[人脸活体检测] 论文:Face De-Spoofing: Anti-Spoofing via Noise Modeling
Face De-Spoofing: Anti-Spoofing via Noise Modeling
论文简介
将非活体人脸图看成是加了噪声后失真的x,用残差的思路检测该噪声从而完成分类。
文章引用量:40+
推荐指数:✦✦✦✦✧
[4] Jourabloo A, Liu Y, Liu X. Face de-spoofing: Anti-spoofing via noise modeling[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 290-306.
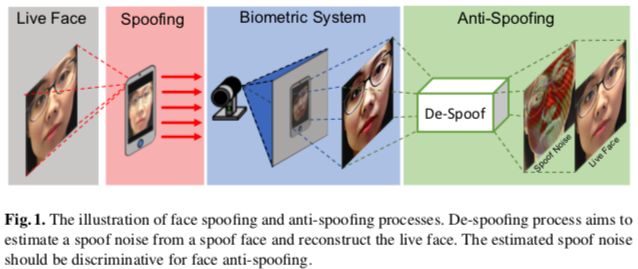
作者认为现有的大部分人脸活体分类算法都是把图像当作一个不可再分割的整体来处理,没有对假冒过程详细建模,所以呢,受到噪声模型和去噪算法的启发,作者提出人脸活体领域的新思路:把假冒人脸分解为假冒噪声(spoofing noise)和真人脸,然后用噪声做分类,Figure 1 所示。但是噪声是没有ground truth的,作者为此在合理的约束和监督信息的基础上设计了一个CNN网络来解决这个问题。实验结果显示噪声模型对分类任务是有帮助的,还把噪声的feature map做了可视化,有助于理解产生假冒的各种媒介。
作者收到de-X问题启发,比如图像去噪、去模糊等,认为假冒人脸和上述情况类似,是对真人图像用增加“特殊噪声”的方法重新渲染,既然高斯噪声、椒盐噪声可以对其建模和去除,“假冒噪声”也可以用类似的办法建模,如把假冒人脸图像x ∈ Rm 看成真人图像xˆ 、退化矩阵A ∈ Rm×m 和加性噪声n ∈ Rm 的函数:
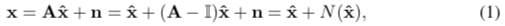
通过估计N (xˆ)和xˆ,从x去掉噪声 。对于真人样本,该模型返回xˆ本身,噪声为“0”。作者认为可以处理纸质攻击和回放攻击,优势有二:反向过程,也就是产生假冒的过程,可以帮助我们对不同假冒媒介的噪声模式建模和可视化;假冒攻击噪声本身可用于区分活体与非活体。虽然“去假冒”和其他de-X问题很相似,也有其“专属”的难点:没有ground truth,de-X通常使用人工合成的数据,原图就可以作为ground truth,对于假冒人脸,不存在去掉所有噪声的真人脸作为ground truth;没有噪声模型,之前没有类似的研究成果,不确定是否能存在一个合理的解的空间;攻击媒介多变,每种攻击类型都可能产生特定的噪声类型。作者参考Binary那边提出合成噪声模式和重建真人图像的CNN,并且用类似于GAN的思路来检验重建人脸的质量。
主要贡献
- 作者为活体识别(打印攻击和回放攻击)提供一个崭新的视角,即在没有ground truth的情况下,将攻击样本分解为真人和攻击噪声;
- 利用适当的约束和辅助监督信息,提出人脸去假冒CNN框架;
- 通过人脸防假冒攻击实验和假冒噪声可视化证明人脸去假冒模型的意义。
作者介绍了De-X问题的模型,如去噪、去模糊或超分辨率等,都是典型的低层视觉问题。通常去噪算法会假设一个加性的高斯噪声,研究人员会用non-local或CNN滤波器来探索图像内部的相似性;对于图像拼接或者超分问题,现有算法会考虑用多个模型去学习低分辨率和超分辨率图像;对于图像修复,使用者对需要修复的区域做mask标记,滤波器则根据团块的上下文来决定到底如何填补缺失的像素。作者认为De-X模型有个优点,就是大部分图像退化(degradation)是可以轻易被模拟的!这就又带来俩好处:训模型的时候,可以自己造监督信息;容易大规模合成训练和测试数据。另一方面,由于假冒人脸而导致的退化是多方面的、复杂的和细微的。它由两个阶段的退化组成:一个是来自假冒介质(如纸张和屏幕),另一个是来自假冒介质与成像环境的交互作用。每个阶段包括大量的变化,如介质类型、照明、非刚性变形和传感器类型。这些变化的组合使得整体退化变化很大。因此,通过合成退化来模拟实际场景中的假冒人脸几乎是不可能的,与传统的De-X问题相比,这是预防假冒人脸攻击领域的一个挑战。作者设计了编解码网络结构、相应的损失函数等来解决没有GT的问题。
Face De-spoofing
1. 假冒攻击噪声的实例研究
在建模之前,作者认为要先搞清两个问题:公式(1)是否是个好的噪声模型;假冒噪声都有哪些些特征。假设真人脸为I’,攻击为I,I和I’之间没有非刚性的变换,那么两者之间的退化(degradation)作者总结为以下步骤:
- 色彩失真:这是由于假冒介质的色域较窄造成的(比如LCD屏幕或打印机的墨盒),是从原始色彩空间转换到一个很小的色彩子空间的过程(很奇怪啊,就算是真人脸,也是通过相机拍下来的,色彩空间应该也很小啊)。这种噪声严重依赖目标的色彩强度,因此可以作为退化矩阵;
- Display artifacts(显示的人工成分?求翻译):假冒媒介通常用若干邻近点/传感器来近似某一个先像素的颜色,并且在展示时假冒人脸和原始尺寸可能不相同。近似和下采样过程会导致一定程度的高频信息点损失、模糊和像素扰动。由于噪声的目标依赖性,它也可以作为退化矩阵使用;
- Presenting artifacts(表达的人工成分?):当向相机展示假冒介质时,该介质与环境交互并带来几个人工成分,包括表面的反射和透明度。此噪声可作为附加噪声使用。
- Imaging artifacts(成像的人工成分?):成像栅格模式,如相机传感器阵列(如CMOS和CCD)上的屏幕像素,会造成光线干扰。这种效果会导致混叠,并产生摩尔纹,出现在回放攻击和一些带有强栅格的打印攻击中。此噪声可作为附加噪声使用。
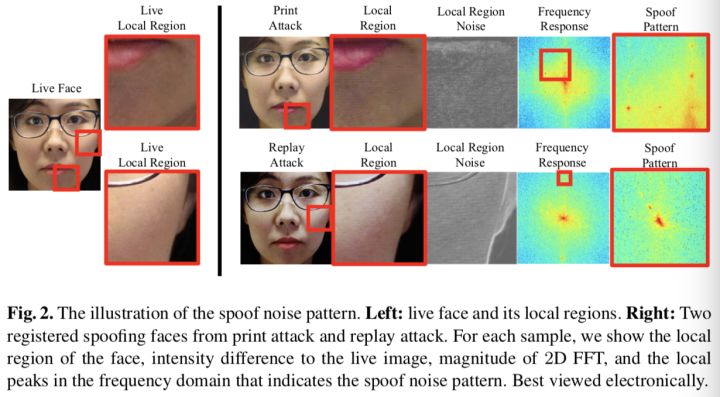
上述的退化矩阵和加性噪声都可以用在公式(1)中,还说明,假冒图像=真人图像+图像依赖性噪声,为了更进一步验证模型,作者在Figure 2中给出了示例:取同一人的攻击样本和真实样本,对同一区域做差分得到噪声图(本人存疑),将噪声图FFT后再频移,可观察到明显的不同。在两种攻击方式中,作者都发现了噪声频谱图低频区域响应很大,该区域对应的是颜色失真和display artifacts。打印攻击中,presenting artifacts中的周期性噪声在高频域没怎么产生波峰,同样在回放攻击中,肉眼可见的摩尔纹在低频段产生波峰,导致摩尔纹的栅格模式在高频段产生波峰。另有,假冒媒介带来的纹理是均匀分布的,所以攻击模式在图像空域也是均匀分布的,周期性的攻击模式在频域相应大也反应了这点。
通过上述实验,作者把攻击噪声定性为具有周期性和普遍性的纹理类型,然后设计网络,在没有精确GT的情况下估计噪声。
2. De-spoof 网络
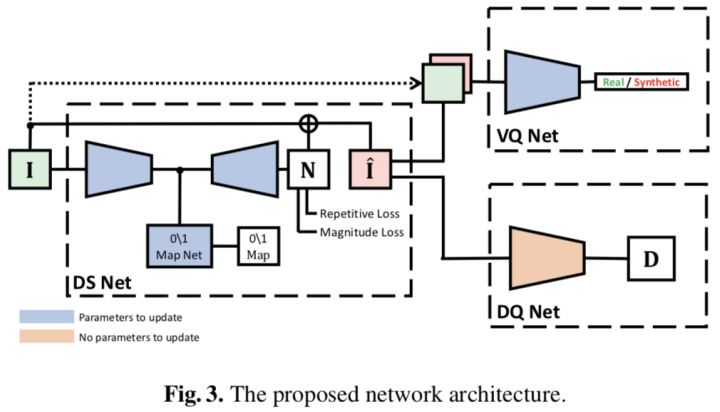
网络结构如Fig 3所示,包括三部分:De-Spoof Net(DS Net),Discriminative Quality Net (DQ Net),和Visual Quality Net (VQ Net)。DS用于从输入图像I预测攻击噪声模式N,重建后的真人图像I’是通过I减去N得到的,为了保证I’无论是看起来还是特征层面都像真人拍的,作者又引入DQ和VQ。整个网络可以端到端训练,具体参数见Tab 1。
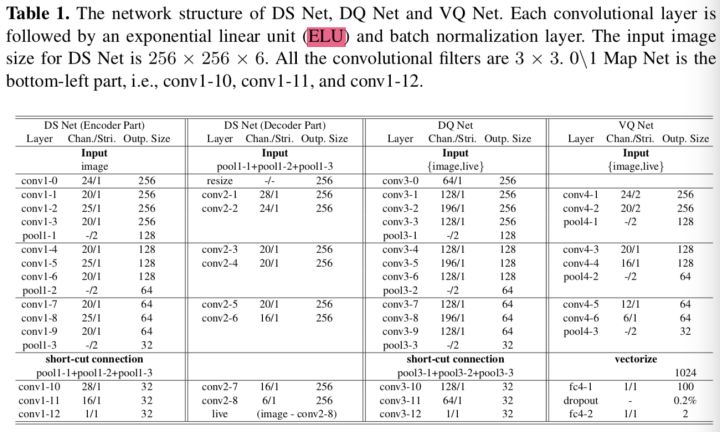
DS 网络是最核心的部分,输入I ∈ R256×256×6 ,6个通道是因为作者不仅用了RGB,还加了HSV,具体的结构就不详细介绍了,表格上都很清楚,每个卷基层作者都加了ELU(exponential linear unit)。
3. DQ Net 和 VQ Net
作者虽然没有GT来监督DS输出的噪声模式,但是还可以监督重建后的人脸图像啊,这是间接的监督噪声预测。VQ Net确保重建后的人脸看起来像真的,DQ Net确保重建后的人脸可以被一个预训练的分类器预测为真的。
- DQ Net
作者参考Binary那篇设计的DQ,可以说就是Binary那篇的深度图部分,所有策略都一样,目标函数如下:
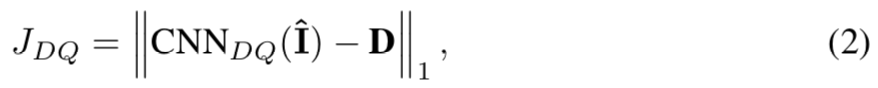
- VQ Net
VQ Net是个典型的GAN,输出2分类结果。训练中每次迭代,VQ需要两个batch来更新,第一个batch固定DS更新VQ,损失函数为:

R和S分别是真人脸和合成人脸的子集。在第二个batch,固定VQ更新DS,损失函数如下:
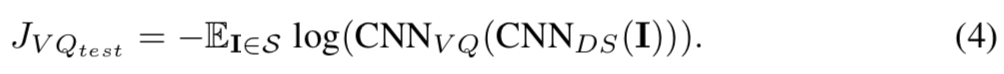
4. 损失函数
作者用1中总结的噪声属性设计了一些损失函数,首先是用幅度损失强制真人图像的噪声全部为“0”;其次,zero\one map损失用于证明假冒噪声的普遍性;再次,用周期性损失证明假冒噪声的周期性。
- 幅度损失(Magnitude Loss):对于预测出的假冒噪声N,有

直接求L1,会不会太暴力了,但好像也没有其他的办法,只有“真人脸的噪声为0”这种信息,谁也不知道真实的假冒噪声应该是什么样子的。
- Zero\One Map 损失:为了在DS的encoder部分学到discriminative的特征,作者定义对真人输出one-map同时对假冒输出zero-map的子任务。虽然这是一个pixel-wise的监督,同时也是假冒噪声普遍性特征的监督方式(解释为啥不搞成一个0和1 二分类)。另有,0\1 map的感受也可以覆盖原图的一块区域,也有助于encoder学习到更有泛化能力的特征。对于encoder的输出F,有
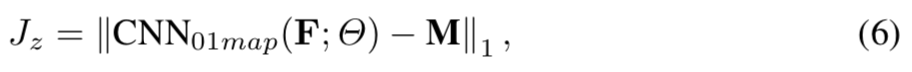
M ∈ 032×32
或者M ∈ 132×32
,也就是0\1 map的标签了。
- 周期性损失:作者前面的讨论证明假冒噪声是有周期性的,为体现该特性,作者把预测出的噪声模式N先转换到频域,然后计算高频段的最大值HP。高频波峰的存在是周期性的体现(我的信号系统知识并没有让我理解这句话)。作者放大攻击样本的HP,减少真实人脸样本的HP,就得到了这么个损失:
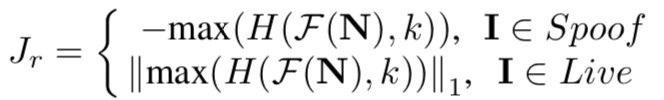
这公式连编号都没有···F是傅立叶变换,H是高频滤波器,比如在频谱图中心画个k*k的框,里面的全为0。
综上,总的损失:

就是加权相加,各个权重也没有解释的必要了。训练时,交替优化公式(7)和公式(3)。
5. 实验
- 数据集、超参和评估指标
作者在三个活体数据集上做测试,分别是Oulu-NPU、CAISA-MFSD和Replay-Attack;用TF完成所有的实验,batch size为6,lr为3e-5,高频滤波器的k为64,公式(7)四个权重从左到右分别为3、0.005、0.1和0.016。DQ单独训练,然后在跟新DS和VQ时固定参数,每个子网络的训练都遵循数据集的协议。作者用APCER、BPCER和ACER在Oulu-NPU上做内部测试;用HTER在CAISA-MFSD和Replay-Attack做交叉测试。
- 模型简化测试
作者用Onlu-NPU的Protocol 1研究score fusing、各个损失函数的重要性和分辨率与模糊程度的影响。
Fusion方法:整个框架有三处输出可以用来做分类,0\1map,噪声模式和深度图。
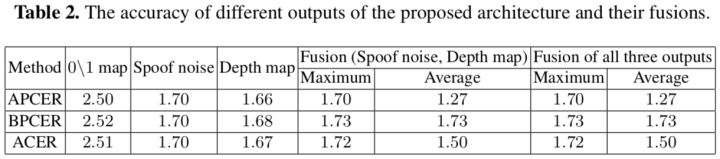
从Table 2可以看出,噪声和深度图混合的效果最好,增加0\1map后没有提升,主要因为0\1map和深度图包含的信息很类似,深度图也是从DS的输出预测出的。
各损失的优势:作者分别把幅度损失、0\1map损失和周期性损失从总的损失中去掉,得到ACER分别为5.24、2.34和1.5。为进一步证实周期性损失,作者通过改变网络输入增大图像分辨率至1080P,得到ACER=2.92,但是不收敛···
分辨率和模糊程度:
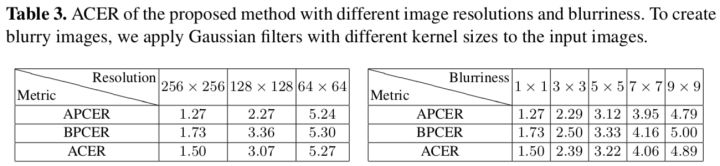
Table 3能看出分辨率和模糊对算法效果影响还是很大的,说明假冒噪声模式主要体现在高频段。
- 对比
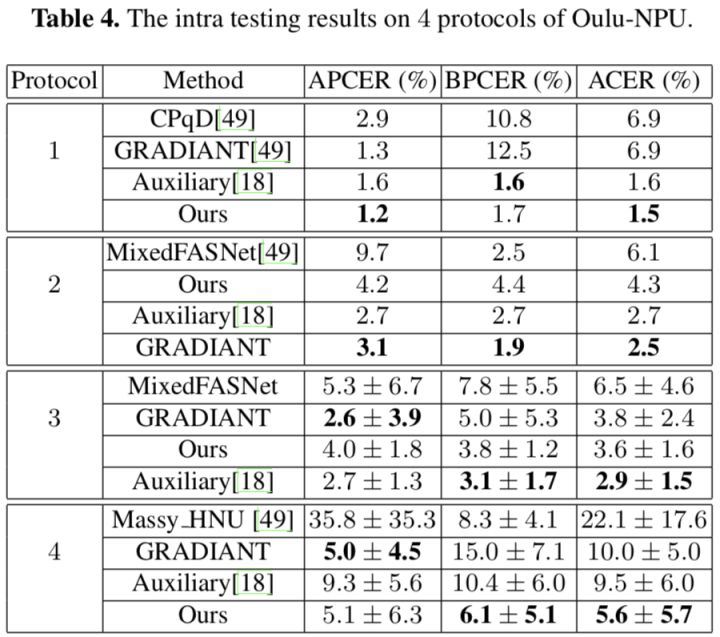
数据集内部测试,见Table 4,Protocol 3为了误导读者么···
交叉测试,见Table 5,作者认为CASIA-MFSD的图像分辨率更高才导致这样的结果,也证实了所提出的算法的确需要较高分辨率的图像作为输入,算是值得未来继续研究的缺点。
- 定性实验
假冒媒介分类:DS预测出的假冒噪声模式可以用来对测试样本按照媒介类型聚类,为了可视化结果,作者用t-SNE把N从2562566(为什么是6?难道不是1么···)降到2维!Fig 4 为可视化结果,明显高频对噪声模式有更大贡献。
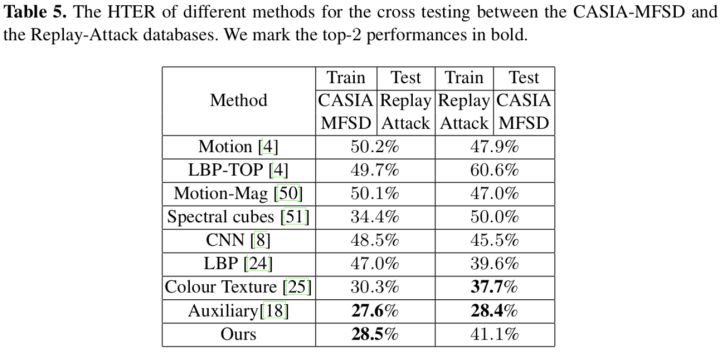
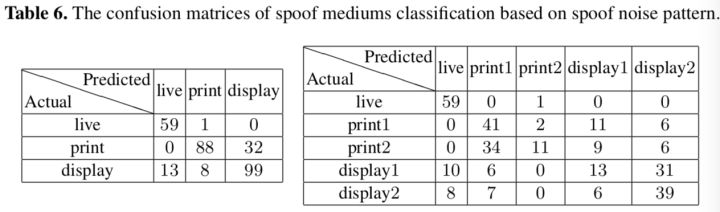
为了进一步展示噪声模式的辨别力,作者把Oulu的Protocol 1的测试集再分成训练集和测试集,训练SVM,目的是区分假冒媒介。作者训了俩模型,一个三分类(真人,打印和回放)的和一个五分类的(真人,print1,print2,replay1和replay2),分别得到%82和54.3%的accuracy,如Tab 6所示。五分类模型大部分的错误都发生统一假冒媒介之间。作者提出的噪声模式在训练时并没有媒介标签,仍然可以在预测结果中体现媒介类型,因此可以获得有一定可信度的媒介分类结果。证实噪声模型的确携带媒介相关的信息,也侧面说明的确学到了噪声。作者认为如果在媒介分类上可以继续提升,没准将来会对法医工作有影响···

更多信息请关注公众号:

[人脸活体检测] 论文:Face De-Spoofing: Anti-Spoofing via Noise Modeling的更多相关文章
- 从零玩转人脸识别之RGB人脸活体检测
从零玩转RGB人脸活体检测 前言 本期教程人脸识别第三方平台为虹软科技,本文章讲解的是人脸识别RGB活体追踪技术,免费的功能很多可以自行搭配,希望在你看完本章课程有所收获. ArcFace 离线SDK ...
- Qt编写百度离线版人脸识别+比对+活体检测
在AI技术发展迅猛的今天,很多设备都希望加上人脸识别功能,好像不加上点人脸识别功能感觉不够高大上,都往人脸识别这边靠,手机刷脸解锁,刷脸支付,刷脸开门,刷脸金融,刷脸安防,是不是以后还可以刷脸匹配男女 ...
- 虹软人脸识别 - faceId及IR活体检测的更新介绍
虹软人脸识别 - faceId及IR活体检测的介绍 前几天虹软推出了 Android ArcFace 2.2版本的SDK,相比于2.1版本,2.2版本中的变化如下: VIDEO模式新增faceId(类 ...
- python3 百度AI-v3之 人脸对比 & 人脸检测 & 在线活体检测 接口
#!/usr/bin/python3 # 百度人脸对比 & 人脸检测api-v3 import sys, tkinter.messagebox, ast import ssl, json,re ...
- 虹软人脸识别 - faceId及IR活体检测的介绍
虹软人脸识别 - faceId及IR活体检测的介绍 前几天虹软推出了 Android ArcFace 2.2版本的SDK,相比于2.1版本,2.2版本中的变化如下: VIDEO模式新增faceId(类 ...
- 人脸标记检测:ICCV2019论文解析
人脸标记检测:ICCV2019论文解析 Learning Robust Facial Landmark Detection via Hierarchical Structured Ensemble 论 ...
- dlib人脸关键点检测的模型分析与压缩
本文系原创,转载请注明出处~ 小喵的博客:https://www.miaoerduo.com 博客原文(排版更精美):https://www.miaoerduo.com/c/dlib人脸关键点检测的模 ...
- OpenCV实战:人脸关键点检测(FaceMark)
Summary:利用OpenCV中的LBF算法进行人脸关键点检测(Facial Landmark Detection) Author: Amusi Date: 2018-03-20 ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
- C# 活体检测
活体检测有多种情形,本文所指:从摄像头获取的影像中判断是活体,还是使用了相片等静态图片. 场景描述 用户个人信息中上传了近照,当用户经过摄像头时进行身份识别. 此时,如果单纯的使用摄像头获取的影像进行 ...
随机推荐
- Nginx自带的变量
$args #请求中的参数值$query_string #同 $args$arg_NAME #GET请求中NAME的值$is_args #如果请求中有参数,值为"?",否则为空字符 ...
- idea远程仓库无法更新导致的各种错误,jar包无法下载
直接把下面的配置替换成settings.xml中的内容 <?xml version="1.0" encoding="UTF-8"?> <set ...
- 查看Linux内存占用情况
参考链接: 查看Linux磁盘及内存占用情况 linux的top命令参数详解 1.ps ps aux --sort -rss a 显示所有终端机下执行的进程,包括其他用户的进程(有的进程没有终 ...
- Vue2使用axios,request.js和vue.config.js
1.配置request.js,用来请求数据 import axios from 'axios' // 1:利用axios对象的方法create,创建一个axios实例 // 2:request就是ax ...
- element表格样式的修改
修改表格头部背景 .el-table th{ background: #f00; } 修改表格行背景 .el-table tr{ background: #f00; } 修改斑马线表格的背景 .el- ...
- 11. ASCII, unicode, utf-8, gbk的区别
这是几种编码方式 ASCII是包含英文字母数字特殊字符等, 长度是1字节, 前128个是基础ASCII码, 128个以后是扩展ASCII码 GBK是国标扩展码, 长度2字节, 表示汉字以及各少数民族语 ...
- 《MySQL是怎样运行的》第七章小结
- DVWA-File Inclusion(文件包含)
文件包含漏洞,当我们在一个代码文件想要引入.嵌套另一个代码文件的时候,就是文件包含. 常见的文件包含函数有include require等函数. 这两个函数的区别就是include在包含文件不存在时p ...
- HDF格式遥感影像批量转为TIFF格式:ArcPy实现
本文介绍基于Python中ArcPy模块,实现大量HDF格式栅格图像文件批量转换为TIFF格式的方法. 首先,来看看我们想要实现的需求. 在一个名为HDF的文件夹下,有五个子文件夹:每一个 ...
- K8S部署应用详解
# 前言 首先以SpringBoot应用为例介绍一下k8s的发布步骤. 1.从代码仓库下载代码,比如GitLab:2.接着是进行打包,比如使用Maven:3.编写Dockerfile文件,把步骤2产生 ...