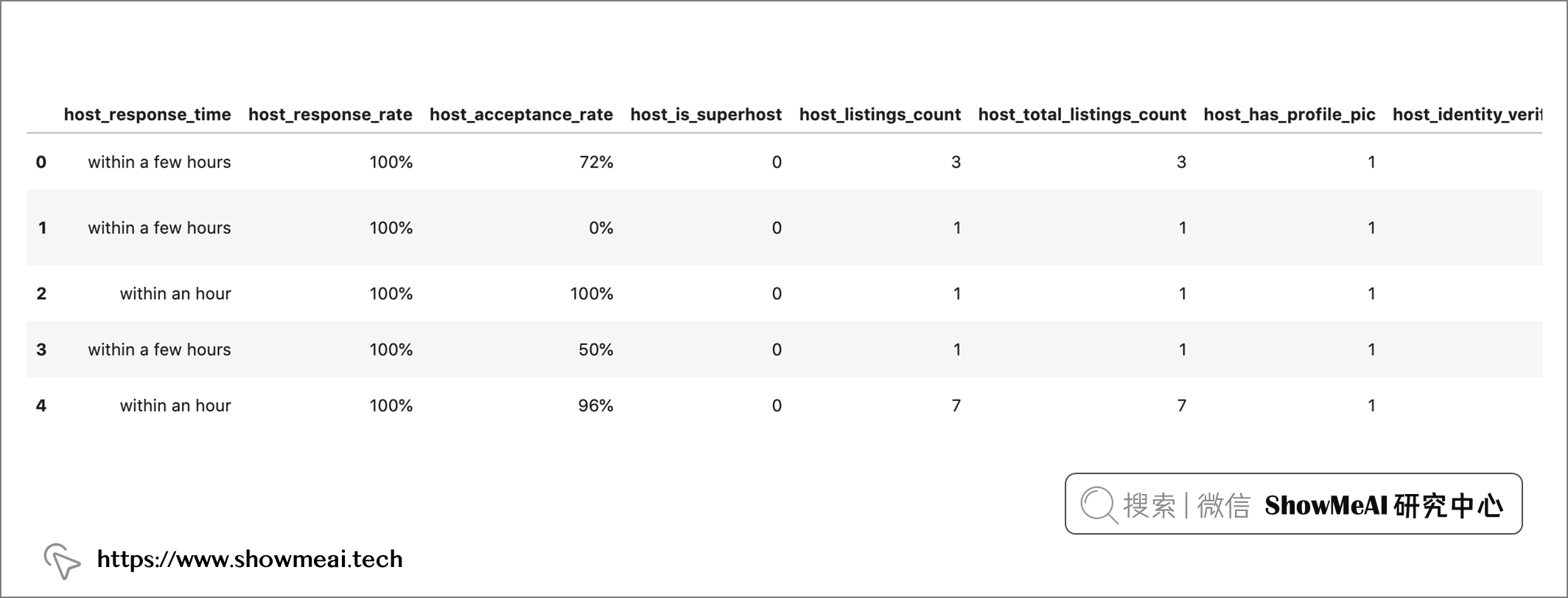
我们发现host_response_rate 和 host_acceptance_rate字段带有百分号,我们再做一点数据清洗。
# 去除百分号并转换为数值型
gm_regression_df['host_response_rate'] = gm_regression_df['host_response_rate'].str.replace("%", "")
gm_regression_df['host_acceptance_rate'] = gm_regression_df['host_acceptance_rate'].str.replace("%", "")
# convert to int
gm_regression_df['host_response_rate'] = pd.to_numeric(gm_regression_df['host_response_rate']).astype(int)
gm_regression_df['host_acceptance_rate'] = pd.to_numeric(gm_regression_df['host_acceptance_rate']).astype(int)
# 查看转换后结果
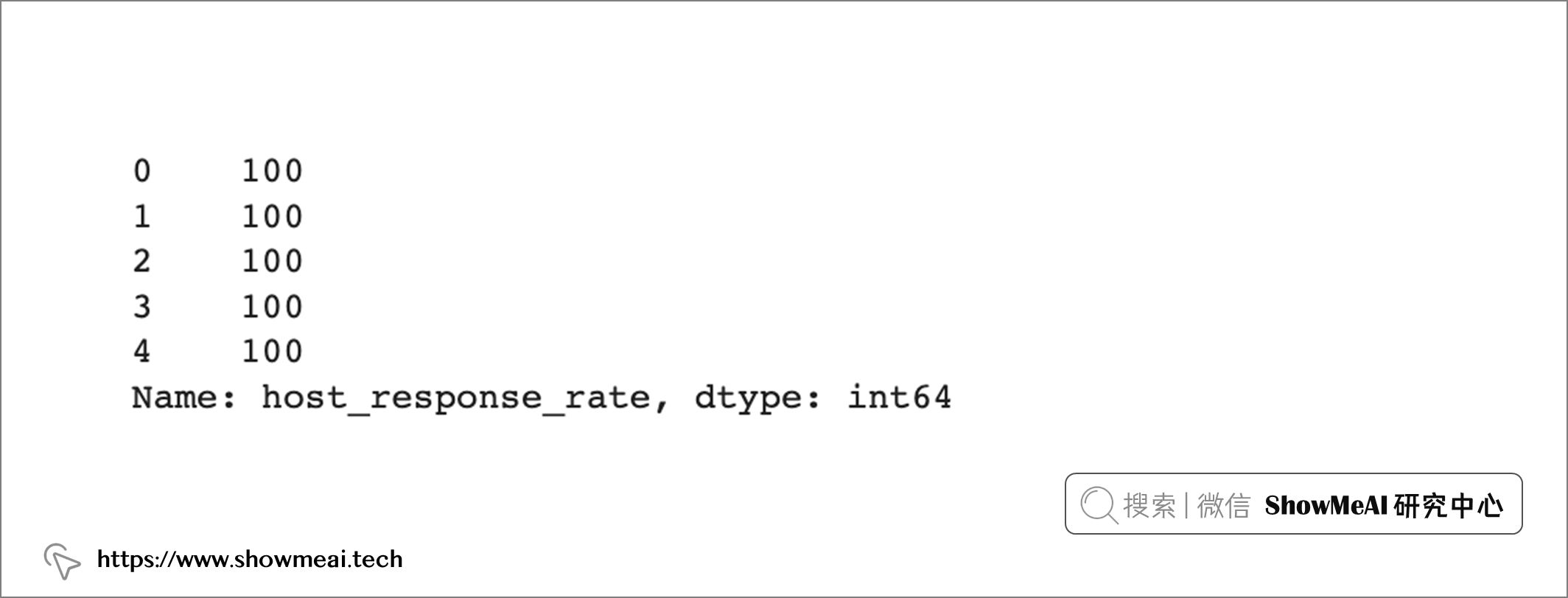
gm_regression_df['host_response_rate'].head()
bathrooms_text 列包含数字和文本数据的组合,我们对其做一些处理
# 查看原始字段
gm_regression_df['bathrooms_text'].value_counts()

# 切分与数据处理
def split_bathroom(df, column, text, new_column):
df_2 = df[df[column].str.contains(text, case=False)]
df.loc[df[column].str.contains(text, case=False), new_column] = df_2[column]
return df
# 应用上述函数
gm_regression_df = split_bathroom(gm_regression_df, column='bathrooms_text', text='shared', new_column='shared_bath')
gm_regression_df = split_bathroom(gm_regression_df, column='bathrooms_text', text='private', new_column='private_bath')
# 查看shared_bath字段
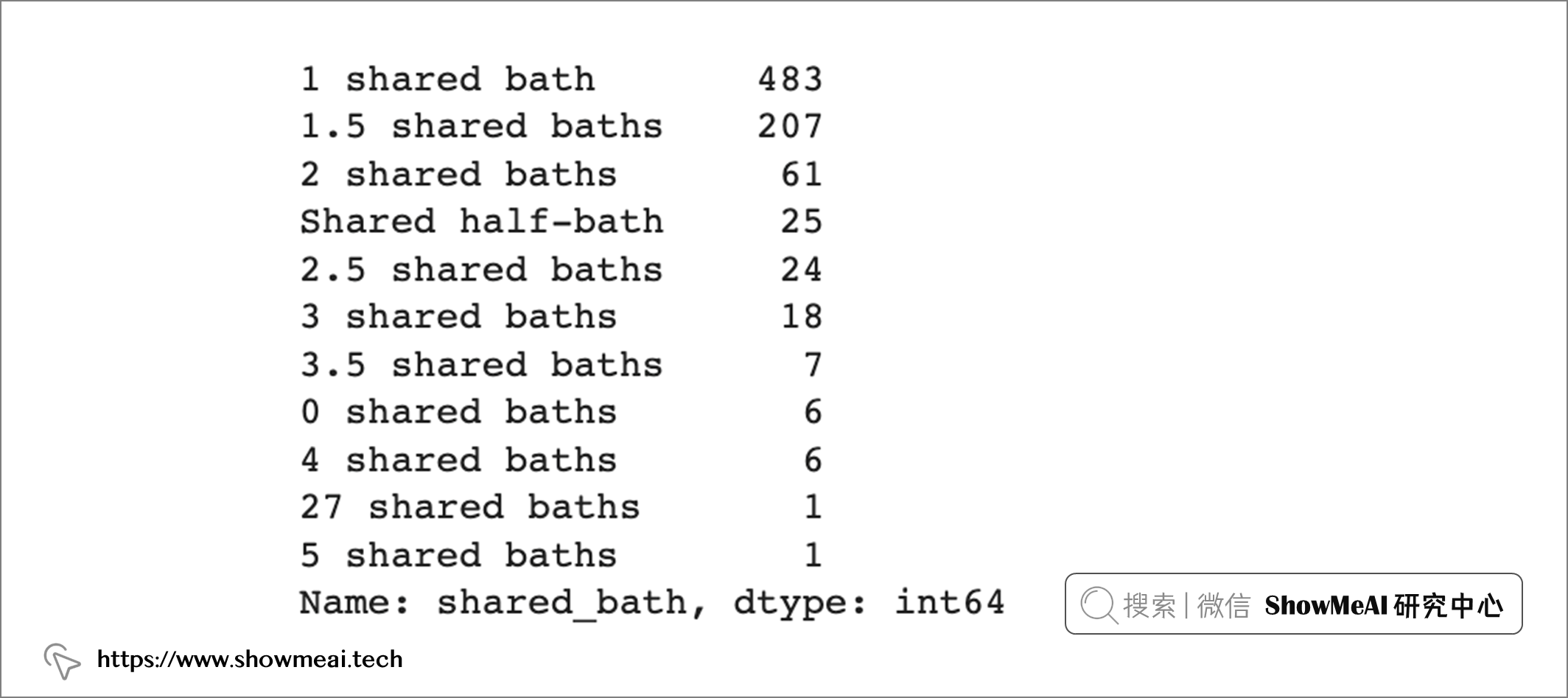
gm_regression_df['shared_bath'].value_counts()
# 查看private_bath字段
gm_regression_df['private_bath'].value_counts()

gm_regression_df['bathrooms_text'] = gm_regression_df['bathrooms_text'].str.replace("private bath", "pb", case=False)
gm_regression_df['bathrooms_text'] = gm_regression_df['bathrooms_text'].str.replace("private baths", "pbs", case=False)
gm_regression_df['bathrooms_text'] = gm_regression_df['bathrooms_text'].str.replace("shared bath", "sb", case=False)
gm_regression_df['bathrooms_text'] = gm_regression_df['bathrooms_text'].str.replace("shared baths", "sb", case=False)
gm_regression_df['bathrooms_text'] = gm_regression_df['bathrooms_text'].str.replace("shared half-bath", "sb", case=False)
gm_regression_df['bathrooms_text'] = gm_regression_df['bathrooms_text'].str.replace("private half-bath", "sb", case=False)
gm_regression_df = split_bathroom(gm_regression_df, column='bathrooms_text', text='bath', new_column='bathrooms_new')
gm_regression_df['shared_bath'] = gm_regression_df['shared_bath'].str.split(" ", expand=True)
gm_regression_df['private_bath'] = gm_regression_df['private_bath'].str.split(" ", expand=True)
gm_regression_df['bathrooms_new'] = gm_regression_df['bathrooms_new'].str.split(" ", expand=True)
# 填充缺失值为0
gm_regression_df = gm_regression_df.fillna(0)
gm_regression_df['shared_bath'] = gm_regression_df['shared_bath'].replace(to_replace='Shared', value=0.5)
gm_regression_df['private_bath'] = gm_regression_df['private_bath'].replace(to_replace='Private', value=0.5)
gm_regression_df['bathrooms_new'] = gm_regression_df['bathrooms_new'].replace(to_replace='Half-bath', value=0.5)
# 转成数值型
gm_regression_df['shared_bath'] = pd.to_numeric(gm_regression_df['shared_bath']).astype(int)
gm_regression_df['private_bath'] = pd.to_numeric(gm_regression_df['private_bath']).astype(int)
gm_regression_df['bathrooms_new'] = pd.to_numeric(gm_regression_df['bathrooms_new']).astype(int)
# 查看处理后的字段
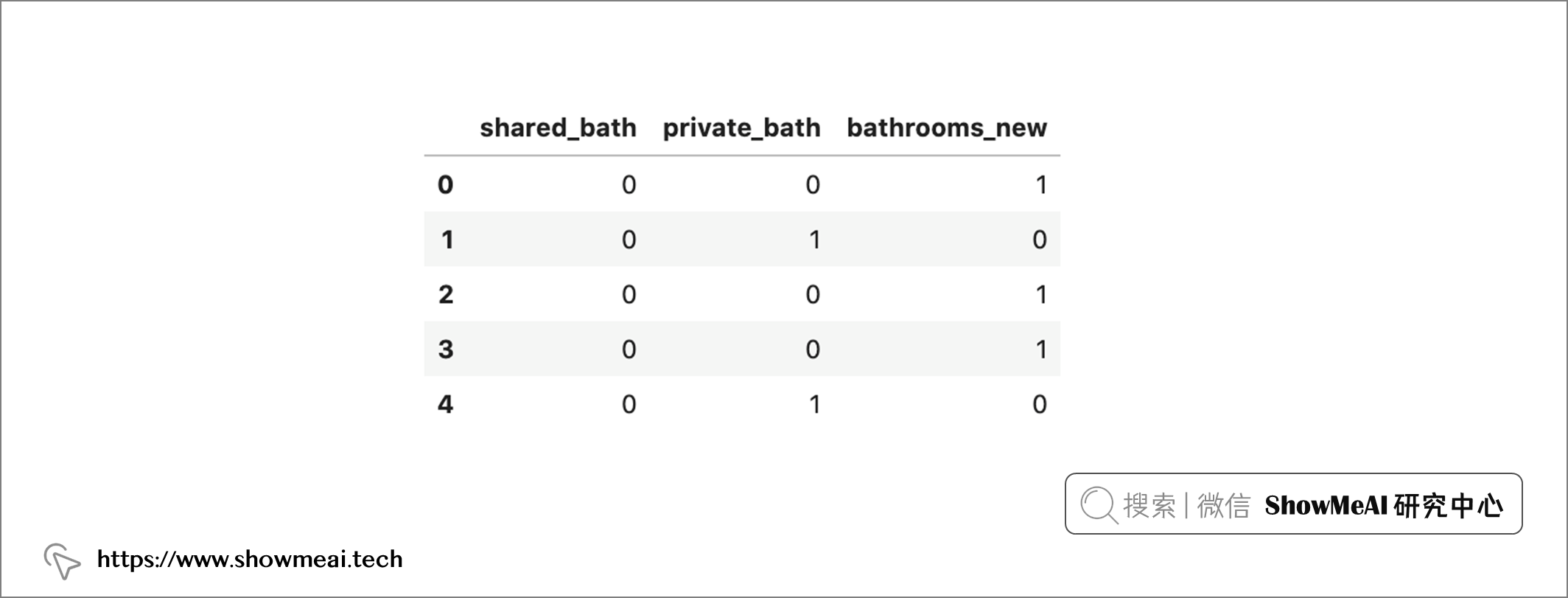
gm_regression_df[['shared_bath', 'private_bath', 'bathrooms_new']].head()
下面我们对类别型字段进行编码,根据字段含义的不同,我们使用「序号编码」和「独热向量编码」等方法来完成。
# 序号编码
def encoder(df):
for column in df[['neighbourhood_group_cleansed', 'property_type']].columns:
labels = df[column].astype('category').cat.categories.tolist()
replace_map = {column : {k: v for k,v in zip(labels,list(range(1,len(labels)+1)))}}
df.replace(replace_map, inplace=True)
print(replace_map)
return df
gm_regression_df = encoder(gm_regression_df)
我们对于host_response_time和room_type字段,使用独热向量编码(哑变量变换)
host_dummy = pd.get_dummies(gm_regression_df['host_response_time'], prefix='host_response')
room_dummy = pd.get_dummies(gm_regression_df['room_type'], prefix='room_type')
# 拼接编码后的字段
gm_regression_df = pd.concat([gm_regression_df, host_dummy, room_dummy], axis=1)
# 剔除原始字段
gm_regression_df = gm_regression_df.drop(columns=['host_response_time', 'room_type'], axis=1)
我们再把之前处理过的df_amenities做一点处理,再拼接到数据特征里
df_3 = pd.DataFrame(df_amenities.sum())
features = df_3['amenities'][:150].to_list()
amenities_updated = df_amenities.filter(items=(features))
gm_regression_df = pd.concat([gm_regression_df, amenities_updated], axis=1)
查看一下最终数据的维度
gm_regression_df.shape
# (3584, 198)
我们最后得到了198个字段,为了避免特征之间的多重共线性,使用方差因子法(VIF)来选择机器学习模型的特征。 VIF 大于 10 的特征被删除,因为这些特征的方差可以由数据集中的其他特征表示和解释。
# 计算VIF
vif_model = gm_regression_df.drop(['price'], axis=1)
vif_df = pd.DataFrame()
vif_df['feature'] = vif_model.columns
vif_df['VIF'] = [variance_inflation_factor(vif_model.values, i) for i in range(len(vif_model.columns))]
# 选出小于10的特征
vif_df_new = vif_df[vif_df['VIF']<=10]
feature_list = vif_df_new['feature'].to_list()
# 选出这些特征对应的数据
model_df = gm_regression_df.filter(items=(feature_list))
model_df.head()
我们拼接上price目标标签字段,可以构建完整的数据集
price_col = gm_regression_df['price']
model_df = model_df.join(price_col)
机器学习算法
我们在这里使用几个典型的回归算法,包括线性回归、RandomForestRegression、Lasso Regression 和 GradientBoostingRegression。
关于机器学习算法的应用方法,欢迎大家查阅ShowMeAI对应的教程与文章,快学快用。
线性回归建模
def linear_reg(df, test_size=0.3, random_state=42):
'''
构建模型并返回评估结果
输入: 数据dataframe
输出: 特征重要度与评估准则(RMSE与R-squared)
'''
X = df.drop(columns=['price'])
y = df[['price']]
X_columns = X.columns
# 切分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = test_size, random_state=random_state)
# 线性回归分类器
clf = LinearRegression()
# 候选参数列表
parameters = {
'n_jobs': [1, 2, 5, 10, 100],
'fit_intercept': [True, False]
}
# 网格搜索交叉验证调参
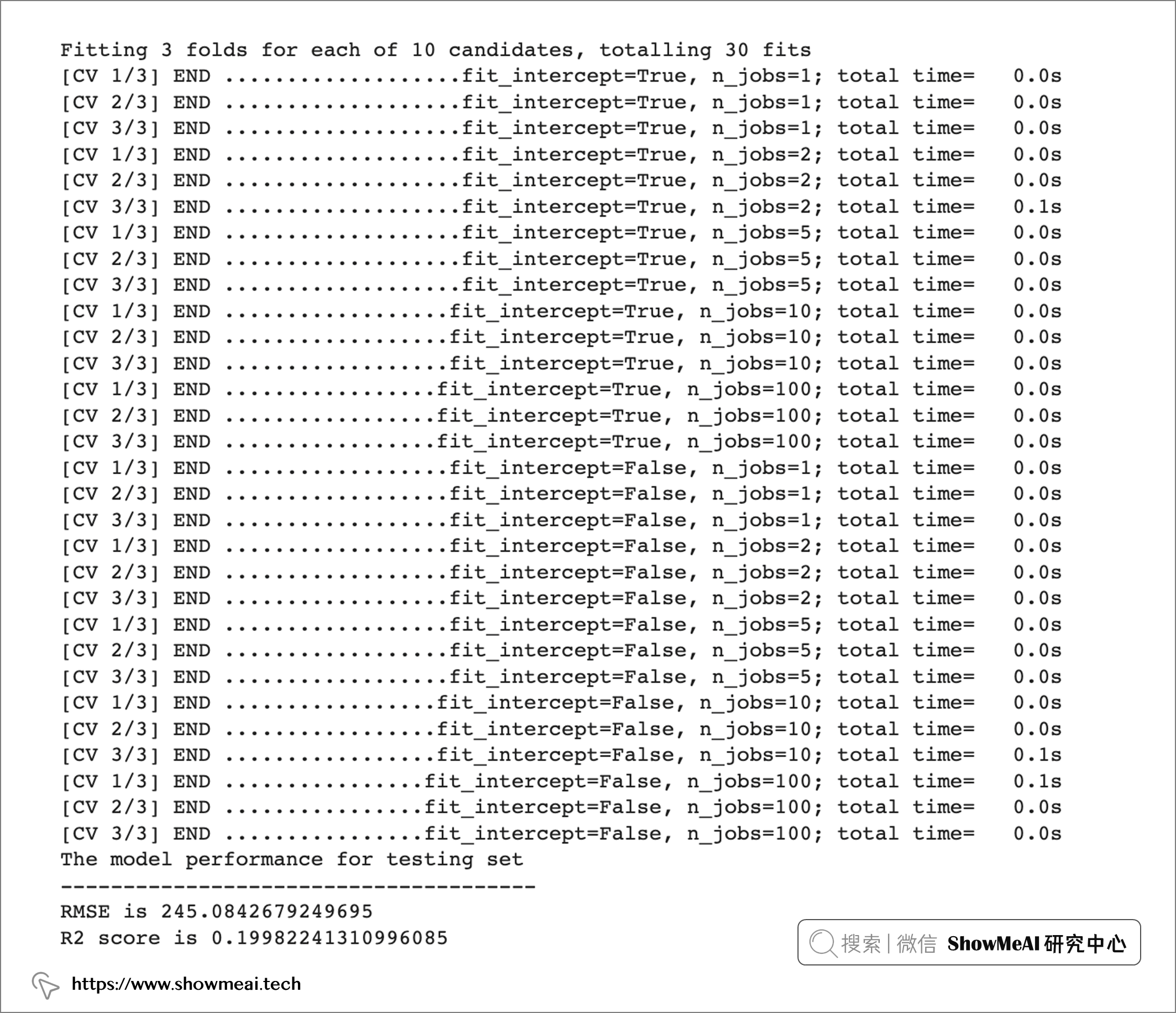
cv = GridSearchCV(estimator=clf, param_grid=parameters, cv=3, verbose=3)
cv.fit(X_train,y_train)
# 测试集预估
pred = cv.predict(X_test)
# 模型评估
r2 = r2_score(y_test, pred)
mse = mean_squared_error(y_test, pred)
rmse = mse **.5
# 最佳参数
best_par = cv.best_params_
coefficients = cv.best_estimator_.coef_
#特征重要度
importance = np.abs(coefficients)
feature_importance = pd.DataFrame(importance, columns=X_columns).T
#feature_importance = feature_importance.T
feature_importance.columns = ['importance']
feature_importance = feature_importance.sort_values('importance', ascending=False)
print("The model performance for testing set")
print("--------------------------------------")
print('RMSE is {}'.format(rmse))
print('R2 score is {}'.format(r2))
print("\n")
return feature_importance, rmse, r2
linear_feat_importance, linear_rmse, linear_r2 = linear_reg(model_df)
随机森林建模
# 随机森林建模
def random_forest(df):
'''
构建模型并返回评估结果
输入: 数据dataframe
输出: 特征重要度与评估准则(RMSE与R-squared)
'''
X = df.drop(['price'], axis=1)
X_columns = X.columns
y = df['price']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# 随机森林模型
clf = RandomForestRegressor()
# 候选参数
parameters = {
'n_estimators': [50, 100, 200, 300, 400],
'max_depth': [2, 3, 4, 5],
'max_depth': [80, 90, 100]
}
# 网格搜索交叉验证调参
cv = GridSearchCV(estimator=clf, param_grid=parameters, cv=5, verbose=3)
model = cv
model.fit(X_train, y_train)
# 测试集预估
pred = model.predict(X_test)
# 模型评估
mse = mean_squared_error(y_test, pred)
rmse = mse**.5
r2 = r2_score(y_test, pred)
# 最佳超参数
best_par = model.best_params_
# 特征重要度
r = permutation_importance(model, X_test, y_test,
n_repeats=10,
random_state=0)
perm = pd.DataFrame(columns=['AVG_Importance'], index=[i for i in X_train.columns])
perm['AVG_Importance'] = r.importances_mean
perm = perm.sort_values(by='AVG_Importance', ascending=False);
return rmse, r2, best_par, perm
# 运行建模
r_forest_rmse, r_forest_r2, r_fores_best_params, r_forest_importance = random_forest(model_df)
运行结果如下
Fitting 5 folds for each of 15 candidates, totalling 75 fits
[CV 1/5] END ..................max_depth=80, n_estimators=50; total time= 2.4s
[CV 2/5] END ..................max_depth=80, n_estimators=50; total time= 1.9s
[CV 3/5] END ..................max_depth=80, n_estimators=50; total time= 1.9s
[CV 4/5] END ..................max_depth=80, n_estimators=50; total time= 1.9s
[CV 5/5] END ..................max_depth=80, n_estimators=50; total time= 1.9s
[CV 1/5] END .................max_depth=80, n_estimators=100; total time= 3.8s
[CV 2/5] END .................max_depth=80, n_estimators=100; total time= 3.8s
[CV 3/5] END .................max_depth=80, n_estimators=100; total time= 3.9s
[CV 4/5] END .................max_depth=80, n_estimators=100; total time= 3.8s
[CV 5/5] END .................max_depth=80, n_estimators=100; total time= 3.8s
[CV 1/5] END .................max_depth=80, n_estimators=200; total time= 7.5s
[CV 2/5] END .................max_depth=80, n_estimators=200; total time= 7.7s
[CV 3/5] END .................max_depth=80, n_estimators=200; total time= 7.7s
[CV 4/5] END .................max_depth=80, n_estimators=200; total time= 7.6s
[CV 5/5] END .................max_depth=80, n_estimators=200; total time= 7.6s
[CV 1/5] END .................max_depth=80, n_estimators=300; total time= 11.3s
[CV 2/5] END .................max_depth=80, n_estimators=300; total time= 11.4s
[CV 3/5] END .................max_depth=80, n_estimators=300; total time= 11.7s
[CV 4/5] END .................max_depth=80, n_estimators=300; total time= 11.4s
[CV 5/5] END .................max_depth=80, n_estimators=300; total time= 11.4s
[CV 1/5] END .................max_depth=80, n_estimators=400; total time= 15.1s
[CV 2/5] END .................max_depth=80, n_estimators=400; total time= 16.4s
[CV 3/5] END .................max_depth=80, n_estimators=400; total time= 15.6s
[CV 4/5] END .................max_depth=80, n_estimators=400; total time= 15.2s
[CV 5/5] END .................max_depth=80, n_estimators=400; total time= 15.6s
[CV 1/5] END ..................max_depth=90, n_estimators=50; total time= 1.9s
[CV 2/5] END ..................max_depth=90, n_estimators=50; total time= 1.9s
[CV 3/5] END ..................max_depth=90, n_estimators=50; total time= 2.0s
[CV 4/5] END ..................max_depth=90, n_estimators=50; total time= 2.0s
[CV 5/5] END ..................max_depth=90, n_estimators=50; total time= 2.0s
[CV 1/5] END .................max_depth=90, n_estimators=100; total time= 3.9s
[CV 2/5] END .................max_depth=90, n_estimators=100; total time= 3.9s
[CV 3/5] END .................max_depth=90, n_estimators=100; total time= 4.0s
[CV 4/5] END .................max_depth=90, n_estimators=100; total time= 3.9s
[CV 5/5] END .................max_depth=90, n_estimators=100; total time= 3.9s
[CV 1/5] END .................max_depth=90, n_estimators=200; total time= 8.7s
[CV 2/5] END .................max_depth=90, n_estimators=200; total time= 8.1s
[CV 3/5] END .................max_depth=90, n_estimators=200; total time= 8.1s
[CV 4/5] END .................max_depth=90, n_estimators=200; total time= 7.7s
[CV 5/5] END .................max_depth=90, n_estimators=200; total time= 8.0s
[CV 1/5] END .................max_depth=90, n_estimators=300; total time= 11.6s
[CV 2/5] END .................max_depth=90, n_estimators=300; total time= 11.8s
[CV 3/5] END .................max_depth=90, n_estimators=300; total time= 12.2s
[CV 4/5] END .................max_depth=90, n_estimators=300; total time= 12.0s
[CV 5/5] END .................max_depth=90, n_estimators=300; total time= 13.2s
[CV 1/5] END .................max_depth=90, n_estimators=400; total time= 15.6s
[CV 2/5] END .................max_depth=90, n_estimators=400; total time= 15.9s
[CV 3/5] END .................max_depth=90, n_estimators=400; total time= 16.1s
[CV 4/5] END .................max_depth=90, n_estimators=400; total time= 15.7s
[CV 5/5] END .................max_depth=90, n_estimators=400; total time= 15.8s
[CV 1/5] END .................max_depth=100, n_estimators=50; total time= 1.9s
[CV 2/5] END .................max_depth=100, n_estimators=50; total time= 2.0s
[CV 3/5] END .................max_depth=100, n_estimators=50; total time= 2.0s
[CV 4/5] END .................max_depth=100, n_estimators=50; total time= 2.0s
[CV 5/5] END .................max_depth=100, n_estimators=50; total time= 2.0s
[CV 1/5] END ................max_depth=100, n_estimators=100; total time= 4.0s
[CV 2/5] END ................max_depth=100, n_estimators=100; total time= 4.0s
[CV 3/5] END ................max_depth=100, n_estimators=100; total time= 4.1s
[CV 4/5] END ................max_depth=100, n_estimators=100; total time= 4.0s
[CV 5/5] END ................max_depth=100, n_estimators=100; total time= 4.0s
[CV 1/5] END ................max_depth=100, n_estimators=200; total time= 7.8s
[CV 2/5] END ................max_depth=100, n_estimators=200; total time= 7.9s
[CV 3/5] END ................max_depth=100, n_estimators=200; total time= 8.1s
[CV 4/5] END ................max_depth=100, n_estimators=200; total time= 7.9s
[CV 5/5] END ................max_depth=100, n_estimators=200; total time= 7.8s
[CV 1/5] END ................max_depth=100, n_estimators=300; total time= 11.8s
[CV 2/5] END ................max_depth=100, n_estimators=300; total time= 12.0s
[CV 3/5] END ................max_depth=100, n_estimators=300; total time= 12.8s
[CV 4/5] END ................max_depth=100, n_estimators=300; total time= 11.4s
[CV 5/5] END ................max_depth=100, n_estimators=300; total time= 11.5s
[CV 1/5] END ................max_depth=100, n_estimators=400; total time= 15.1s
[CV 2/5] END ................max_depth=100, n_estimators=400; total time= 15.3s
[CV 3/5] END ................max_depth=100, n_estimators=400; total time= 15.6s
[CV 4/5] END ................max_depth=100, n_estimators=400; total time= 15.3s
[CV 5/5] END ................max_depth=100, n_estimators=400; total time= 15.3s
随机森林最后的结果如下
r_forest_rmse, r_forest_r2
# (218.7941962807868, 0.4208644494689676)
GBDT建模
def GBDT_model(df):
'''
构建模型并返回评估结果
输入: 数据dataframe
输出: 特征重要度与评估准则(RMSE与R-squared)
'''
X = df.drop(['price'], axis=1)
Y = df['price']
X_columns = X.columns
X_train, X_test, y_train, y_test = train_test_split(X, Y, random_state=42)
clf = GradientBoostingRegressor()
parameters = {
'learning_rate': [0.1, 0.5, 1],
'min_samples_leaf': [10, 20, 40 , 60]
}
cv = GridSearchCV(estimator=clf, param_grid=parameters, cv=5, verbose=3)
model = cv
model.fit(X_train, y_train)
pred = model.predict(X_test)
r2 = r2_score(y_test, pred)
mse = mean_squared_error(y_test, pred)
rmse = mse**.5
coefficients = model.best_estimator_.feature_importances_
importance = np.abs(coefficients)
feature_importance = pd.DataFrame(importance, index= X_columns,
columns=['importance']).sort_values('importance', ascending=False)[:10]
return r2, mse, rmse, feature_importance
GBDT_r2, GBDT_mse, GBDT_rmse, GBDT_feature_importance = GBDT_model(model_df)
GBDT_r2, GBDT_rmse
# (0.46352992147034244, 210.58063809645563)
结果&分析
目前随机森林的表现最稳定,而集成模型GradientBoostingRegression 的R²很高,RMSE 值也偏高,Boosting的模型受异常值影响很大,这可能是因为数据集中的异常值引起的。
下面我们来做一下优化,删除数据集中的异常值,看看是否可以提高模型性能。
效果优化
异常值在早些时候就已经被识别出来了,我们基于统计的方法来对其进行处理。
# 基于统计方法计算价格边界
q3, q1 = np.percentile(model_df['price'], [75, 25])
iqr = q3 - q1
q3 + (iqr*1.5)
# 得到结果245.0
我们把任何高于 245 美元的值都视为异常值并删除。
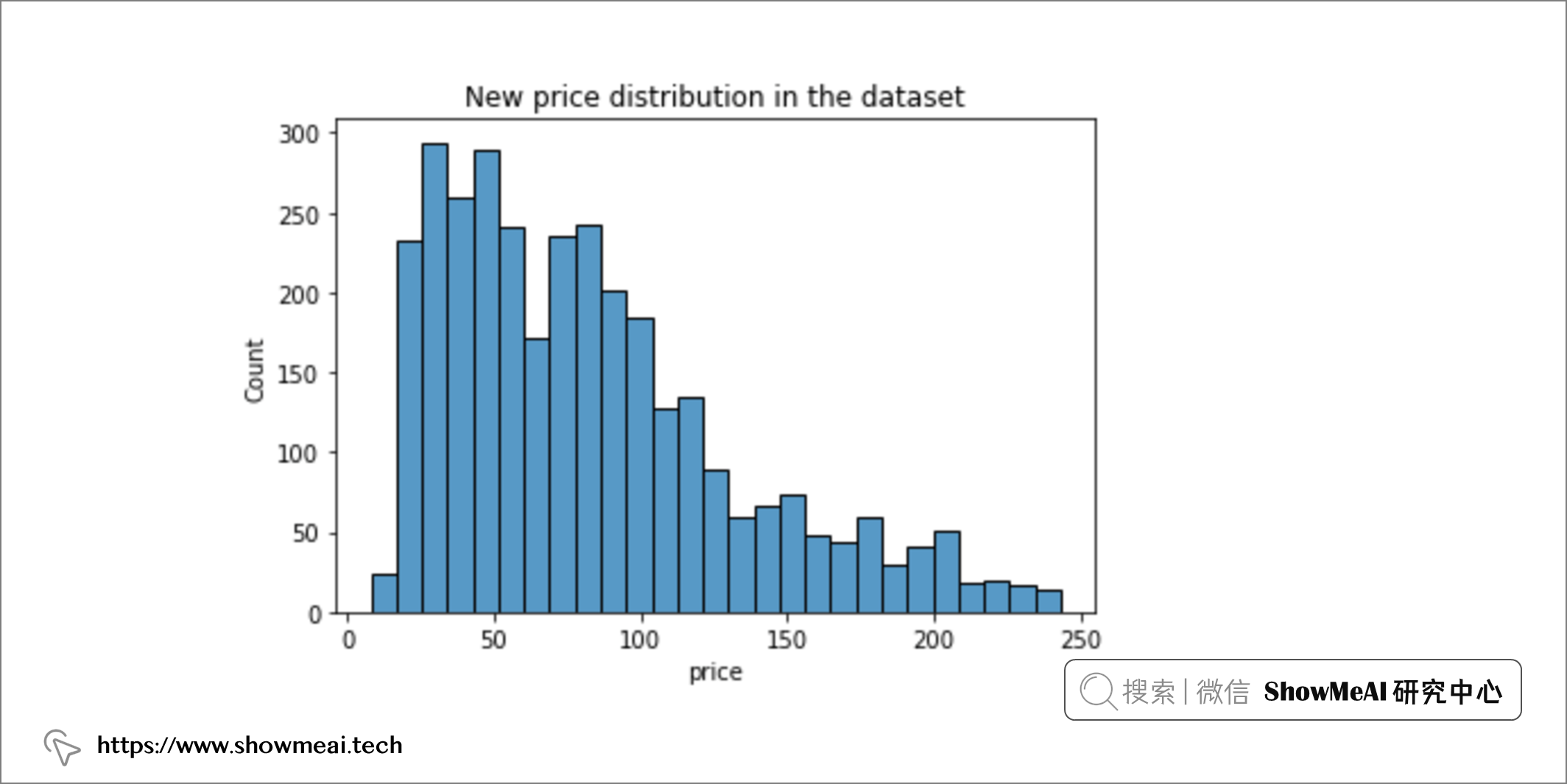
new_model_df = model_df[model_df['price']<245]
# 绘制此时的价格分布
sb.histplot(new_model_df['price'])
plt.title('New price distribution in the dataset')
重新运行这些算法
linear_feat_importance, linear_rmse, linear_r2 = linear_reg(new_model_df)
r_forest_rmse, r_forest_r2, r_fores_best_params, r_forest_importance = random_forest(new_model_df)
GBDT_r2, GBDT_mse, GBDT_rmse, GBDT_feature_importance = GBDTboost(new_model_df)
得到的新结果如下

归因分析
那么,基于我们的模型来分析,在预测大曼彻斯特地区 Airbnb 房源的价格时,哪些因素更重要?
r_feature_importance = r_forest_importance.reset_index()
r_feature_importance = r_feature_importance.rename(columns={'index':'Feature'})
r_feature_importance[:15]
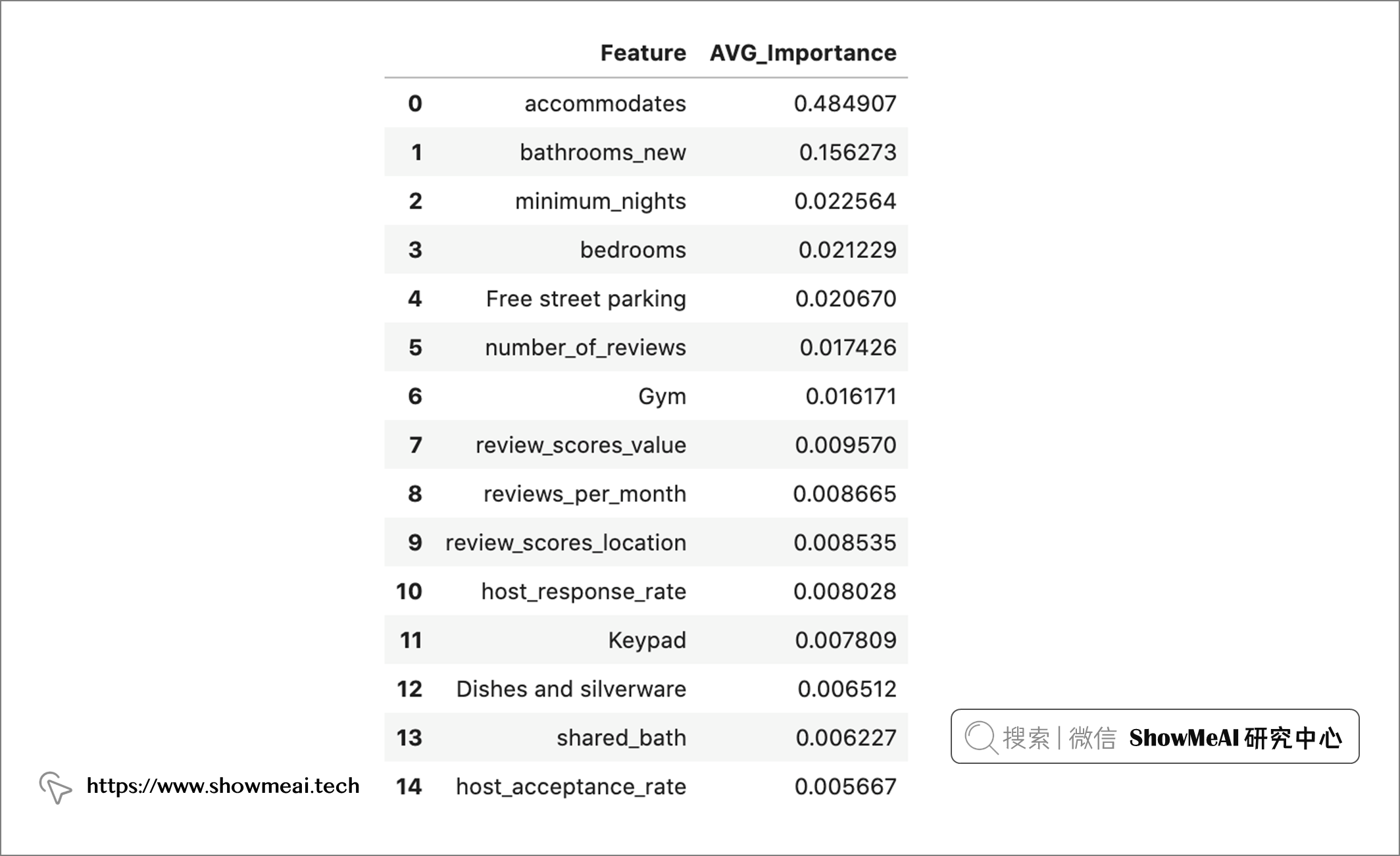
# 绘制最重要的15个因素
r_feature_importance[:15].sort_values(by='AVG_Importance').plot(kind='barh', x='Feature', y='AVG_Importance', figsize=(8,6));
plt.title('Top 15 Most Imporatant Features');

我们的模型给出的重要因素包括:
- accommodates :可以容纳的最大人数。
- bathrooms_new :非共用或非私人浴室的数量。
- minimum_nights :房源可预定的最少晚数。
- number_of_reviews :总评论数。
- Free street parking :免费路边停车位的存在是影响模型定价的最重要的便利设施。
- Gym :健身房设施。
总结&展望

我们通过对Airbnb的数据进行深入挖掘分析和建模,完成对于民宿租赁场景下的AI理解与建模预估。我们后续还有一些可以做的事情,提升模型的表现,完成更精准地预估,比如:
- 更完善的特征工程,结合业务场景构建更有效的业务特征。
- 使用xgboost、lightgbm、catboost等模型。
- 使用贝叶斯调参等方法对超参数做更深入的调优。
- 深度学习与神经网络的方法引入。
参考资料
- 数据科学工具库速查表 | Pandas 速查表:https://www.showmeai.tech/article-detail/101
- 图解数据分析:从入门到精通系列教程:https://www.showmeai.tech/tutorials/33
- 机器学习实战:手把手教你玩转机器学习系列:https://www.showmeai.tech/tutorials/41
- 机器学习实战 | SKLearn入门与简单应用案例:https://www.showmeai.tech/article-detail/202
- 机器学习实战 | SKLearn最全应用指南:https://www.showmeai.tech/article-detail/203
- 机器学习实战 | 机器学习特征工程最全解读:https://www.showmeai.tech/article-detail/208
AI带你省钱旅游!精准预测民宿房源价格!的更多相关文章
- 微服务从代码到k8s部署应有尽有系列(五、民宿服务)
我们用一个系列来讲解从需求到上线.从代码到k8s部署.从日志到监控等各个方面的微服务完整实践. 整个项目使用了go-zero开发的微服务,基本包含了go-zero以及相关go-zero作者开发的一些中 ...
- 【LOJ】#3101. 「JSOI2019」精准预测
LOJ#3101. 「JSOI2019」精准预测 设0是生,1是死,按2-sat连边那么第一种情况是\((t,x,1) \rightarrow (t + 1,y,1)\),\((t + 1,y, 0) ...
- [LOJ 3101] [Luogu 5332] [JSOI2019]精准预测(2-SAT+拓扑排序+bitset)
[LOJ 3101] [Luogu 5332] [JSOI2019]精准预测(2-SAT+拓扑排序+bitset) 题面 题面较长,略 分析 首先,发现火星人只有死和活两种状态,考虑2-SAT 建图 ...
- 【JSOI2019】精准预测(2-SAT & bitset)
Description 现有一台预测机,可以预测当前 \(n\) 个人在 \(T\) 个时刻内的生死关系.关系有两种: \(\texttt{0 t x y}\):如果 \(t\) 时刻 \(x\) 死 ...
- 马上AI全球挑战者大赛-违约用户风险预测
方案概述 近年来,互联网金融已经是当今社会上的一个金融发展趋势.在金融领域,无论是投资理财还是借贷放款,风险控制永远是业务的核心基础.对于消费金融来说,其主要服务对象的特点是:额度小.人群大.周期短, ...
- 利用keras自带房价数据集进行房价预测
import numpy as np from keras.datasets import boston_housing from keras import layers from keras imp ...
- Airbnb新用户的民宿预定结果预测
1. 背景 关于这个数据集,在这个挑战中,您将获得一个用户列表以及他们的人口统计数据.web会话记录和一些汇总统计信息.您被要求预测新用户的第一个预订目的地将是哪个国家.这个数据集中的所有用户都来自美 ...
- [JSOI2019]精准预测
题目 这么明显的限制条件显然是\(\text{2-sat}\) 考虑按照时间拆点,\((0/1,x,t)\)表示\(x\)个人在时间\(t\)是生/死 有一些显然的连边 \[(0,x,t+1)-> ...
- [JSOI2019]精准预测(2-SAT+拓扑排序+bitset)
设第i个人在t时刻生/死为(x,0/1,t),然后显然能够连上(x,0,t)->(x,0,t-1),(x,1,t)->(x,1,t+1),然后对于每个限制,用朴素的2-SAT连边即可. 但 ...
随机推荐
- FormData 和表单元素(form)的区别
Form 元素 <form>元素表示文档中的一个区域,此区域包含交互控件,用于向 Web 服务器提交信息(文件.字符).下面称之为表单元素或表单. 要向 Web 服务器提交信息,我们必须要 ...
- 来开源吧!发布开源组件到 MavenCentral 仓库超详细攻略
请点赞关注,你的支持对我意义重大. Hi,我是小彭.本文已收录到 GitHub · AndroidFamily 中.这里有 Android 进阶成长知识体系,有志同道合的朋友,关注公众号 [彭旭锐] ...
- 刷题记录:Codeforces Round #731 (Div. 3)
Codeforces Round #731 (Div. 3) 20210803.网址:https://codeforces.com/contest/1547. 感觉这次犯的低级错误有亿点多-- A 一 ...
- ELK技术-Logstash
1.背景 1.1 简介 Logstash 是一个功能强大的工具,可与各种部署集成. 它提供了大量插件,可帮助业务做解析,丰富,转换和缓冲来自各种来源的数据. Logstash 是一个数据流引擎 它是用 ...
- .Net Core 配置文件读取 - IOptions、IOptionsMonitor、IOptionsSnapshot
原文链接:https://www.cnblogs.com/ysmc/p/16637781.html 众所周知,appsetting.json 配置文件是.Net 的重大革新之心,抛开了以前繁杂的xml ...
- 二极管1N4148和1N4007的区别
二极管1N4148和1N4007的定义 1N4148 是开关二极管,耐压100V,电流150mA,反向恢复速度快,为nS级别. 1N4007 是普通整流二极管,耐压1000V,电流1A ,反向恢复时间 ...
- 一个注解解决ShardingJdbc不支持复杂SQL
背景介绍 公司最近做分库分表业务,接入了 Sharding JDBC,接入完成后,回归测试时发现好几个 SQL 执行报错,关键这几个表都还不是分片表.报错如下: 这下糟了嘛.熟悉 Sharding J ...
- DNS委派不生效
DNS委派不生效 近日,在公司内部的Windows DNS服务器上建立了一个新的区域,其中有两个子区域委派到其它的DNS服务器上.其中一个被委派的区域地址是公网. 建立了委派区域后客户端无法解析 ...
- Django 创建 APP和目录结构介绍
一.通过pip安装Django 以windows 系统中使用pip命令安装为例 win+r,调出cmd,运行命令:pip install django自动安装PyPi 提供的最新版本.指定版本,可使用 ...
- K8S Pod Pending 故障原因及解决方案
文章转载自:https://mp.weixin.qq.com/s/SBpnxLfMq4Ubsvg5WH89lA