对比学习 ——simsiam 代码解析。
目录
写在前面的话 CSDN真的是'sb'中的'sb'软件, 辛辛苦苦写半天 我复制个东西过来 他就把前面的刷没了 还要我重头写????????????神经并b
------------------------------------------------------------------------------------------------------------------------------
2022李宏毅作业HW3 是食物的分类 ,但是我怎么尝试 再监督学习的模式下 准确率都达不到百分之60 .。半监督也感觉效果不明显。 所以 这次就想着对比学习能不能用来解决这个问题呢 。?看了一圈,感觉simsiam是对比学习里比较简单的一种方法,好像效果也不错。 所以来看一看这个东西是怎么玩的。
simsaim 是对比学习很新的文章了。 他的训练方式简单来说就是 ,一张图片 ,用不同的方式去增广后形成图片对 。 然后用一张去预测另一张。 不懂得可以看朱老师的视频。
1 : 事先准备 。
代码地址 : 好像不是官方的
下载解压。
直接在main函数的 运行 编辑配置中输入
--data_dir ../Data/ --log_dir ../logs/ -c configs/simsiam_cifar.yaml --ckpt_dir ~/.cache/ --hide_progress --download
os.environ['CUDA_VISIBLE_DEVICES']='0'
注意 : 第二次运行可以删掉download
2 : 代码阅读。
神经网络的一个基本的框架就是 : 数据读取 , 模型载入, 训练,测试。 我们接下来根据这四块来看。
2.1: 数据读取
运行main文件 。
main(device=args.device, args=args)
进入main 函数 。
是三个数据集的读取。
train_loader ,, memory_loader 和 test_loader。 train和memory 都是训练集的数据 他们的不同之处在于, 数据增广的方式不同。 train的增广是用来训练的 memory和test的增广都是用来测试的。由于在对比学习里, 数据增广是很重要的 ,所以这里看下数据增广的方式。
dataset=get_dataset(
transform=get_aug(train=True, **args.aug_kwargs),
train=True,
**args.dataset_kwargs),
**args.aug_kwargs 里规定了图片大小是32. 以及这次用的是simsaim。
这里两个train 。 只有训练集的第一个train是true。 而训练集的增广方式如下
class SimSiamTransform():
def __init__(self, image_size, mean_std=imagenet_mean_std):
image_size = 224 if image_size is None else image_size # by default simsiam use image size 224
p_blur = 0.5 if image_size > 32 else 0 # exclude cifar
# the paper didn't specify this, feel free to change this value
# I use the setting from simclr which is 50% chance applying the gaussian blur
# the 32 is prepared for cifar training where they disabled gaussian blur
self.transform = T.Compose([
T.RandomResizedCrop(image_size, scale=(0.2, 1.0)),
T.RandomHorizontalFlip(),
T.RandomApply([T.ColorJitter(0.4,0.4,0.4,0.1)], p=0.8),
T.RandomGrayscale(p=0.2),
T.RandomApply([T.GaussianBlur(kernel_size=image_size//20*2+1, sigma=(0.1, 2.0))], p=p_blur),
T.ToTensor(),
T.Normalize(*mean_std)
])
def __call__(self, x):
x1 = self.transform(x)
x2 = self.transform(x)
return x1, x2
增广方式可以参考 官网 Transforming and augmenting images — Torchvision 0.12 documentation
这里依次是 : 随机resize 然后剪切为输入大小, 也就是会随机取图片里的一块。
随机水平变换
0.8的概率调节亮度对比度和饱和度。
0.2概率灰度化
对于32的照片 不做高斯模糊。
转化为张量并标准化。
然后 对于一个输入 这里会做两次transform call可以让这个类像函数那样被调用。
对于 测试用的训练集 。也就是memory 是下面的增广方式。 而test也是下面的增广方式 。
else:
self.transform = transforms.Compose([
transforms.Resize(int(image_size*(8/7)), interpolation=Image.BICUBIC), # 224 -> 256
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize(*normalize)
])
如果输入是 224 就 先放大到256,然后中心裁剪224,之后标准化。
如果输入是32 就放大到36 再中心裁剪32 .后标准化。
用的是cifar10的数据。 其实也就相当于很普通的 读图片 然后增广, 加标签。
我们只要看getitem取出来的数据是什么就好 。
img, target = self.data[index], self.targets[index]
# doing this so that it is consistent with all other datasets
# to return a PIL Image
img = Image.fromarray(img)
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
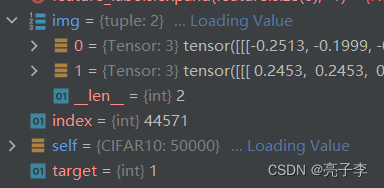 注意 如果是训练集 在trans时会返回两张图片 ,所以返回的是一个元组。 而测试时 ,img就是单独的一张图片。 target也就是标签。
注意 如果是训练集 在trans时会返回两张图片 ,所以返回的是一个元组。 而测试时 ,img就是单独的一张图片。 target也就是标签。
总结:数据部分 我们需要做一个数据集, 然后训练集的增广要返回两个结果。 当读取数据时,返回的是图片数据和标签数据。
2.2: 模型载入
这一部分我们来看模型 ,我们可以根据下面的伪代码来看模型长什么样子。 伪代码非常容易看懂。 aug就是增广嘛。 f来提特征,然后两个预测。 算loss 回传。

model = get_model(args.model).to(device)
这句来获得模型。
if model_cfg.name == 'simsiam':
model = SimSiam(get_backbone(model_cfg.backbone))
backbone就是普通的res18 这里不需要预训练的模型 只需要初始模型 。
class SimSiam(nn.Module):
def __init__(self, backbone=resnet50()):
super().__init__()
self.backbone = backbone
self.projector = projection_MLP(backbone.output_dim)
self.encoder = nn.Sequential( # f encoder
self.backbone,
self.projector
)
self.predictor = prediction_MLP()
def forward(self, x1, x2):
f, h = self.encoder, self.predictor
z1, z2 = f(x1), f(x2)
p1, p2 = h(z1), h(z2)
L = D(p1, z2) / 2 + D(p2, z1) / 2
return {'loss': L}
这个就是simsam的模型了 。 projector 是个三层的普通mlp 。 encoder 就是伪代码里的f了 而predictor就是伪代码里的h了 。 我们具体来看下loss 。
def D(p, z, version='simplified'): # negative cosine similarity
if version == 'original':
z = z.detach() # stop gradient
p = F.normalize(p, dim=1) # l2-normalize
z = F.normalize(z, dim=1) # l2-normalize
return -(p*z).sum(dim=1).mean()
elif version == 'simplified':# same thing, much faster. Scroll down, speed test in __main__
return - F.cosine_similarity(p, z.detach(), dim=-1).mean()
else:
raise Exception
传说 simsaim的精髓就在于这个loss, 在于这个z.detach 也就是传说中的stop gradiant。 有了这个梯度停止, simsaim才能够训练的起来。 这时的simsaim就和k-means算法有点类似了。 说法很多 大家可以搜搜看。
其实我们可以看出来一点东西,在算loss时, p是预测值, z是标签,如果标签也要算梯度,两边就都在变了,参考我们平时的label都是不变的,确实z也不应该算梯度。
那么什么是stop gradiant呢 就是不算梯度的意思。比如
x = 2
y = 2**2
z = y+x z.grad = 5 y.detach()
z.grad = 1
本来y是x的平方 求导等于4 所以z对x求导是5 然后不算y的梯度了 那么就只剩1了 。
这就是模型的全部了 ,输入两张图片 ,然后抽特征 预测 分别算loss
3 训练过程:
训练是非常普通的训练。
for idx, ((images1, images2), labels) in tqdm(enumerate(local_progress)):
model.zero_grad()
data_dict = model.forward(images1.to(device, non_blocking=True), images2.to(device, non_blocking=True))
loss = data_dict['loss'].mean() # ddp
loss.backward()
optimizer.step()
lr_scheduler.step()
data_dict.update({'lr':lr_scheduler.get_lr()})
local_progress.set_postfix(data_dict)
# logger.update_scalers(data_dict)
从测试集中抽loader 注意抽出的是两张图片 由不同transformers形成的。 之后过模型得到loss,梯度回传。 这里日志一直报错 我直接屏蔽了。
4 测试过程:
测试过程比较的关键。
这里是用knn算法进行测试的 ,关于knn 可以看 深入浅出KNN算法(一) KNN算法原理 - zzzzMing - 博客园。
简单的说, 就是从众。 在一个大平面上有很多的点, 然后你就看离自己最近的k个点,他们的标签是啥, 然后选最多的那个当自己的标签。
accuracy = knn_monitor(model.module.backbone, memory_loader, test_loader, device, k=min(args.train.knn_k, len(memory_loader.dataset)), hide_progress=args.hide_progress)
def knn_monitor(net, memory_data_loader, test_data_loader, epoch, k=200, t=0.1, hide_progress=False):
net.eval()
classes = len(memory_data_loader.dataset.classes)
total_top1, total_top5, total_num, feature_bank = 0.0, 0.0, 0, []
with torch.no_grad():
# generate feature bank
for data, target in tqdm(memory_data_loader, desc='Feature extracting', leave=False, disable=hide_progress):
feature = net(data.cuda(non_blocking=True))
feature = F.normalize(feature, dim=1)
feature_bank.append(feature)
# [D, N]
feature_bank = torch.cat(feature_bank, dim=0).t().contiguous()
# [N]
feature_labels = torch.tensor(memory_data_loader.dataset.targets, device=feature_bank.device)
# loop test data to predict the label by weighted knn search
test_bar = tqdm(test_data_loader, desc='kNN', disable=hide_progress)
for data, target in test_bar:
data, target = data.cuda(non_blocking=True), target.cuda(non_blocking=True)
feature = net(data)
feature = F.normalize(feature, dim=1)
pred_labels = knn_predict(feature, feature_bank, feature_labels, classes, k, t)
total_num += data.size(0)
total_top1 += (pred_labels[:, 0] == target).float().sum().item()
test_bar.set_postfix({'Accuracy':total_top1 / total_num * 100})
return total_top1 / total_num * 100
注意 这里的net 只是backbone 也就是resnet 而 memory 就是训练数据 不过增广方式不一样 。还有训练数据 和k值 取200.
net.eval()
classes = len(memory_data_loader.dataset.classes)
total_top1, total_top5, total_num, feature_bank = 0.0, 0.0, 0, []
一些初始化和获取类别数。
with torch.no_grad():
# generate feature bank
for data, target in tqdm(memory_data_loader, desc='Feature extracting', leave=False, disable=hide_progress):
feature = net(data.cuda(non_blocking=True))
feature = F.normalize(feature, dim=1)
feature_bank.append(feature)
# [D, N]
feature_bank = torch.cat(feature_bank, dim=0).t().contiguous()
feature_labels = torch.tensor(memory_data_loader.dataset.targets, device=feature_bank.device)
获取大平面上的点。 从训练集抽数据, 然后获取他们的特征。
最后的feature_bank大小是49664*512 也就是将近50000条数据 每个数据都有512 维的特征。 然后做了一个转置。
for data, target in test_bar:
data, target = data.cuda(non_blocking=True), target.cuda(non_blocking=True)
feature = net(data)
feature = F.normalize(feature, dim=1)
抽取测试集的特征。
pred_labels = knn_predict(feature, feature_bank, feature_labels, classes, k, t)
def knn_predict(feature, feature_bank, feature_labels, classes, knn_k, knn_t):
# compute cos similarity between each feature vector and feature bank ---> [B, N]
sim_matrix = torch.mm(feature, feature_bank)
# [B, K]
sim_weight, sim_indices = sim_matrix.topk(k=knn_k, dim=-1) #求出最大的knn_k个值
# [B, K]
sim_labels = torch.gather(feature_labels.expand(feature.size(0), -1), dim=-1, index=sim_indices)
sim_weight = (sim_weight / knn_t).exp()
# counts for each class
one_hot_label = torch.zeros(feature.size(0) * knn_k, classes, device=sim_labels.device)
# [B*K, C]
one_hot_label = one_hot_label.scatter(dim=-1, index=sim_labels.view(-1, 1), value=1.0)
# weighted score ---> [B, C]
pred_scores = torch.sum(one_hot_label.view(feature.size(0), -1, classes) * sim_weight.unsqueeze(dim=-1), dim=1)
pred_labels = pred_scores.argsort(dim=-1, descending=True)
return pred_labels
我们来看 knn是如果计算相似度的 ,也就是距离的。torch.mm表示矩阵的乘法。 我举个例子。
下面只是例子 ,真实数据需要归一化
a = [[1,2,3],
[4,5,6]]
b = [[1,2,3],
[2,4,6],
[3,6,9],
[4,8,1]]
a有2个样本, b有4个样本。 他们的特征都是3维。 现在求a[0] 和b中哪些样本最相似。
就要让a[0]和b中每一个样本点乘 得到 14, 28, 42, 23。数越大表示越相似,也就越近。 所以我们让a和b的转置相乘,得到:
tensor([[14, 28, 42, 23],
[32, 64, 96, 62]])
我们发现第一排 就是a[0]的相似度, 每一列都是与b中样本的点乘结果。
sim_matrix = torch.mm(feature, feature_bank)
所以这里的sim_matrix 就是一个512 * 49664大小的矩阵。 512 表示有512个样本, 49664 表示每个样本和所有点的乘积。
sim_weight, sim_indices = sim_matrix.topk(k=knn_k, dim=-1)
topk 表示取最大的值,和他们下标 这里取200个 我们就得到了离每一个样本,最近的那些点,他们的下标是多少。
sim_labels = torch.gather(feature_labels.expand(feature.size(0), -1), dim=-1, index=sim_indices)
feature_labels.expand(feature.size(0), -1) 之前的文章说过 ,是一个复制扩充。 -1表示不改变维度。 feature是50000维 扩充后变成512 *50000 (注意label和49664不相等,是因为loader舍弃了最后的一部分,但是没关系 , 本来就取不到这部分值)。
torch.gather 是按下标取值。
我们对标签按下标取值,得到了512 *200的矩阵, 每一行都表示这个样本距离最近的200个样本的标签。
sim_weight = (sim_weight / knn_t).exp()
看到后面就知道这个knn_t的作用了 。 作用就是 控制相似度的权重。 比如 一个更相似的 他的标签可以一个顶好几个不相似的。 那么顶几个呢 ? 就是t控制的了 。
# counts for each class
one_hot_label = torch.zeros(feature.size(0) * knn_k, classes, device=sim_labels.device)
# [B*K, C]
one_hot_label = one_hot_label.scatter(dim=-1, index=sim_labels.view(-1, 1), value=1.0)
我们需要先搞懂scatter函数 。说实话着实有点难。因为官网的scatter都很难理解了 ,何况这个和官网不一样
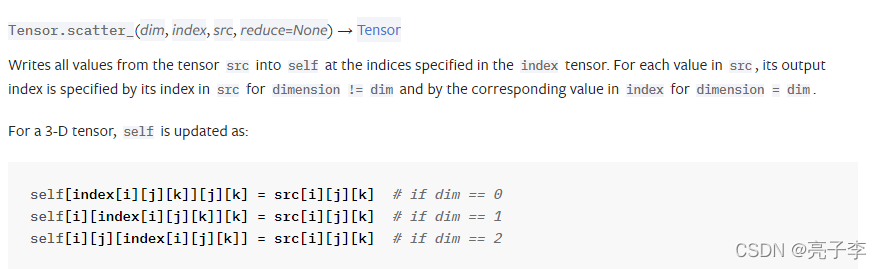
我们可以看到 官网的第三个参数是src 也就是数据源,而这里是value 。。。真是奇怪。
对于tensor.scatter函数 可以看 这篇
对于torch.tensor.scatter()这个函数的理解。_亮子李的博客-CSDN博客
相信大家对scatter 都有了理解。 我们回来。
这里先创建一个 长是512 *200 = 102400 宽是10的向量。
而sim_labels的大小是 (102400,1) 这个scatter做了什么呢 ? 如下
one_hot = torch.tensor
([[0,0,0,0,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,0]])
sim_label = torch.tensor([[3],[4]])
print(one_hot.scatter(-1,sim_label,value=1))
tensor([[0, 0, 0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0, 0, 0]])
也就是把每行标签对应得数字那一列变为1 ,如果这行特征得标签是1 就把第一个数变为1,这样子。 类似的有102400行。 得到onehot后 按我得想法, 就统计200行中哪一列的1最多呗。 比如前200行里 第3列的1对多, 就说明第一个样本最近的200个里,最多的标签是2 ,。我们看看他们怎么做的。
pred_scores = torch.sum(one_hot_label.view(feature.size(0), -1, classes) * sim_weight.unsqueeze(dim=-1), dim=1)
one_hot_label.view(feature.size(0), -1, classes)
这句可以理解。 变回512 *200*10 这样就可以统计各自的两百个了。
sim_weight.unsqueeze(dim=-1)
sim_weight 虽然在上面做了一点变换,但是我们其实不用管他,因为上面只是一种归一化的方式,我们依然可以把它看作最近 当前样本特征和两百个点特征的乘积。unsqueeze 表示扩充一维 在最后, sim_weight就变成了 512 *200 *1。 我们如何理解这个pred_score呢? 我们不要看512个样本。 我们只看一个样本。 对于一个样本。他的one_label是200*10 而sim_weight就是200 *1 特征的点乘结果,也就是200个相似度分数 。 从两行 看两百行 很显然 就是让各行的标签1 乘上那个相似度分数。 之后再对200这个维度求和,就得到了各个标签相似的分数的和。 维度1*10
c = one_hot.scatter(-1,sim_label,value=1)
d = torch.tensor([[3],[4]])
print(c*d)
#################
tensor([[0, 0, 0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0, 0, 0]])
tensor([[0, 0, 0, 3, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 4, 0, 0, 0, 0, 0]])
print(torch.sum(c*d,dim=0))
#########
tensor([0, 0, 0, 3, 4, 0, 0, 0, 0, 0])
看到这里我们明白了 。 这里的knn并不是简单的从众,他还要看影响力。 更相似的样本,他的标签对我们的结果的影响力更大。 这里相当于对标签做了一个加权求和。
回到512维 我们得到了512*10的矩阵 表示512个样本的各个标签的相似度分数 我们只要argsort就可以得到最大值的下标啦。 np.argsort这个函数可以对向量排序 然后返回他们原来的下标 des 表示可以降序。
pred_labels = pred_scores.argsort(dim=-1, descending=True)
return pred_labels
得到标签 , 回到原来的knn
total_num += data.size(0)
total_top1 += (pred_labels[:, 0] == target).float().sum().item()
test_bar.set_postfix({'Accuracy':total_top1 / total_num * 100})
return total_top1 / total_num * 100
这里是计算top1 我估计如果计算top5 估计就是 target in labels[:,4]了 得到预测标签后准确率久很好算了。
5 :线性验证
继续跟着主函数走 。 可以看到一堆保存的步骤。 然后进入linear_eval函数。 我猜测是用backbone抽特征然后直接预测结果的函数。
train_loader = torch.utils.data.DataLoader(
dataset=get_dataset(
transform=get_aug(train=False, train_classifier=True, **args.aug_kwargs),
train=True,
**args.dataset_kwargs
),
batch_size=args.eval.batch_size,
shuffle=True,
**args.dataloader_kwargs
)
test_loader = torch.utils.data.DataLoader(
dataset=get_dataset(
transform=get_aug(train=False, train_classifier=False, **args.aug_kwargs),
train=False,
**args.dataset_kwargs
),
batch_size=args.eval.batch_size,
shuffle=False,
**args.dataloader_kwargs
)
model = get_backbone(args.model.backbone)
classifier = nn.Linear(in_features=model.output_dim, out_features=10, bias=True).to(args.device)
先读取训练集和测试集, 然后 model是resnet 一个分类器是 一个全连接。 我好奇的是为什么不直接把backbone最后一层的恒等映射改为这个分类器呢 ?
msg = model.load_state_dict({k[9:]:v for k, v in save_dict['state_dict'].items() if k.startswith('backbone.')}, strict=True)
载入模型 
k长这个样子 取出那些以backb开头的层 就是resnet的层。 然后去掉前面9个字母 就是resnet的名字。
classifier = torch.nn.DataParallel(classifier)
# define optimizer
optimizer = get_optimizer(
args.eval.optimizer.name, classifier,
lr=args.eval.base_lr*args.eval.batch_size/256,
momentum=args.eval.optimizer.momentum,
weight_decay=args.eval.optimizer.weight_decay)
# define lr scheduler
lr_scheduler = LR_Scheduler(
optimizer,
args.eval.warmup_epochs, args.eval.warmup_lr*args.eval.batch_size/256,
args.eval.num_epochs, args.eval.base_lr*args.eval.batch_size/256, args.eval.final_lr*args.eval.batch_size/256,
len(train_loader),
)
loss_meter = AverageMeter(name='Loss')
acc_meter = AverageMeter(name='Accuracy')
定义优化器和loss 最下面这个averagemeter是啥呀
查了一下 就是一个类似于队列这种的 数据结构。 然后可以更新 关键是可以求平均。
for epoch in global_progress:
loss_meter.reset()
model.eval()
classifier.train()
local_progress = tqdm(train_loader, desc=f'Epoch {epoch}/{args.eval.num_epochs}', disable=True)
for idx, (images, labels) in enumerate(local_progress):
classifier.zero_grad()
with torch.no_grad():
feature = model(images.to(args.device))
preds = classifier(feature)
loss = F.cross_entropy(preds, labels.to(args.device))
loss.backward()
optimizer.step()
loss_meter.update(loss.item())
lr = lr_scheduler.step()
local_progress.set_postfix({'lr':lr, "loss":loss_meter.val, 'loss_avg':loss_meter.avg})
然后定义好后 就是一个普通的训练过程了 。 值得注意的是 model是eval模型 也就是他是冻住的,参数不改变。而classfier是可以改变的, 梯度回传也只回传分类头的梯度, 这里就只训练分类器。
classifier.eval()
correct, total = 0, 0
acc_meter.reset()
for idx, (images, labels) in enumerate(test_loader):
with torch.no_grad():
feature = model(images.to(args.device))
preds = classifier(feature).argmax(dim=1)
correct = (preds == labels.to(args.device)).sum().item()
acc_meter.update(correct/preds.shape[0])
print(f'Accuracy = {acc_meter.avg*100:.2f}')
普通的测试。
6 : 用自己数据集进行对比学习。
路走远了,别忘了开始的方向。 我们是用对比学习解决食物分类的问题的。
我们要做的有几件事情。
第一: 改数据集 :
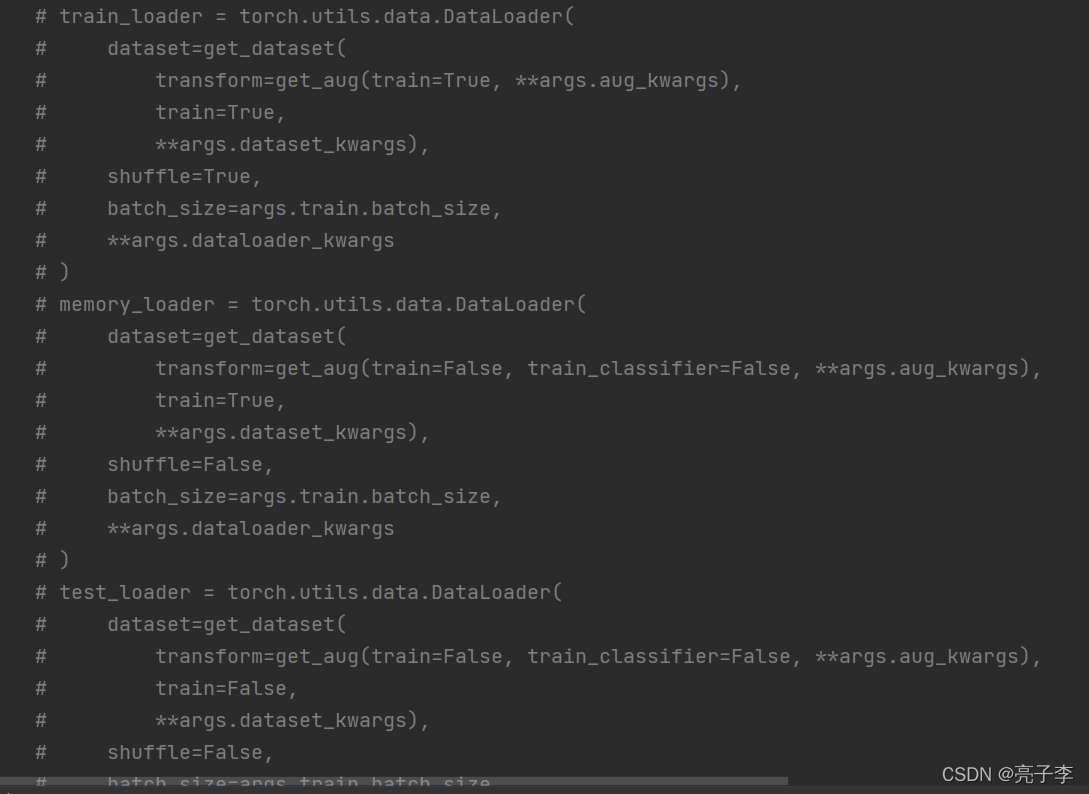
把它原来的三个数据集全#了。
然后 加入自己的数据集。 使用他的增广方式。 但在增广前 需要在 dataset的get里加 topil 因为他的增广里没有这个。
hw3食物分类有三个数据集:
一个有标签训练集 我用来当memory
一个无标签训练集 我用来当train
一个验证集 我用来测试。
pil_trans = transforms.ToPILImage()
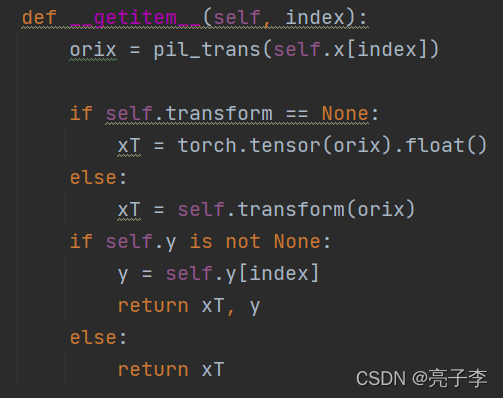
filepath = '/home/lhy/hw3/food-11'
train_loader = getDataLoader(filepath, 'train_unl', True, args.train.batch_size, transform=get_aug(train=True, train_classifier=False, **args.aug_kwargs))
memory_loader = getDataLoader(filepath, 'train', False,args.train.batch_size, transform=get_aug(train=False, train_classifier=False, **args.aug_kwargs))
test_loader = getDataLoader(filepath, 'val', False,args.train.batch_size, transform=get_aug(train=False, train_classifier=False, **args.aug_kwargs))
2 改变batch_size和图片大小。
在这个文件里改batch 你会发现这个对比学习的模型 出奇的占内存,当我图片大小为224时,我的batch只能设置为32.
main函数里改imagesize 为自己的。
点运行。O了 。 然后发现效果并不是很好。。。。。
对比学习 ——simsiam 代码解析。的更多相关文章
- 突破瓶颈,对比学习:Eclipse开发环境与VS开发环境的调试对比
曾经看了不少Java和Android的相关知识,不过光看不练易失忆,所以,还是写点文字,除了加强下记忆,也证明我曾经学过~~~ 突破瓶颈,对比学习: 学习一门语言,开发环境很重,对于VS的方形线条开发 ...
- Java程序员学C#基本语法两个小时搞定(对比学习)
对于学习一门新的语言,关键是学习新语言和以前掌握的语言的区别,但是也不要让以前语言的东西,固定了自己的思维模式,多看一下新的语言的编程思想. 1.引包 using System;java用import ...
- # nodejs模块学习: express 解析
# nodejs模块学习: express 解析 nodejs 发展很快,从 npm 上面的包托管数量就可以看出来.不过从另一方面来看,也是反映了 nodejs 的基础不稳固,需要开发者创造大量的轮子 ...
- git 学习(3) ----- 代码共享和多人协作
当我们开发项目的时候,项目会越来越大,就有可能需要其它同事进行参与,甚至进行开源,这时就需要找一个地方把代码存放起来,好供其它人下载并开发.这个地方,最好放到服务器上,因为只要能上网,就可以获取到, ...
- [转] Java程序员学C#基本语法两个小时搞定(对比学习)
Java程序员学C#基本语法两个小时搞定(对比学习) 对于学习一门新的语言,关键是学习新语言和以前掌握的语言的区别,但是也不要让以前语言的东西,固定了自己的思维模式,多看一下新的语言的编程思想. ...
- day89 DjangoRsetFramework学习---restful规范,解析器组件,Postman等
DjangoRsetFramework学习---restful规范,解析器组件,Postman等 本节目录 一 预备知识 二 restful规范 三 DRF的APIView和解析 ...
- CSS学习之float解析
转自:http://www.w3cplus.com/css/float.html 一.float是什么? float即为浮动,在CSS中的作用是使元素脱离正常的文档流并使其移动到其父元素的“最左边”或 ...
- 笔记-爬虫-js代码解析
笔记-爬虫-js代码解析 1. js代码解析 1.1. 前言 在爬取网站时经常会有js生成关键信息,而且js代码是混淆过的. 以瓜子二手车为例,直接请求https://www.guaz ...
- 【论文笔记】AutoML for MCA on Mobile Devices——论文解读与代码解析
理论部分 方法介绍 本节将详细介绍AMC的算法流程.AMC旨在自动地找出每层的冗余参数. AMC训练一个强化学习的策略,对每个卷积层会给出其action(即压缩率),然后根据压缩率进行裁枝.裁枝后,A ...
随机推荐
- Linux下使用Google Authenticator配置SSH登录动态验证码
1.一般ssh登录服务器,只需要输入账号和密码.2.本教程的目的:在账号和密码之间再增加一个验证码,只有输入正确的验证码之后,再输入密码才能登录.这样就增强了ssh登录的安全性.3.账号.验证码.密码 ...
- springboot自定义启动图画
小小娱乐,你是不是看到好多文章或段子上有这个 是不是很好玩,其实修改也很简单,就是在springboot的resources下新建一个banner.txt文件,将要输出图案放到txt文件中就好,启动时 ...
- C#: .net序列化及反序列化 [XmlElement(“节点名称”)] [XmlAttribute(“节点属性”)] (上篇)
.net序列化及反序列化 序列化是指一个对象的实例可以被保存,保存成一个二进制串,当然,一旦被保存成二进制串,那么也可以保存成文本串了.比如,一个计数器,数值为2,我们可以用字符串"2&qu ...
- C# WinForm 设置按纽为透明,使用背景色
今天开发登陆界面时,遇到一个窗体控制设置问题: 1.将按纽设置为透明: 2.并且使用背景图片的颜色: 3.并且需要当点击这个按纽时,仍然显示背景图片颜色: 4.去掉按纽边框显示线: 需要的效果如下: ...
- 学习廖雪峰的Git教程3--从远程库克隆以及分支管理
一.远程库克隆 这个就比较简单了, git clone git@github.com:****/Cyber-security.git 远程库的地址可以在仓库里一个clone or download的绿 ...
- Dubbo 如何优雅停机?
Dubbo 是通过 JDK 的 ShutdownHook 来完成优雅停机的,所以如果使用 kill -9 PID 等强制关闭指令,是不会执行优雅停机的,只有通过 kill PID 时,才 会执行.
- 面试问题之计算机网络:OSI七层网络模型及相关协议
一.应用层 功能:为应用程序提供服务并规定应用程序中通信相关的细节: 包括的协议如下: 1.超文本传输协议HTTP:这是一种基本的客户机/服务器的访问协议:浏览器向服务器发送请求,而服务器会应相应的网 ...
- homebrew 安装nginx+php+mysql
转:https://juejin.im/post/5c8fb28a6fb9a07103548318 brew search nginxbrew install nginx /usr/local/etc ...
- MyISAM 表格将在哪里存储,并且还提供其存储格式?
每个 MyISAM 表格以三种格式存储在磁盘上: ·".frm"文件存储表定义 ·数据文件具有".MYD"(MYData)扩展名 索引文件具有".MY ...
- SVG是什么?
SVG表示(scalable vector graphics)可缩放矢量图形.这是一个基于文本的图形语言,它可以绘制使用文本.线.点等的图形,因此可以轻巧又快速地渲染.