python数据可视化-matplotlib入门(5)-饼图和堆叠图
饼图常用于统计学模块,画饼图用到的方法为:pie( )
一、pie()函数用来绘制饼图
pie(x, explode=None, labels=None, colors=None, autopct=None, pctdistance=0.6, shadow=False, labeldistance=1.1, startangle=0, radius=1, counterclock=True, wedgeprops=None, textprops=None, center=0, 0, frame=False, rotatelabels=False, *, normalize=None, data=None)
pie()函数参数较多,需要我们调整的常见为以下几个
x: 每个扇形的占比的序列或数组
explode :如果不是None,则是一个len(x)长度的数组,指定每一块的突出程度;突出显示,设置每一块分割出来的间隙大小
labels:为每个扇形提供标签的字符串序列
colors:为每个扇形提供颜色的字符串序列
autopct :如果是一个格式字符串,标签将是fmt % pct。如果是一个函数,它将被调用。
shadow:阴影
startangle:从x轴逆时针旋转,饼的旋转角度 参数用法,可以去官网查询,并自己多去偿试。
二、一个简单的例子:统计每天休息、工作、娱乐等时间的百分比
import matplotlib.pyplot as plt slices = [7,2,9,3,3]
activities = ['sleeping','eating','working','studing','playing']
cols = ['r','m','y','c','b'] plt.pie(slices,
labels=activities,
colors=cols, #自定义的颜色序列,对比slices,可多可少,少时自动补充,如没有,则默认不同颜色。
startangle=90,
shadow= True,
explode=(0,0.1,0,0,0.2),#占比突出程度,
autopct='%1.1f%%' #百分比的显示格式
) plt.title('Time statistics')
plt.show()
实际运行结果:
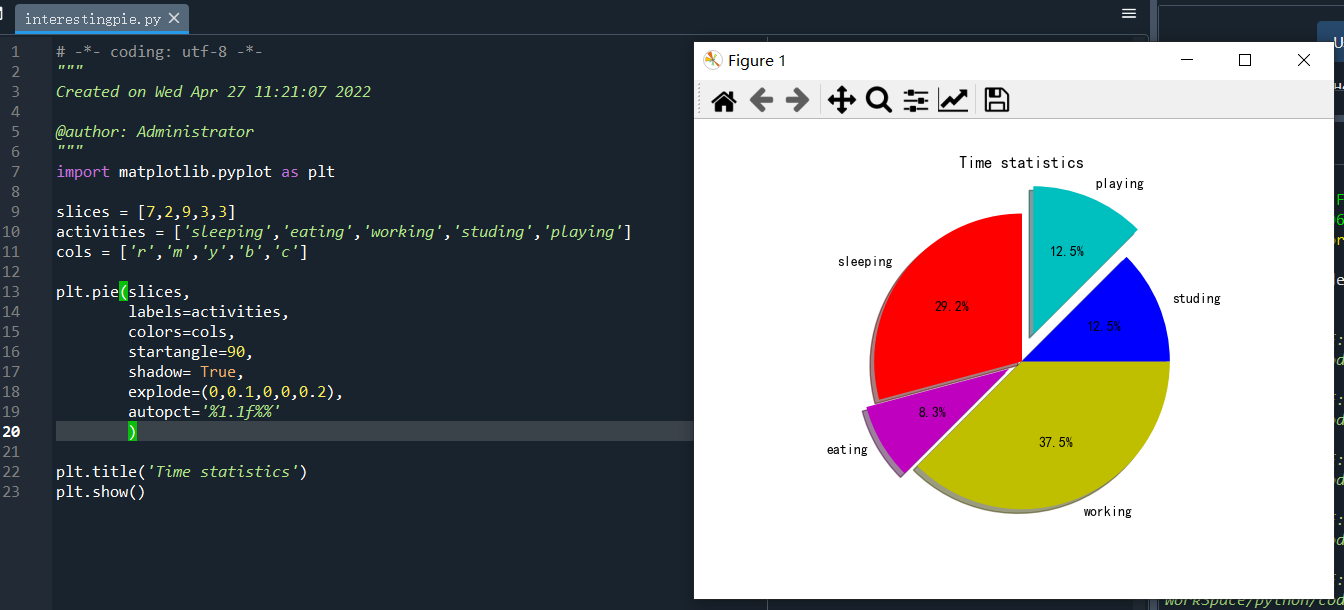
注意:startangle=90时的开始位置。整个饼图是从0度(圆心向右方向)逆时针分布的。
那继续用上篇创建的2个色子,来实现一个饼图。
思考:上述饼图代码中最能决定饼图形状的参数是slices = [7,2,9,3,3],在不考虑每个占比名称、美观等的情况下,先确定如何实现slices中的各数值。
比如,当投掷2粒色子(一个8个面,一个6个面)时,1000000次时,分别统计出现点1、2、3、4、5……14的总次数,保存到slices中即可。用数列中的统计方法 list.count()即可。
主要就是增加两行代码:
new_slices=[] # 新建一个数列 while side <= max_result:
side += 1
new_bins.append(side) #这是之前做柱状图需要用到的
new_slices.append( results.count(int(side)) ) #将保存两色子之和的数列,直接进行统计,results.count(int(side))就是在results的数列中统计出现side的次数。
运行结果,一样也是显示出点数之和7,8,9的出现的次数最多,然后逐渐减小:
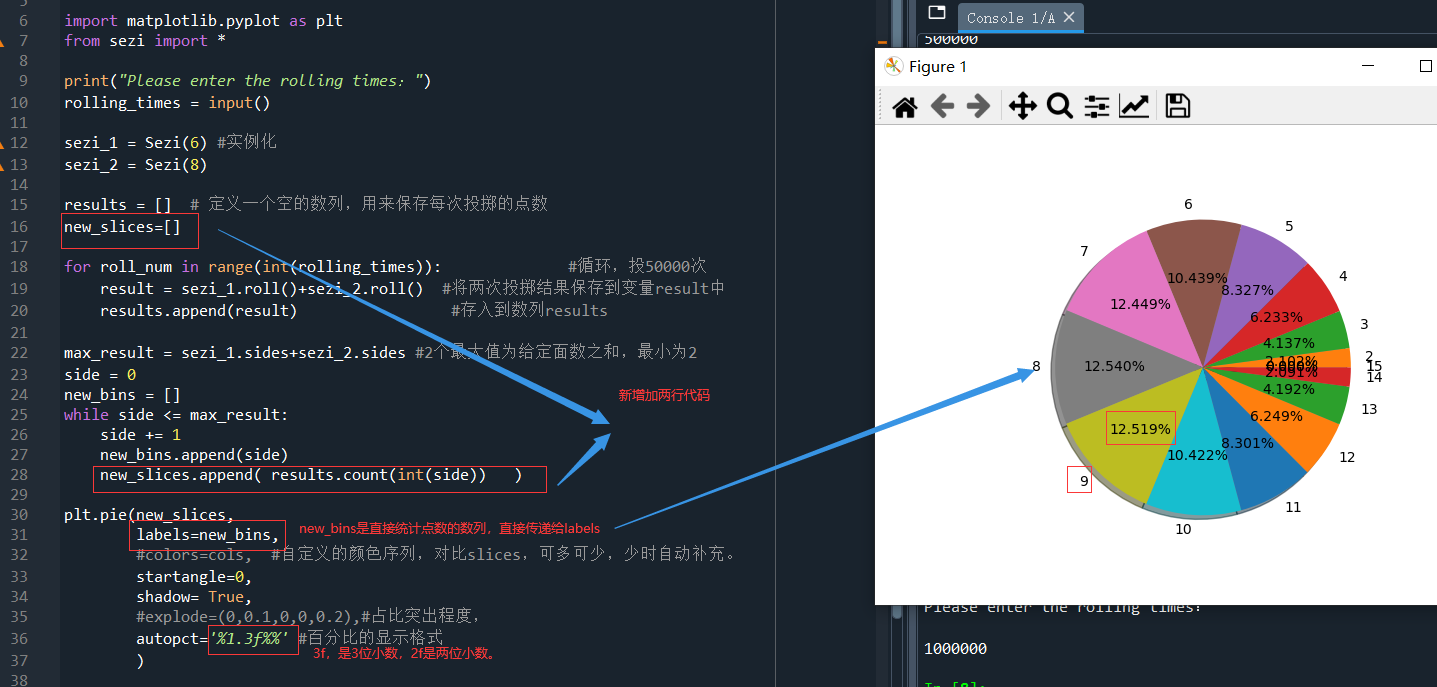
总之,饼图通过将一个圆按照分类的占比划分成多个区块,整个圆饼代表数据的总量,每个区块表示该分类占总体的比例大小,所有区块的加和等于100%。
三、 堆叠图
使用matplotlib中的stackplot()函数可以快速绘制堆积图,stackplot()函数的语法格式如下所示
stackplot(x, y, labels=(), baseling='zero', data=None, *args, **kwargs)
该函数常用参数的含义如下
x:表示x轴的数据,可以是一维数组。
y:表示y轴的数据,可以是二维数组或一维数组序列。
labels:表示每组折线及填充区域的标签。
baseline:表示计算基线的方法,包括'zero'、'sym'、'wiggle'和'weighted_wiggle'。
其中,'zero'表示恒定零基线,即简单的堆积图;
'sym'表示对称于零基线;
'wiggle'表示最小化平方斜率的总和;
'weighted_wiggle'表示执行相同的操作,但权重用于说明每层的大小。
用同一个例子来看一下堆叠图的效果,代码如下:
import matplotlib.pyplot as plt days = [1,2,3,4,5,6,7] sleeping =[7,8,6,8,7,8,6]
eating = [2,3,3,3,2,2,2]
working = [7,7,7,8,10,3,4]
studing = [6,4,4,4,3,8,11]
playing = [2,2,4,1,2,3,1] labellist = ['sleeping','eating','working','studing','playing']
colorlist = ['c','y','b','r','g'] plt.stackplot(days, sleeping,eating,working,studing,playing,labels=labellist,colors=colorlist)
plt.xlabel('x')
plt.ylabel('y')
plt.legend(loc=(0.07, 0.05))
plt.title('Stack Plots')
plt.show()
运行结果如下:
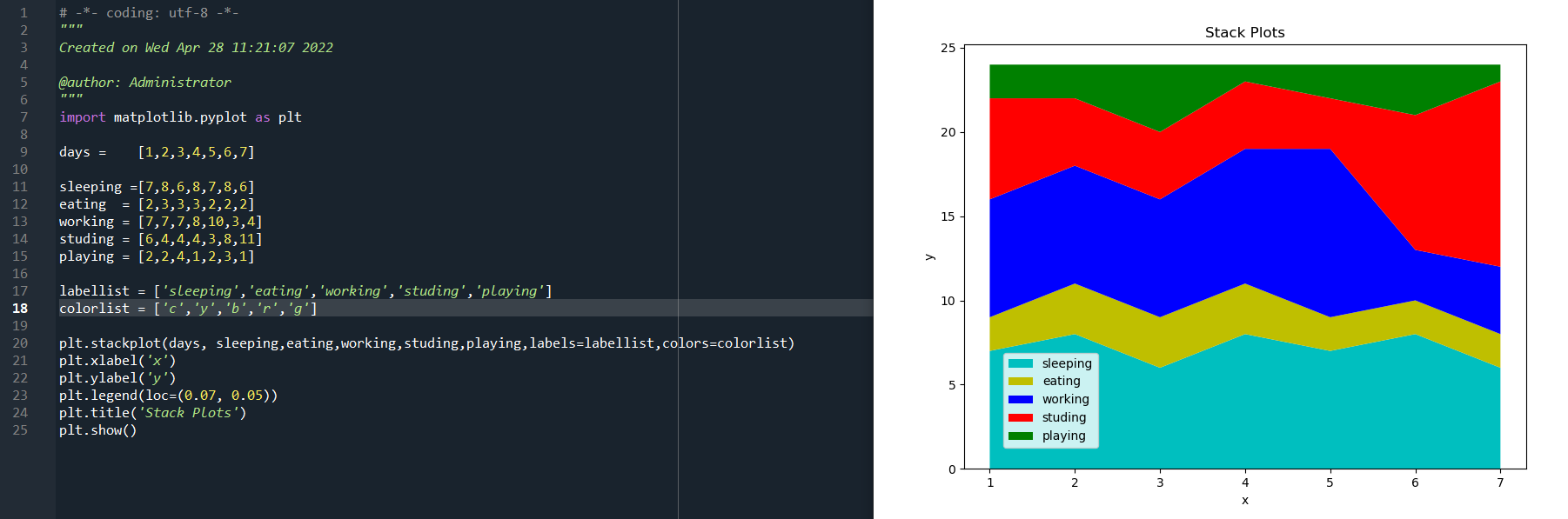
plt.legend()是显示左下角的标签。而语句plt.stackplot()函数中的sleeping,eating,working,studing,playing是一维数组序列,即stackplot(x,y……)中的y值,是一系列一维数据。
很明显,通过上述饼图与堆叠图的对比,它们的区别:饼图只能展示一段时间里,某个项目所花时间占总时间的比,而堆叠图可以展示这一段时间里,每天各项所花费时间。
既然sleeping,eating,working,studing,playing形成的一维数组,感觉参数比较多,那直接形成一个二维数组如何?做如下修改:
days = [1,2,3,4,5,6,7]
"""
sleeping =[7,8,6,8,7,8,6]
eating = [2,3,3,3,2,2,2]
working = [7,7,7,8,10,3,4]
studing = [6,4,4,4,3,8,11]
playing = [2,2,4,1,2,3,1]
"""
times =[ # 二维数组,以数列作为元素的数列。
[7,8,6,8,7,8,6], #上述sleeping数列
[2,3,3,3,2,2,2],
[7,7,7,8,10,3,4],
[6,4,4,4,3,8,11],
[2,2,4,1,2,3,1]
]
plt.stackplot(days, times,labels=labellist,colors=colorlist)
运行结果如图:
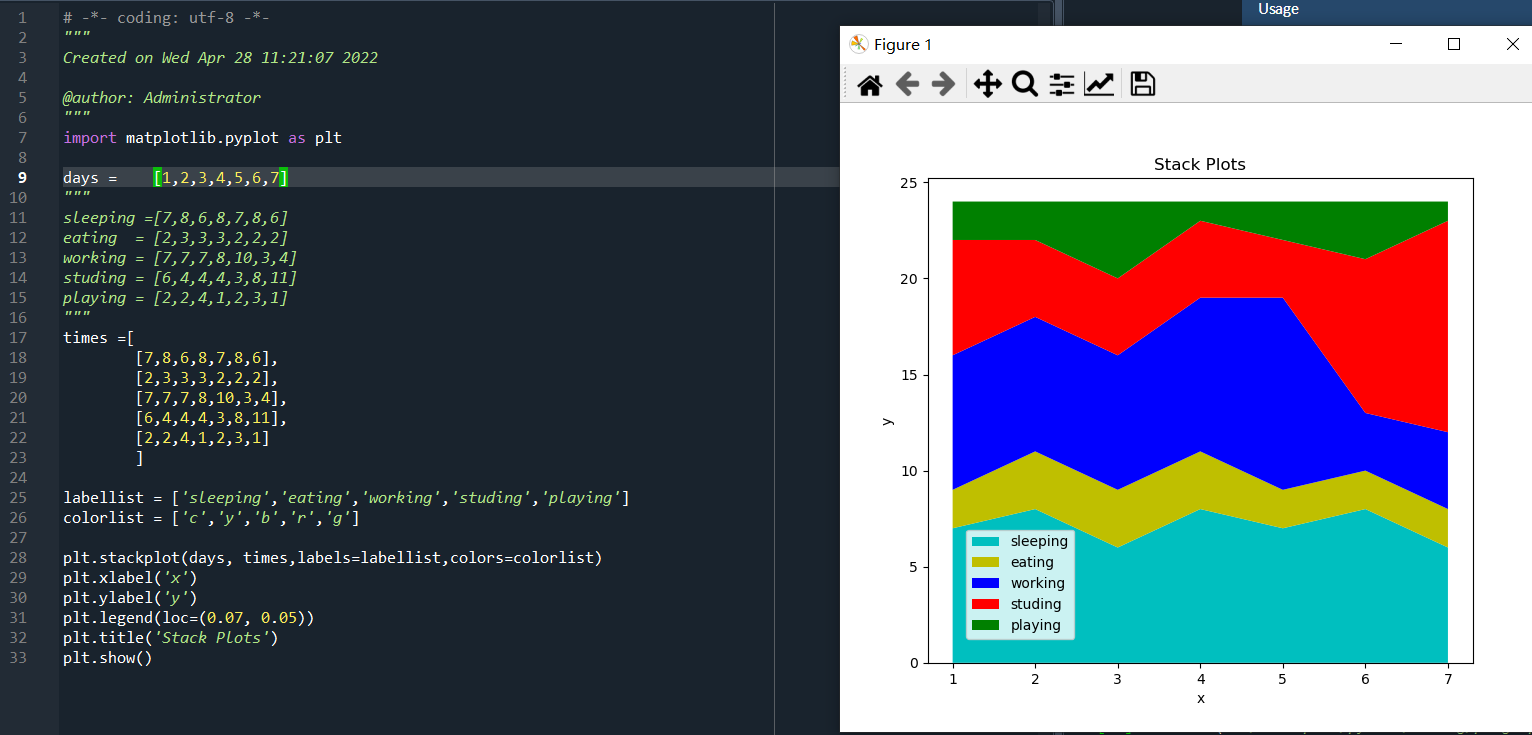
效果与原来的一维数组一样。
但手工这样编程的时候录入数据太过麻烦,下篇介绍直接读取文件数据并进行处理。
python数据可视化-matplotlib入门(5)-饼图和堆叠图的更多相关文章
- python数据可视化-matplotlib入门(7)-从网络加载数据及数据可视化的小总结
除了从文件加载数据,另一个数据源是互联网,互联网每天产生各种不同的数据,可以用各种各样的方式从互联网加载数据. 一.了解 Web API Web 应用编程接口(API)自动请求网站的特定信息,再对这些 ...
- python数据可视化-matplotlib入门(6)-从文件中加载数据
前几篇都是手动录入或随机函数产生的数据.实际有许多类型的文件,以及许多方法,用它们从文件中提取数据来图形化. 比如之前python基础(12)介绍打开文件的方式,可直接读取文件中的数据,扩大了我们的数 ...
- Python数据可视化matplotlib和seaborn
Python在数据科学中的地位,不仅仅是因为numpy, scipy, pandas, scikit-learn这些高效易用.接口统一的科学计算包,其强大的数据可视化工具也是重要组成部分.在Pytho ...
- Python数据可视化--matplotlib
抽象化|具体化: 如盒形图 | 现实中的图 功能性|装饰性:没有装饰和渲染 | 包含艺术性美学上的装饰 深度表达|浅度表达:深入层次的研究探索数据 | 易于理解的,直观的表示 多维度|单一维度:数据的 ...
- python数据可视化(一)——绘制随机漫步图
数据可视化指的是通过可视化表示来探索数据,它与数据挖掘紧密相关. python有一系列的可视化和分析工具,最流行的工具之一是matplotlib,它是一个数学绘图库. 实现绘制随机漫步图 利用ra ...
- python数据可视化——matplotlib 用户手册入门:使用指南
参考matplotlib官方指南: https://matplotlib.org/tutorials/introductory/usage.html#sphx-glr-tutorials-introd ...
- python数据可视化——matplotlib 用户手册入门:pyplot 画图
参考matplotlib官方指南: https://matplotlib.org/tutorials/introductory/pyplot.html#sphx-glr-tutorials-intro ...
- Python数据可视化Matplotlib——Figure画布背景设置
之前在今日头条中更新了几期的Matplotlib教学短视频,在圈内受到了广泛好评,现应大家要求,将视频中的代码贴出来,方便大家学习. 为了使实例图像显得不单调,我们先将绘图代码贴上来,此处代码对Fig ...
- Python数据可视化——使用Matplotlib创建散点图
Python数据可视化——使用Matplotlib创建散点图 2017-12-27 作者:淡水化合物 Matplotlib简述: Matplotlib是一个用于创建出高质量图表的桌面绘图包(主要是2D ...
随机推荐
- consumer 是推还是拉?
Kafka 最初考虑的问题是,customer 应该从 brokes 拉取消息还是 brokers 将消 息推送到 consumer,也就是 pull 还 push.在这方面,Kafka 遵循了一种大 ...
- SpringBoot Jpa 双数据源mysql + oracle + liquibase+参考源码
一.yml文件配置 spring: # 数据库配置 datasource: primary: jdbc-url: jdbc:mysql://localhost:3306/mes-dev?useUnic ...
- mac 修改环境变量bash_profile除了cd用不了其他命令,又关闭了终端
1.添加命令出错,会导致mac不能使用命令 2.打开终端再添加export PATH=/usr/bin:/usr/sbin:/bin:/sbin:/usr/X11R6/bin 一条 3.可以使用命令, ...
- ACL 权限控制机制 ?
UGO(User/Group/Others) 目前在 Linux/Unix 文件系统中使用,也是使用最广泛的权限控制方式.是一种粗 粒度的文件系统权限控制模式. ACL(Access Control ...
- selenium 模块使用
selenium 概念:基于浏览器自动化的一个模块,可以模拟浏览器行为 环境的安装:下载selenium模块 selenium和爬虫之间的关联是什么? 便捷的获取页面中动态加载的数据 requests ...
- 学习heartbeat-01简介
1.Heartbeat介绍 Heartbeat 是一个基于Linux开源的,被广泛使用的高可用集群系统,自1999年开始到现在,发布了众多版本,是目前开源Linux-HA项目最成功的一个例子,在行业内 ...
- 4.4 ROS节点名称重名
4.4 ROS节点名称重名 场景:ROS 中创建的节点是有名称的,C++初始化节点时通过API:ros::init(argc,argv,"xxxx");来定义节点名称,在Pytho ...
- Altium Designer 开始一个项目
通常一个嵌入式开发都需要一个开发板,这就涉及到原理图设计和PCB设计等流程.目前比较主流的设计软件当属Altium Designer了,于是便向写一个关于这方面的专题,也好总结一下,省得以后忘记. A ...
- 从零开始:微信小程序新手入门宝典《一》
为了方便大家了解并入门微信小程序,我将一些可能会需要的知识,列在这里,让大家方便的从零开始学习: 一:微信小程序的特点 张小龙:张小龙全面阐述小程序,推荐通读此文: 小程序是一种不需要下载.安装即可使 ...
- HTML5相关文章和资源
Polyfills HTML5 Cross Browser Polyfills canvas HTML5 JS实现毛玻璃效果(高斯模糊) 高斯模糊的算法Canvas 内部元素添加事件处理 应用场景 P ...