延申三大问题中的第三个问题处理---发布更新时先把服务从注册中心给down下来,等待一段时间后再能更新模块
一开始采取的思路大致如下:
在preStop中使用/bin/sh命令,先down 然后sleep一段时间,
这种思路的执行情况如下:
假若升级容器使用的镜像版本的话,先执行preStop中的命令,sleep设定的时间,在花费删除pod时的默认30秒等待时间,然后才会开始拉取新的镜像,创建新pod
如下所示:
lifecycle:
postStart:
exec:
command: ["/bin/sh","-c","curl -v -X PUT http://cloud-eureka-0.cloud-eureka.test.svc.cluster.local:8761/eureka/apps/HKD-CONFIG/cloud-config-0.cloud-config.test.svc.cluster.local:hkd-config:8888/status?value=UP;sleep 300;"]
preStop:
exec:
command: ["/bin/sh","-c","curl -v -X PUT http://cloud-eureka-0.cloud-eureka.test.svc.cluster.local:8761/eureka/apps/HKD-CONFIG/cloud-config-0.cloud-config.test.svc.cluster.local:hkd-config:8888/status?value=DOWN;sleep 300;"]
但是这种情况下这个等待时间不好把握,因此可以换一种思路来处理
一般情况下这种操作是针对升级/回滚采用的,也就是说换成不同的容器镜像,因此可以利用删除pod默认有等待时间这个功能
在preStop中只是使用命令把服务从注册中心给down掉,然后修改删除pod默认的这个等待时间,这个默认等待时间是30秒,修改成300秒
这样一来,升级服务的话也就是升级容器使用的docker镜像版本,先把服务从注册中心给down掉,然后等待300秒再删除这个pod,而不是等待30秒就删除这个pod
Pods 的终止流程
1.用户发送一个删除 Pod 的命令, 并使用默认的宽限期(30s)。
2.把 API server 上的 pod 的时间更新成 Pod 与宽限期一起被认为 “dead” 之外的时间点。
3.使用客户端的命令,显示出的Pod的状态为 ”terminating”。
4.(与第3步同时发生)Kubelet 发现某一个 Pod 由于时间超过第2步的设置而被标志成 terminating 状态时, Kubelet j将启动一个停止进程。
1.如果 pod 已经被定义成一个 preStop hook,这会在 pod 内部进行调用。如果宽限期已经过期但 preStop 锚依然还在运行,将调用第2步并在原来的宽限期上加一个小的时间窗口(2 秒钟)。
2.把 Pod 里的进程发送到 TERM 信号。
5.(与第3步同时发生),Pod 被从终端的服务列表里移除,同时也不再被 replication controllers 看做时一组运行中的 pods. 在负载均衡(比如说 service proxy)会将它们从轮做中移除前, Pods 这种慢关闭的方式可以继续为流量提供服务。
6.当宽期限过期时, 任何还在 Pod 里运行的进程都会被 SIGKILL 杀掉。
7.Kubelet 通过在 API server 把宽期限设置成0(立刻删除)的方式完成删除 Pod的过程。 这时 Pod 在 API 里消失,也不再能被用户看到。
默认所有的宽期限都在30秒内。kubectl delete 命令支持 --grace-period= 选项,这个选项允许用户用他们自己指定的值覆盖默认值。值’0‘代表 强制删除 pod. 在 kubectl 1.5 及以上的版本里,执行强制删除时必须同时指定 --force , --grace-period=0。
强制删除 pods
强制删除一个 pod 是从集群状态还有 etcd 里立刻删除这个 pod. 当 Pod 被强制删除时, api 服务器不会等待来自 Pod 所在节点上的 kubelet 的确认信息:pod 已经被终止。在 API 里 pod 会被立刻删除,这样新的 pod 就能被创建并且使用完全一样的名字。在节点上, pods 被设置成立刻终止后,在强行杀掉前还会有一个很小的宽限期。
最多可以容忍的时间
K8s 的 Pod 终止流程中还有一个“最多可以容忍的时间”,即 grace period(在 Pod 的 .spec.terminationGracePeriodSeconds 字段中定义),这个值默认是 30 秒,我们在执行 kubectl delete 的时候也可通过 --grace-period 参数显式指定一个优雅退出时间来覆盖 Pod 中的配置。而当 grace period 超出之后,K8s 就只能选择 SIGKILL 强制干掉 Pod 了。
在如下这个界面上能找到这个字段,但是不是在这儿编辑的
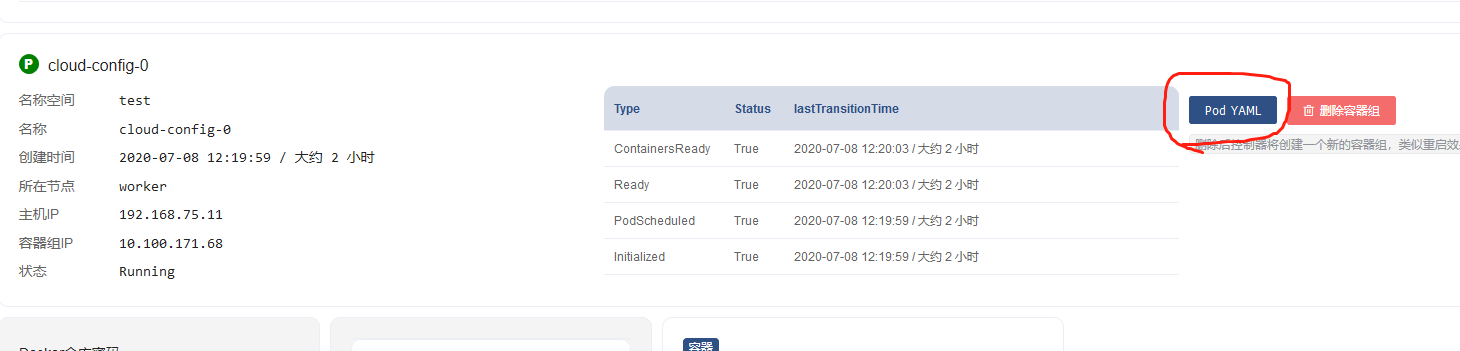
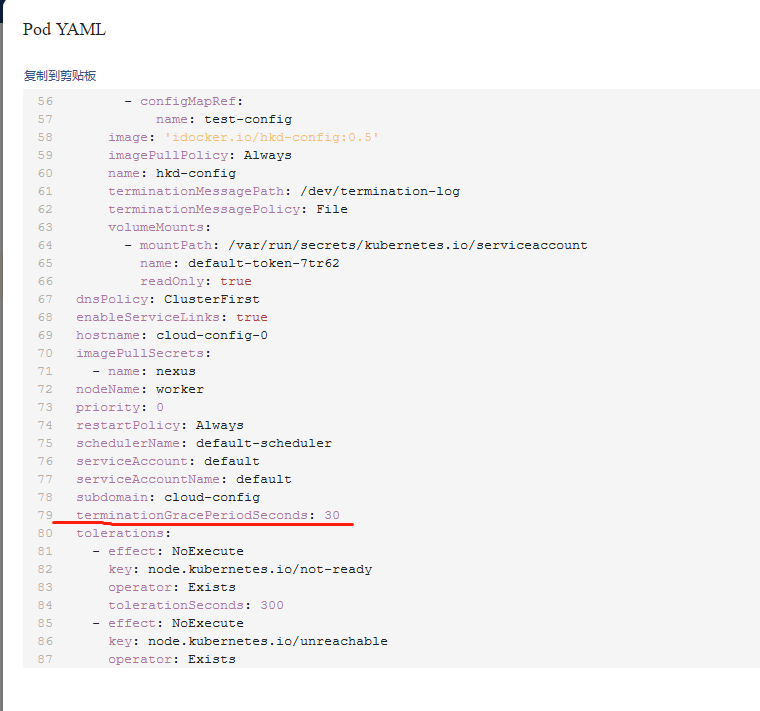
是在容器组这儿进行编辑的
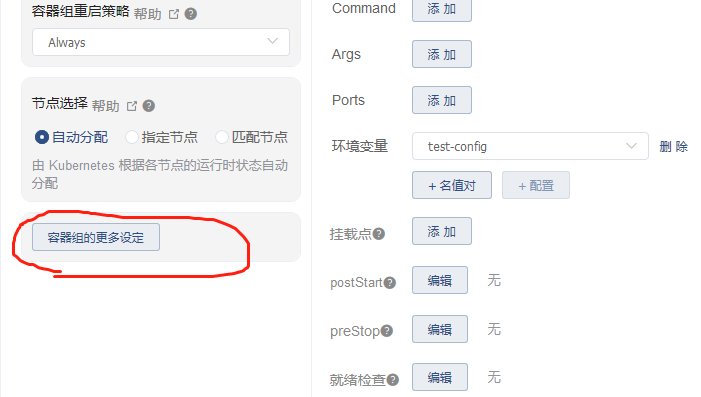
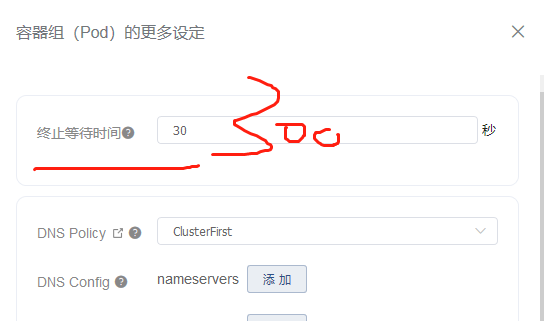
或者直接编辑这个yaml文件
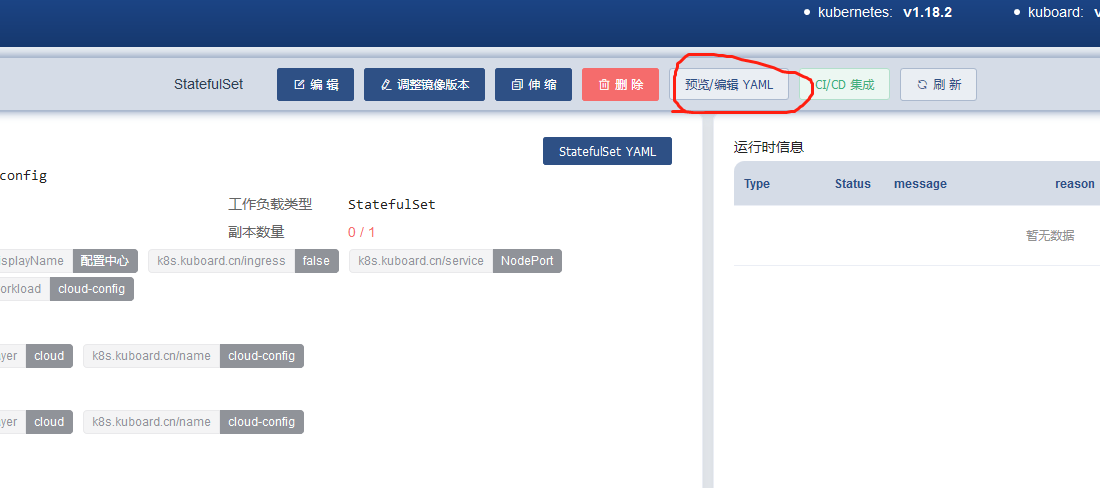
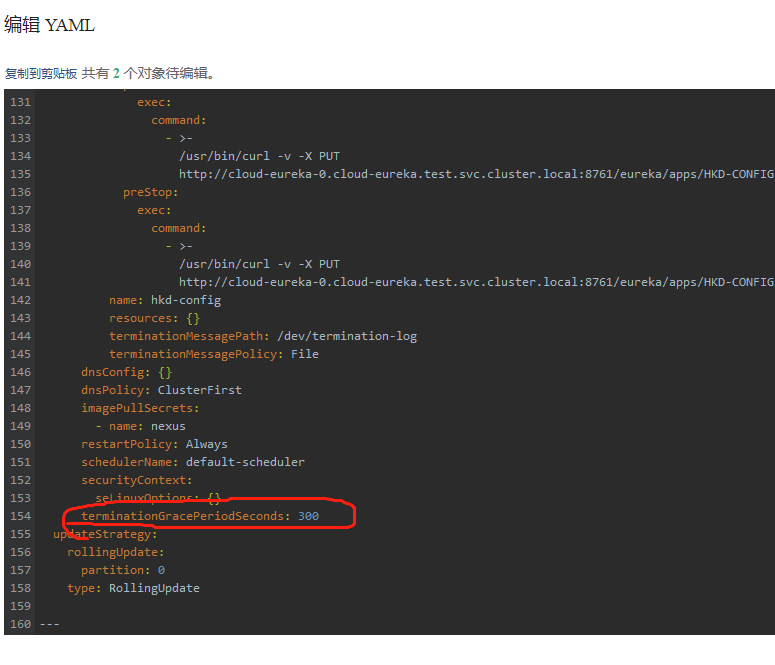
解决这个问题的完整步骤如下:
1.在创建这个pod应用的时候,找到容器组设置,修改这个时间,比如修改成300秒
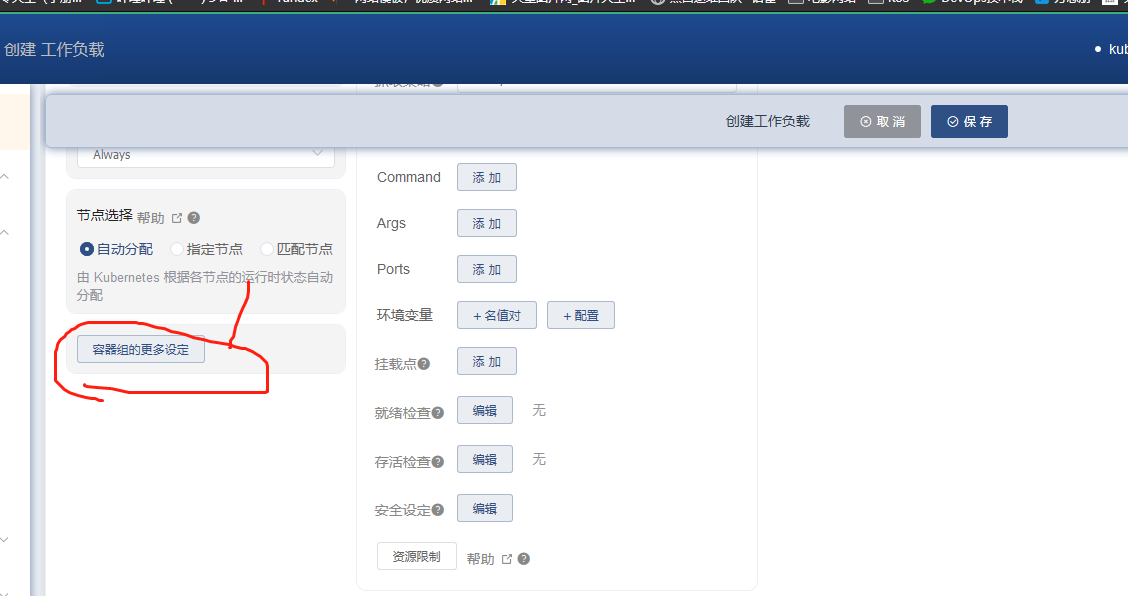
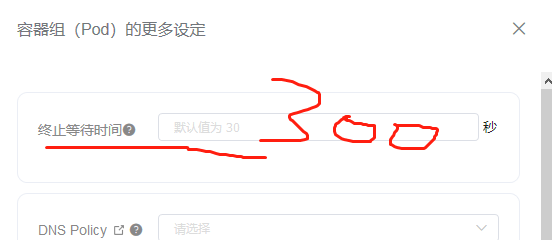
注意查看上一张图片,会发现没有postStart和preStop,因此只能是先创建好pod后,然后再修改,这时候就会显示这两个了
2.修改这个应用pod,设置postStart和preStop
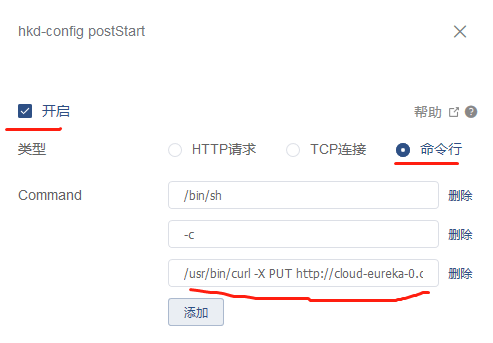
第一行命令是:/bin/sh
第二行命令是: -c
第三行命令是:/usr/bin/curl -v -X PUT http://cloud-eureka-0.cloud-eureka.test.svc.cluster.local:8761/eureka/apps/HKD-CONFIG/cloud-config-0.cloud-config.test.svc.cluster.local:hkd-config:8888/status?value=UP
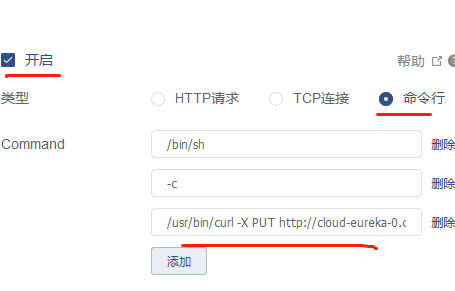
第一行命令是:/bin/sh
第二行命令是: -c
第三行命令是:/usr/bin/curl -v -X PUT http://cloud-eureka-0.cloud-eureka.test.svc.cluster.local:8761/eureka/apps/HKD-CONFIG/cloud-config-0.cloud-config.test.svc.cluster.local:hkd-config:8888/status?value=DOWN
到此时就可以了
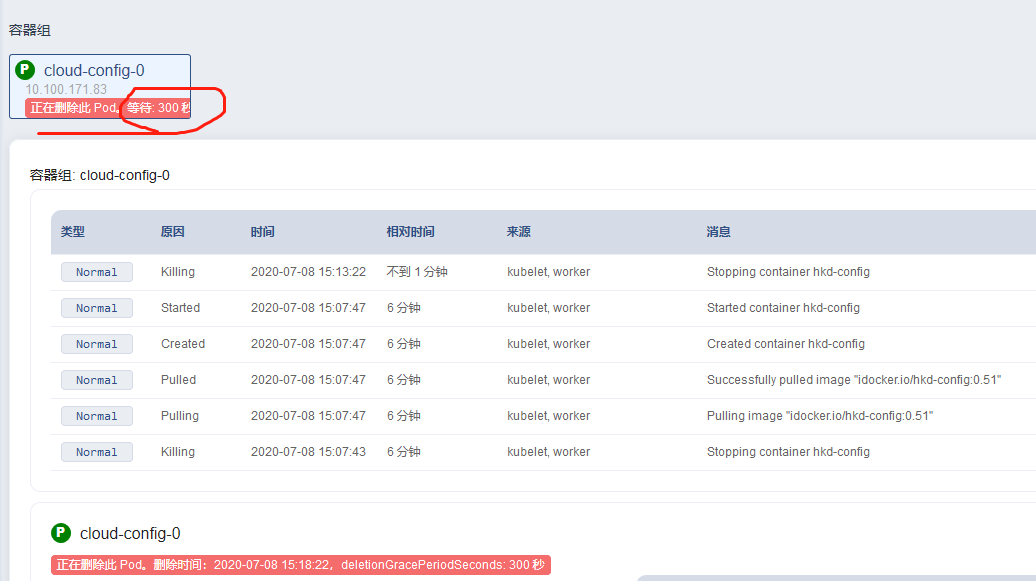
查看效果,比如删除这个pod,观察界面显示以及eureka日志等
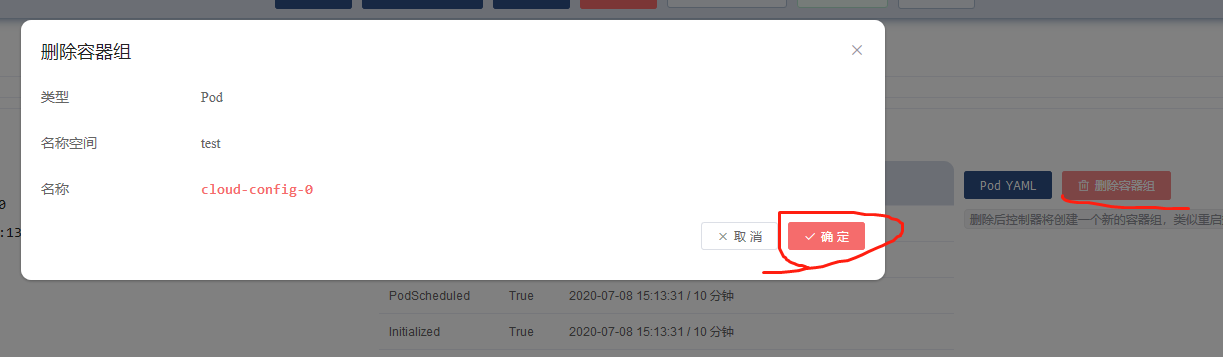
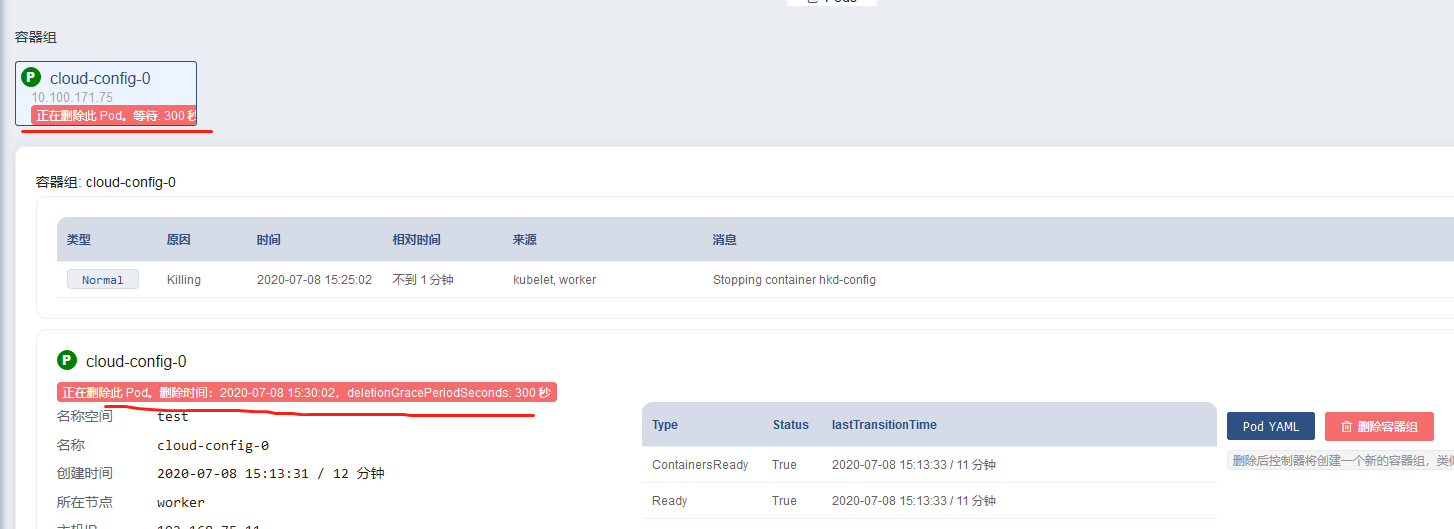
问题:实践发现,就算修改了这个默认的等待时间,当删除pod时这个时间不生效
最终解决办法
还是通过preStop命令行的方式,增加上sleep,只不过命令写法有些不同
如下所示:
lifecycle:
postStart:
exec:
command: ["/bin/sh","-c","/usr/bin/curl -v -X PUT http://cloud-eureka-0.cloud-eureka.test.svc.cluster.local:8761/eureka/apps/HKD-CONFIG/cloud-config-0.cloud-config.test.svc.cluster.local:hkd-config:8888/status?value=UP && sleep 300"]
preStop:
exec:
command: ["/bin/sh","-c","/usr/bin/curl -v -X PUT http://cloud-eureka-0.cloud-eureka.test.svc.cluster.local:8761/eureka/apps/HKD-CONFIG/cloud-config-0.cloud-config.test.svc.cluster.local:hkd-config:8888/status?value=DOWN && sleep 300"]
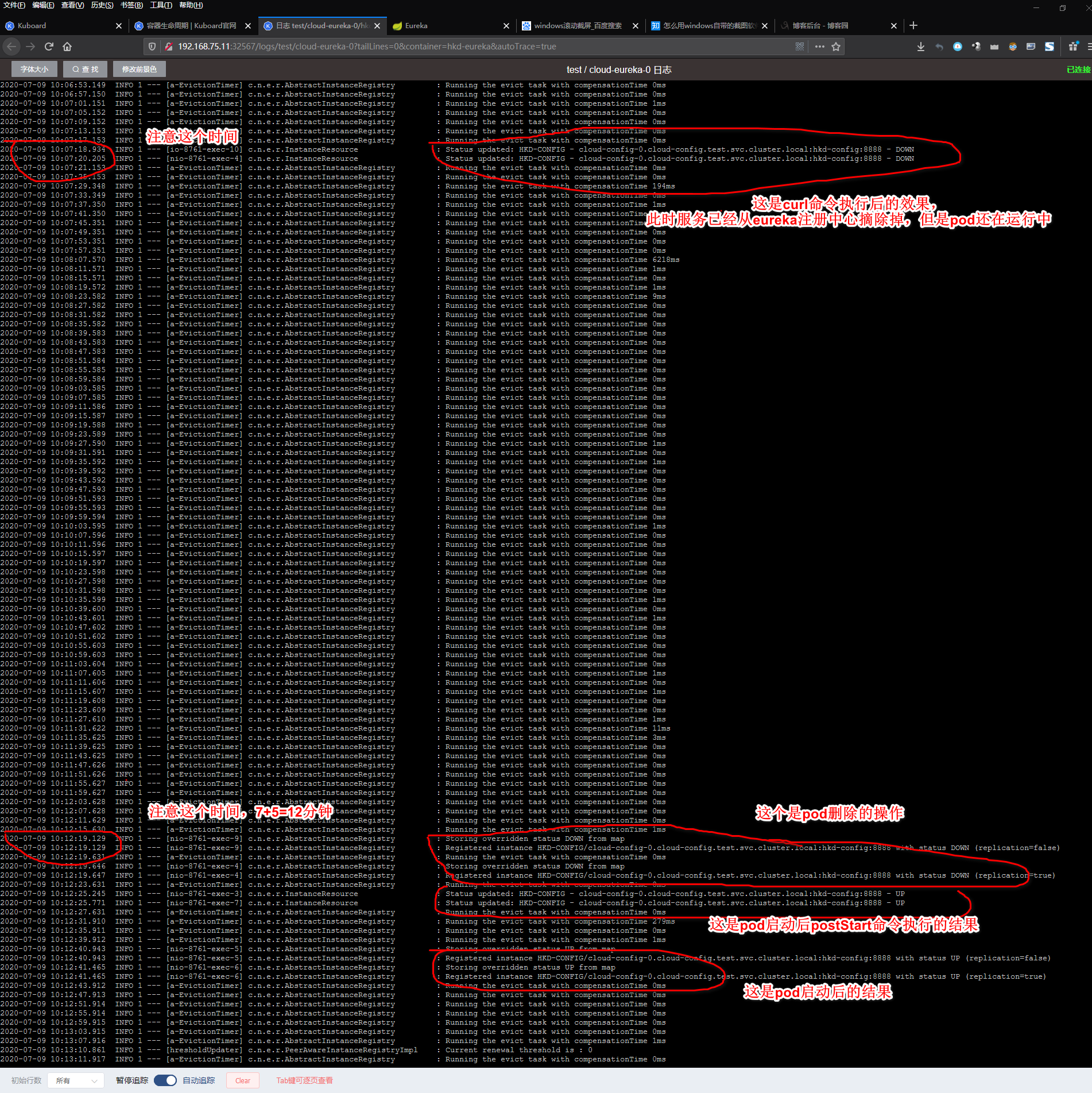
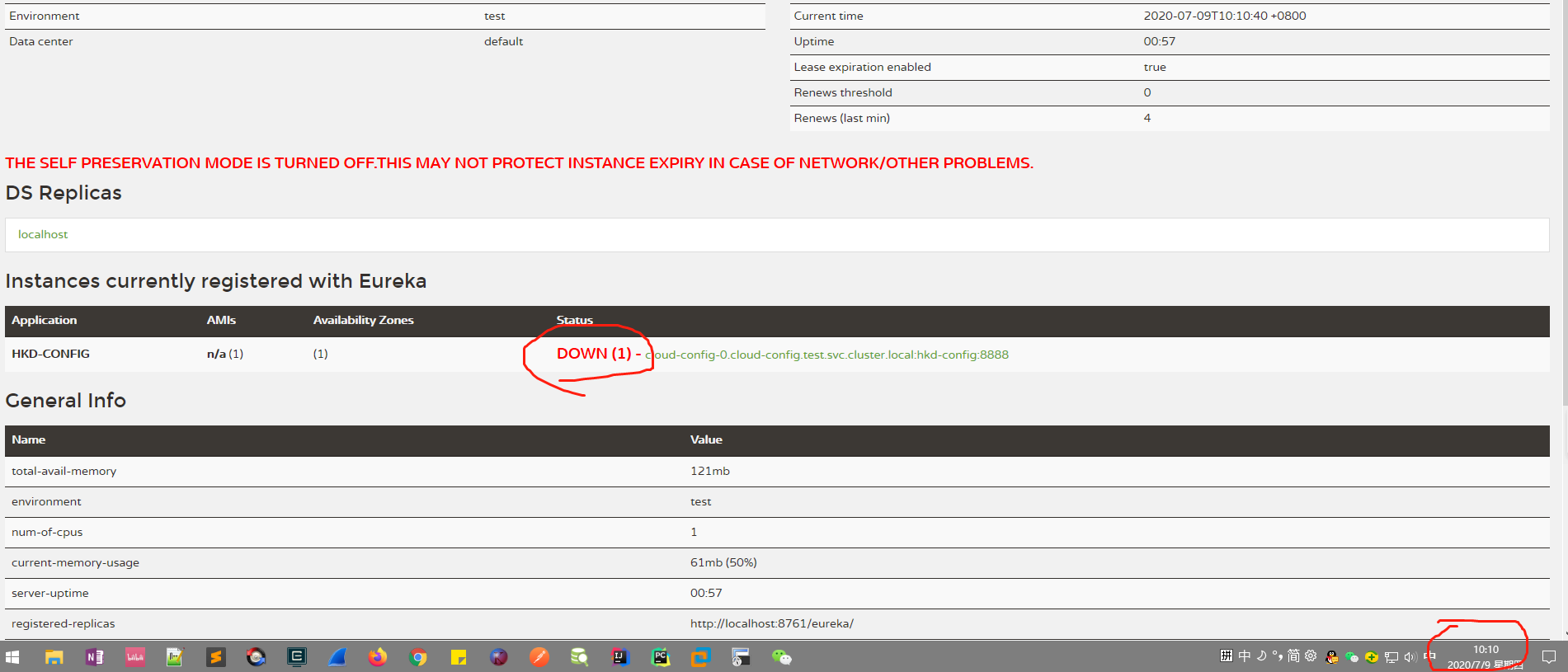
然后更新使用的镜像,或者删除pod等操作,就会开始先执行preStop中的命令,把服务从eureka注册中心给摘除,显示down,然后就会等待300秒的时间,过了300秒才开始删除pod,启动新pod
界面显示的等待时间
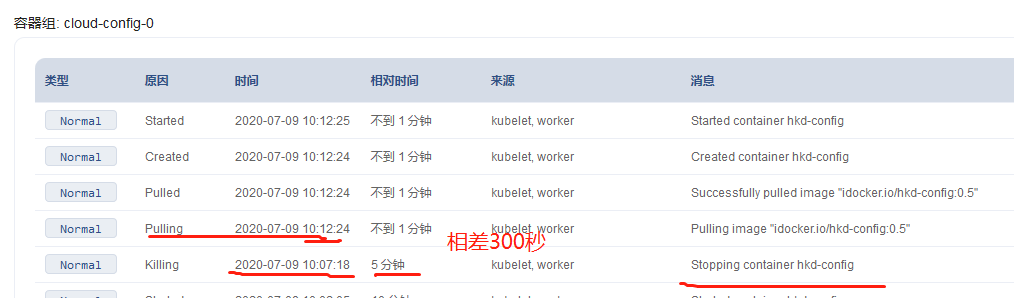
eureka日志中的显示
eureka界面显示,只要在10:07-10:12,这5分钟之间的时间服务状态是down
延申三大问题中的第三个问题处理---发布更新时先把服务从注册中心给down下来,等待一段时间后再能更新模块的更多相关文章
- 延申三大问题中的第二个问题处理---收集查看k8s中pod的控制台日志
1.不使用logstash 2.步骤: 2.1 先获取一个文件的日志 2.2 再获取多个文件的日志 2.3 批量获取文件日志 pod日志文件路径 [root@worker hkd-eureka]# p ...
- 延申三大问题中的第一个问题处理---原先shell脚本中启动jar文件命令的配置,附加参数等
经过一系列的试错,最终采用的解决办法如下: 采用的配置文件 附加的启动参数 或者把这些都给统一添加到ConfigMap中
- JAVA中实现让程序等待一段时间的方法
JAVA中想让代码等待一段时间再继续执行,可以通过让当前线程睡眠一段时间的方式. 方法一:通过线程的sleep方法. Thread.currentThread().sleep(1000); 在需要程序 ...
- TensorFlow实现Softmax Regression识别手写数字中"TimeoutError: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败”问题
出现问题: 在使用TensorFlow实现MNIST手写数字识别时,出现"TimeoutError: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应 ...
- VMware 中的win7虚拟机在一段时间后就会自动挂起
VMware workstation 中的win7虚拟机在一段时间不用后就会自动挂起. 其实这不是VMware workstation 的问题,而是win7的问题.关闭win7系统 的自动休眠功能即可 ...
- C#中WebService 的 Timer定时器过段时间后自动停止运行
我用.net做的一个Timer定时器,定时获取短信并给予回复,但大概过了十几个小时以后,Timer定时器会自动停止,再发送短信就不能收到回复,需要在服务器中重新运行定时器才可以,请教各位! 我是在.n ...
- 解决老项目中 Timer运行一段时间后失效的问题
那是因为Timer中的代码出现了异常未被捕获,所以线程被挂起 只需要加入 try catch即可 推荐使用 Quartz 2018-08-08 03:50:44 [ Timer-1:39366015 ...
- 为什么一段时间后网站后台自动退出 php中session过期时间设置
修改php配置文件中的session.gc_maxlifetime.如果想了解更多session回收机制,继续阅读.(本文环境php5.2) 概述:每一次php请求,会有1/100的概率(默认值)触发 ...
- C#中通过调用Dll函数时,执行一段时间后,就会报内存可能被破坏的错的解决办法
遇到同样的问题,已经解决的:http://blog.csdn.net/youxiazzz12/article/details/24313347
随机推荐
- redis 集群 slots are covered by nodes.
原因数据数据损坏.需要修复 1.检测 redis-cli --cluster check 127.0.0.1:7000 2.检测结果 slots are covered by nodes3.进行修复 ...
- Restarting network (via systemctl): Job for network.service failed because the control process exited with error code. See "systemctl status network.service" and "journalctl -xe" for details.
编辑完 ip地址,要重启网络 sudo service network restart 结果返回错误,错误如下 Restarting network (via systemctl): Job for ...
- MySQL主从复制及读写分离
MySQL主从复制 MySQL数据库自身提供的主从复制功能可以方便的实现数据的多处自动备份,实现数据库的拓展.多个数据备份不仅可以加强数据的安全性,通过实现读写分离还能进一步提升数据库的负载性能. M ...
- 函数式接口的概念&函数式接口的定义和函数式接口的使用
函数式接口概念 函数式接口在Java中是指:有且仅有一个抽象方法的接口. 函数式接口,即适用于函数式编程场景的接口.而Java中的函数式编程体现就是Lambda,所以函数式接口就是可以适用于Lambd ...
- 迷宫类dp整合
这是迷宫类dp我自己取的名字,通常比较简单,上货 简单模型 数字三角形 状态表示:f[i][j]表示起点第\(i\)行第\(j\)个数最短路径的长度 状态转移:\(f[i][j] = max(f[i ...
- 在 macOS 上搭建 Flutter 开发环境
下载 Flutter SDK flutter官网下载:https://flutter.io/sdk-archive/#macos 若上述链接无法访问,可通过GitHub下载 https://githu ...
- 浅谈 Lucas 定理
Lucas 定理是用来求 \(C^n_m\bmod p\) 的. 定理 \[C^n_m\equiv C^{n\bmod p}_{m\bmod p}\cdot C^{\lfloor n/p\rfloor ...
- 使用jmh框架进行benchmark测试
性能问题 最近在跑flink社区1.15版本使用json_value函数时,发现其性能很差,通过jstack查看堆栈经常在执行以下堆栈 可以看到这里的逻辑是在等锁,查看jsonpath的LRUCach ...
- 活动报名|对话贡献者:DolphinScheduler x Pulsar 在线 Meetup
各位 DolphinScheduler 和 Pulsar 社区的小伙伴们,Apache DolphinScheduler x Pulsar 在线 Meetup 来啦! 导语 大数据任务调度.消息流的订 ...
- java-运算符以及简单运用
运算符: 1)赋值运算符:= 2)算术运算符:+-*/%,++,-- 3)关系运算符:>,<,>=,<=,==,!= boolean 4)逻辑运算符:&&,|| ...