生产出现oom问题,怎么排查?
生产出现oom问题,怎么排查?
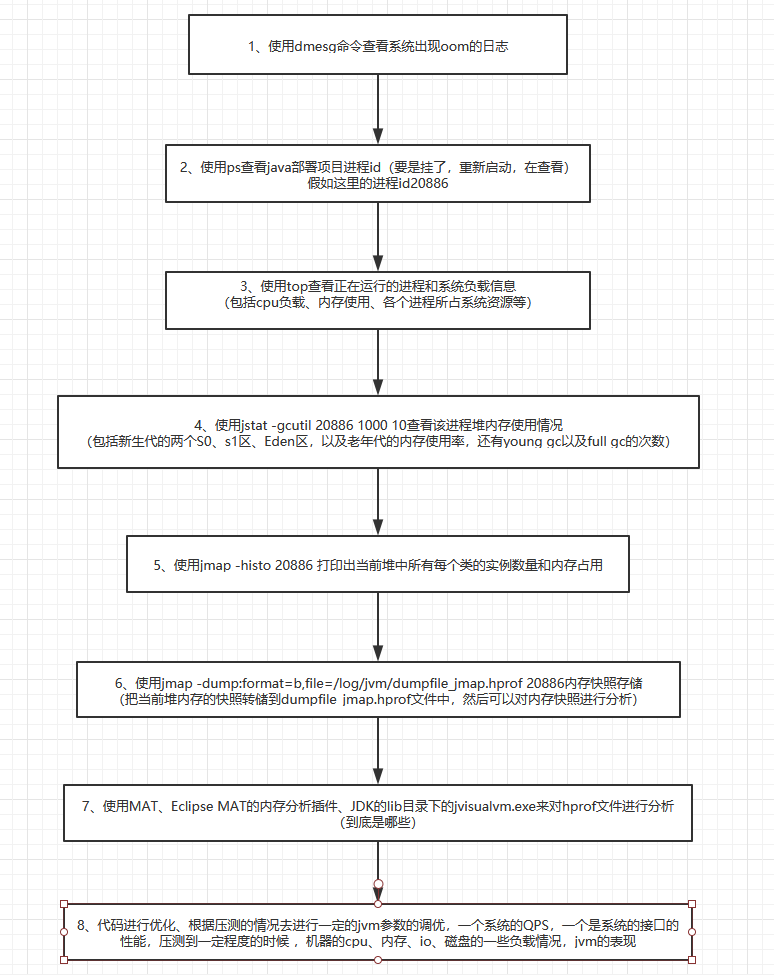
1、使用dmesg命令查看系统日志
dmesg |grep -E ‘kill|oom|out of memory’,可以查看操作系统启动后的系统日志,这里就是查看跟内存溢出相关联的系统日志。
2、这时候,需要启动项目,使用ps命令查看进程
ps -aux|grep java命令查看一下你的java进程,就可以找到你的java进程的进程id。
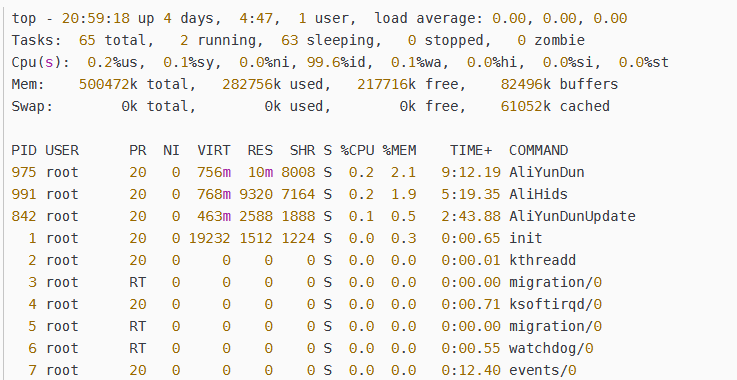
3、接着使用top命令
top命令显示的结果列表中,会看到%MEM这一列,这里可以看到你的进程可能对内存的使用率特别高。以查看正在运行的进程和系统负载信息,包括cpu负载、内存使用、各个进程所占系统资源等。
4、使用jstat命令
用jstat -gcutil 20886 1000 10命令,就是用jstat工具,对指定java进程(20886就是进程id,通过ps -aux | grep java命令就能找到),按照指定间隔,看一下统计信息,这里会每隔一段时间显示一下,包括新生代的两个S0、s1区、Eden区,以及老年代的内存使用率,还有young gc以及full gc的次数。
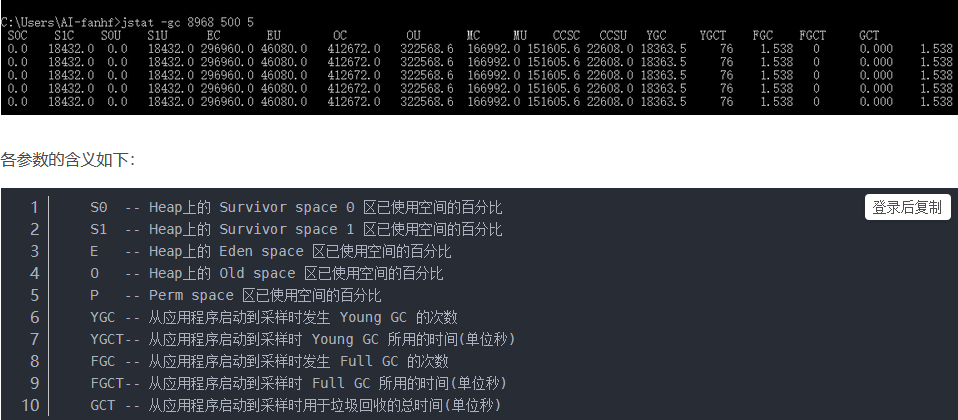
使用 jstat -gcutil 8968 500 5 表示每500毫秒打印一次Java堆状况(各个区的容量、使用容量、gc时间等信息),打印5次
例如:
看到的东西类似下面那样:
S0 S1 E O YGC FGC
26.80 0.00 10.50 89.90 86 954
其实如果大家了解原理,应该知道,一般来说大量的对象涌入内存,结果始终不能回收,会出现的情况就是,快速撑满年轻代,然后young gc几次,根本回收不了什么对象,导致survivor区根本放不下,然后大量对象涌入老年代。老年代很快也满了,然后就频繁full gc,但是也回收不掉。
然后对象持续增加不就oom了,内存放不下了,爆了呗。
所以jstat先看一下基本情况,马上就能看出来,其实就是大量对象没法回收,一直在内存里占据着,然后就差不多内存快爆了。
5、使用jmap命令查看
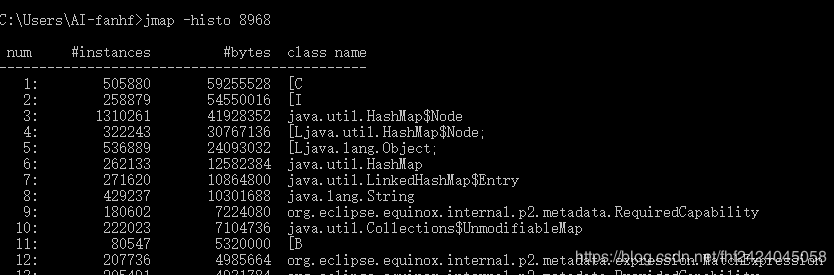
执行jmap -histo pid可以打印出当前堆中所有每个类的实例数量和内存占用,如下,class name是每个类的类名([B是byte类型,[C是char类型,[I是int类型),bytes是这个类的所有示例占用内存大小,instances是这个类的实例数量。
6、把当前堆内存的快照转储到dumpfile_jmap.hprof文件中,然后可以对内存快照进行分析
使用jmap -dump:format=b,file=文件名 [pid],就可以把指定java进程的堆内存快照搞到一个指定的文件里去,但是jmap -dump:format其实一般会比较慢一些,也可以用gcore工具来导出内存快照
例如:jmap -dump:format=b,file=D:/log/jvm/dumpfile_jmap.hprof 20886
接着就是可以用MAT工具,或者是Eclipse MAT的内存分析插件,来对hprof文件进行分析,看看到底是哪个王八蛋对象太多了,导致内存溢出了

或者使用jdk的目录下的bin目录下的:jvisualvm.exe
8、总结:
一般常见的OOM,要么是短时间内涌入大量的对象,导致你的系统根本支持不住,此时你可以考虑优化代码,或者是加机器;要么是长时间来看,你的很多对象不用了但是还被引用,就是内存泄露了,你也是优化代码就好了;这就会导致大量的对象不断进入老年代,然后频繁full gc之后始终没法回收,就撑爆了
要么是加载的类过多,导致class在永久代理保存的过多,始终无法释放,就会撑爆
我这里可以给大家最后提一点,人家肯定会问你有没有处理过线上的问题,你就说有,最简单的,你说有个小伙子用了本地缓存,就放map里,结果没控制map大小,可以无限扩容,最终导致内存爆了,后来解决方案就是用了一个ehcache框架,自动LRU清理掉旧数据,控制内存占用就好了。
另外,务必提到,线上jvm必须配置-XX:+HeapDumpOnOutOfMemoryError,-XX:HeapDumpPath=/path/heap/dump。因为这样就是说OOM的时候自动导出一份内存快照,你就可以分析发生OOM时的内存快照了,到底是哪里出现的问题。
9、修改代码调优,修改jvm配置调优,部署接口压测
代码进行优化、根据压测的情况去进行一定的jvm参数的调优,一个系统的QPS,一个是系统的接口的性能,压测到一定程度的时候 ,机器的cpu、内存、io、磁盘的一些负载情况,jvm的表现
10、流程
附加:系统频繁full gc:
比OOM稍微好点的是频繁full gc,如果OOM就是系统自动就挂了,很惨,你绝对是超级大case,但是频繁full gc会好多,其实就是表现为经常请求系统的时候,很卡,一个请求卡半天没响应,就是会觉得系统性能很差。
首先,你必须先加上一些jvm的参数,让线上系统定期打出来gc的日志:
-XX:+PrintGCTimeStamps
-XX:+PrintGCDeatils
-Xloggc:<filename>
这样如果发现线上系统经常卡顿,可以立即去查看gc日志,大概长成这样:
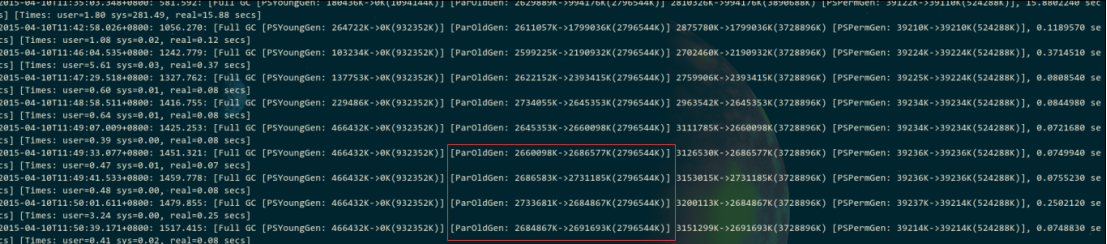
如果要是发现每次Full GC过后,ParOldGen就是老年代老是下不去,那就是大量的内存一直占据着老年代,啥事儿不干,回收不掉,所以频繁的full gc,每次full gc肯定会导致一定的stop the world卡顿,这是不可能完全避免的
接着采用跟之前一样的方法,就是dump出来一份内存快照,然后用Eclipse MAT插件分析一下好了,看看哪个对象量太大了
接着其实就是跟具体的业务场景相关了,要看具体是怎么回事,常见的其实要么是内存泄露,要么就是类加载过多导致永久代快满了,此时一般就是针对代码逻辑来优化一下。
给大家还是举个例子吧,我们线上系统的一个真实例子,大家可以用这个例子在面试里来说,比如说当时我们有个系统,在后台运行,每次都会一下子从mysql里加载几十万行数据进来各种处理,类似于定时批量处理,这个时候,如果对几十万数据的处理比较慢,就会导致比如几分钟里面,大量数据囤积在老年代,然后没法回收,就会频繁full gc。
当时我们其实就是根据这个发现了当时两台机器已经不够了,因为我们当时线上用了两台4核8G的虚拟机在跑,明显不够了,就要加机器了,所以增加了机器,每台机器处理更少的数据量,那不就ok了,马上就缓解了频繁full gc的问题了。
生产出现oom问题,怎么排查?的更多相关文章
- 生产环境OOM\死锁问题排查修复
OOM: 1.快速恢复业务:如果是集群中的一台机器故障,先隔离故障服务器:如果是多台,则根据Nginx转发策略,对该功能转发到单独的集群,与其他流量隔离,确保其他业务不受影响 2.收集内存溢出Dump ...
- 一次线上OOM过程的排查
https://blog.csdn.net/qq_16681169/article/details/53296137 一.出现问题 在前一段时间日常环境很不稳定,前端调用mtop接口会出网络异常或服务 ...
- 总结:利用asp.net core日志进行生产环境下的错误排查(asp.net core version 2.2,用IIS做服务器)
概述 调试asp.net core程序时,在输出窗口中,在输出来源选择“调试”或“xxx-ASP.NET Core Web服务器”时,可以看到类似“info:Microsoft.AspNetCore. ...
- java运维: 一次线上问题排查所引发的思考
本文转载自 crossoverJie 的b博客 https://www.cnblogs.com/crossoverJie/p/9282065.html 前言 之前或多或少分享过一些内存模型.对象创建之 ...
- php-fpm内存泄漏问题排查
生产环境内存泄漏问题排查,以下是排查思路 生产环境上有严重的内存溢出问题(红色框所示,正常值应为是 20M 左右)同时系统有 Core Dump 文件产生排查过程中还发现一个现象,如果关闭 OPc ...
- RabbitMQ消费者消失与 java OOM
原因: 下午先是收到钉钉告警有一个消费者系统任务积压, 当时以为就是有范围上量没有当回事,后来客服群开始反馈说有客户的数据没有生成.这个时候查看mq的后台,发现任务堆积数量还是很多. 这个时候登录一台 ...
- OOM故障处理流程
一.OOM机制概述 Linux 内核有个机制叫OOM killer(Out Of Memory killer),该机制会监控那些占用内存过大,尤其是瞬间占用内存很快的进程,为防止内存耗尽而自动把该进程 ...
- JVM性能调优(4) —— 性能调优工具
前序文章: JVM性能调优(1) -- JVM内存模型和类加载运行机制 JVM性能调优(2) -- 垃圾回收器和回收策略 JVM性能调优(3) -- 内存分配和垃圾回收调优 一.JDK工具 先来看看有 ...
- [原创]PostgreSQL Plus Advanced Server批量创建分区表写入亿级别数据实例
当前情况:大表的数据量已接近2亿条我的解决思路:为它创建n*100个分区表,将各个分区表放在不同的tablespace上这样做的优点:1.首先是对这个级别的数据表的性能会有所提升2.数据管理更科学3. ...
随机推荐
- 3D 世界的钥匙「GitHub 热点速览 v.22.08」
有没有想过把身边的物件儿转成 3D 动画,在网页上实现一把?本期特推的项目 Three.js 就是帮你创建 3D 页面的知名开源项目,好玩的 3D 世界在向你招手.除了打开浏览器 3D 世界的钥匙外, ...
- java中的interface(接口)
概念 usb插槽就是现实中的一个接口 你可以把u盘都插在usb插槽上,而不用担心买来的u盘插不进插槽中不管是插电脑,还是插相机,还是插收音机原因是做usb的厂家和做各种设备的厂家都遵守了统一的规定包括 ...
- Python 中 selenium 库
目录 selenium 基础语法 一. 环境配置 1. 安装环境 2. 配置参数 3. 常用参数搭配 4. 分浏览器启动 二. 基本语法 1. 元素定位 2. 控制浏览器操作 3. 操作元素的方法 3 ...
- jmeter重点(详细)
之前,写过一篇文章:jmeter,学这些重点就可以了,今天就来把一些重点细节点说一下. 测试计划 可以理解为各种测试元件的容器 其中: 定义整个测试中使用的重复值(全局变量),一般定义服务器的ip.端 ...
- stegsolve.jar压缩包打开和使用方法
1.stegsolve.jar下载 下载地址:http://www.caesum.com/handbook/Stegsolve.jar 2.stegsolve.jar打开方法 (1)需要下载java并 ...
- 【C# 集合】HashTable .net core 中的Hashtable的实现原理
上一篇我介绍了Hash函数 这篇我来说一下Hash函数在 HashTable中的应用. HashTable的特性: 1.装载因子:.net core 0.72 ,java 0.75 2.冲突解决方案: ...
- 聊聊你对AQS的理解
场景引入 面试官上来就一句,谈谈你对AQS的理解,大家心里可能收到了1W点伤害,AQS是什么,可能连全称都不知道,所以下面让我们聊聊AQS. 以ReentrantLock来介绍一下AQS 在java中 ...
- 编译原理 | 构造LR(1)自动机的注意事项
在画图之前,有时候要先对产生式集合进行某些操作. 下图所示的情况,不需要补一条拓广产生式,因为开始符Z没有出现在某条产生式的右侧. 即,如果开始符出现在某条产生式的右部,需要增加拓广产生式.
- Python:对元组使用关键字in
如果in的左边是个含有多个元素的元组对象 例如 ('a','b') in L 那么L在什么情况下,这个式子会输出True呢? 答案是,L中必须也有一个和想要查找的元组一模一样的元组才行,比如: L=[ ...
- Python数据可视化 -- Wordcloud
Python数据可视化 -- Wordcloud 安装 启动命令行,输入:pip install wordcloud word cloud 库介绍 及简单使用 wordcloud库,可以说是pytho ...