ProxySQL(10):读写分离方法论
文章转载自:https://www.cnblogs.com/f-ck-need-u/p/9318558.html
不同类型的读写分离
数据库中间件最基本的功能就是实现读写分离,ProxySQL当然也支持。而且ProxySQL支持的路由规则非常灵活,不仅可以实现最简单的读写分离,还可以将读/写都分散到多个不同的组,以及实现分库sharding(分表sharding的规则比较难写,但也能实现)。
本文只描述通过规则制定的语句级读写分离,不讨论通过 ip/port, client, username, schemaname 实现的读写分离。
下面描述了ProxySQL能实现的常见读写分离类型。
最简单的读写分离
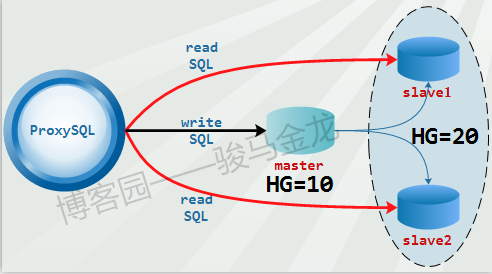
这种模式的读写分离,严格区分后端的master和slave节点,且slave节点必须设置选项read_only=1。在ProxySQL上,分两个组,一个写组HG=10,一个读组HG=20。同时在ProxySQL上开启monitor模块的read_only监控功能,让ProxySQL根据监控到的read_only值来自动调整节点放在HG=10(master会放进这个组)还是HG=20(slave会放进这个组)。
这种模式的读写分离是最简单的,只需在mysql_users表中设置用户的默认路由组为写组HG=10,并在mysql_query_rules中加上两条简单的规则(一个select for update,一个select)即可。
例如,下面实现的就是这种读写分离模式。
mysql_replication_hostgroups:
+------------------+------------------+----------+
| writer_hostgroup | reader_hostgroup | comment |
+------------------+------------------+----------+
| 10 | 20 | cluster1 |
+------------------+------------------+----------+
mysql_servers:
+--------------+----------+------+--------+--------+
| hostgroup_id | hostname | port | status | weight |
+--------------+----------+------+--------+--------+
| 10 | master | 3306 | ONLINE | 1 |
| 20 | slave1 | 3306 | ONLINE | 1 |
| 20 | slave2 | 3306 | ONLINE | 1 |
+--------------+----------+------+--------+--------+
mysql_users:
+----------+-------------------+
| username | default_hostgroup |
+----------+-------------------+
| root | 10 |
+----------+-------------------+
mysql_query_rules:
+---------+-----------------------+----------------------+
| rule_id | destination_hostgroup | match_digest |
+---------+-----------------------+----------------------+
| 1 | 10 | ^SELECT.*FOR UPDATE$ |
| 2 | 20 | ^SELECT |
+---------+-----------------------+----------------------+
这种读写分离模式,在环境较小时能满足绝大多数需求。但是需求复杂、环境较大时,这种模式就太过死板,因为一切都是monitor模块控制的。
多个读组或写组的分离模式
前面那种读写分离模式,是通过monitor模块监控read_only来调整的,所以每一个后端集群必须只能分为一个写组,一个读组。
但如果想要区分不同的select,并将不同的select路由到不同的节点上。例如有些查询语句的开销非常大,想让它们独占一个节点/组,其它查询共享一个节点/组,怎么实现?
例如,下面这种模式。
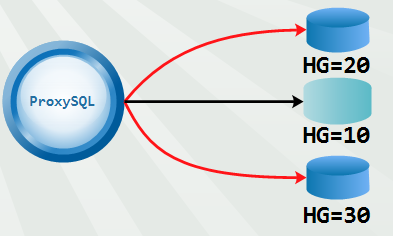
看上去非常简单。但是却能适应各种需求。例如,后端做了分库,对某库的查询要路由到特定的主机组(后文专门分析这种情况)。
至于各个组机组是同一个主从集群(下图左边),还是互相独立的主从集群环境(下图右边),要看具体的需求,不过这种读写分离模式都能应付。
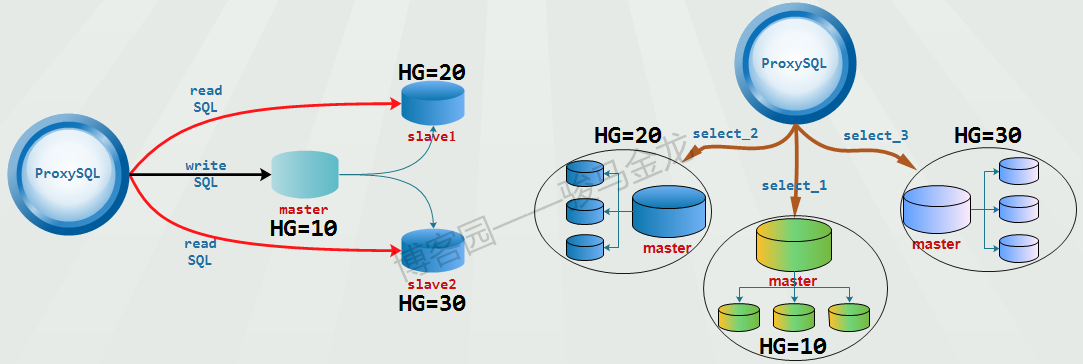
在实现这种模式时,前提是不能开启monitor模块的read_only监控功能,也不要设置 mysql_replication_hostgroup 表。
例如,下面的配置实现的是上图左边的结构:写请求路由给HG=10,对test1库的select语句路由给HG=20,其它select路由给HG=30。
mysql_servers:
+--------------+----------+------+--------+--------+
| hostgroup_id | hostname | port | status | weight |
+--------------+----------+------+--------+--------+
| 10 | host1 | 3306 | ONLINE | 1 |
| 20 | host2 | 3306 | ONLINE | 1 |
| 30 | host3 | 3306 | ONLINE | 1 |
+--------------+----------+------+--------+--------+
mysql_users:
+----------+-------------------+
| username | default_hostgroup |
+----------+-------------------+
| root | 10 |
+----------+-------------------+
mysql_query_rules:
+---------+-----------------------+----------------------+
| rule_id | destination_hostgroup | match_digest |
+---------+-----------------------+----------------------+
| 1 | 10 | ^SELECT.*FOR UPDATE$ |
| 2 | 20 | ^SELECT.*test1\..* |
| 3 | 30 | ^SELECT |
+---------+-----------------------+----------------------+
sharding后的读写分离
ProxySQL对sharding的支持比较弱,要写sharding的路由规则真心觉得有点繁琐。但无论如何,ProxySQL通过定制路由规则是能实现简单的sharding的。这也算是读写分离的一种情况。
如下图,将课程所在库分为三个库:"MySQL"、"python"和"Linux"。当查询条件中的筛选条件是MySQL时,就路由给MySQL库所在的主机组HG=20,筛选条件是Python时,就路由给HG=10,同理HG=30。

找出需要特殊对待的SQL语句
有些SQL语句执行次数较多、性能开销较大、执行时间较长等等,这几类语句都需要特殊对待。例如,将它们路由到独立的节点/主机组,或者为它们开启缓存功能。
本文通过sysbench来模拟,以便为官方手册里的这篇文章提供测试环境。当然,如果您会sysbench或其它性能测试工具,可无视。
1.首先创建测试数据库sbtest。这里我直接连接到后端的MySQL节点创建库和表。
mysqladmin -h192.168.100.22 -uroot -pP@ssword1! -P3306 create sbtest;
2.准备测试表,假设以2张表为例,每个表中10W行数据。填充完后,两张表表名为sbtest1和sbtest2。
SYSBENCH=/usr/share/sysbench/
sysbench --mysql-host=192.168.100.22 \
--mysql-port=3306 \
--mysql-user=root \
--mysql-password=P@ssword1! \
$SYSBENCH/oltp_common.lua \
--tables=1 \
--table_size=100000 \
prepare
3.sysbench连接到ProxySQL,做只读测试。注意下面的选项--db-ps-mode必须设置为disable,表示禁止ProxySQL使用prepare statement,目前ProxySQL还不支持对prepare语句的缓存。不过ProxySQL作者已经将此功能提上日程了。
sysbench --threads=4 \
--time=20 \
--report-interval=5 \
--mysql-host=127.0.0.1 \
--mysql-port=6033 \
--mysql-user=root \
--mysql-password=P@ssword1! \
--db-ps-mode=disable \
$SYSBENCH/oltp_read_only.lua \
--skip_trx=on \
--tables=1 \
--table_size=100000 \
run
由于这时候还没有设置sysbench的测试语句的路由,所以它们全都会路由到同一个主机组,例如默认的组。
4.查看stats_mysql_query_digest表,按照各种测试指标条件进行排序,例如按照总执行时间字段sum_time降序以便找出最耗时的语句,按照count_star降序排序找出执行次数最多的语句,还可以按照平均执行时间降序等等。请参照上面列出的官方手册文章。
例如,此处按照sum_time降序排序:
Admin> SELECT count_star,sum_time,digest,digest_text
FROM stats_mysql_query_digest
ORDER BY sum_time DESC
LIMIT 4;
+------------+----------+--------------------+---------------------------------------------+
| count_star | sum_time | digest | digest_text |
+------------+----------+--------------------+---------------------------------------------+
| 72490 | 17732590 | 0x13781C1DBF001A0C | SELECT c FROM sbtest1 WHERE id=? |
| 7249 | 9629225 | 0x704822A0F7D3CD60 | SELECT DISTINCT c FROM sbtest1 XXXXXXXXXXXX |
| 7249 | 6650716 | 0xADF3DDF2877EEAAF | SELECT c FROM sbtest1 WHERE id XXXXXXXXXXXX |
| 7249 | 3235986 | 0x7DD56217AF7A5197 | SELECT c FROM sbtest1 WHERE id yyyyyyyyyyyy |
+------------+----------+--------------------+---------------------------------------------+
5.对那些开销大的语句,制定独立的路由规则,并决定是否开启查询缓存以及缓存过期时长。
6.写好规则后进行测试。
ProxySQL(10):读写分离方法论的更多相关文章
- MHA+ProxySQL实现读写分离高可用
最近在研究ProxySQL,觉得还挺不错的,所以就简单的折腾了一下,ProxySQL目前也是Percona在推荐的一个读写分离的中间件.关于详细的介绍可以参考官方文档.https://github.c ...
- 如何利用MHA+ProxySQL实现读写分离和负载均衡
摘要:本文分享一下"MHA+中间件ProxySQL"如何来实现读写分离+负载均衡的相关知识. 本文分享自华为云社区<MySQL高可用架构MHA+ProxySQL实现读写分离和 ...
- 重要参考步骤---ProxySQL实现读写分离
MySQL配置主从同步文章地址:https://www.cnblogs.com/sanduzxcvbnm/p/16295369.html ProxySQL实现读写分离与读负载均衡参考文档:https: ...
- MySQL中间件之ProxySQL(10):读写分离方法论
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.不同类型的读写分离 数据库中间件最基本的功能就是实现读写分离,Pr ...
- MySQL架构之 主从+ProxySQL实现读写分离
准备服务器: docker run -d --privileged -v `pwd`/mysql_data:/data -p 3001:3306 --name mysql5-master --host ...
- ProxySQL(读写分离)部署
proxySQL是MySQL的中间件产品,是灵活强大的代理层,实现读写分离,支持Query路由功能,支持动态指定某个SQL进行缓存,支持动态加载配置,故障切换和一些SQL 过滤功能 环境: 192.1 ...
- Linux学习-基于CentOS7的ProxySQL实现读写分离
一.实验环境 主机:3台,一台ProxySQL(192.168.214.37),两台主从复制,master(192.168.214.17),slave(192.168.214.27) 系统:CentO ...
- MySQL使用ProxySQL实现读写分离
1 ProxySQL简介: ProxySQL是一个高性能的MySQL中间件,拥有强大的规则引擎.官方文档:https://github.com/sysown/proxysql/wiki/下载地址:ht ...
- 【DB宝42】MySQL高可用架构MHA+ProxySQL实现读写分离和负载均衡
目录 一.MHA+ProxySQL架构 二.快速搭建MHA环境 2.1 下载MHA镜像 2.2 编辑yml文件,创建MHA相关容器 2.3 安装docker-compose软件(若已安装,可忽略) 2 ...
随机推荐
- Calendar类介绍_获取对象的方式和Calendar类的常用成员方法
java.util.Calendar类:日历类 Calendar类是一个抽象类,里边提供了很多操作日历字段的方法(YEAR.MONTH.DAY_OF_MONTH.HOUR ) Calendar类无法直 ...
- BufferedWniter_字符缓冲输出流和BufferedReader_字符缓冲输入流
java.io.BufferedWriter extends Writer BufferedWriter:字符缓冲输出流 继承自父类的共性成员方法: -void write(int c)写入单个字符 ...
- springboot配置logback.xml
由于springboot框架自带log4j,因此我们只需配置下logback文件,即可, 在main/resources根目录下,新建logback-spring.xml文件,copy下述代码: &l ...
- 4-1 Spring框架基础知识
Spring框架基础知识 1.Spring 框架作用 主要解决了创建对象和管理对象的问题. 自动装配机制 2.Spring 框架 (Spring容器,JavaBean容器,Bean容器,Spring容 ...
- Python常用基础语法知识点大全
记得我是数学系的,大二时候因为参加数学建模,学习Python爬虫,去图书馆借了一本Python基础书,不厚,因为有matlab和C语言基础,这本书一个星期看完了,学完后感觉Python入门很快,然后要 ...
- redis集群的三种方式
Redis三种集群方式:主从复制,哨兵模式,Cluster集群. 主从复制 基本原理 当新建立一个从服务器时,从服务器将向主服务器发送SYNC命令,接收到SYNC命令后的主服务器会进行一次BGSAVE ...
- Modbus转BACnet IP网关
BACnet是楼宇自动化和控制网络数据通信协议的缩写.它是为楼宇自动化网络开发的数据通信协议 根据1999年底互联网上楼宇自动化网络的信息,全球已有数百家国际知名制造商支持BACnet,包括楼宇自 ...
- 心动不如行动,基于Docker安装关系型数据库PostgrelSQL替代Mysql
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_171 最近"全栈数据库"的概念甚嚣尘上,主角就是PostgrelSQL,它最近这几年的技术发展不可谓不猛,覆盖 ...
- 6.15 NOI 模拟
\(T1\ ckr\)与平方数 不会吧,不会吧,真有人不会积分,好吧,我真的一点也不会... 基本公式\(:\) \(1.\)多项式定积分的计算方法 \[f(x)=\sum_{i=0}^nc_ix^i ...
- web前端要学些什么,学习思路
有没有Web前端大神给个意见 我已学了 html css JS 马上要学Vue或React不知道那个好 需不需要先了解一下jQuery 还需要学些什么