week_10
Andrew Ng 机器学习笔记 ---By Orangestar
Week_10 (大数据处理)
1. Learning With Large Datasets
机器学习很多时候都要处理非常多的数据。对算法的要求颇高。 数据就是力量!
要检验数据集越多,学习算法表现得更好。
就要画学习曲线。
如图: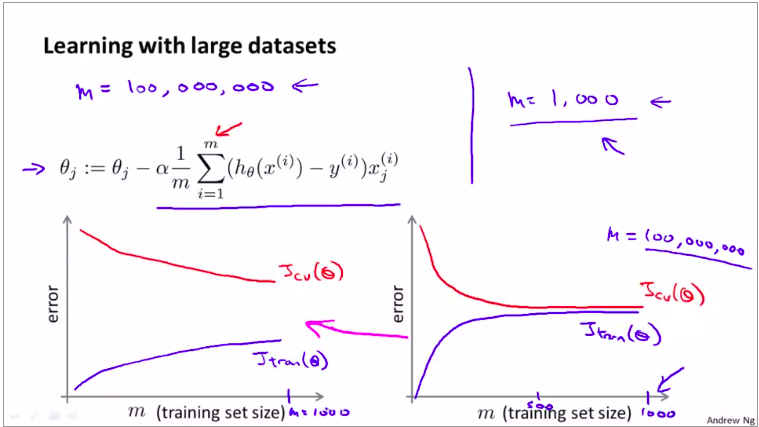
下节我们要介绍两个:
第一个叫做 :随机梯度下降。
第二个叫做: 映射约减。
这两个方法都是用来处理大数据集的。
2. Stochastic Gradient Descent(随机梯度下降法)
当我们训练集非常大的时候,梯度下降算法显得计算量非常非常大。所以,这节课学习 随机梯度下降法,可以用于大数据集
在梯度下降法的时候:简单进行回顾
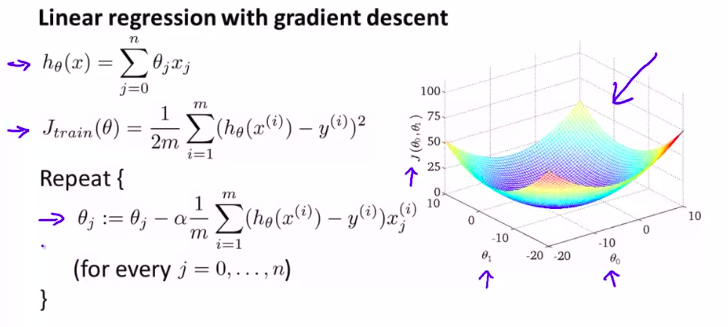
首先我们要知道为什么梯度下降算法在大数据集的时候这么慢。就是这个微分项搞的鬼。它每一步执行的时候,都要对所有数据来求和。(我突然联想到动态规划)
所以传统梯度算法也叫作:
批量梯度下降(batch gradient descent)
所以,这样非常的无效率。仅仅为了计算一次迭代就计算如此多的数据量。
如图:
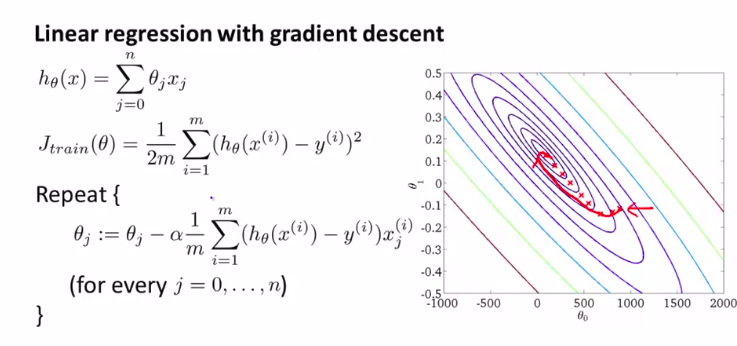
所以,我们当然要对算法进行优化:
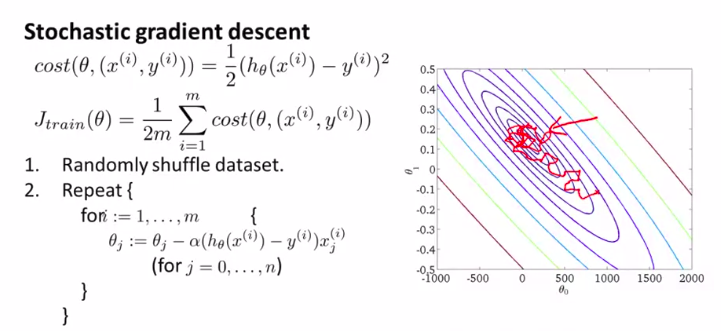
(随机梯度下降)
第一步是将所有数据打乱,也就是把样本重新排列。
(这就是标准的数据预处理过程,这保证了我们对训练集样本的访问是随机的顺序)
然后,如图:(就是对样本进行一个遍历)
对随机梯度下降来说,我们只需要一次关注一个训练样本
在这过程中我们开始一点点把参数朝着全局最小值的方向进行修改
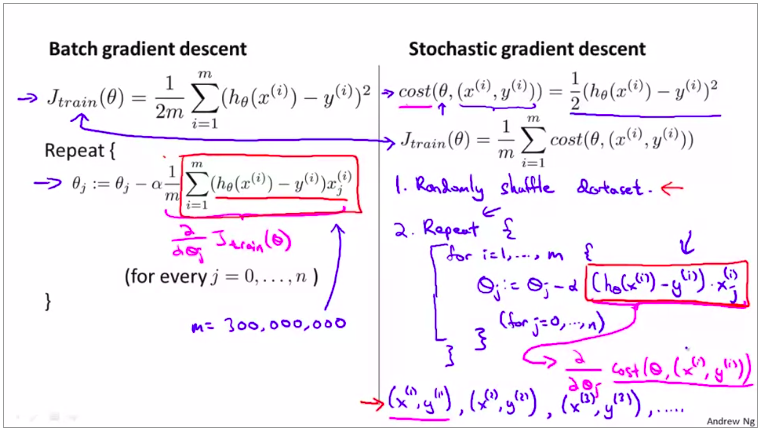
下面是详细介绍这个算法的步骤:
(一般来说,参数是朝着全局最小值的方向被更新的,但也不一定,所以这个算法在梯度下降的时候看起来像是以迂回的路径朝着全局最小值逼近。)
所以,这个和传统的批量梯度下降的收敛形式是不一样的
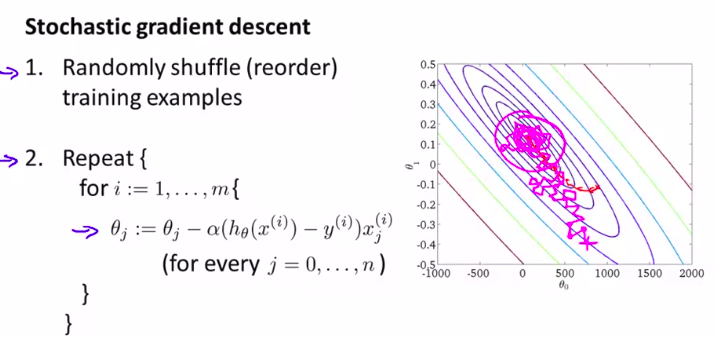
但是这个没有什么问题,它可以足够接近全局最小值。这应用已经足够了。
所以,这个外边的循环一般只进行1到10次就已经足够了。
3. Mini-Batch Gradient Descent(小批量梯度下降)
这节我们讨论小批量梯度下降,这个算法有时候甚至比随机梯度下降还要快一点。
首先看看我们到目前为止所学过的算法的区别

我们所学习的小批量梯度下降 每次迭代我们只用一个小样本。这个小样本所包含的样本数为 b 。b是一个叫做“小批量规模”的参数。一般取5到200个。
然后我们就用这b个样本来做一个梯度下降的一次迭代。
下面来详细看看这个算法的实现步骤:

所以,我们不用扫描所有样本,只需要用b个小样本就可以改进参数,朝着最优前进。
和随机梯度下降的区别?
---向量化!!
具体来说,小批量梯度下降可能比随机梯度下降好,仅当你有好的向量化实现的时候,在那种情况下,10个样本求和可以用一种更向量化的方法实现,这允许你部分并行计算10个样本的和。
换句话来说,使用正确的向量化方法计算剩下的项,你有时可以使用好的数值代数库来部分地并行计算b个样本。这样就更简便了。
但是缺点是:小批量梯度下降多了一个参数b。这意味着你需要花一些时间来调试这个参数b。(一般选择10)
4. Stochastic Gradient Descent Convergence
这节介绍:
- 如何确保在使用随机梯度下降算法的时候,判断调试过程已经完成,并且能正常收敛。
- 如何调整随机梯度下降中的学习速率\(\alpha\)
、
对于随机梯度下降算法,为了检查算法是否收敛,我们可以: 沿用之前定义的cost函数。但是,在随机梯度下降法对训练集进行扫描的时候,我们使用某个样本来更新\(\theta\)之前,我们先计算出,这个假设对这个训练样本的表现。
然后再让它在这个训练样本上预测。
最后,为了检查随机梯度下降的收敛性,我们要做的是:
每1000次迭代,我们可以画出前一步的cost函数,并对算法处理的后1000个样本的cost值求平均值。
这样做可以很好的预测数你的算法在最后1000个样本个上的表现。
然后,通过观察这些画出来的图,我们就能检查出随机梯度下降是否在进行收敛。
如下图:

实际操作的例子::
如果噪声过大,可以增大检查的样本数量。
如果在发散,可以减小学习率
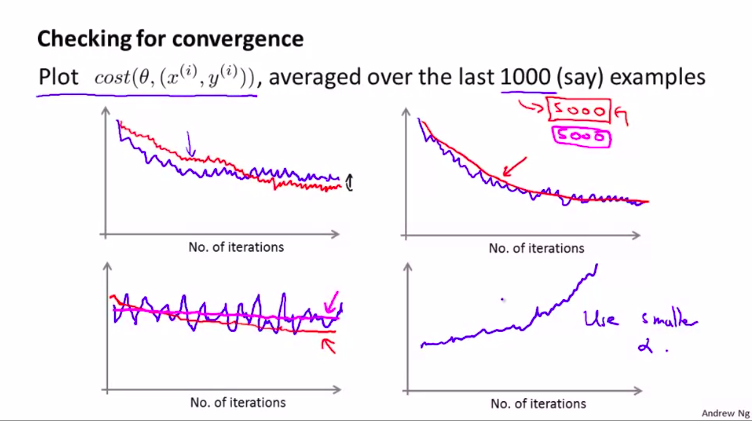
还有一点,我们在学习的时候,一般不会真正的收敛到 全局最小值,而是在它的附近。
但是,如果我们想要得到全局最小值还是可以的。
一种典型的方法就是设置\(\alpha\)的值, 让学习率随时间的变化逐渐减小。
比如:一种典型的方法来设置α的值 。是让α等于某个常数1 除以 迭代次数加某个常数2 。迭代次数指的是你运行随机梯度下降的迭代次数

这样我们观察到的图像可能就不是在全局最小值周围乱晃,而是要收敛到全局最小值的时候,曲线变缓,慢慢靠近全局最小值。
但是,这两个常熟的确定需要更多的工作量,而且我们一般情况下只要能得到很接近全局最小值的参数就已经很满意了。
总结: 我们可以应用这种方法来保证随机梯度下降法正在正常运转和收敛,也可以用它来调整学习速率的大小。
5. Online Learning
在线学习机制
想法:如果你有一个由连续的用户流引发的连续的数据流 用户流进入你的网站 。你能做的是使用一个在线学习机制 从数据流中学习 用户的偏好 。然后使用这些信息 来优化一些 关于网站的决策。
(实时学习算法主张数据算一个丢一个!)
先看一个购物调整价格的例子:

我们先来用逻辑回归
这个数据集并不是固定的了。
所以我们要在线学习算法

差不多就是上面这张图。每当有数据流进来的时候都更新参数
另一个例子:
更新搜索条目
(学习预测点击率CTR(click through rate))

(产品搜索问题)
6. Map Reduce and Data Parallelism
以上讲的 算法都只能在一台计算机上运行。但是,有些机器学习问题,太大以至于不可能只在一台计算机上运行。
所以,我们要介绍一种新的进行大规模机器学习的;另一种方法。称为 映射约减(map reduce)的算法
(可能比梯度下降都还更重要)
基本操作过程就是把数据分开到几个计算机中去处理
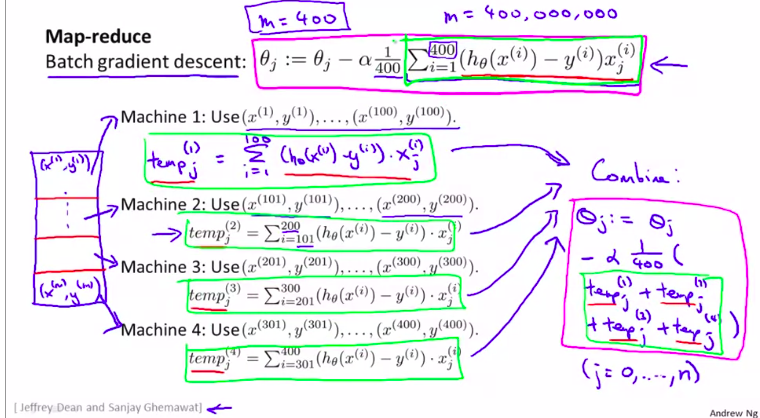
图解:
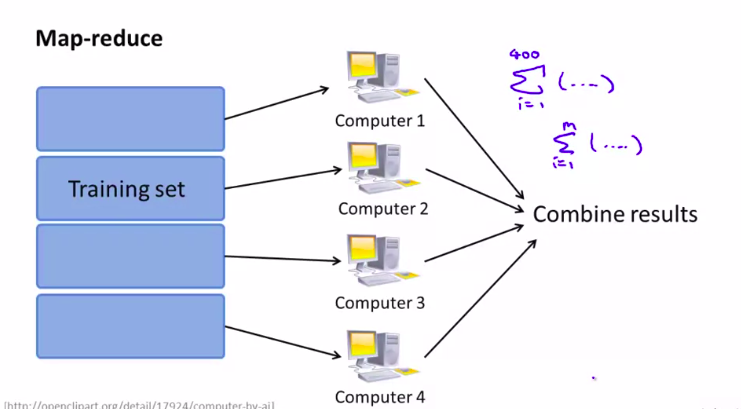
当然,应用映射约减之前,我们要明白我们的机器学习算法是否可以表示为训练样本个的某种求和。

应用实例:

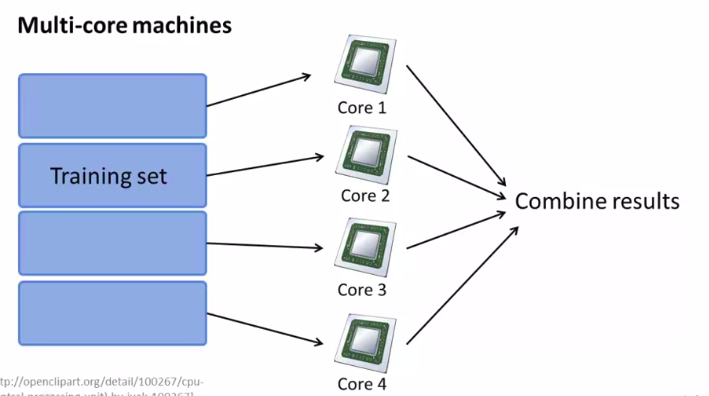
当然,即使我们只有一台计算机也可以用这个映射约减
因为现在的计算机都是多核的!
就相当于多台计算机!
如图:
week_10的更多相关文章
- Week_10 C
拓扑排序 Week_10 C 题意:输入n行数据a,b ,表示a的钱数大于b的钱数,最低的人分的的钱数为888,问最少需要多少钱可以分给员工 思路:标准的拓扑排序,不过这题需要逆向拓扑 注意点 ...
随机推荐
- 洛谷P1884 [USACO12FEB]Overplanting S (矩形切割)
一种矩形切割的做法: 1 #include<bits/stdc++.h> 2 using namespace std; 3 typedef long long LL; 4 const in ...
- 微信DAT文件转JPG图片(图片恢复)
微信电脑版现在已经是日常工作生活必不可少的工具,有时候删除了聊天记录或者被系统清理软件清理了,但还想查看曾经的微信聊天图片. 这个时候辛辛苦苦找到了文件,却发现无法查看,因为微信电脑版为了保护我们的隐 ...
- 【算法】基础DP
参考资料 背包九讲 一.线性DP 如果现在在状态 i 下,它上一步可能的状态是什么. 上一步不同的状态依赖于什么. 根据上面的分析,分析出状态和转移方程.注意:dp 不一定只有两维或者一维,一开始设计 ...
- Linux系统管理_网络管理
常用网络指令 yum -y install net-tools #安装ifconfig工具 ifconfig #查看网络配置 ifup ens33 #启用网卡 ifdown ens33 #禁用网卡 s ...
- JavaBean组件<jsp:forward>动作<jsp:param>动作登录页面输入用户名和密码,然后进入检查页面判断是否符合要求,符合要求跳转到成功界面,不符合要求返回登录界面,显示错误信息。
JavaBean组件 JavaBean组件实际是一种java类.通过封装属性和方法成为具有某种功能或者处理某个业务的对象. 特点:1.实现代码的重复利用.2.容易编写和维护.3.jsp页面调用方便. ...
- 线性表的基本操作(C语言实现)
文章目录 这里使用的工具是DEV C++ 可以借鉴一下 实现效果 顺序存储代码实现 链式存储存储实现 这里使用的工具是DEV C++ 可以借鉴一下 一.实训名称 线性表的基本操作 二.实训目的 1.掌 ...
- servlet过滤器--使用过滤器统计网站访问人数的计数(注解形式)
文章目录 1.什么是过滤器? 2.过滤器核心对象 3.过滤器创建和配置 4.举例子 1.什么是过滤器? 主要用于对客户端的请求进行过滤处理,再将经过过滤后的请求转交给下一个资源. 2.过滤器核心对象 ...
- 齐博x1文本代码标签的使用
文本标签虽然简单,但是使用的地方确实非常多的. {qb:tag name="XXXX" type="text"}推荐新闻{/qb:tag} 类似这种使用的频率是 ...
- Vue ref 和 v-for 结合(ref 源码解析)
前言 Vue 中组件的使用很方便,而且直接取组件实例的属性方法等也很方便,其中通过 ref 是最普遍的. 平时使用中主要是对一个组件进行单独设置 ref ,但是有些场景下可能是通过给定数据渲染的,这时 ...
- vulnhub靶场之NOOB: 1
准备: 攻击机:虚拟机kali.本机win10. 靶机:NOOB: 1,网段地址我这里设置的桥接,所以与本机电脑在同一网段,下载地址:https://download.vulnhub.com/noob ...