Android IO 框架 Okio 的实现原理,到底哪里 OK?
本文已收录到 AndroidFamily,技术和职场问题,请关注公众号 [彭旭锐] 提问。
前言
大家好,我是小彭。
今天,我们来讨论一个 Square 开源的 I/O 框架 Okio,我们最开始接触到 Okio 框架还是源于 Square 家的 OkHttp 网络框架。那么,OkHttp 为什么要使用 Okio,它相比于 Java 原生 IO 有什么区别和优势?今天我们就围绕这些问题展开。
本文源码基于 Okio v3.2.0。
思维导图
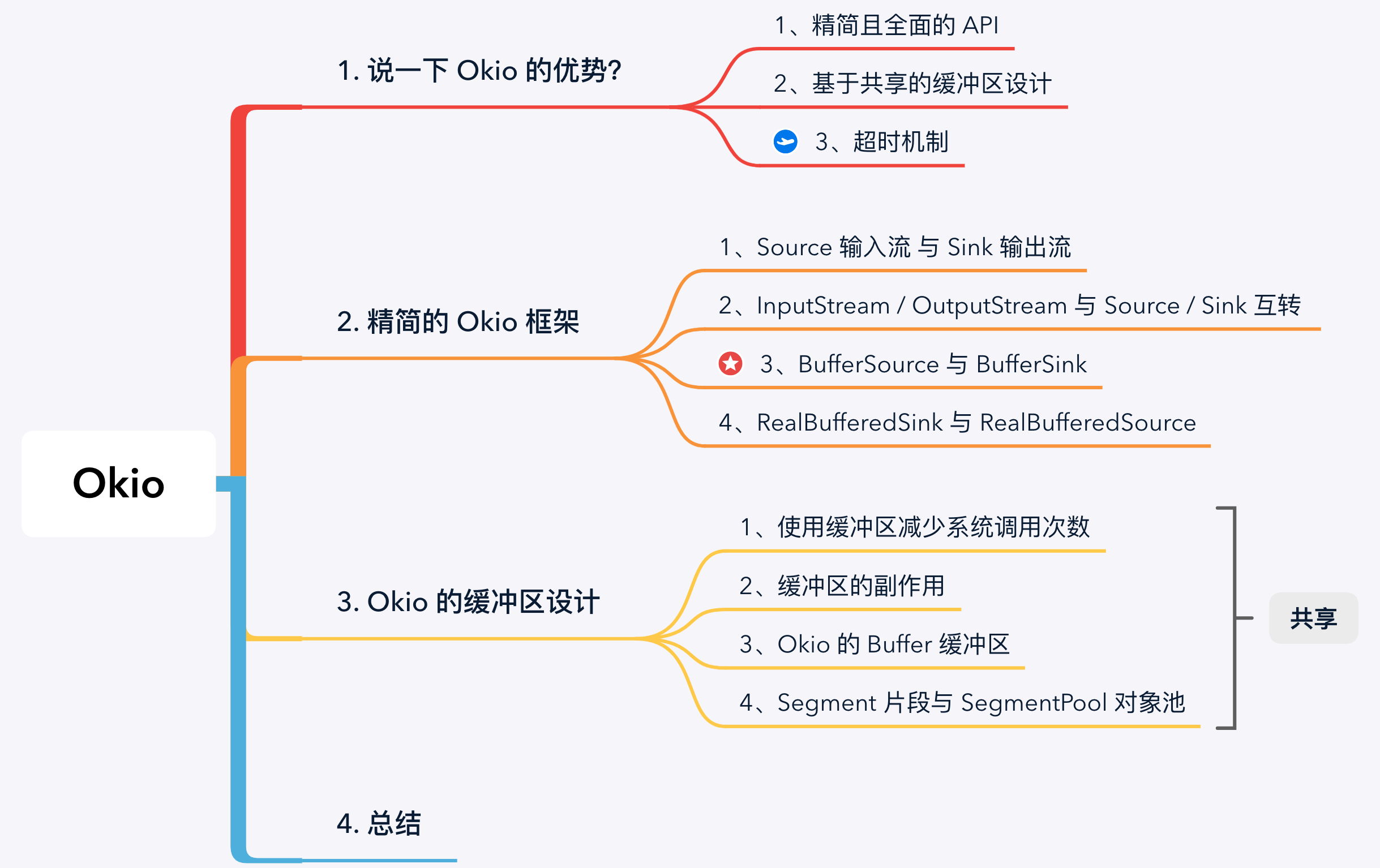
1. 说一下 Okio 的优势?
相比于 Java 原生 IO 框架,我认为 Okio 的优势主要体现在 3 个方面:
1、精简且全面的 API: 原生 IO 使用装饰模式,例如使用 BufferedInputStream 装饰 FileInputStream 文件输入流,可以增强流的缓冲功能。但是原生 IO 的装饰器过于庞大,需要区分字节、字符流、字节数组、字符数组、缓冲等多种装饰器,而这些恰恰又是最常用的基础装饰器。相较之下,Okio 直接在 BufferedSource 和 BufferedSink 中聚合了原生 IO 中所有基础的装饰器,使得框架更加精简;
2、基于共享的缓冲区设计: 由于 IO 系统调用存在上下文切换的性能损耗,为了减少系统调用次数,应用层往往会采用缓冲区策略。但是缓冲区又会存在副作用,当数据从一个缓冲区转移到另一个缓冲区时需要拷贝数据,这种内存中的拷贝显得没有必要。而 Okio 采用了基于共享的缓冲区设计,在缓冲区间转移数据只是共享 Segment 的引用,而减少了内存拷贝。同时 Segment 也采用了对象池设计,减少了内存分配和回收的开销;
3、超时机制: Okio 弥补了部分 IO 操作不支持超时检测的缺陷,而且 Okio 不仅支持单次 IO 操作的超时检测,还支持包含多次 IO 操作的复合任务超时检测。
下面,我们将从这三个优势展开分析:
2. 精简的 Okio 框架
先用一个表格总结 Okio 框架中主要的类型:
| 类型 | 描述 |
|---|---|
| Source | 输入流 |
| Sink | 输出流 |
| BufferedSource | 缓存输入流接口,实现类是 RealBufferedSource |
| BufferedSink | 缓冲输出流接口,实现类是 RealBufferedSink |
| Buffer | 缓冲区,由 Segment 链表组成 |
| Segment | 数据片段,多个片段组成逻辑上连续数据 |
| ByteString | String 类 |
| Timeout | 超时控制 |
2.1 Source 输入流 与 Sink 输出流
在 Java 原生 IO 中有四个基础接口,分别是:
- 字节流:
InputStream输入流和OutputStream输出流; - 字符流:
Reader输入流和Writer输出流。
而在 Okio 更加精简,只有两个基础接口,分别是:
- 流:
Source输入流和Sink输出流。
Source.kt
interface Source : Closeable {// 从输入流读取数据到 Buffer 中(Buffer 等价于 byte[] 字节数组)// 返回值:-1:输入内容结束@Throws(IOException::class)fun read(sink: Buffer, byteCount: Long): Long// 超时控制(详细分析见后续文章)fun timeout(): Timeout// 关闭流@Throws(IOException::class)override fun close()}
Sink.java
actual interface Sink : Closeable, Flushable {// 将 Buffer 的数据写入到输出流中(Buffer 等价于 byte[] 字节数组)@Throws(IOException::class)actual fun write(source: Buffer, byteCount: Long)// 清空输出缓冲区@Throws(IOException::class)actual override fun flush()// 超时控制(详细分析见后续文章)actual fun timeout(): Timeout// 关闭流@Throws(IOException::class)actual override fun close()}
2.2 InputStream / OutputStream 与 Source / Sink 互转
在功能上,InputStream - Source 和 OutputStream - Sink 分别是等价的,而且是相互兼容的。结合 Kotlin 扩展函数,两种接口之间的转换会非常方便:
- source(): InputStream 转 Source,实现类是 InputStreamSource;
- sink(): OutputStream 转 Sink,实现类是 OutputStreamSink;
比较不理解的是: Okio 没有提供 InputStreamSource 和 OutputStreamSink 转回 InputStream 和 OutputStream 的方法,而是需要先转换为 BufferSource 与 BufferSink,再转回 InputStream 和 OutputStream。
- buffer(): Source 转 BufferedSource,Sink 转 BufferedSink,实现类分别是 RealBufferedSource 和 RealBufferedSink。
示例代码
// 原生 IO -> Okioval source = FileInputStream(File("")).source()val bufferSource = FileInputStream(File("")).source().buffer()val sink = FileOutputStream(File("")).sink()val bufferSink = FileOutputStream(File("")).sink().buffer()// Okio -> 原生 IOval inputStream = bufferSource.inputStream()val outputStream = bufferSink.outputStream()
JvmOkio.kt
// InputStream -> Sourcefun InputStream.source(): Source = InputStreamSource(this, Timeout())// OutputStream -> Sinkfun OutputStream.sink(): Sink = OutputStreamSink(this, Timeout())private class InputStreamSource(private val input: InputStream,private val timeout: Timeout) : Source {override fun read(sink: Buffer, byteCount: Long): Long {if (byteCount == 0L) return 0require(byteCount >= 0) { "byteCount < 0: $byteCount" }try {// 同步超时监控(详细分析见后续文章)timeout.throwIfReached()// 读入 Bufferval tail = sink.writableSegment(1)val maxToCopy = minOf(byteCount, Segment.SIZE - tail.limit).toInt()val bytesRead = input.read(tail.data, tail.limit, maxToCopy)if (bytesRead == -1) {if (tail.pos == tail.limit) {// We allocated a tail segment, but didn't end up needing it. Recycle!sink.head = tail.pop()SegmentPool.recycle(tail)}return -1}tail.limit += bytesReadsink.size += bytesReadreturn bytesRead.toLong()} catch (e: AssertionError) {if (e.isAndroidGetsocknameError) throw IOException(e)throw e}}override fun close() = input.close()override fun timeout() = timeoutoverride fun toString() = "source($input)"}private class OutputStreamSink(private val out: OutputStream,private val timeout: Timeout) : Sink {override fun write(source: Buffer, byteCount: Long) {checkOffsetAndCount(source.size, 0, byteCount)var remaining = byteCount// 写出 Bufferwhile (remaining > 0) {// 同步超时监控(详细分析见后续文章)timeout.throwIfReached()// 取有效数据量和剩余输出量的较小值val head = source.head!!val toCopy = minOf(remaining, head.limit - head.pos).toInt()out.write(head.data, head.pos, toCopy)head.pos += toCopyremaining -= toCopysource.size -= toCopy// 指向下一个 Segmentif (head.pos == head.limit) {source.head = head.pop()SegmentPool.recycle(head)}}}override fun flush() = out.flush()override fun close() = out.close()override fun timeout() = timeoutoverride fun toString() = "sink($out)"}
Okio.kt
// Source -> BufferedSourcefun Source.buffer(): BufferedSource = RealBufferedSource(this)// Sink -> BufferedSinkfun Sink.buffer(): BufferedSink = RealBufferedSink(this)
2.3 BufferSource 与 BufferSink
在 Java 原生 IO 中,为了减少系统调用次数,我们一般不会直接调用 InputStream 和 OutputStream,而是会使用 BufferedInputStream 和 BufferedOutputStream 包装类增加缓冲功能。
例如,我们希望采用带缓冲的方式读取字符格式的文件,则需要先将文件输入流包装为字符流,再包装为缓冲流:
Java 原生 IO 示例
// 第一层包装FileInputStream fis = new FileInputStream(file);// 第二层包装InputStreamReader isr = new InputStreamReader(new FileInputStream(file), "UTF-8");// 第三层包装BufferedReader br = new BufferedReader(isr);String line;while ((line = br.readLine()) != null) {...}// 省略 close
同理,我们在 Okio 中一般也不会直接调用 Source 和 Sink,而是会使用 BufferedSource 和 BufferedSink 包装类增加缓冲功能:
Okio 示例
val bufferedSource = file.source()/*第一层包装*/.buffer()/*第二层包装*/while (!bufferedSource.exhausted()) {val line = bufferedSource.readUtf8Line();...}// 省略 close
网上有资料说 Okio 没有使用装饰器模式,所以类结构更简单。 这么说其实不太准确,装饰器模式本身并不是缺点,而且从 BufferedSource 和 BufferSink 可以看出 Okio 也使用了装饰器模式。 严格来说是原生 IO 的装饰器过于庞大,而 Okio 的装饰器更加精简。
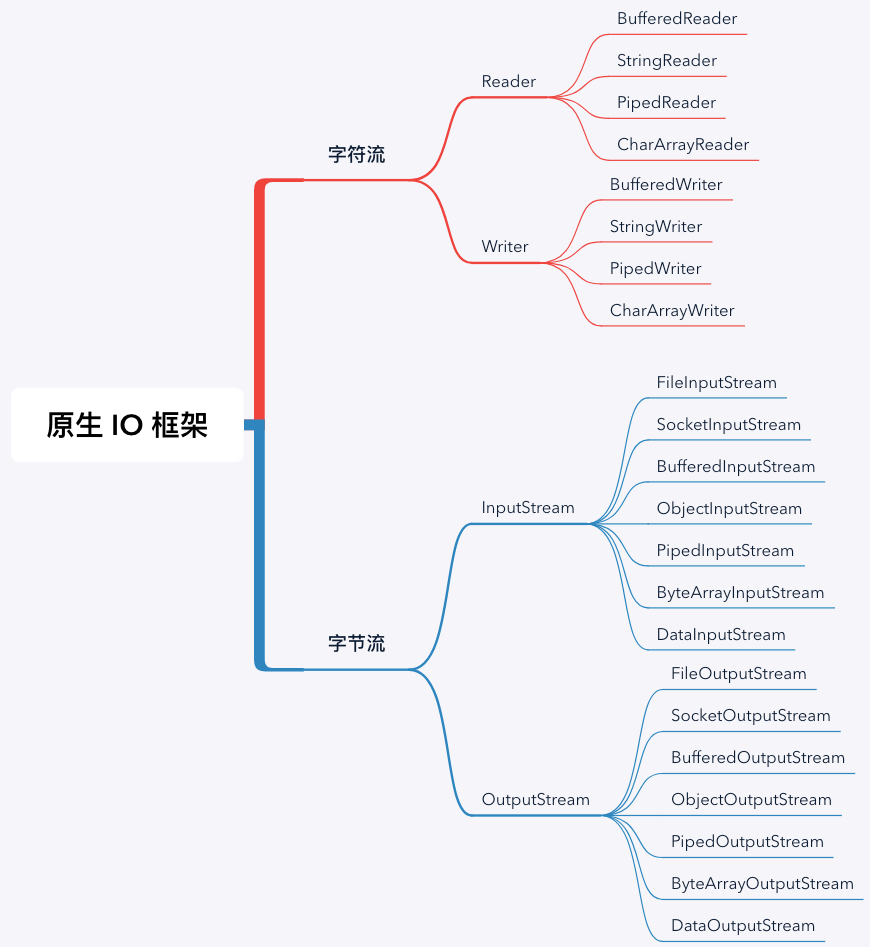
比如原生 IO 常用的流就有这么多:
原始流: FileInputStream / FileOutputStream 与 SocketInputStream / SocketOutputStream;
基础接口(区分字节流和字符流): InputStream / OutputStream 与 Reader / Writer;
缓存流: BufferedInputStream / BufferedOutputStream 与 BufferedReader / BufferedWriter;
基本类型: DataInputStream / DataOutputStream;
字节数组和字符数组: ByteArrayInputStream / ByteArrayOutputStream 与 CharArrayReader / CharArrayWriter;
此处省略一万个字。
原生 IO 框架
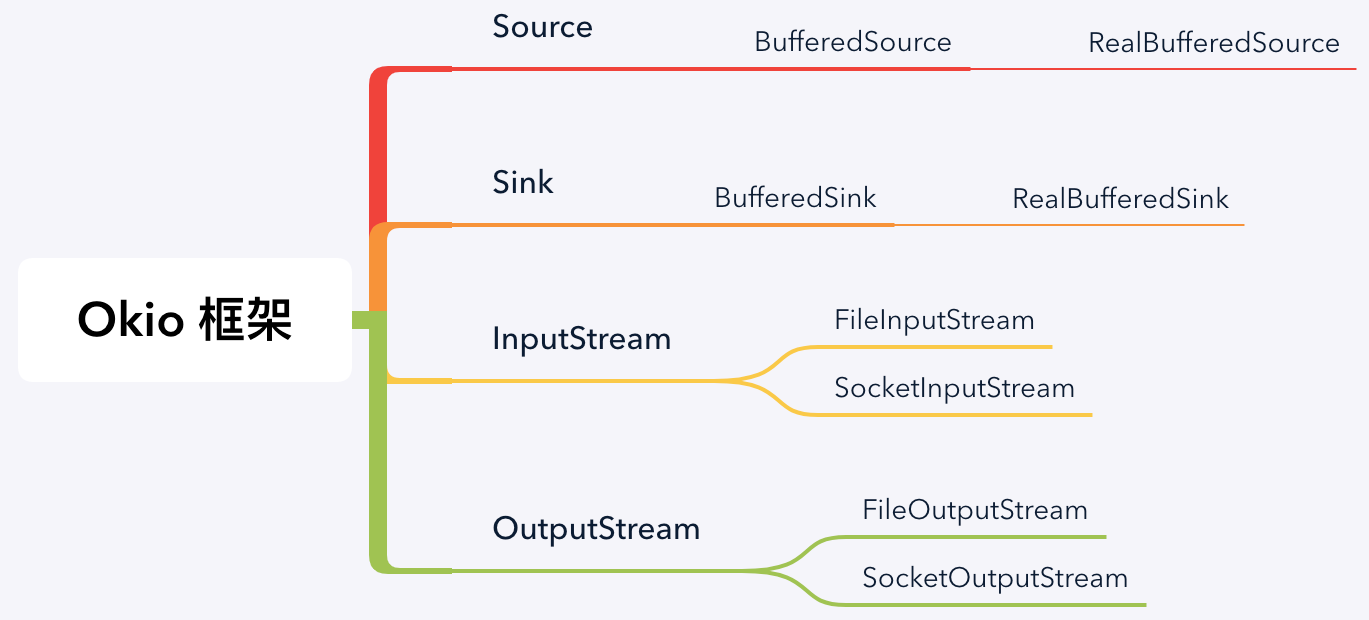
而这么多种流在 Okio 里还剩下多少呢?
- 原始流: FileInputStream / FileOutputStream 与 SocketInputStream / SocketOutputStream;
- 基础接口: Source / Sink;
- 缓存流: BufferedSource / BufferedSink。
Okio 框架
就问你服不服?
而且你看哈,这些都是平时业务开发中最常见的基本类型,原生 IO 把它们都拆分开了,让问题复杂化了。反观 Okio 直接在 BufferedSource 和 BufferedSink 中聚合了原生 IO 中基本的功能,而不再需要区分字节、字符、字节数组、字符数组、基础类型等等装饰器,确实让框架更加精简。
BufferedSource.kt
actual interface BufferedSource : Source, ReadableByteChannel {actual val buffer: Buffer// 读取 Int@Throws(IOException::class)actual fun readInt(): Int// 读取 String@Throws(IOException::class)fun readString(charset: Charset): String...fun inputStream(): InputStream}
BufferedSink.kt
actual interface BufferedSink : Sink, WritableByteChannel {actual val buffer: Buffer// 写入 Int@Throws(IOException::class)actual fun writeInt(i: Int): BufferedSink// 写入 String@Throws(IOException::class)fun writeString(string: String, charset: Charset): BufferedSink...fun outputStream(): OutputStream}
2.4 RealBufferedSink 与 RealBufferedSource
BufferedSource 和 BufferedSink 还是接口,它们的真正的实现类是 RealBufferedSource 和 RealBufferedSink。可以看到,在实现类中会创建一个 Buffer 缓冲区,在输入和输出的时候,都会借助 “Buffer 缓冲区” 减少系统调用次数。
RealBufferedSource.kt
internal actual class RealBufferedSource actual constructor(// 装饰器模式@JvmField actual val source: Source) : BufferedSource {// 创建输入缓冲区@JvmField val bufferField = Buffer()// 带缓冲地读取(全部数据)override fun readString(charset: Charset): String {buffer.writeAll(source)return buffer.readString(charset)}// 带缓冲地读取(byteCount)override fun readString(byteCount: Long, charset: Charset): String {require(byteCount)return buffer.readString(byteCount, charset)}}
RealBufferedSink.kt
internal actual class RealBufferedSink actual constructor(// 装饰器模式@JvmField actual val sink: Sink) : BufferedSink {// 创建输出缓冲区@JvmField val bufferField = Buffer()// 带缓冲地写入(全部数据)override fun writeString(string: String, charset: Charset): BufferedSink {buffer.writeString(string, charset)return emitCompleteSegments()}// 带缓冲地写入(beginIndex - endIndex)override fun writeString(string: String,beginIndex: Int,endIndex: Int,charset: Charset): BufferedSink {buffer.writeString(string, beginIndex, endIndex, charset)return emitCompleteSegments()}}
至此,Okio 基本框架分析结束,用一张图总结:
Okio 框架

3. Okio 的缓冲区设计
3.1 使用缓冲区减少系统调用次数
在操作系统中,访问磁盘和网卡等 IO 操作需要通过系统调用来执行。系统调用本质上是一种软中断,进程会从用户态陷入内核态执行中断处理程序,完成 IO 操作后再从内核态切换回用户态。
可以看到,系统调用存在上下文切换的性能损耗。为了减少系统调用次数,应用层往往会采用缓冲区策略:
以 Java 原生 IO BufferedInputStream 为例,会通过一个 byte[] 数组作为数据源的输入缓冲,每次读取数据时会读取更多数据到缓冲区中:
- 如果缓冲区中存在有效数据,则直接从缓冲区数据读取;
- 如果缓冲区不存在有效数据,则先执行系统调用填充缓冲区(fill),再从缓冲区读取数据;
- 如果要读取的数据量大于缓冲区容量,就会跳过缓冲区直接执行系统调用。
输出流 BufferedOutputStream 也类似,输出数据时会优先写到缓冲区,当缓冲区满或者手动调用 flush() 时,再执行系统调用写出数据。
伪代码
// 1. 输入fun read(byte[] dst, int len) : Int {// 缓冲区有效数据量int avail = count - posif(avail <= 0) {if(len >= 缓冲区容量) {// 直接从输入流读取read(输入流 in, dst, len)}// 填充缓冲区fill(数据源 in, 缓冲区)}// 本次读取数据量,不超过可用容量int cnt = (avail < len) ? avail : len?read(缓冲区, dst, cnt)// 更新缓冲区索引pos += cntreturn cnt}// 2. 输出fun write(byte[] src, len) {if(len > 缓冲区容量) {// 先将缓冲区写出flush(缓冲区)// 直接写出数据write(输出流 out, src, len)}// 缓冲区剩余容量int left = 缓冲区容量 - countif(len > 缓冲区剩余容量) {// 先将缓冲区写出flush(缓冲区)}// 将数据写入缓冲区write(缓冲区, src, len)// 更新缓冲区已添加数据容量count += len}
3.2 缓冲区的副作用
的确,缓冲区策略能有效地减少系统调用次数,不至于读取一个字节都需要执行一次系统调用,大多数情况下表现良好。 但考虑一种 “双流操作” 场景,即从一个输入流读取,再写入到一个输出流。回顾刚才讲的缓存策略,此时的数据转移过程为:
- 1、从输入流读取到缓冲区;
- 2、从输入流缓冲区拷贝到 byte[](拷贝)
- 3、将 byte[] copy 到输出流缓冲区(拷贝);
- 4、将输出流缓冲区写入到输出流。
如果这两个流都使用了缓冲区设计,那么数据在这两个内存缓冲区之间相互拷贝,就显得没有必要。
3.3 Okio 的 Buffer 缓冲区
Okio 当然也有缓冲区策略,如果没有就会存在频繁系统调用的问题。
Buffer 是 RealBufferedSource 和 RealBufferedSink 的数据缓冲区。虽然在实现上与原生 BufferedInputStream 和 BufferedOutputStream 不一样,但在功能上是一样的。区别在于:
1、BufferedInputStream 中的缓冲区是 “一个固定长度的字节数组” ,数据从一个缓冲区转移到另一个缓冲区需要拷贝;
2、Buffer 中的缓冲区是 “一个 Segment 双向循环链表” ,每个 Segment 对象是一小段字节数组,依靠 Segment 链表的顺序组成逻辑上的连续数据。这个 Segment 片段是 Okio 高效的关键。
Buffer.kt
actual class Buffer : BufferedSource, BufferedSink, Cloneable, ByteChannel {// 缓冲区(Segment 双向链表)@JvmField internal actual var head: Segment? = null// 缓冲区数据量@get:JvmName("size")actual var size: Long = 0Linternal setoverride fun buffer() = thisactual override val buffer get() = this}
对比 BufferedInputStream:
BufferedInputStream.java
public class BufferedInputStream extends FilterInputStream {// 缓冲区的默认大小(8KB)private static int DEFAULT_BUFFER_SIZE = 8192;// 输入缓冲区(固定长度的数组)protected volatile byte buf[];// 有效数据起始位,也是读数据的起始位protected int pos;// 有效数据量,pos + count 是写数据的起始位protected int count;...}
3.4 Segment 片段与 SegmentPool 对象池
Segment 中的字节数组是可以 “共享” 的,当数据从一个缓冲区转移到另一个缓冲区时,可以共享数据引用,而不一定需要拷贝数据。
Segment.kt
internal class Segment {companion object {// 片段的默认大小(8KB)const val SIZE = 8192// 最小共享阈值,超过 1KB 的数据才会共享const val SHARE_MINIMUM = 1024}// 底层数组@JvmField val data: ByteArra// 有效数据的起始位,也是读数据的起始位@JvmField var pos: Int = 0// 有效数据的结束位,也是写数据的起始位@JvmField var limit: Int = 0// 共享标记位@JvmField var shared: Boolean = false// 宿主标记位@JvmField var owner: Boolean = false// 后续指针@JvmField var next: Segment? = null// 前驱指针@JvmField var prev: Segment? = nullconstructor() {// 默认构造 8KB 数组(为什么默认长度是 8KB)this.data = ByteArray(SIZE)// 宿主标记位this.owner = true// 共享标记位this.shared = false}}
另外,Segment 还使用了对象池设计,被回收的 Segment 对象会缓存在 SegmentPool 中。SegmentPool 内部维护了一个被回收的 Segment 对象单链表,缓存容量的最大值是 MAX_SIZE = 64 * 1024,也就相当于 8 个默认 Segment 的长度:
SegmentPool.kt
// object:全局单例internal actual object SegmentPool {// 缓存容量actual val MAX_SIZE = 64 * 1024// 头节点private val LOCK = Segment(ByteArray(0), pos = 0, limit = 0, shared = false, owner = false)...}
Segment 示意图

4. 总结
- 1、Okio 将原生 IO 多种基础装饰器聚合在 BufferedSource 和 BufferedSink,使得框架更加精简;
- 2、为了减少系统调用次数的同时,应用层 IO 框架会使用缓存区设计。而 Okio 使用了基于共享 Segment 的缓冲区设计,减少了在缓冲区间转移数据的内存拷贝;
- 3、Okio 弥补了部分 IO 操作不支持超时检测的缺陷,而且 Okio 不仅支持单次 IO 操作的超时检测,还支持包含多次 IO 操作的复合任务超时检测。
关于 Okio 超时机制的详细分析,我们在 下一篇文章 里讨论。请关注。
参考资料
- Github · Okio
- Okio 官网
- Okio 源码学习分析 —— 川峰 著
- Okio 好在哪?—— MxsQ 著
Android IO 框架 Okio 的实现原理,到底哪里 OK?的更多相关文章
- Android网络框架-Volley实践 使用Volley打造自己定义ListView
这篇文章翻译自Ravi Tamada博客中的Android Custom ListView with Image and Text using Volley 终于效果 这个ListView呈现了一些影 ...
- Android自动化测试框架UIAutomator原理浅析
UIAutomator是一个Android自动化测试框架,是谷歌在Android4.1版本发布时推出的一款用Java编写的UI测试框架,它只能用于UI即黑盒方面的测试.所以UIAutomator只能运 ...
- Android网络框架Volley(体验篇)
Volley是Google I/O 2013推出的网络通信库,在volley推出之前我们一般会选择比较成熟的第三方网络通信库,如: android-async-http retrofit okhttp ...
- Android网络框架Volley
Volley是Google I/O 2013推出的网络通信库,在volley推出之前我们一般会选择比较成熟的第三方网络通信库,如: android-async-http retrofit okhttp ...
- Android 开发 框架系列 Google的ORM框架 Room
目录 简介 导入工程 使用流程概况 一个简单的小Demo 深入学习 @Entity使用 自定义表名 tableName 自定义字段名@ColumnInfo 主键 @PrimaryKey 索引 @In ...
- Android Butterknife框架
Android Butterknife框架 注解攻略 时间 2014-02-27 09:28:09 Msquirrel原文 http://www.msquirrel.com/?p=95 一.原理. ...
- 2017年Android百大框架排行榜
框架:提供一定能力的小段程序 >随意转载,标注作者"金诚"即可 >本文已授权微信公众号:鸿洋(hongyangAndroid)原创首发. >本文已经开源到Gith ...
- Android 性能监控系列一(原理篇)
欢迎关注微信公众号:BaronTalk,获取更多精彩好文! 一. 前言 性能问题是导致 App 用户流失的罪魁祸首之一,如果用户在使用我们 App 的时候遇到诸如页面卡顿.响应速度慢.发热严重.流量电 ...
- android 优秀框架整理
程序员界有个神奇的网站,那就是github,这个网站集合了一大批优秀的开源框架,极大地节省了开发者开发的时间,在这里我进行了一下整理,这样可以使我们在使用到时快速的查找到,希望对大家有所帮助! 1. ...
- 2017年Android百大框架排行榜(转)
一.榜单介绍 排行榜包括四大类: 单一框架:仅提供路由.网络层.UI层.通信层或其他单一功能的框架 混合开发框架:提供开发hybrid app.h5与webview结合能力.web app能力的框架 ...
随机推荐
- 我的Vue之旅 10 Gin重写后端、实现页面详情页 Mysql + Golang + Gin
第三期 · 使用 Vue 3.1 + Axios + Golang + Mysql + Gin 实现页面详情页 使用 Gin 框架重写后端 Gin Web Framework (gin-gonic.c ...
- 搭建K8S集群前置条件
搭建K8S集群 搭建k8s环境平台规划 单master集群 单个master节点,然后管理多个node节点 多master集群 多个master节点,管理多个node节点,同时中间多了一个负载均衡的过 ...
- 2022春每日一题:Day 37
题目:[USACO14FEB]Auto-complete S 字典树套路题,字典树优化剪枝,加个cnt标记即可 代码: #include <cstdio> #include <cst ...
- Fastjsonfan反序列化(1)
前言 之前只是对FastJson漏洞有简单的一个认知,虽然由于网上fastjson漏洞调试的文章很多,但是真正有着自己的理解并能清楚的讲述出来的文章少之又少.大多文章都是对已知的漏洞调用流程做了大量分 ...
- 【终极解决办法】pyinstaller打包exe没有错误,运行exe提示Failed to execute script 'mainlmageWindows' due tounhandled exception: No module named 'docx'
一.通过pyinstaller打包exe可执行文件,由于我的py是多个,所以要先生成spec文件,代码如下: pyi-makespec mainImageWindows.py 此时生产了一个mainI ...
- 【大数据面试】【框架】Hadoop-入门、HDFS
一.入门 1.常用端口号 2.x 50070:查看HDFS Web-UI 8088:查看MapReduce运行情况 19888:历史服务器 9000:hdfs客户端访问集群 50090:Seconda ...
- K8s 超详细总结
一个目标:容器操作:两地三中心:四层服务发现:五种Pod共享资源:六个CNI常用插件:七层负载均衡:八种隔离维度:九个网络模型原则:十类IP地址:百级产品线:千级物理机:万级容器:相如无亿,K8s有亿 ...
- Navicat破解教程
一.注意: 软件适用于WIN7/8/10/11: 安装全程断网: 下载.解压和安装都应该在英文路径下进行: 解压安装前关闭所有杀毒软件,WIN10/11系统需关闭Windows Defender的实时 ...
- 巧如范金,精比琢玉,一分钟高效打造精美详实的Go语言技术简历(Golang1.18)
研发少闲月,九月人倍忙.又到了一年一度的"金九银十"秋招季,又到了写简历的时节,如果你还在用传统的Word文档寻找模板,然后默默耕耘,显然就有些落后于时代了,本次我们尝试使用云平台 ...
- 第三章 --------------------XAML的属性和事件
1.XAML注释是什么样子的? 在之前的章节有提起过,但是这一节我还是想系统的学习XAML,XAML的注释如下 <!-- //这其中填写注释 --> Notice:在注释的部分编译器是不编 ...