jdk1.8中hashmap的扩容resize
1 final Node<K,V>[] resize() {
2 Node<K,V>[] oldTab = table;
3 int oldCap = (oldTab == null) ? 0 : oldTab.length;
4 int oldThr = threshold;
5 int newCap, newThr = 0;
6 if (oldCap > 0) {
7 if (oldCap >= MAXIMUM_CAPACITY) {
8 threshold = Integer.MAX_VALUE;
9 return oldTab;
10 }
11 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
12 oldCap >= DEFAULT_INITIAL_CAPACITY) //注释1
13 newThr = oldThr << 1; // double threshold
14 }
15 else if (oldThr > 0) // initial capacity was placed in threshold
16 newCap = oldThr;
17 else { // zero initial threshold signifies using defaults
18 newCap = DEFAULT_INITIAL_CAPACITY;
19 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
20 }
21 if (newThr == 0) {
22 float ft = (float)newCap * loadFactor;
23 newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
24 (int)ft : Integer.MAX_VALUE);
25 }
26 threshold = newThr;
27 @SuppressWarnings({"rawtypes","unchecked"})
28 Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
29 table = newTab;
30 if (oldTab != null) {
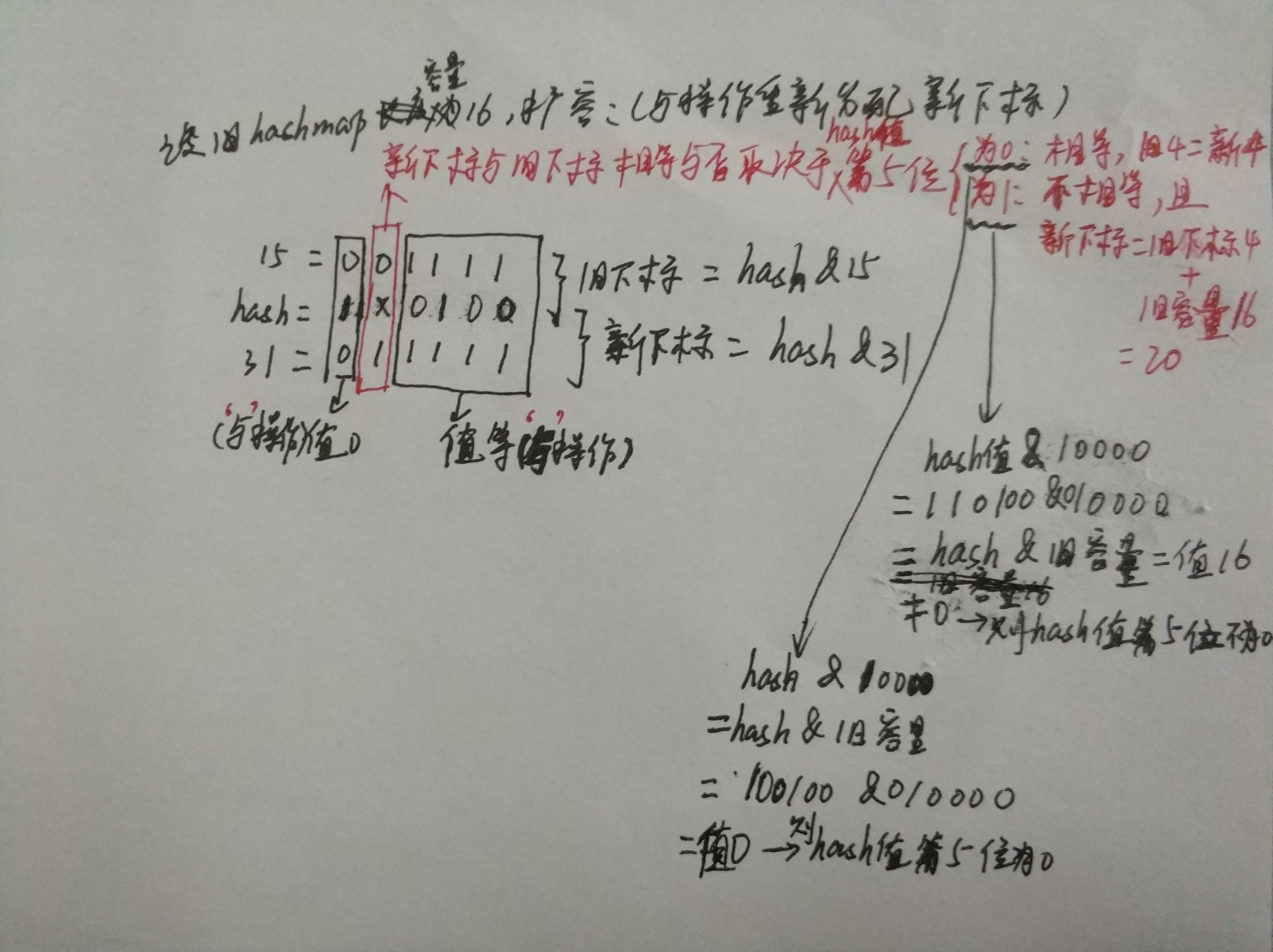
31 for (int j = 0; j < oldCap; ++j) { //注释2
32 Node<K,V> e;
33 if ((e = oldTab[j]) != null) {//注释3
34 oldTab[j] = null;
35 if (e.next == null) //注释4
36 newTab[e.hash & (newCap - 1)] = e;
37 else if (e instanceof TreeNode) //注释5
38 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
39 else { // preserve order //注释6
40 Node<K,V> loHead = null, loTail = null; //注释7
41 Node<K,V> hiHead = null, hiTail = null;//注释8
42 Node<K,V> next;
43 do {
44 next = e.next;
45 if ((e.hash & oldCap) == 0) { //注释9
46 if (loTail == null) //注释10
47 loHead = e;
48 else
49 loTail.next = e;
50 loTail = e;
51 }
52 else {
53 if (hiTail == null)//注释11
54 hiHead = e;
55 else
56 hiTail.next = e;
57 hiTail = e;
58 }
59 } while ((e = next) != null);
60 if (loTail != null) { //注释12
61 loTail.next = null;
62 newTab[j] = loHead;
63 }
64 if (hiTail != null) {//注释13
65 hiTail.next = null;
66 newTab[j + oldCap] = hiHead;
67 }
68 }
69 }
70 }
71 }
72 return newTab;
73 }
jdk1.8中hashmap的扩容resize的更多相关文章
- JDK1.7中HashMap死环问题及JDK1.8中对HashMap的优化源码详解
一.JDK1.7中HashMap扩容死锁问题 我们首先来看一下JDK1.7中put方法的源码 我们打开addEntry方法如下,它会判断数组当前容量是否已经超过的阈值,例如假设当前的数组容量是16,加 ...
- JDK1.8中HashMap实现
JDK1.8中的HashMap实现跟JDK1.7中的实现有很大差别.下面分析JDK1.8中的实现,主要看put和get方法. 构造方法的时候并没有初始化,而是在第一次put的时候初始化 putVal方 ...
- JDK1.7中HashMap底层实现原理
一.数据结构 HashMap中的数据结构是数组+单链表的组合,以键值对(key-value)的形式存储元素的,通过put()和get()方法储存和获取对象. (方块表示Entry对象,横排表示数组ta ...
- JDK1.8中HashMap的hash算法和寻址算法
JDK 1.8 中 HashMap 的 hash 算法和寻址算法 HashMap 源码 hash() 方法 static final int hash(Object key) { int h; ret ...
- jdk1.8 HashMap的扩容resize()方法详解
/** * Initializes or doubles table size. If null, allocates in * accord with initial capacity target ...
- jdk1.7中hashmap扩容时不会产生死循环
在扩容时 transfer( ) 方法中 newTable 新数组 局部变量 table 旧数组 全局变量 当第一个链表进行while循环时 执行到 e.next = newTable[i]; 时 n ...
- 关于JDK1.7+中HashMap对红黑树场景的思考
背景 在1.7之前的版本,当数组元素较多(几百.几千,或者更多)的时候,在这种前提扩容,涉及全量元素的遍历和坐标的重新定位,这个耗时会比较长.这是之前存在的一个弊端吧.那么引入红黑树之后就解决了问题, ...
- hashMap在jdk1.7与jdk1.8中的原理及不同
在分析jdk1.7中HashMap的hash冲突时,不知大家是否有个疑问就是万一发生碰撞的节点非常多怎么版?如果说成百上千个节点在hash时发生碰撞,存储一个链表中,那么如果要查找其中一个节点,那就不 ...
- JDK1.8 中的HashMap
HashMap本质上Java中的一种数据结构,他是由数组+链表的形式组织而成的,当然了在jdk1.8后,当链表长度大于8的时候为了快速寻址,将链表修改成了红黑树. 既然本质上是一个数组,那我们 ...
随机推荐
- idea导入gitee下载的项目文件
前一段时间在学习javaWeb时想要把gitee中的下载的项目在本地环境中跑一遍,然后根据效果再自己做出来. 但是当导入到IDEA中,配置完tomcat后一直报404错误.404是学习javaweb阶 ...
- mysql覆盖索引与回表
mysql覆盖索引与回表 Harri2012关注 62019.07.28 11:14:15字数 1,292阅读 77,322 select id,name where name='shenjian' ...
- C++各种输入
https://blog.csdn.net/qq_29735775/article/details/81165882 1.cin 2.cin.get() 3.cin.getline() 4.getli ...
- 请说说你对Hibernat的理解?JDBC和Hibernate各有什么优势和劣势?
Hibernate是一个轻量级的持久层开源框架,它是连接Java应用程序和关系数据库的中间件,负责Java对象和关系数据之间的映射.Hibernate内部对JDBC API进行了封装,负责Java对象 ...
- C# 如何让new 出来的form显示在最外层?
/// <summary> /// 显示比对不同点的位置 /// </summary> public void showDiffImage() { //在此处弹出不一样图 Bi ...
- NULL 是什么意思 ?
NULL 这个值表示 UNKNOWN(未知):它不表示""(空字符串).对 NULL 这 个值的任何比较都会生产一个 NULL 值.您不能把任何值与一个 NULL 值进行比 较,并 ...
- 学习saltstack (一)
salt介绍 Salt是一个基础平台管理工具 Salt是一个配置管理系统,能够维护预定义状态的远程节点 Salt是一个分布式远程执行系统,用来在远程节点上执行命令和查询数据 salt的核心功能 是命令 ...
- css两栏布局、圣杯布局、双飞翼布局
最近几个月一直用vue在写手机端的项目,主要写业务逻辑,在js方面投入的时间和精力也比较多.这两天写页面明显感觉css布局方面的知识有不足,所以复习一下布局方法. 两栏布局 1.浮动 .box1 .l ...
- 7步学会在Windows下上架iOS APP流程
之前用跨平台开发工具做了一个应用,平台可以同时生成安卓版和苹果版,想着也把这应用上架到App Store试试,于是找同学借了个苹果开发者账号,但没那么简单,还要用到Mac电脑的钥匙串申请发布证书和上传 ...
- Native方法的使用
Java不是完美的,Java的不足除了体现在运行速度上要比传统的C++慢许多之外,Java无法直接访问到操作系统底层(如系统硬件等),为此Java使用native方法来扩展Java程序的功能. 可以将 ...