五年经验的前端社招被问:CPU 和 GPU 到底有啥区别?
首先来看 CPU 和 GPU 的百科解释:
CPU(Central ProcessingUnit,中央处理器):功能主要是解释计算机指令以及处理计算机软件中的数据

GPU(Graphics ProcessingUnit,图形处理器;又称显示核心、显卡、视觉处理器、显示芯片或绘图芯片):GPU 不同于传统的 CPU,如Intel i5 或 i7 处理器,其内核数量较少,专为通用计算而设计。相反,GPU是一种特殊类型的处理器,具有数百或数千个内核,经过优化,可并行运行大量计算。虽然 GPU 在游戏中以 3D 渲染而闻名,但它们对运行分析、深度学习和机器学习算法尤其有用。GPU 允许某些计算比传统 CPU 上运行相同的计算速度快 10 倍至 100 倍。

CPU 和 GPU 之所以大不相同,是由于其设计目标的不同,它们分别针对了两种不同的应用场景:
- CPU 需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理。这些都使得 CPU 的内部结构异常复杂
- 而 GPU 面对的则是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境
于是 CPU 和 GPU 就呈现出非常不同的架构(如下图 1-3 所示,图片来源 Nvidia),其中 GPU 部分的绿色是计算单元(ALU),橙红色是存储单元(Cache),橙黄色是控制单元(Control),DRAM 代表内存:
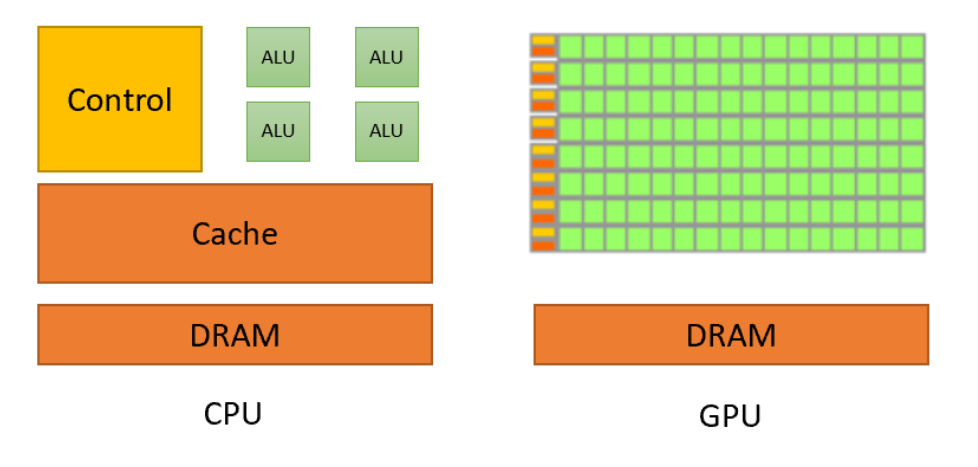
由上图 1-3 可以看出:GPU 采用了数量众多的计算单元和超长的流水线,但只有非常简单的控制逻辑并省去了 Cache。而 CPU 不仅被 Cache 占据了大量空间,而且还有有复杂的控制逻辑和诸多优化电路,相比之下计算能力只是 CPU 很小的一部分。
由此我们引出 CPU 和 GPU 的设计目标:
1)CPU 是基于低延迟(Low Latency)的设计,内核数量较少
- Powerful ALU(强大的算术运算单元):它可以在很少的时钟周期内完成算术计算;
- Large Caches(大的缓存):将部分数据保存在缓存中,使得长延迟的内存访问转换称短延迟的缓存访问;
- Sophisticated Control(复杂的逻辑控制单元):当程序含有多个分支的时候,它通过提供分支预测的能力来降低分支延时;并且,当一些指令依赖前面的指令结果时,它通过提供尽可能快的数据转发的能力来减少数据延迟。
2)GPU 是基于大吞吐量(Big Throughput)的设计,内核数量较多
Small Caches(小的缓存):GPU 中缓存的目的不是保存后面需要访问的数据的,这点和 CPU 不同,而是为 Thread 提供服务的。如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问内存。但是由于需要访问内存,自然会带来延时的问题;
批量读取/访问,一个非常常见的提升吞吐量的设计,比如 Kafka 中就用到了类似思想
Simple Control(简单的逻辑控制单元):把多个的访问合并成少的访问;
Energy efficient ALUs(大量的算术运算单元):如上所述,GPU 虽然有内存延时,却有非常多的 ALU 并支持非常多的 Thread,因此,可以充分利用 ALU 尽可能多地分配线程从而达到非常大的吞吐量。
总结来说,作为强大的执行引擎,CPU 将它数量相对较少的内核集中用于处理单个任务,并快速将其完成。这使它尤其适合用于处理逻辑控制、串行计算、数据库运行等类型的工作。
相比之下,GPU 由数百个内核组成,可以同时处理数千个线程,所以与 CPU 擅长、串行的运算和通用类型数据运算不同,GPU 擅长的是大规模并发计算,将复杂的问题分解成数千或数百万个独立的任务,并一次性解决它们,比如图像处理任务,包括纹理、灯光和形状渲染等子任务都必须同时完成,以保持图像在屏幕上快速呈现,除此之外,GPU 还被大量应用于深度学习、密码破解等任务中。
表 1.1 CPU 和 GPU 的区别
| CPU | GPU |
|---|---|
| Several cores | Many cores |
| Low latency | High throughput |
| Good for serial processing | Good for parallel processing |
| Can do a handful of operations at once | Can do thousands of operations at once |
下面用一个通俗的例子来做个比喻:
注意只是比喻,可能不会太恰当,主要是帮助理解
假设我们需要做一道鸡兔同笼的小学奥数题(来源 1500 年前的《孙子算经》):
- 今有雉兔同笼,上有三十五头,下有九十四足,问雉兔各几何?
计算题目,理解题目并且整理出解题的步骤以及解法,这是 CPU 干的事情,于是 CPU 给出了类似下面的二元一次方程:
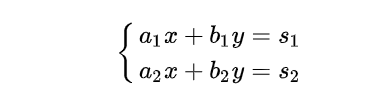
解题的过程需要用到的众多计算,则需要一帮不需要很高逻辑理解力的计算者完成,他们只需要负责其中很简单但是数量又很大的简单运算就行了,最后他们把各自运算的结果交出来给 CPU 整理,那么这群计算者就是 GPU。
简单来说就是:
- CPU 力气大啥事都能干,还要协调手下各类小弟;
- GPU 就是 CPU 的其中一个小弟,老大分配给给他处理图形或者并行计算等任务,这方面处理简单,但是量大,老大虽然能处理,可是精力有限(指 CPU 内核数量较少),所以不如交给小弟处理了,小弟精力旺盛(指 GPU 拥有大量内核),而且专门干这行,非常有经验,干起活儿来贼快。
本文首发于公众号@飞天小牛肉,阿里云 & InfoQ 签约作者,分享大厂面试原创题解和个人成长经验,觉得有用的小伙伴点点关注呀~
五年经验的前端社招被问:CPU 和 GPU 到底有啥区别?的更多相关文章
- 前端深入之css篇|link和@import到底有什么区别?
写在前面 在真正的前端开发中,我们很少去写行内样式和内嵌样式,通常都是去引用外部样式. 而在我们学习之初的外部样式表都是用link引入的,但是当后来我们学习的逐渐深入,发现@import也可以引入样式 ...
- 写在19年初的后端社招面试经历(两年经验): 蚂蚁 头条 PingCAP
去年(18年)年底想出来看看机会,最后很幸运地拿到了 PingCAP,今日头条的 offer 以及蚂蚁金服的口头 offer.想着可以总结一下经验,分享一下自己这一段"骑驴找马"过 ...
- Offer经验分享 - 蚂蚁金服、字节跳动、PDD、百度、华为、Paypal - Java社招面经
年中的时候因为换工作的缘故,陆续参加了华为.蚂蚁.字节跳动.PDD.百度.Paypal的社招面试,除了字节跳动流程较长,我主动结束面试以外,其他的都顺利拿到了Offer. 最近时间稍微宽裕点了,写个面 ...
- 【社招】来杭州吧,阿里国际UED招前端~~
来杭州吧,阿里国际UED招前端~~ 依稀记得,几年前在北京的日子,两点一线的生活方式,似乎冲淡模糊了身边的一切,印象最深刻的莫过于北京的地铁站了吧(因为只有等地铁,搭地铁的时候,才能够停下脚步,静静地 ...
- 你不知道的腾讯社招面试经验(已offer)
# 你不知道的腾讯社招面试经验(已offer) ## 背景 最近一段时间换工作,成功获得了腾讯的offer.在这里有点经验跟大家分享,我觉得,比起具体的面试题,有些东西更加重要,你知道这些东西,再去准 ...
- 阿里巴巴前端面试分享-社招(p6)
借鉴了朋友的阿里面试经:(社招前端2年经验) 电话面 简单自我介绍, 做过哪些项目, 使用哪些技术栈 ? 如何看待前端框架选型 ? vue的如何实现双向绑定的 ? react 虚拟DOM 是什么? 如 ...
- 【北京/上海/南京】【部门直推】【可查询】【实习&社招】字节跳动数据平台前端内推
[北京/上海/南京][部门直推][可查询][实习&社招]字节跳动数据平台前端内推 重要信息,写在前面 [投递邮箱]chengxinsong@bytedance.com [微信扫码] 2019 ...
- 朋友的一年工作经验跳槽字节跳动社招经历分享(已拿offer)
虽然已经临近年末,但是还是萌生要看新机会的想法,主要的原因是觉得在目前的岗位上技术增长遇到的瓶颈,因此想去做一些更有挑战的工作.因为仍然准备继续在深圳工作,因此选定了三家公司,腾讯.字节跳动和 sho ...
- 平安银行Java面试-社招-五面(2019/09)
个人情况 2017年毕业,普通本科,计算机科学与技术专业,毕业后在一个二三线小城市从事Java开发,2年Java开发经验.做过分布式开发,没有高并发的处理经验,平时做To G的项目居多.写下面经是希望 ...
- 回答阿里社招面试如何准备,顺便谈谈对于Java程序猿学习当中各个阶段的建议
引言 其实本来真的没打算写这篇文章,主要是LZ得记忆力不是很好,不像一些记忆力强的人,面试完以后,几乎能把自己和面试官的对话都给记下来.LZ自己当初面试完以后,除了记住一些聊过的知识点以外,具体的内容 ...
随机推荐
- 初试 Centos7 上 Ceph 存储集群搭建
转载自:https://cloud.tencent.com/developer/article/1010539 1.Ceph 介绍 Ceph 是一个开源的分布式存储系统,包括对象存储.块设备.文件系统 ...
- day04-MySQL常用函数01
5.MySQL常用函数 5.1合计/统计函数 5.1.1合计函数-count count 返回行的总数 Select count(*)|count (列名) from table_name [WHER ...
- ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码) ASCII简介 ASCII(American Standard ...
- KTV和泛型(3)
泛型除了KTV,还有一个让人比较疑惑的玩意,而且它就是用来表达疑惑的:? 虽然通过泛型已经达到我们想要的效果了,例如: List<String> list = new ArrayList& ...
- HTML基础知识(3)浮动、塌陷问题
1.浮动 1.1 代码 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> & ...
- 齐博x1当前URL标签
当前URL标签 {:get_url('location')} 当前URL的二维码标签 {:urls('index/qrcode/index')}?url={:urlencode(get_url('lo ...
- 记一次 .NET 某娱乐聊天流平台 CPU 爆高分析
一:背景 1.讲故事 前段时间有位朋友加微信,说他的程序直接 CPU=100%,每次只能手工介入重启,让我帮忙看下到底怎么回事,哈哈,这种CPU打满的事故,程序员压力会非常大, 我让朋友在 CPU 高 ...
- Codeforces Round #816 (Div. 2)/CodeForces1715
CodeForces1715 Crossmarket 解析: 题目大意 有一个 \(n \times m\) 的空间,Stanley 需要从左上角到右下角:Megan 则需要从左下角到右上角.两人可以 ...
- 聊聊GPU与CPU的区别
目录 前言 CPU是什么? GPU是什么? GPU与CPU的区别 GPU的由来 并行计算 GPU架构优化 GPU和CPU的应用场景 作者:小牛呼噜噜 | https://xiaoniuhululu.c ...
- 如何正确遵守 Python 代码规范
前言 无规矩不成方圆,代码亦是如此,本篇文章将会介绍一些自己做项目时遵守的较为常用的 Python 代码规范. 命名 大小写 模块名写法: module_name 包名写法: package_name ...