Hadoop入门学习笔记(二)
Yarn学习
YARN简介
YARN是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度
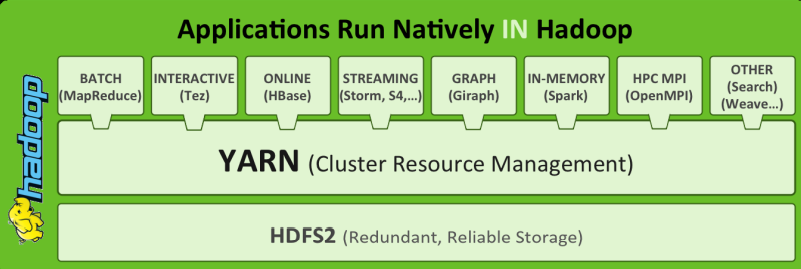
YARN功能说明
- 资源管理系统:集群的硬件资源,和程序运行相关,比如内存、CPU等。
- 调度平台:多个程序同时申请计算资源如何分配,调度的规则(算法)。
- 通用:不仅仅支持MapReduce程序,理论上支持各种计算程序。YARN不关心你干什么,只关心你要资源,在有 的情况下给你,用完之后还我。
即使MapReduce现在不流行了 也可以用别的计算模型来替代 如 spark flink,一定程度上 yarn促进了hadoop的流行。
YARN主要结构
ResourceManager(RM) YARN集群中的主角色,决定系统中所有应用程序之间资源分配的最终权限,即最终仲裁者。 接收用户的作业提交,并通过NM分配、管理各个机器上的计算资源。
NodeManager(NM) YARN中的从角色,一台机器上一个,负责管理本机器上的计算资源。 根据RM命令,启动Container容器、监视容器的资源使用情况。并且向RM主角色汇报资源使用情况。
ApplicationMaster(AM) 用户提交的每个应用程序均包含一个AM。 应用程序内的“老大”,负责程序内部各阶段的资源申请,监督程序的执行情况。
核心交互流程
MR作业提交 Client-->RM
资源的申请 MrAppMaster-->RM
MR作业状态汇报 Container(Map|Reduce Task)-->Container(MrAppMaster)
节点的状态汇报 NM-->R
三种调度器
FIFO Scheduler(先进先出调度器)、Capacity Scheduler(容量调度器)、Fair Scheduler(公平调度器)。

FIFO Scheduler概述
- FIFO Scheduler是Hadoop1.x中JobTracker原有的调度器实现,此调度器在YARN中保留了下来。
- FIFO Scheduler是一个先进先出的思想,即先提交的应用先运行。调度工作不考虑优先级和范围,适用于负载较低 的小规模集群。当使用大型共享集群时,它的效率较低且会导致一些问题。
- FIFO Scheduler拥有一个控制全局的队列queue,默认queue名称为default,该调度器会获取当前集群上所有的 资源信息作用于这个全局的queue。
FIFO Scheduler优势、坏处
- 优势: 无需配置、先到先得、易于执行
- 坏处: 任务的优先级不会变高,因此高优先级的作业需要等待 不适合共享集群
Capacity Scheduler概述
Capacity Scheduler容量调度是Apache Hadoop3.x默认调度策略。该策略允许多个组织共享整个集群资源,每个 组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源, 这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。
Capacity可以理解成一个个的资源队列,这个资源队列是用户自己去分配的。队列内部又可以垂直划分,这样一个 组织内部的多个成员就可以共享这个队列资源了,在一个队列内部,资源的调度是采用的是先进先出(FIFO)策略
Capacity Scheduler调度器以队列为单位划分资源。简单通俗点来说,就是一个个队列有独立的资源,队列的结构 和资源是可以进行配置的。
层次化的队列设计(Hierarchical Queues) 层次化的管理,可以更容易、更合理分配和限制资源的使用。
容量保证(Capacity Guarantees) 每个队列上都可以设置一个资源的占比,保证每个队列都不会占用整个集群的资源。
安全(Security) 每个队列有严格的访问控制。用户只能向自己的队列里面提交任务,而且不能修改或者访问其他队列的任务。
弹性分配(Elasticity) 空闲的资源可以被分配给任何队列。 当多个队列出现争用的时候,则会按照权重比例进行平衡。
Fair Scheduler概述
- Fair Scheduler叫做公平调度,提供了YARN应用程序公平地共享大型集群中资源的另一种方式。使所有应用在平 均情况下随着时间的流逝可以获得相等的资源份额
- Fair Scheduler设计目标是为所有的应用分配公平的资源(对公平的定义通过参数来设置)
- 公平调度可以在多个队列间工作,允许资源共享和抢占。
这边的公平要怎么理解呢?
我的理解是 不同队列(用户)之间是公平的,在一个队列中的各个任务间也是公平的,而不是谁队列中的任务多,谁获得的资源就多。可以理解为,每个家庭分配一样的粮食,你家有多少人,自己再公平分配。但调度器也可以开启资源抢占,当你队列中的资源闲置,可以允许别的队列去抢占,这需要你去开启相关配置
Hadoop入门学习笔记(二)的更多相关文章
- Hadoop入门学习笔记---part1
随着毕业设计的进行,大学四年正式进入尾声.任你玩四年的大学的最后一次作业最后在激烈的选题中尘埃落定.无论选择了怎样的选题,无论最后的结果是怎样的,对于大学里面的这最后一份作业,也希望自己能够尽心尽力, ...
- Hadoop入门学习笔记---part4
紧接着<Hadoop入门学习笔记---part3>中的继续了解如何用java在程序中操作HDFS. 众所周知,对文件的操作无非是创建,查看,下载,删除.下面我们就开始应用java程序进行操 ...
- Hadoop入门学习笔记---part3
2015年元旦,好好学习,天天向上.良好的开端是成功的一半,任何学习都不能中断,只有坚持才会出结果.继续学习Hadoop.冰冻三尺,非一日之寒! 经过Hadoop的伪分布集群环境的搭建,基本对Hado ...
- Hadoop入门学习笔记---part2
在<Hadoop入门学习笔记---part1>中感觉自己虽然总结的比较详细,但是始终感觉有点凌乱.不够系统化,不够简洁.经过自己的推敲和总结,现在在此处概括性的总结一下,认为在准备搭建ha ...
- Hadoop入门学习笔记(一)
Week2 学习笔记 Hadoop核心组件 Hadoop HDFS(分布式文件存储系统):解决海量数据存储 Hadoop YARN(集群资源管理和任务调度框架):解决资源任务调度 Hadoop Map ...
- Hadoop入门学习笔记总结系列文章导航
一.为何要学习Hadoop? 这是一个信息爆炸的时代.经过数十年的积累,很多企业都聚集了大量的数据.这些数据也是企业的核心财富之一,怎样从累积的数据里寻找价值,变废为宝炼数成金成为当务之急.但数据增长 ...
- Hadoop入门学习笔记之一
http://hadoop.apache.org/docs/r1.2.1/api/index.html 适当的利用 null 在map中可以实现对文件的简单处理,如排序,和分集合输出等. 需要关心的内 ...
- Hadoop入门学习笔记-第一天 (HDFS:分布式存储系统简单集群)
准备工作: 1.安装VMware Workstation Pro 2.新建三个虚拟机,安装centOS7.0 版本不限 配置工作: 1.准备三台服务器(nameNode10.dataNode20.da ...
- Hadoop入门学习笔记-第三天(Yarn高可用集群配置及计算案例)
什么是mapreduce 首先让我们来重温一下 hadoop 的四大组件:HDFS:分布式存储系统MapReduce:分布式计算系统YARN: hadoop 的资源调度系统Common: 以上三大组件 ...
随机推荐
- 富文本编辑器CKeditor的配置和图片上传,看完不后悔
CKeditor是一款富文本编辑器,本文将用极为简单的方式介绍一下它的使用和困扰大家很久的图片上传问题,要有耐心. 第一步:如何使用 1.官网下载https://ckeditor.com/ckedit ...
- 用CSS实现Tab页切换效果
用CSS实现Tab切换效果 最近切一个页面的时候涉及到了一个tab切换的部分,因为不想用js想着能不能用纯CSS的选择器来实现切换效果.搜了一下大致有下面三种写法. 利用:hover选择器 缺点:只有 ...
- python-使用函数求特殊a串数列和
给定两个均不超过9的正整数a和n,要求编写函数fn(a,n) 求a+aa+aaa++⋯+aa⋯aa(n个a)之和,fn须返回的是数列和 函数接口定义: 1 fn(a,n) 2 其中 a 和 n 都是用 ...
- linux安装mongodb磁盘空间不足
Insufficient free space for journal filesPlease make at least 3379MB available in /export/servers/mo ...
- 微信支付之微信H5支付(坑,ajax不支持重定向跳转)
这里讲的是 微信h5支付, 是微信以外的手机浏览器调用微信h5支付 h5支付: H5支付是指商户在微信客户端外的移动端网页展示商品或服务,用户在前述页面确认使用微信支付时,商户发起本服务呼起 ...
- C# 一个基于.NET Core3.1的开源项目帮你彻底搞懂WPF框架Prism
--概述 这个项目演示了如何在WPF中使用各种Prism功能的示例.如果您刚刚开始使用Prism,建议您从第一个示例开始,按顺序从列表中开始.每个示例都基于前一个示例的概念. 此项目平台框架:.NET ...
- CRLF 漏洞学习和工具使用
原理 CRLF 指的是回车符(CR,ASCII 13,\r,%0d) 和换行符(LF,ASCII 10,\n,%0a),操作系统就是根据这个标识来进行换行的.但是如果对输入过滤不严,就会将恶意语句注入 ...
- sqli-labs环境搭建
1 下载phpStudy 下载地址:https://www.xp.cn/download.html 由于sqli-lib最后一次提交代码的时候是2014年,所以高版本的phpStudy可能不兼容了,推 ...
- windows+ubuntu双系统时间同步问题
windows+ubuntu双系统时间同步问题 给Ubuntu更新时间,在终端输入: sudo apt-get install ntpdate sudo ntpdate time.windows.co ...
- GIL全局解释器锁、协程运用、IO模型
GIL全局解释器锁 一.什么是GIL 首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念.就好比C是一套语言(语法)标准,但是可以用不 ...