基于Python的渗透测试信息收集系统的设计和实现
信息收集系统的设计和实现
渗透测试是保卫网络安全的一种有效且必要的技术手段,而渗透测试的本质就是信息收集,信息搜集整理可为后续的情报跟进提供强大的保证,目标资产信息搜集的广度,决定渗透过程的复杂程度,目标主机信息搜集的深度,决定后渗透权限的持续把控。
实现功能
系统主要基于Python实现了Web指纹探测、端口扫描和服务探测、真实IP信息探测、WAF防火墙探测、子域名扫描、目录扫描和敏感信息探测的功能。
设计思路
Web指纹探测
CMS识别功能主要通过调用本地识别接口识别,或者调用网络识别接口识别两种方式,其中本地接口识别主要是通过比对常见CMS的特征来完成识别。系统收集了1400+的国内常见指纹,并且以josn文件类型的方式保存,便于以后的补充和扩展。

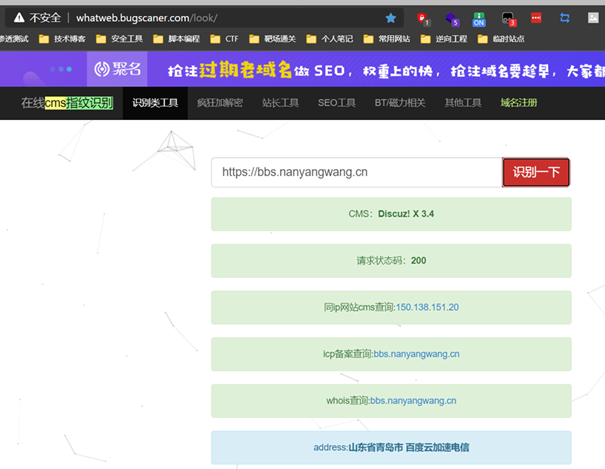
而网络接口识别则是通过在线指纹识别网站whatweb的api来实现,whatweb在线识别演示如图所示。
CDN检测
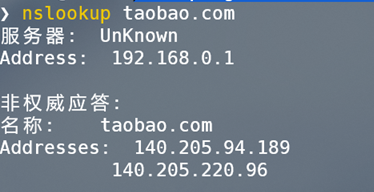
CDN判断功能主要是通过两种本地判断方式和三种网络接口在线判断方式共同运行,最后结合五种判断方式得到的结果得出最终结论的方法实现。本地判断主要是借助Socket模块中的getaddrinfo方法来解析域名,以及nslookup查询域名信息的方法来判断是否存在CDN防护。

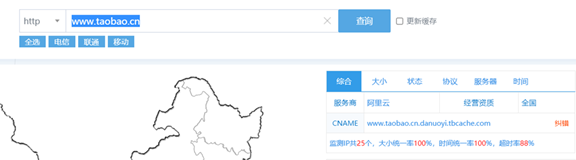
三种网络接口在线判断CDN服务的演示如图所示。


子域名扫描
子域名扫描功能一方面是通过本地字典爆破,另外一方面主要是通过Bing搜索引擎,对要查询的域名进行谷歌语法搜索子域名。

敏感目录文件扫描
敏感目录文件扫描功能主要是通过读取本地字典文件,然后拼接URL,并且把拼接后的URL通过Python中的HackRequests模块进行request请求,如果拼接后的URL返回状态码200,那么我们可以判断拼接后的URL可以正常访问,也就说明我们从本地字典中读取到的目录或者文件是存在的。如果拼接后的URL返回状态码不是200,那么我们从本地字典中读取到的目录或文件可能是不存在的。
端口扫描服务探测
端口扫描功能主要是通过Python中的Socket模块创建TCP三次握手连接,并通过返回值是否为0来判断端口是否存活。以及使用Python中的Nmap模块,来调用端口扫描神器Nmap进行端口扫描功能。
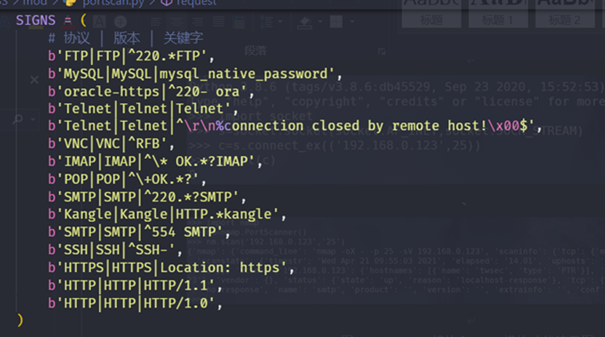
服务探测主要是通过Socket模块中的sendall方法来发送请求,然后接收响应包并对响应包中的内容与本地保存的服务特征信息进行关键字匹配,以此来判断开放端口对应的服务类型,同时输出返回信息,可以在本地无法匹配到相关特征时进行人工判断服务类型。
关键代码实现
系统以webinfo.py为主程序文件,通过与用户交互,获取用户指令,然后根据用户输入的指令来调用不同的模块代码文件,进而实现对应的功能。
系统主函数功能实现
系统主函数的主要功能是通过与用户交互,提示用户输入正确的选项,并根据用户的输入来调用其他对应的功能函数,完成用户想要完成的不同功能。同时应做好程序的异常处理机制,防止因用户的不正确输入,而导致的程序崩溃的情况发生,提高程序的健壮性。
if __name__ == "__main__":
try:
demo=input("请选择功能模块a.cms识别,b.cdn判断,c.子域名扫描,d.敏感目录文件扫描,e.端口扫描服务探测(输入序号即可):")
if(demo=="a"):
try:
test = int(input("输入数字1进行单个url解析cms,输入数字2进行文件批量解析cms:"))
if(test==1):
try:
domain = input("输入要检测web指纹的url(注意不带路径如https://www.baidu.com):")
try:
urllib.request.urlopen(domain)
print("开始调用本地接口检测"+domain+"的cms!")
webcms=webcms(domain)
webcms.run()
print("开始调用网络接口检测"+domain+"的cms!")
info=str(cmso2(domain))
print(domain+"解析到的其他信息为:"+info)
except urllib.error.HTTPError:
print("域名有误,请检查并按格式输入!")
time.sleep(2)
except urllib.error.URLError:
print("域名有误,请检查并按格式输入!")
time.sleep(2)
except Exception as e:
print("程序运行出错!请检查并再次尝试!")
time.sleep(2)
if(test==2):
threads = [20]
filename = input("请输入要解析的url文件路径:")
try:
t=threading.Thread(target=cmsfile(filename),args=filename)
for ti in threads:
t.setDaemon(True)
t.start()
for ti in threads:
t.join()
except Exception as e:
print("输入有误,或文件路径找不到,请检查并按格式输入!")
time.sleep(2)
except Exception as e:
print("输入有误,请检查并按格式输入!")
time.sleep(2)
elif(demo=="b"):
cdn.run()
elif(demo=="c"):
subdomain.jkxz()
elif(demo=="d"):
dirfilesm.bprun()
elif(demo=="e"):
portscan.port()
else:
print("输入出错,请重试!")
time.sleep(2)
except Exception as e:
print("程序运行出错!请检查并再次尝试!")
time.sleep(2)
CMS识别功能的实现
CMS识别时先通过与用户交互,判断用户是进行单个URL识别还是进行批量文件识别,这一过程实现方式和主函数模块类似,主要是通过if判断变量test的值。如果test的值为1,则代表用户选择单个URL识别功能,如果test的值为2,则代表用户选择批量文件识别的功能。批量文件识别时,主要涉及到Python中文件的操作。
具体识别时主要分为本地接口识别和网络接口api识别两种方式。本地识别先通过爬虫获取目标网站的特征信息,这一过程通过类Downloader来完成。Downloader类主要定义了三个函数方法:get,post和download,通过这三个函数可以对目标网站进行爬虫,获取到目标网站的基本特征信息。
获取到的网站特征信息再和本地的josn文件进行比对,从而识别出目标网站的CMS信息。这个过程主要是通过类webcms来实现,类webcms一方面将本地josn文件中的内容读取到队列中,另外一方面将爬取到的信息与队列中的信息进行正则匹配,根据匹配结果得出识别结论。为了提高程序运行效率,需要同时对提取本地josn文件内容的过程和比对信息的过程进行多线程的操作。
网络api识别接口的实现,主要是对通过api请求得到的数据进行二次处理,得到相应的CMS信息,同时也可借助该接口得到目标网站的其他相关信息。
class webcms(object):
workQueue = queue.Queue()
URL = ""
threadNum = 0
NotFound = True
Downloader = Downloader()
result = ""
def __init__(self,url,threadNum = 20):
self.URL = url
self.threadNum = threadNum
filename = os.path.join(sys.path[0], "data", "data.json")
fp = open(filename,encoding="utf-8")
webdata = json.load(fp,encoding="utf-8")
for i in webdata:
self.workQueue.put(i)
fp.close()
def getmd5(self, body):
m2 = hashlib.md5()
m2.update(body.encode())
return m2.hexdigest()
def th_whatweb(self):
if(self.workQueue.empty()):
self.NotFound = False
return False
if(self.NotFound is False):
return False
cms = self.workQueue.get()
_url = self.URL + cms["url"]
html = self.Downloader.get(_url)
print ("[whatweb log]:checking %s"%_url)
if(html is None):
return False
if cms["re"]:
if(html.find(cms["re"])!=-1):
self.result = cms["name"]
self.NotFound = False
return True
else:
md5 = self.getmd5(html)
if(md5==cms["md5"]):
self.result = cms["name"]
self.NotFound = False
return True
def run(self):
while(self.NotFound):
th = []
for i in range(self.threadNum):
t = threading.Thread(target=self.th_whatweb)
t.start()
th.append(t)
for t in th:
t.join()
if(self.result):
print ("[cmsscan]:%s cms is %s"%(self.URL,self.result))
else:
print ("[cmsscan]:%s cms NOTFound!"%self.URL)
def cmso2(domain):
requests.packages.urllib3.disable_warnings()
response = requests.get(domain,verify=False)
whatweb_dict = {"url":response.url,"text":response.text,"headers":dict(response.headers)}
whatweb_dict = json.dumps(whatweb_dict)
whatweb_dict = whatweb_dict.encode()
whatweb_dict = zlib.compress(whatweb_dict)
data = {"info":whatweb_dict}
res=requests.post("http://whatweb.bugscaner.com/api.go",files=data)
dic=json.loads(res.text)
if('CMS' in dic.keys()):
info=str(dic['CMS'])
info=info.replace("[","")
info=info.replace("]","")
info=info.replace("'","")
print(domain+"的cms为:"+info)
else:
print(domain+"的cms未能识别!")
return dic
CDN判断功能的实现
CDN判断功能的实现主要是通过系统中的五个功能函数,分别对目标域名进行CDN检测,最后再统计各个功能函数的检测结果。当五个功能函数的检测结果中有三个或者三个以上是存在CDN防护的情况下,可以认为目标域名存在CDN防护,反之则可以认为目标域名不存在CDN防护。这一过程的实现主要是通过设定flag,并根据函数返回结果对flag进行加权赋值,最后再根据flag的值得出最终的结果。
五个功能函数中的前两个函数主要是通过Socket模块中的getaddrinfo方法解析域名,以及nslookup查询域名信息的方法来得到域名对应的IP列表。如果以此得到的目标域名的IP数量在两个或者两个以上,则说明目标域名可能存在CDN防护,这两个函数返回结果为True,反之则说明目标域名可能不存在CDN防护,函数返回结果为False。
另外三个函数主要借助第三方查询网站查询目标域名的cname域名信息,并以此判断目标域名是否存在CDN防护。具体实现则主要借助爬虫来完成,同时对返回的数据信息进行筛选处理,得到我们想要的结果。
def getipo1(domain):
ip_list=[]
flag1 = 0
ipaddr = socket.getaddrinfo(domain,None)
for item in ipaddr:
if item[4][0] not in ip_list:
ip_list.append(item[4][0])
flag1 = flag1+1
return flag1,ip_list
def getipo2(domain):
flag2 = 0
pi = subprocess.Popen('nslookup {}'.format(domain), shell=True, stdout=subprocess.PIPE)
out = pi.stdout.read().decode('gbk') # 编码根据实际结果调整
# 判断返回值中是否有 Addresses 字段,且该字段下 ip 地址要大于等于 2 个,即说明使用了 CDN
strs = re.findall(r'Addresses:(\s*(((25[0-5]|2[0-4]\d|1\d{2}|[1-9]?\d)\.){3}(25[0-5]|2[0-4]\d|1\d{2}|[1-9]?\d)\s*)*)', out, re.S)
if strs == []:
return flag2
else:
l = strs[0][0].split('\r\n\t')
for address in l:
flag2 = flag2+1
return flag2
def getipo3(domain):
flag3 = 0
url = 'http://cdn.chinaz.com/search/?host='+domain
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text,'lxml')
#a = soup.find_all(text=(re.compile("可能使用CDN云加速")))
b = soup.find_all(text=(re.compile("不属于CDN云加速")))
if(b==[]):
flag3=flag3+1
return flag3
if(b!=[]):
return flag3
def getipo4(domain):
flag4 = 0
info = "未知"
url = 'http://tools.bugscaner.com/api/whichcdn/'
payload = {'url':domain}
res = requests.post(url,data=payload)
content = json.loads(res.text)
if(str(content['secess'])=="True"):
flag4 = flag4+1
info=content['info']
return flag4,info
if(str(content['secess'])=="False"):
return flag4,info
def getipo5(domain):
flag5 = 0
info="未知"
#browser=webdriver.PhantomJS(executable_path=r'D:\GeckoDriver\phantomjs-2.1.1-windows\bin\phantomjs.exe')
url = 'https://tools.ipip.net/cdn.php'
#browser.get(url)
#Cookie = browser.get_cookies()
#browser.close()
#strr = ''
#for c in Cookie:
#strr += c['name']
#strr += '='
#strr += c['value']
#strr += ';'
cookie="LOVEAPP_SESSID=19676de35da2f3d730a92ceac59888c2d9f44f1b; __jsluid_s=7312e36ccdfd6c67bd2d54a59f5ef9f2; _ga=GA1.2.671769493.1617350155; _gid=GA1.2.268809088.1617350155; Hm_lvt_6b4a9140aed51e46402f36e099e37baf=1617350155; login_r=https%253A%252F%252Ftools.ipip.net%252F;"
payload = {'node':663,'host':domain}
user_agent=UserAgent().random
headers={"User-Agent":user_agent,"Cookie":cookie}
res = requests.post(url,data=payload,headers=headers)
#print(res.text)
soup=BeautifulSoup(res.text,'lxml')
data = soup.find_all('td')
#print(data)
a=soup.find_all(text=(re.compile("未知")))
if(a!=[]):
return flag5,info
else:
for item in data:
info1 = item.find('a')
info=info1.text
#print(info)
flag5=flag5+1
return flag5,info
子域名扫描功能的实现
子域名扫描功能主要是通过本地字典爆破和搜索引擎搜索两种方法来实现。其中字典爆破是通过加载本地字典来拼接URL,并对拼接后的URL进行request请求,然后根据返回的状态码来判断子域名是否存在。
搜索引擎搜索则主要借助特殊搜索语法site的使用,同时借助爬虫技术,对搜索到的数据进行筛选处理,进而得到目标域名的子域名信息。
def bp(url):
user_agent=UserAgent().random
header={"User-Agent":user_agent}
try:
h = HackRequests.hackRequests()
res = h.http(url,headers=header)
if (res.status_code==200):
print("成功爆破出子域名:"+url)
except:
pass
def zymbp(filename,domain):
try:
f = open(filename,encoding='utf8')
lines = f.readlines()
i = -1
for key in lines:
i=i+1
key=lines[i].strip('\n')
url = "http://"+key+"."+domain
threads = [20]
t=threading.Thread(target=bp(url),args=url)
for ti in threads:
t.setDaemon(True)
t.start()
for ti in threads:
t.join()
except Exception as e:
print("输入有误,或文件路径找不到,请检查并按格式输入!")
time.sleep(2)
def bprun():
filename=input("请输入要爆破的子域名字典路径:")
try:
domain=input("请输入要爆破的域名(格式为:baidu.com):")
try:
threads = [20]
t=threading.Thread(target=zymbp(filename,domain),args=(filename,domain))
for ti in threads:
t.setDaemon(True)
t.start()
for ti in threads:
t.join()
except Exception as e:
print("程序运行出错!请检查并再次尝试!")
time.sleep(2)
except Exception as e:
print("输入有误,或文件路径找不到,请检查并按格式输入!")
time.sleep(2)
def bing_search(site,pages):
subdomain=[]
user_agent=UserAgent().random
headers={'User-Agent':user_agent,'Accept':'*/*','Accept_Language':'en-US,en;q=0.5','Accept-Encoding':'gzip,deflate','referer':"http://cn.bing.com/search?q=email+site%3abaidu.com&qs=n&sp=-1&pq=emailsite%3abaidu.com&first=2&FORM=PERE1"}
for i in range(1,int(pages)+1):
url="https://cn.bing.com/search?q=site%3a"+site+"&go=Search&qs=Search&qs=ds&first="+str((int(i)-1)*10)+"&FORM=PERE"
conn=requests.session()
conn.get('http://cn.bing.com',headers=headers)
html=conn.get(url,stream=True,headers=headers,timeout=8)
soup=BeautifulSoup(html.content,'html.parser')
job_bt=soup.findAll('h2')
for i in job_bt:
link=i.a.get('href')
domain=str(urlparse(link).scheme+"://"+urlparse(link).netloc)
if(domain in subdomain):
pass
else:
subdomain.append(domain)
print("成功搜索出子域名:"+domain)
def runbing():
try:
site=input("请输入要查询的域名(格式为:baidu.com):")
page=int(input("请输入查询的页数:"))
try:
bing_search(site,page)
except Exception as e:
print("程序运行出错!请检查并再次尝试!")
time.sleep(2)
except Exception as e:
print("输入有误,请检查并按格式输入!")
time.sleep(2)
敏感目录文件扫描功能的实现
敏感目录文件的扫描功能主要是通过加载本地字典文件,对当前URL进行拼接,然后再借助HackRequests库对拼接后的URL进行request请求验证。当返回状态码为200时,则认为当前请求的目录或者文件存在。
def dirfilebp(filename,domain):
try:
f = open(filename,encoding='utf8')
lines = f.readlines()
i = -1
for key in lines:
i=i+1
key=str(lines[i].strip('\n'))
url = domain+key
threads = [20]
t=threading.Thread(target=bp(url),args=url)
for ti in threads:
t.setDaemon(True)
t.start()
for ti in threads:
t.join()
except Exception as e:
print("输入有误,或文件路径找不到,请检查并按格式输入!")
time.sleep(2)
def bp(url):
user_agent=UserAgent().random
header={"User-Agent":user_agent}
try:
h = HackRequests.hackRequests()
res = h.http(url,headers=header)
if (res.status_code==200):
print("成功爆破出目录或文件:"+url)
except:
pass
端口扫描服务探测功能的实现
端口扫描功能一方面是借助Python中的Socket模块创建TCP三次握手连接,并通过返回值是否为0来判断端口是否存活。另外一方面则是借助Python中的Nmap模块,来调用端口扫描神器Nmap进行端口扫描功能。
服务探测主要是通过Socket模块中的sendall方法来发送请求,然后接收响应包并对响应包中的内容与本地保存的服务特征信息进行关键字匹配,以此来判断开放端口对应的服务类型,同时输出返回信息,可以在本地无法匹配到相关特征时进行人工判断服务类型。
def sorun(queue_s,ip):
while not queue_s.empty():
try:
port=queue_s.get()
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.settimeout(1)
c=s.connect_ex((ip,port))
if (c==0):
print ("%s:%s is open" % (ip,port))
else:
# print "%s:%s is not open" % (ip,port)
pass
except:
pass
def somain(ip,spo,epo):
threads = []
threads_count = 100 # 线程数,默认 100
queue_s = queue.Queue()
#ip=ip
try:
for i in range(spo,epo+1): # 默认扫描1-1000的端口,可以手动修改这里的端口范围
queue_s.put(i) # 使用 queue.Queue().put() 方法将端口添加到队列中
for i in range(threads_count):
threads.append(sorun(queue_s,ip)) # 扫描的端口依次添加到线程组
for i in threads:
i.start()
for i in threads:
i.join()
except:
pass
def nmscan(hosts,port):
nm = nmap.PortScanner()
nm.scan(hosts=hosts, arguments=' -v -sS -p '+port)
try:
for host in nm.all_hosts():
print('----------------------------------------------------') #输出主机及主机名
print('Host : %s (%s)' % (host, nm[host].hostname())) #输出主机状态,如up、down
print('State : %s' % nm[host].state())
for proto in nm[host].all_protocols(): #遍历扫描协议,如tcp、udp
print('----------') #输入协议名
print('Protocol : %s' % proto) #获取协议的所有扫描端口
lport = nm[host][proto].keys() #端口列表排序
list(lport).sort() #遍历端口及输出端口与状态
for port in lport:
print('port : %s\tstate : %s' % (port, nm[host][proto][port]['state']))
except:
pass
def regex(response, port):
text = ""
if re.search(b'<title>502 Bad Gateway', response):
proto = {"Service failed to access!!"}
for pattern in SIGNS:
pattern = pattern.split(b'|')
if re.search(pattern[-1], response, re.IGNORECASE):
proto = "["+port+"]" + " open " + pattern[1].decode()
break
else:
proto = "["+port+"]" + " open " + "Unrecognized"
print(proto)
def request(ip,port):
response = ''
PROBE = 'GET / HTTP/1.0\r\n\r\n'
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(10)
result = sock.connect_ex((ip, int(port)))
if result == 0:
try:
sock.sendall(PROBE.encode())
response = sock.recv(256)
print(response)
if response:
regex(response, port)
except ConnectionResetError:
pass
else:
pass
sock.close()
def fwmain(ip,port):
print("Scan report for "+ip+"\n")
for line in port.split(','):
request(ip,line)
time.sleep(0.2)
print("\nScan finished!....\n")
运行演示和代码地址
运行演示如下图
代码地址:https://github.com/twsec-pro/twsecBS
基于Python的渗透测试信息收集系统的设计和实现的更多相关文章
- 渗透测试-信息收集-c段收集
平时做渗透测试我比较喜欢用lijiejie 写的 subDomainsBrute来爆破子域名 那么爆破完成后就想收集一下网站的c段信息 下面以平安为例 爆破得到子域名为 i.pingan.com.cn ...
- Python:渗透测试开源项目
Python:渗透测试开源项目[源码值得精读] sql注入工具:sqlmap DNS安全监测:DNSRecon 暴力破解测试工具:patator XSS漏洞利用工具:XSSer Web服务器压力测试工 ...
- GyoiThon:基于机器学习的渗透测试工具
简介 GyoiThon是一款基于机器学习的渗透测试工具. GyoiThon根据学习数据识别安装在Web服务器上的软件(操作系统,中间件,框架,CMS等).之后,GyoiThon为已识别的软件执行有效的 ...
- 首款中文渗透测试专用Linux系统—MagicBox
1. MagicBox的介绍 首款中文渗透测试专用Linux系统——MagicBox即将问世,中文名称:“魔方系统”,开发代号:Genesis.第一版本发布时间计划为2012年12月5日 这是 ...
- 基于Python的XSS测试工具XSStrike使用方法
基于Python的XSS测试工具XSStrike使用方法 简介 XSStrike 是一款用于探测并利用XSS漏洞的脚本 XSStrike目前所提供的产品特性: 对参数进行模糊测试之后构建合适的payl ...
- 《Spring_Four》第三次作业——基于Jsoup的大学生考试信息展示系统的原型设计与开发
<Spring_Four团队>第三次团队项目——基于Jsoup的大学生考试信息展示系统的原型设计与开发 一.实验目的与要求 (1)掌握软件原型开发技术: (2)学习使用软件原型开发工具:本 ...
- 基于B/S架构的在线考试系统的设计与实现
前言 这个是我的Web课程设计,用到的主要是JSP技术并使用了大量JSTL标签,所有代码已经上传到了我的Github仓库里,地址:https://github.com/quanbisen/online ...
- 渗透测试之信息收集(Web安全攻防渗透测试实战指南第1章)
收集域名信息 获得对象域名之后,需要收集域名的注册信息,包括该域名的DNS服务器信息和注册人的联系方式等. whois查询 对于中小型站点而言,域名所有人往往就是管理员,因此得到注册人的姓名和邮箱信息 ...
- 内网渗透之信息收集-windows系统篇
windows 用户相关 query user #查看当前在线的用户 whoami #查看当前用户 net user #查看当前系统全部用户 net1 user #查看当前系统全部用户(高权限命令) ...
随机推荐
- react开发教程(三)组件的构建
什么是组件 组件化就好像我们的电脑装机一样,一个电脑由显示器.主板.内存.显卡.硬盘,键盘,鼠标.... 组件化开发有如下的好处:降低整个系统的耦合度,在保持接口不变的情况下,我们可以替换不同的组件快 ...
- 每天找回一点点之MD5加密算法
之前在做项目的时候用户密码都进行了MD5的加密,今天突然想起来了总结一下(●'◡'●) 一.MD5是什么? MD5信息摘要算法(英语:MD5 Message-Digest Algorithm),一种被 ...
- [源码解析] TensorFlow 分布式环境(8) --- 通信机制
[源码解析] TensorFlow 分布式环境(8) --- 通信机制 目录 [源码解析] TensorFlow 分布式环境(8) --- 通信机制 1. 机制 1.1 消息标识符 1.1.1 定义 ...
- hyperledger 儿童车级开发项目实战----投票系统(1)
今天根据hyperledger 企业级开发项目实战视频,自己做了一个投票demo.在这做个记录 首先编写智能合约 在$GOPATH的的src路径下创建项目的名称,我的是mkdir vote 然后创建c ...
- Spring集成web环境(使用封装好的工具)
接上文spring集成web环境(手动实现) ##########代码接上文############# spring提供了一个监听器ContextLoaderListener对上述功能的封装,该监听器 ...
- 使用java生成备份sqlserver数据表的insert语句
针对sqlserver数据表的备份工具很多,有时候条件限制需要我们自己生成insert语句,以便后期直接执行这些插入语句.下面提供了一个简单的思路,针对mysql或oracle有兴趣的以后可以试着修改 ...
- 启动jar包的shell脚本
在jar包的同级目录新建文件例如:app_jar.sh 然后填写如下内容: #!/bin/bash #source /etc/profile # Auth:Liucx # Please change ...
- vue滚动分页加载
做了一个项目,要求将后台数据滚动加载. 滚动加载必须要求后台传的接口中由pageSize和pageIndex两个参数,来判断每次传数据的条数和数据的页码. 首先要判断滑轮是向上滚动还是向下滚动,可以在 ...
- .NET 7 Preview 3添加了这些增强功能
.NET 7 Preview 3 已发布, .NET 7 的第三个预览版包括对可观察性.启动时间.代码生成.GC Region.Native AOT 编译等方面的增强. 有兴趣的用户可以下载适用于 W ...
- Vue生产环境调试的方法
vue 生产环境默认是无法启用vue devtools的,如果生产应用出了问题,就很难解决.. 原理 先说下vue如何判断devtools是否可用的. vue devtools扩展组件会在window ...