Asynchronous Methods for Deep Reinforcement Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

ICML 2016
Abstract
我们提出了一个概念上简单且轻量级的深度强化学习框架,该框架使用异步梯度下降来优化深度神经网络控制器。我们提出了四种标准强化学习算法的异步变体,并表明并行参与者学习器对训练具有稳定作用,允许所有四种方法成功训练神经网络控制器。性能最佳的方法是actor-critic的异步变体,它超越了Atari领域的当前最先进技术,同时在单个多核CPU而不是GPU上训练了一半的时间。此外,我们展示了异步actor-critic在各种连续电机控制问题以及使用视觉输入导航随机3D迷宫的新任务上取得了成功。
1. Introduction
2. Related Work
3. Reinforcement Learning Background
4. Asynchronous RL Framework
我们现在介绍单步Sarsa、单步Q-learning、n步Q-learning和优势actor-critic的多线程异步变体。设计这些方法的目的是找到能够可靠地训练深度神经网络策略且无需大量资源的RL算法。虽然底层的RL方法完全不同,actor-critic是一种同策的策略搜索方法,而Q-learning是一种基于异策价值的方法,但鉴于我们的设计目标,我们使用两个主要思想来使所有四种算法都实用。
首先,我们使用异步actor学习者,类似于Gorila框架(Nair et al., 2015),但我们没有使用单独的机器和参数服务器,而是在单台机器上使用多个CPU线程。将学习器保持在一台机器上消除了发送梯度和参数的通信成本,并使我们能够使用Hogwild! (Recht et al., 2011)训练的风格更新。
其次,我们观察到并行运行的多个actor学习者可能正在探索环境的不同部分。此外,可以在每个actorx学习者中明确使用不同的探索策略来最大化这种多样性。通过在不同的线程中运行不同的探索策略,多个actor学习者并行应用在线更新对参数所做的整体更改可能比单个智能体应用在线更新在时间上的相关性更小。因此,我们不使用回放缓存,而是依靠采用不同探索策略的并行actor来执行DQN训练算法中经验回放所承担的稳定角色。
除了稳定学习之外,使用多个并行的actor学习者还具有多种实际好处。首先,我们获得了训练时间的减少,这与并行actor学习者的数量大致呈线性关系。其次,由于我们不再依赖经验回放来稳定学习,我们能够使用诸如Sarsa和actor-critic之类的策略强化学习方法以稳定的方式训练神经网络。我们现在描述我们的单步Q-learning、单步Sarsa、n步Q-learning和优势actor-critic的变体。
Asynchronous one-step Q-learning:
Asynchronous one-step Sarsa:
Asynchronous n-step Q-learning:
Asynchronous advantage actor-critic: 该算法,我们称之为异步优势actor-critic (A3C),维护一个策略π(at|st; θ)和价值函数的估计V(st; θv)。与我们的n步Q-learning变体一样,我们的actor-critic变体也在前向视图中运行,并使用相同的n步回报组合来更新策略和价值函数。策略和价值函数在每tmax个动作后或达到终端状态时更新。算法执行的更新可以看作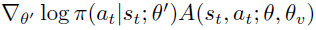 其中A(st, at, θ, θv)是由
其中A(st, at, θ, θv)是由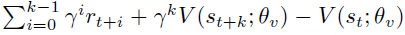 给出的对优势函数的估计,其中 k 可以因状态而异,其上限为tmax。该算法的伪代码在补充算法S3中给出。
给出的对优势函数的估计,其中 k 可以因状态而异,其上限为tmax。该算法的伪代码在补充算法S3中给出。
与基于价值的方法一样,我们依靠并行的actor学习者和累积更新来提高训练稳定性。请注意,虽然策略的参数和价值函数的 v 为一般性显示为分开的,但在实践中我们总是共享一些参数。我们通常使用卷积神经网络,该网络具有一个用于策略的 softmax 输出 (atjst; ) 和一个用于值函数 V (st; v) 的线性输出,所有非输出层共享。
我们还发现,将策略的熵添加到目标函数可以通过阻止过早收敛到次优确定性策略来改进探索。这种技术最初是由 (Williams & Peng, 1991) 提出的,他发现它对需要分层行为的任务特别有用。 包括熵正则化项关于策略参数的完整目标函数的梯度形式为 r 0 log (atjst; 0)(Rt V (st; v)) + r 0H( ( st; 0)),其中 H 是熵。 超参数控制熵正则化项的强度。
Optimization:
5. Experiments
Asynchronous Methods for Deep Reinforcement Learning的更多相关文章
- 论文笔记之:Asynchronous Methods for Deep Reinforcement Learning
Asynchronous Methods for Deep Reinforcement Learning ICML 2016 深度强化学习最近被人发现貌似不太稳定,有人提出很多改善的方法,这些方法有很 ...
- Asynchronous Methods for Deep Reinforcement Learning(A3C)
Mnih, Volodymyr, et al. "Asynchronous methods for deep reinforcement learning." Internatio ...
- (zhuan) Deep Reinforcement Learning Papers
Deep Reinforcement Learning Papers A list of recent papers regarding deep reinforcement learning. Th ...
- 【资料总结】| Deep Reinforcement Learning 深度强化学习
在机器学习中,我们经常会分类为有监督学习和无监督学习,但是尝尝会忽略一个重要的分支,强化学习.有监督学习和无监督学习非常好去区分,学习的目标,有无标签等都是区分标准.如果说监督学习的目标是预测,那么强 ...
- [DQN] What is Deep Reinforcement Learning
已经成为DL中专门的一派,高大上的样子 Intro: MIT 6.S191 Lecture 6: Deep Reinforcement Learning Course: CS 294: Deep Re ...
- 18 Issues in Current Deep Reinforcement Learning from ZhiHu
深度强化学习的18个关键问题 from: https://zhuanlan.zhihu.com/p/32153603 85 人赞了该文章 深度强化学习的问题在哪里?未来怎么走?哪些方面可以突破? 这两 ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- (转) Playing FPS games with deep reinforcement learning
Playing FPS games with deep reinforcement learning 博文转自:https://blog.acolyer.org/2016/11/23/playing- ...
- (转) Deep Reinforcement Learning: Playing a Racing Game
Byte Tank Posts Archive Deep Reinforcement Learning: Playing a Racing Game OCT 6TH, 2016 Agent playi ...
随机推荐
- KMP 算法中的 next 数组
KMP 算法中对 next 数组的理解 next 数组的意义 此处 next[j] = k:则有 k 前面的浅蓝色区域和 j 前面的浅蓝色区域相同: next[j] 表示当位置 j 的字符串与主串不匹 ...
- Nacos配置中心集群原理及源码分析
Nacos作为配置中心,必然需要保证服务节点的高可用性,那么Nacos是如何实现集群的呢? 下面这个图,表示Nacos集群的部署图. Nacos集群工作原理 Nacos作为配置中心的集群结构中,是一种 ...
- Java中的软引用、弱引用、虚引用的适用场景以及释放机制
Java的强引用,软引用,弱引用,虚引用及其使用场景 从 JDK1.2 版本开始,把对象的引用分为四种级别,从而使程序能更加灵活的控制对象的生命周期.这四种级别由高到低依次为:强引用.软引用.弱引 ...
- 解释AOP模块 ?
AOP模块用于发给我们的Spring应用做面向切面的开发, 很多支持由AOP联盟提供,这样就确保了Spring和其他AOP框架的共通性.这个模块将元数据编程引入Spring.
- 面试问题之C++语言:多态
什么是多态? 概念:同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果,这就是多态性.简单的说,就是用基类的引用指向子类的对象. 为什么要用多态呢? 原因:封装可以隐藏实现细节,使得代码模 ...
- Spring ModelAttribute注解失效原因
public String test(@RequestParam(value = "test") @ModelAttribute("test") String ...
- 学习Apache(一)
实验目的 通过apache实现反向代理的功能,类似nginx反向代理和haproxy反向代理 环境准备 逻辑架构如下 前端是apche服务器,监听80端口,后端有两台web服务器,分别是node1和n ...
- Python - time标准库使用与程序计时
- spi详解
来源:https://www.sohu.com/a/211324861_468626 1. SPI简介 SPI,是英语Serial Peripheral interface的缩写,顾名思义就是串行外围 ...
- 完美解决 scipy.misc.imread 报错 TypeError: Image data cannot be converted to float
File "/home/harrison/anaconda3/lib/python3.7/site-packages/matplotlib/image.py", line 634, ...