05安装一个Hadoop分布式集群
安装一个Hadoop分布式集群
最小化的Hadoop已经可以满足学习过程中大部分需求,但是为了研究Hadoop集群运行机制,部署一个类生产的环境还是有必要的。因为集群机器比较少,笔者没有配置ssh,所以就需要在每一台机器上手动启动服务。启动上相对繁琐一些,优点是可以高度自定义集群中的任务节点数量,从而更好的理解集群中各个进程的作用。
一、环境准备
笔者认为一个Hadoop集群管理着两种资源,计算资源(CPU和内存)与存储资源(数据存储)。所以就对应了两类服务,yarn和HDFS:
yarn resourcemanager:资源管理器,负责管理nodemanager、调度集群资源
yarn nodemanager:节点管理器,管理物理机器上的CPU和内存,一个集群可以有多个节点
HDFS namenode:HDFS namenode节点,管理文件系统元数据
HDFS datanode:HDFS datanode节点,存储文件数据块
historyserver:历史作业查询服务,用于查询已经结束的任务运行期间数据
yarn之后会进行介绍,这里只需要知道它和HDFS一样,有两种服务:resourcemanager和nodemanager,resourcemanager类似HDFS的namenode节点,nodemanager类似HDFS的datanode节点。
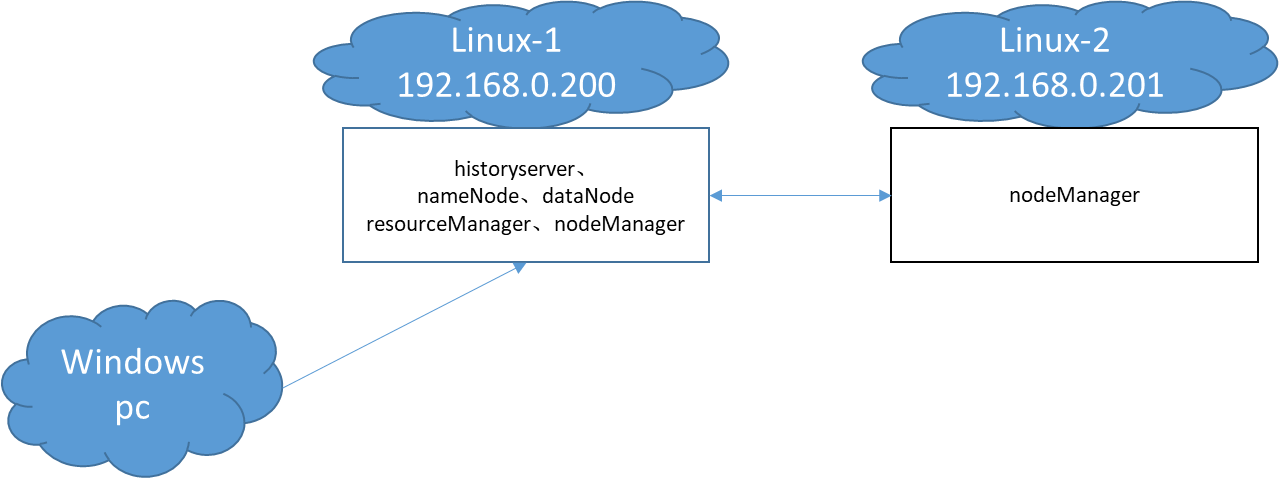
我的集群使用了2个虚拟机,debian系统,8G内存,并且安装了JDK1.8。这样我就有3台机器,分别是客户机Windows,Linux-1和Linux-2。Linux-1运行了集群全套的服务,Linux-2负责运行一个nodemanager节点,模拟被resourcemanager调度。
Linux-1和Linux-2的完整情况如下:
| Linux-1 | Linux-2 | |
|---|---|---|
| IP地址 | 192.168.0.200 | 192.168.0.201 |
| resourcemanager | 运行 | |
| nodemanager | 运行 | 运行 |
| namenode | 运行 | |
| datanode | 运行 | |
| historyserver | 运行 |
整个集群的网络需要能够互相访问,其他无特殊要求,系统拓扑如下:
二、配置文件结构
1、配置文件结构简介
一个配置文件结构如下:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>my.host</name>
<value>192.168.0.200</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://${my.host}:8082/</value>
</property>
</configuration>
一个配置文件的根节点是configuration,一般包含多个property节点,而一个property节点就是一个配置参数。property节点有name和value两个属性,分别是配置名称和值。
如果存在多个同名的property节点,后一个property节点会覆盖前一个。property节点的value支持${}占位符,运行的时候占位符会被解析为实际的值。
2、Hadoop配置
Hadoop有上百个配置,分为默认配置和自定义配置两类。如果某个参数在自定义配置没有,则会加载默认配置,所以我们只需要在自定义配置中加入少量的参数就可以运行集群。
可以在以下网址查询到Hadoop的默认配置:
自定义配置位于Hadoop安装目录下的etc/hadoop下,对应的4个自定义配置文件,名称分别为core-site.xml、yarn-site.xml、mapred-site.xml、hdfs-site.xml
三、安装和配置集群
1、修改配置文件
从https://hadoop.apache.org/releases.html下载Hadoop程序。这里我下载的是2.10.2。分别解压到Linux-1和Linux-2上,解压后程序目录如下:
drwxr-xr-x 2 debian debian 4096 5月 25 2022 bin
drwxr-xr-x 3 debian debian 4096 5月 25 2022 etc
drwxr-xr-x 2 debian debian 4096 5月 25 2022 include
drwxr-xr-x 3 debian debian 4096 5月 25 2022 lib
drwxr-xr-x 2 debian debian 4096 5月 25 2022 libexec
-rw-r--r-- 1 debian debian 106210 5月 25 2022 LICENSE.txt
drwxr-xr-x 3 debian debian 4096 2月 4 17:05 logs
-rw-r--r-- 1 debian debian 15830 5月 25 2022 NOTICE.txt
-rw-r--r-- 1 debian debian 1366 5月 25 2022 README.txt
drwxr-xr-x 3 debian debian 4096 5月 25 2022 sbin
drwxr-xr-x 4 debian debian 4096 5月 25 2022 share
etc/hadoop为程序配置文件存放配置,我们需要在每一个节点创建4个文件core-site.xml、yarn-site.xml、mapred-site.xml、hdfs-site.xml。
笔者的配置完整内容如下:
core-site.xml
my.host需要配置成当前主机实际的地址。my.namenode.host、my.resourcemanager.host、my.jobhistory.host分别配置为:HDFS namenode运行地址、yarn资源管理器运行地址、历史作业查询服务jobhistory运行地址。这里提一下fs.defaultFS,它的含义是HDFS的namenode地址,HDFS的datanode通过这个地址来发现namenode,同时这个地址也是默认文件系统地址,用于解析相对的文件路径。
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 当前主机地址,修改成Linux-1或Linux-2实际的IP地址 -->
<property>
<name>my.host</name>
<value>192.168.0.200</value>
</property>
<!-- dfs namenode所在地址 -->
<property>
<name>my.namenode.host</name>
<value>192.168.0.200</value>
</property>
<!-- yarn 资源管理器所在地址 -->
<property>
<name>my.resourcemanager.host</name>
<value>192.168.0.200</value>
</property>
<!-- 作业历史所在地址 -->
<property>
<name>my.jobhistory.host</name>
<value>192.168.0.200</value>
</property>
<!-- 文件系统地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://${my.namenode.host}:8082/</value>
</property>
</configuration>
yarn-site.xml
yarn中机器ip的配置大多数继承于core-site.xml,所以可以直接分发这个文件到各个机器上,唯一需要注意的是yarn.nodemanager.local-dirs参数,这个目录用于存放任务运行过程中的临时文件,通常需要大一点。
<?xml version="1.0"?>
<configuration>
<!-- 资源管理器地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>${my.resourcemanager.host}</value>
</property>
<!-- 资源管理器绑定地址 -->
<property>
<name>yarn.resourcemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
<!-- 节点管理器地址 -->
<property>
<name>yarn.nodemanager.hostname</name>
<value>${my.host}</value>
</property>
<!-- 节点管理器绑定地址 -->
<property>
<name>yarn.nodemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
<!-- 节点管理器临时文件存放路径 -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data1/debian/hadoop-data/nodemanager-local-data</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 节点管理器运行容器最大内存 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4000</value>
</property>
<!-- 节点管理器单个容器分配最大内存 -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>3000</value>
</property>
</configuration>
mapred-site.xml
mapred-site.xml配置只需要配置历史作业查询服务jobhistory运行地址,笔者的这个配置文件参数也来源于core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 历史任务IPC地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>${my.jobhistory.host}:10020</value>
</property>
<!-- 历史任务web服务地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>${my.jobhistory.host}:19888</value>
</property>
</configuration>
hdfs-site.xml
这个配置文件用于控制HDFS的namenode和datanode节点数据存放路径,dfs.namenode.checkpoint.dir控制namenode数据持久化目录,之前提到的HDFS文件系统中的文件元数据就保存在这里。dfs.datanode.data.dir为数据块存放路径,HDFS中的数据块就存放在这里。
这里并没有配置namenode所在地址,datanode是通过core-site.xml的fs.defaultFS中配置的地址寻找namenode的
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 配置namenode数据存储目录 多个逗号分割-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/data1/debian/hadoop-data/namenode-data</value>
</property>
<!-- 配置辅助namenode数据存储目录 多个逗号分割-->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/data1/debian/hadoop-data/namenode-checkpoint-data</value>
</property>
<!-- namenode rpc绑定主机地址 -->
<property>
<name>dfs.namenode.rpc-bind-host</name>
<value>0.0.0.0</value>
</property>
<!-- 配置datanode数据存储目录 多个逗号分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data1/debian/hadoop-data/datanode-data</value>
</property>
<!-- 数据副本数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
2、初始化HDFS nameserver数据目录
一个新的HDFS的namenode类似新硬盘,使用前需要先格式化(初始化数据文件),datanode节点不需要这个操作。一个HDFS的容量大小取决于datanode节点数量,所以也不需要设置HDFS的容量。
在namenode运行的节点,使用如下命令初始化HDFS的数据目录:
bin/hdfs namenode -format
运行完成后在dfs.namenode.name.dir配置的目录会生成namenode所需要的数据文件,里面有一个文件夹current,由于笔者HDFS节点已经运行过一段时间了,所以current中的内容如下:
debian@debian:/data1/debian/hadoop-data/namenode-data$ pwd
/data1/debian/hadoop-data/namenode-data
debian@debian:/data1/debian/hadoop-data/namenode-data$ ll
总用量 8
drwxr-xr-x 2 debian debian 4096 2月 4 15:27 current
-rw-r--r-- 1 debian debian 10 2月 4 15:27 in_use.lock
debian@debian:/data1/debian/hadoop-data/namenode-data$ ll current/
总用量 15396
-rw-r--r-- 1 debian debian 1048576 1月 22 14:20 edits_0000000000000000001-0000000000000000001
-rw-r--r-- 1 debian debian 1048576 1月 22 14:21 edits_0000000000000000002-0000000000000000002
-rw-r--r-- 1 debian debian 1048576 1月 22 14:21 edits_0000000000000000003-0000000000000000003
-rw-r--r-- 1 debian debian 1048576 1月 22 14:29 edits_0000000000000000004-0000000000000000004
-rw-r--r-- 1 debian debian 1048576 1月 24 17:47 edits_0000000000000000005-0000000000000000048
-rw-r--r-- 1 debian debian 1048576 1月 24 18:03 edits_0000000000000000049-0000000000000000061
-rw-r--r-- 1 debian debian 1048576 1月 28 10:01 edits_0000000000000000062-0000000000000000170
-rw-r--r-- 1 debian debian 1048576 2月 2 17:01 edits_0000000000000000171-0000000000000000171
-rw-r--r-- 1 debian debian 1048576 2月 2 21:18 edits_0000000000000000172-0000000000000000482
-rw-r--r-- 1 debian debian 1048576 2月 2 22:32 edits_0000000000000000483-0000000000000000866
-rw-r--r-- 1 debian debian 1048576 2月 2 22:45 edits_0000000000000000867-0000000000000000867
-rw-r--r-- 1 debian debian 1048576 2月 2 23:09 edits_0000000000000000868-0000000000000001143
-rw-r--r-- 1 debian debian 1048576 2月 3 10:50 edits_0000000000000001144-0000000000000001382
-rw-r--r-- 1 debian debian 1048576 2月 4 00:39 edits_0000000000000001383-0000000000000001620
-rw-r--r-- 1 debian debian 1048576 2月 4 17:07 edits_inprogress_0000000000000001621
-rw-r--r-- 1 debian debian 8109 2月 4 00:01 fsimage_0000000000000001382
-rw-r--r-- 1 debian debian 62 2月 4 00:01 fsimage_0000000000000001382.md5
-rw-r--r-- 1 debian debian 10696 2月 4 15:27 fsimage_0000000000000001620
-rw-r--r-- 1 debian debian 62 2月 4 15:27 fsimage_0000000000000001620.md5
-rw-r--r-- 1 debian debian 5 2月 4 15:27 seen_txid
-rw-r--r-- 1 debian debian 214 2月 4 15:27 VERSION
四、启动服务
1、启停脚本说明
进入Hadoop安装目录下的sbin文件夹,主要有3个脚本文件,用于启停集群中各种守护进程,它们分别是
hadoop-daemon.sh
启停HDFS的namenode和datanode,它还有多主机的启停版本hadoop-daemons.sh
yarn-daemon.sh
启停yarn的资源管理器和节点管理器,它还有多主机的启停版本yarn-daemons.sh
mr-jobhistory-daemon.sh
启停历史任务管理服务historyserver
2、启动HDFS
在Linux-1机器上运行如下命令
-- 启动namenode
sbin/hadoop-daemon.sh start namenode
-- 启动datanode
sbin/hadoop-daemon.sh start datanode
使用jps命令可以看到两个进程
debian@debian:~/program/hadoop-2.10.2$ jps
676 NameNode
7846 Jps
733 DataNode
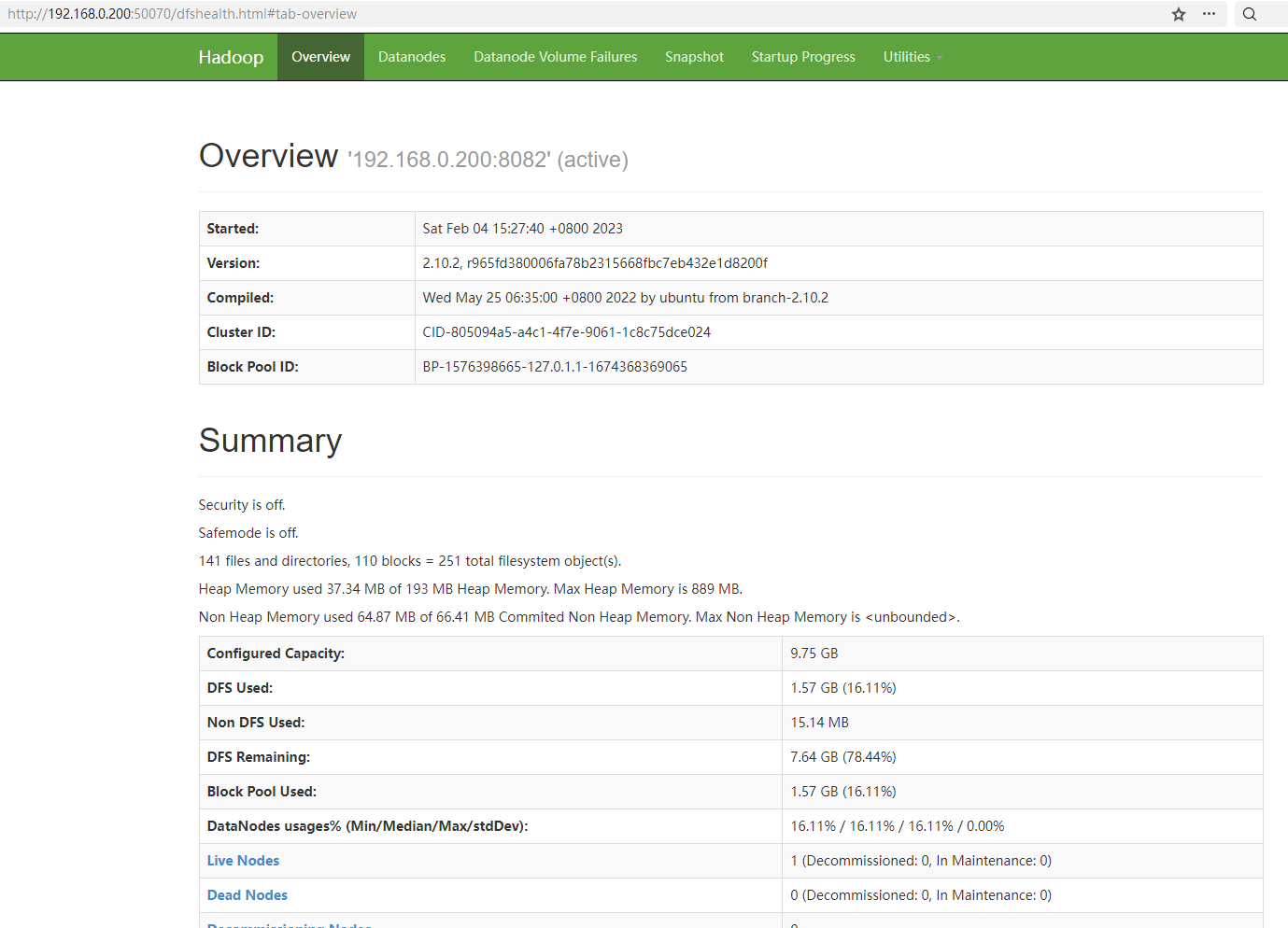
在windows物理机的浏览器输入http://192.168.0.200:50070/可访问HDFS的web管理页面,笔者的显示如下:
3、启动yarn
在Linux-1上输入如下命令启动yarn resourcemanager
-- 启动yarn resourcemanager
sbin/yarn-daemon.sh start resourcemanager
然后在Linux-1和Linux-2启动yarn nodemanager
-- 启动yarn nodemanager
sbin/yarn-daemon.sh start nodemanager
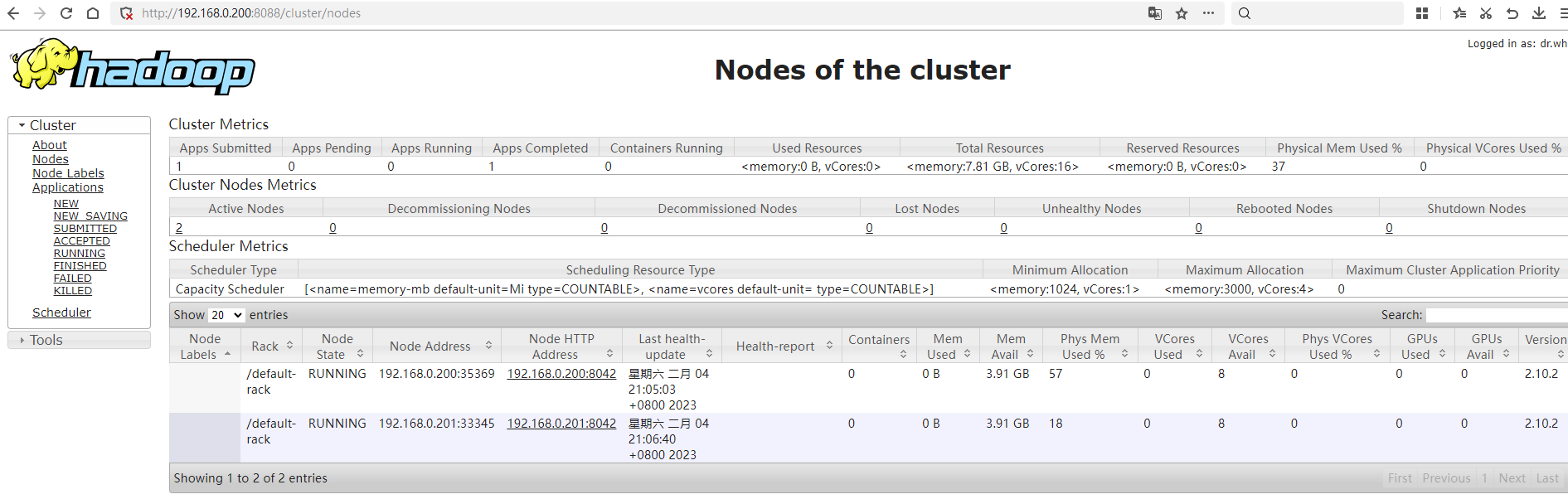
访问yarn的web管理地址http://192.168.0.200:8088/,可以看到当前集群下有两个资源管理器
4、启动历史作业查询服务
在Linux-1运行如下命令启动:
sbin/mr-jobhistory-daemon.sh start historyserver
访问可以看到http://192.168.0.200:19888,如下界面:

五、在集群运行一个MapReduce作业
本文所有的代码放在我的github上,地址是:https://github.com/xunpengliu/hello-hadoop 。本节需要用到的模块是maxSaleMapReduce。任务用到的数据文件可以用common模块中的SaleDataGenerator可以生成。
1、编写任务配置
为了让任务运行在Hadoop集群上,我们需要编写一个配置文件cluster-config.xml。需要注意的是yarn.resourcemanager.hostname配置,很多书籍或其他资料配置的是yarn.resourcemanager.address,因为笔者提交作业是在windows上提交的,作业使用的配置是Hadoop默认配置,如果不配置yarn.resourcemanager.hostname,那么yarn.resourcemanager.resource-tracker.address的值就是0.0.0.0:8031(默认${yarn.resourcemanager.hostname}:8031),导致ApplicationMasters进程无法连上yarn resourcemanager。
如果需要跨平台,也就是提交作业的系统和集群运行的系统不一样,需要把mapreduce.app-submission.cross-platform配置成true
其他的配置就没什么特别的了,fs.defaultFS配置成HDFS的namenode的地址。mapreduce执行框架配置成yarn
完整内容如下:
<configuration>
<!-- 跨平台提交 -->
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
<!-- 文件系统地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.0.200:8082/</value>
</property>
<!-- 资源管理器地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.0.200</value>
</property>
<!-- 执行框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- map任务数量 -->
<property>
<name>mapreduce.job.maps</name>
<value>5</value>
</property>
</configuration>
2、准备作业数据文件
任务用到的数据文件可以用common包中的SaleDataGenerator生成,把生成数据文件传到HDFS上的/input目录上,可以用Hadoop的fs命令上传。
hadoop fs -copyFromLocal file-0 hdfs://192.168.0.200:8082/input/file-0
hadoop fs -copyFromLocal file-1 hdfs://192.168.0.200:8082/input/file-1
hadoop fs -copyFromLocal file-2 hdfs://192.168.0.200:8082/input/file-2
hadoop fs -copyFromLocal file-3 hdfs://192.168.0.200:8082/input/file-3
hadoop fs -copyFromLocal file-4 hdfs://192.168.0.200:8082/input/file-4
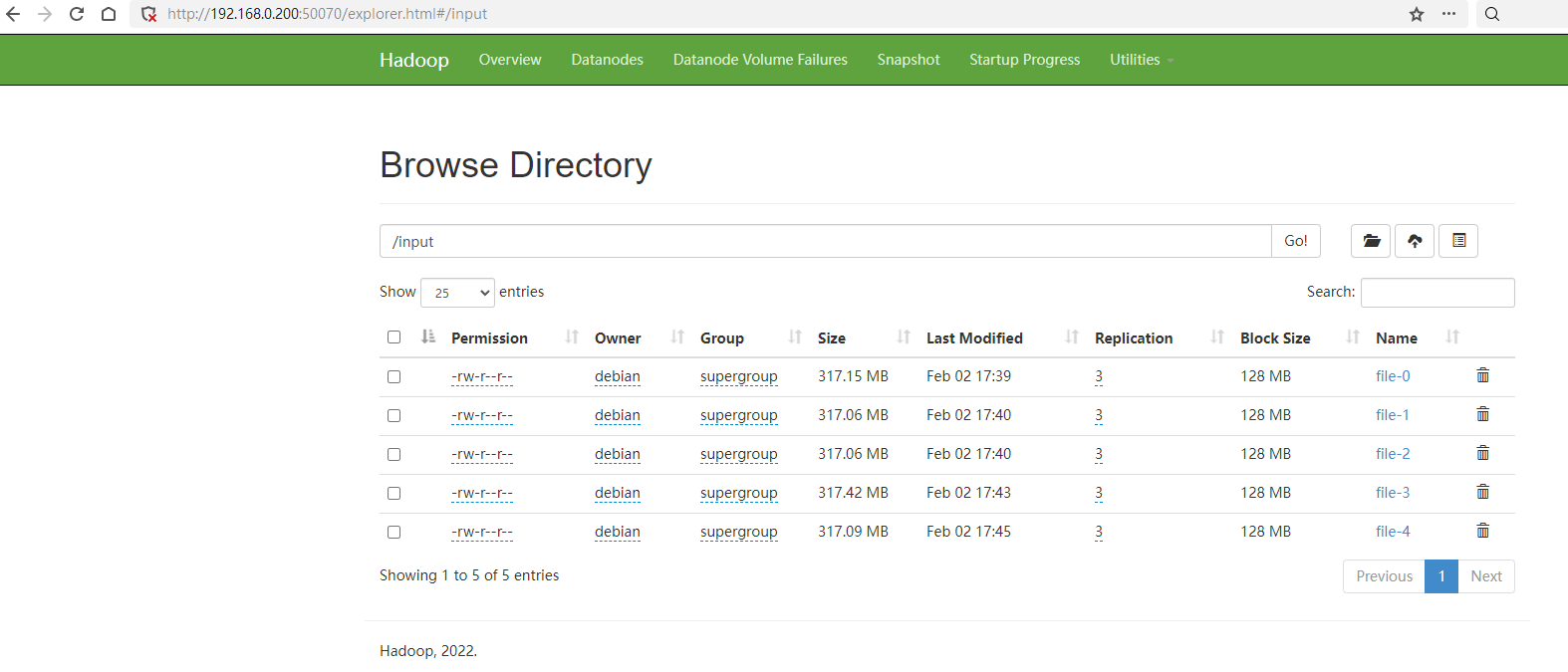
上传完成后可以在HDFS的管理页面中看到文件:
3、启动作业
输入命令启动作业:
hadoop jar maxSaleMapReduce-1.0-SNAPSHOT.jar -conf cluster-config.xml -libjars ./lib/common-1.0-SNAPSHOT.jar /input /output
命令最后的input和output参数分别是数据输入目录和输出目录,由于是相对路径,会自动使用fs.defaultFS配置进行填充,所以相当于hdfs://192.168.0.200:8082/input和hdfs://192.168.0.200:8082/output。
命令执行如下:
C:\Users\l3789\Desktop\新建文件夹>hadoop jar maxSaleMapReduce-1.0-SNAPSHOT.jar -conf cluster-config.xml -libjars ./lib/common-1.0-SNAPSHOT.jar /input /output
23/02/04 21:27:31 INFO client.RMProxy: Connecting to ResourceManager at /192.168.0.200:8032
23/02/04 21:27:41 INFO input.FileInputFormat: Total input files to process : 5
23/02/04 21:27:41 INFO mapreduce.JobSubmitter: number of splits:15
23/02/04 21:27:42 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1675501509686_0002
23/02/04 21:27:42 INFO conf.Configuration: resource-types.xml not found
23/02/04 21:27:42 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
23/02/04 21:27:42 INFO resource.ResourceUtils: Adding resource type - name = memory-mb, units = Mi, type = COUNTABLE
23/02/04 21:27:42 INFO resource.ResourceUtils: Adding resource type - name = vcores, units = , type = COUNTABLE
23/02/04 21:27:42 INFO impl.YarnClientImpl: Submitted application application_1675501509686_0002
23/02/04 21:27:42 INFO mapreduce.Job: The url to track the job: http://192.168.0.200:8088/proxy/application_1675501509686_0002/
23/02/04 21:27:42 INFO mapreduce.Job: Running job: job_1675501509686_0002
23/02/04 21:27:46 INFO mapreduce.Job: Job job_1675501509686_0002 running in uber mode : false
23/02/04 21:27:46 INFO mapreduce.Job: map 0% reduce 0%
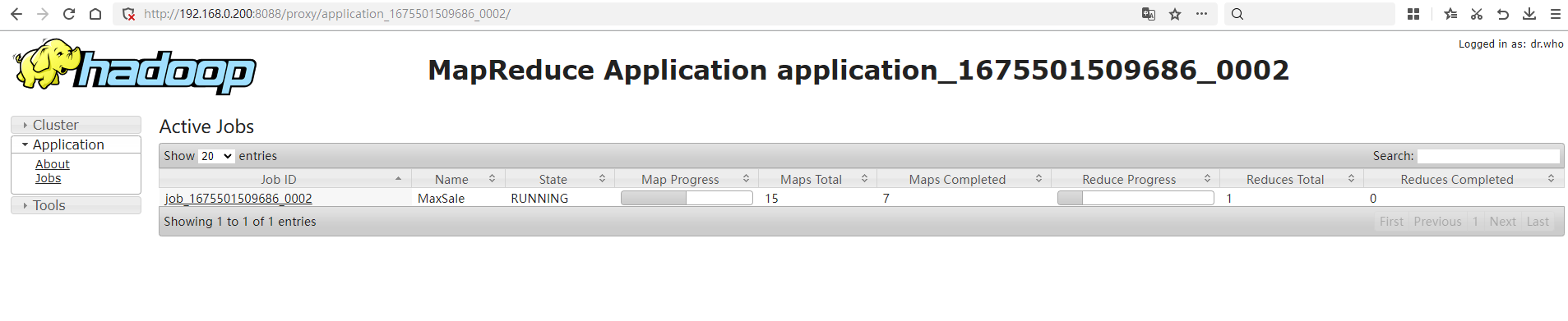
可以访问http://192.168.0.200:8088/proxy/application_1675501509686_0002/查看任务运行情况:
六、常见问题
上传文件到HDFS提示copyFromLocal: Permission denied
这个是因为hadoop命令获取到用户与HDFS上的权限不符,修改环境变量更改运行用户,然后重新执行命令:
-- windows
set HADOOP_USER_NAME=debian
-- linux
export HADOOP_USER_NAME=debian
运行MapReduce作业提示无读写权限
23/02/04 21:34:34 INFO client.RMProxy: Connecting to ResourceManager at /192.168.0.200:8032
Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=test, access=EXECUTE, inode="/tmp":debian:supergroup:drwx------
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:350)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkTraverse(FSPermissionChecker.java:311)
/tmp存放任务运行的历史结果,供historyserver使用。运行任务的用户无写入权限,把这个目录设置成所有人可写,或者修改运行用户为/tmp目录的用户
修改环境变量更改运行用户,然后重新执行命令:
-- windows
set HADOOP_USER_NAME=debian
-- linux
export HADOOP_USER_NAME=debian
运行任务状态一直卡在,任务日志报org.apache.hadoop.ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8031
这个问题卡了我好久,MapReduce任务的ApplicationMasters进程无法连上yarn resourcemanager。根本原因是提交任务的机器使用的yarn.resourcemanager.resource-tracker.address配置是默认的,需要在任务的配置文件中加入yarn.resourcemanager.address配置
05安装一个Hadoop分布式集群的更多相关文章
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- CentOS6安装各种大数据软件 第四章:Hadoop分布式集群配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 使用Docker在本地搭建Hadoop分布式集群
学习Hadoop集群环境搭建是Hadoop入门必经之路.搭建分布式集群通常有两个办法: 要么找多台机器来部署(常常找不到机器) 或者在本地开多个虚拟机(开销很大,对宿主机器性能要求高,光是安装多个虚拟 ...
- 超快速使用docker在本地搭建hadoop分布式集群
超快速使用docker在本地搭建hadoop分布式集群 超快速使用docker在本地搭建hadoop分布式集群 学习hadoop集群环境搭建是hadoop入门的必经之路.搭建分布式集群通常有两个办法: ...
- 大数据系列之Hadoop分布式集群部署
本节目的:搭建Hadoop分布式集群环境 环境准备 LZ用OS X系统 ,安装两台Linux虚拟机,Linux系统用的是CentOS6.5:Master Ip:10.211.55.3 ,Slave ...
- 基于Hadoop分布式集群YARN模式下的TensorFlowOnSpark平台搭建
1. 介绍 在过去几年中,神经网络已经有了很壮观的进展,现在他们几乎已经是图像识别和自动翻译领域中最强者[1].为了从海量数据中获得洞察力,需要部署分布式深度学习.现有的DL框架通常需要为深度学习设置 ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- 暑假第二弹:基于docker的hadoop分布式集群系统的搭建和测试
早在四月份的时候,就已经开了这篇文章.当时是参加数据挖掘的比赛,在计科院大佬的建议下用TensorFlow搞深度学习,而且要在自己的hadoop分布式集群系统下搞. 当时可把我们牛逼坏了,在没有基础的 ...
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
- hadoop分布式集群的搭建
电脑如果是8G内存或者以下建议搭建3节点集群,如果是搭建5节点集群就要增加内存条了.当然实际开发中不会用虚拟机做,一些小公司刚刚起步的时候会采用云服务,因为开始数据量不大. 但随着数据量的增大才会考虑 ...
随机推荐
- python中的if条件语句
# 如果...就... # 1. print('1.') if 1+1 == 2: print('1+1是等于2的') print('1+1还是等于2的') print('1+1就等于2的') # 2 ...
- ES6 学习笔记(三)原始值与引用值
总结: 1.原始值,表示单一的数据,如10,"abc",true等. 1.1. ES的6种原始值: Undefined.Null.Boolean.Number.String.Sym ...
- SpringBoot 02: 初识SpringBoot
1. SpringBoot 产生原因 spring, springmvc框架使用上的一些缺点: 需要使用的大量的配置文件 还需要配置各种对象 需要把使用的对象放入到spring容器中才能使用对象 需要 ...
- C++初阶(类的访问权限以及封装+this指针+构造函数+析构函数+拷贝构造函数+参数列表+友元+内部类)
面向过程与面向对象 C语言是面向过程的,关注的是过程(函数),分析出求解问题的步骤,通过函数调用逐步解决问题. C++是基于面向对象的,关注的是对象,将一件事情拆分成不同的对象,靠对象之间的交互完成. ...
- 某厂面试:如何优雅使用 SPI 机制
代码不多,文章可能有点长.朋友面试某厂问到的 SPI 机制,联想到自己项目最近写到的 SPI 场景,文章简要描述下 SPI 机制的发展历程 产出背景 因为最近项目中使用分库分表以及数据加密使用到了 S ...
- windows10 ftp文件夹错误
遇到问题: 解决办法: 1. cmd直接访问 ftp ip 2. 启用tftp client 从文件夹访问 注直接访问会弹出如之前报错一样的失败:ftp://ip ftp://用户:密码@ip 使用如 ...
- 重新认识下JVM级别的本地缓存框架Guava Cache(2)——深入解读其容量限制与数据淘汰策略
大家好,又见面了. 本文是笔者作为掘金技术社区签约作者的身份输出的缓存专栏系列内容,将会通过系列专题,讲清楚缓存的方方面面.如果感兴趣,欢迎关注以获取后续更新. 通过<重新认识下JVM级别的本地 ...
- Java Web中requset,session,application 的作用域及区别
三者概述 requset概述: request是表示一个请求,只要发出一个请求就会创建一个request 用处:常用于服务器间同一请求不同页面之间的参数传递,常应用于表单的控件值传递. session ...
- [CG] 用 Docker 配置 Ubuntu OpenGL 环境
成功在 MacOS 的 Docker 中运行 OpenGL 程序并显示这里记录一下: 我用的是 https://hub.docker.com/r/thewtex/opengl 这个镜像非常好,大部分工 ...
- X活手环的表盘自定义修改
文章用到的所有工具及软件成品 前言 前几天我在某宝买了一个智能手环,无奈软件中的表盘太少,所有我想着修改一下app中的资源文件. 反编译APK 这里反编译APK用apktool工具就可以. apkto ...