GaussDB(for MySQL) :Partial Result Cache,通过缓存中间结果对算子进行加速
摘要:华为云数据库高级内核技术专家详解GaussDB(for MySQL)Partial Result Cache特性,如何通过缓存中间结果对算子进行加速?
本文分享自华为云社区《GaussDB创新特性解读:Partial Result Cache,通过缓存中间结果对算子进行加速》,作者:GaussDB 数据库 。

为了加速查询性能,传统的关系型数据库,比如Oracle、DB2,都有结果集缓存的特性,用来缓存一条查询语句的结果集。如果后续同样的语句被查询,数据库将直接从结果集缓存中获取结果,而不用再重新执行该查询。MySQL 在4.0版本中也引入了结果集缓存Query cache,但是在设计上有局限性,具体如下:
- Query cache针对单个查询,任何一个表做了修改,如果影响到结果集就需要刷新或者失效。
- Query cache对隔离级别有依赖,不同的隔离级别产生的结果集不一样。
- Query cache需要对所有数据进行缓存,如果表结果比较大的话,缓存需要占据较大的内存或者写入磁盘。
这也导致了该特性在MySQL 8.0版本被移除。
鉴于结果集缓存对查询性能的增益,我们在GaussDB(for MySQL)引入Partial result cache这一新特性,简称PTRC。顾名思义,这也是一个结果集缓存特性。不同于传统的结果集缓存,PTRC是用来辅助单个查询的内部算子的执行。也就是说PTRC粒度更小,是对查询内部的某个算子的中间结果进行缓存,从而起到算子加速的作用。
这里的Partial 有两层概念:

从这两点可以看出,PTRC是与单个查询相关的,生命周期从查询开始到查询结束,自动终止。由于它是对算子进行加速,所以一个查询内部可以有多个PTRC。只要优化器根据代价计算,认为该算子适合PTRC,那么优化器就会为该算子引入PTRC。
PTRC如何确定对算子并加速?
这里我们引入一个新概念:参数化的重复扫描,指的是扫描算子根据参数的不同进行算子扫描。比如Nested Loop Join,对于外表扫描的每一条数据,内表会根据JOIN条件进行扫描,那么对于内表来说就是一次“参数化的重复扫描”。再比如correlated subquery,对于父查询的每一次扫描都会根据父查询的结果集调用子查询执行,然后返回子查询的结果集。
PTRC是如何工作的?
如前所述,PTRC是缓存算子的中间结果集,那么也和其他cache一样,将数据以key ,value的方式缓存到cache中,通过key来命中,得到value。那么PTRC的相关key和value是如何获取的?
下面我们以Correlated subquery为例做简单分析,查询语句如下:
SELECT *
FROM t1
WHERE t1.a IN (SELECT a
FROM t2,
t3
WHERE t2.b = t1.b
AND t2. c > t3.d);
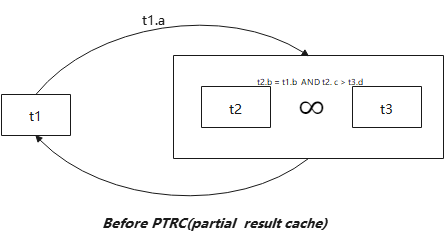
上图是子查询使用EXISTS策略执行的流程图。可以看出:对于数据表t1中的每一条数据,都会驱动子查询执行,直到数据表t1中的所有记录都循环结束。对于数据表t1中的每一条记录对应的t1.a,都需要根据该列值重新扫描子查询,进而判断子查询的返回值。
我们通过EXPLAIN来对比引入PTRC前后执行计划的差异:
EXPLAIN format=tree
SELECT *
FROM t1
WHERE t1.a IN (SELECT a
FROM t2,
t3
WHERE t2.b = t1.b
AND t2. c > t3.d);
-> Filter: <in_optimizer>(t1.a,<exists>(select #2)) (cost=0.35 rows=1)
-> Table scan on t1 (cost=0.35 rows=1)
-> Select #2 (subquery in condition; dependent)
-> Result cache : cache keys(t1.a, t1.b)
-> Limit: 1 row(s) (cost=0.80 rows=1)
-> Filter: (t2.c > t3.d) (cost=0.80 rows=1)
-> Inner hash join (no condition) (cost=0.80 rows=1)
-> Table scan on t3 (cost=0.35 rows=2)
-> Hash
-> Filter: ((t2.b = t1.b) and (<cache>(t1.a) = t2.a)) (cost=0.35 rows=1)
-> Table scan on t2 (cost=0.35 rows=1)
可以看出引入PTRC后,多了一个算子Result cache(标红部分),表明该算子当前的子查询引入了PTRC,引入后的执行流程变更为:
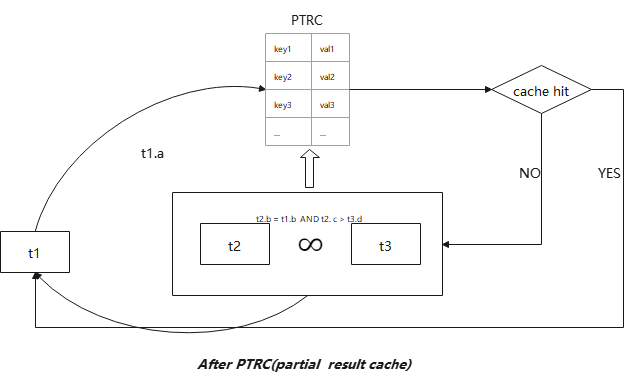
引入PTRC后,对于数据表t1中的每一条数据对应的t1.a列值,优先查看PTRC,如果命中,直接从PTRC中获取结果集,而不需要执行子查询。如果未命中,需要按原来的方式继续执行子查询,子查询执行的结果会储存到PTRC中。如果下一次同样的列值来驱动执行子查询,可以直接从PTRC获取。
优化器如何选择PTRC?
优化器在为算子选择PTRC的时候会依赖代价估算,主要是看命中率(命中率 = 不同键值的行数/键值的总行数), 如果命中率大于rds_partial_result_cache_cost_threshold(具体含义参考下文的系统变量介绍)变量定义的最小代价,PTRC将会被选择,反之则不会被选择。是否选择了PTRC,可以通过Explain format=tree或者Explain analyze来观察实际的命中情况。我们通过一个例子来说明:
EXPLAIN analyze
SELECT *
FROM t1
WHERE t1.a IN (SELECT a
FROM t2,
t3
WHERE t2.b = t1.b
AND t2. c > t3.d);
-> Filter: <in_optimizer>(t1.a,<exists>(select #2)) (cost=0.35 rows=1) (actual time=3800.595..3800.595 rows=0 loops=1)
-> Table scan on t1 (cost=0.35 rows=1) (actual time=0.064..0.093 rows=1 loops=1)
-> Select #2 (subquery in condition; dependent)
-> Result cache : cache keys(t1.a, t1.b) (Cache Hits: 0, Cache Misses:1, Cache Evictions: 0, Cache Overflows: 0, Memory Usage: 40960 ) (actual time=0.115..0.115 rows=0 loops=1)
-> Limit: 1 row(s) (cost=0.80 rows=1) (actual time=0.094..0.094 rows=0 loops=1)
-> Filter: (t2.c > t3.d) (cost=0.80 rows=1) (actual time=0.093..0.093 rows=0 loops=1)
-> Inner hash join (no condition) (cost=0.80 rows=1) (actual time=0.092..0.092 rows=0 loops=1)
-> Table scan on t3 (cost=0.35 rows=2) (never executed)
-> Hash
-> Filter: ((t2.b = t1.b) and (<cache>(t1.a) = t1.a)) (cost=0.35 rows=1) (actual time=0.039..0.039 rows=0 loops=1)
-> Table scan on t2 (cost=0.35 rows=1) (actual time=0.038..0.038 rows=0 loops=1)
从Result cache这个算子后面可以看到:
- Cache Hits: 0,表示命中的次数为0
- Cache Misses:1,表示没有命中的次数为1
- Cache Evictions: 0,表示使用LRU淘汰的记录数
- Cache Overflows: 0,表示内存overflow的次数
- Memory Usage: 40960,表示当前查询使用的内存量
由于优化器使用代价估算来计算是否使用PTRC,如果估算错误的话,PTRC还是有额外的代价,比如创建自身的一些数据结构,以及记录的拷贝。为了尽可能的保证查询的性能,PTRC采取了动态反馈的方式来查看PTRC在实际执行的过程中是否继续使用。PTRC会自动判断命中率是否适合保留PTRC,优化器根据没有命中的次数,每隔rds_partial_result_cache_hit_ratio_frequency会检查命中率是否低于rds_partial_result_cache_min_hit_ratio。如果低于该值,优化器会自动禁止继续使用PTRC。
优化器如何限制PTRC的内存使用
由于单个查询可以有多个PTRC算子,每个算子都会使用内存来存储缓存数据,那么控制PTRC内存使用就非常有必要,以防止内存OOM。
通过系统变量rds_partial_result_cache_max_mem_size来定义每个查询所使用的所有PTRC算子使用的最大内存。如果PTRC使用的内存总数超过该值,优化器会根据LRU算法来进行淘汰。如果通过LRU算法可以找到适合当前存储记录的大小的记录进行淘汰,当前记录可以进行缓存,否则当前记录将不被缓存。
PTRC如何配置?
首先,PTRC默认是开启的,可以通过Optimizer_switch中的partial_result_cache选项更改设置:设置为ON,启用PTRC,否则就关闭。通过下表中的4个系统变量,对PTRC进行具体设置。

PTRC性能测试
下面是我们使用TPCH的Q17来测试不同数据量下启用PTRC前后的性能变化。
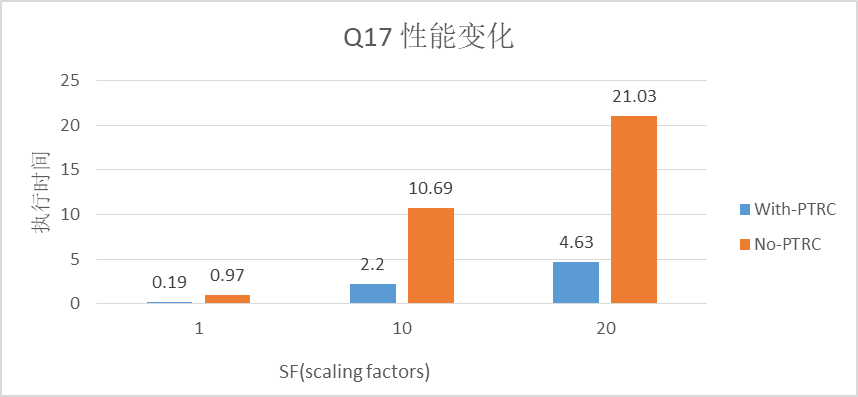
由于PTRC是一个cache,所以命中率越高性能提升就会越高。当然如果PTRC相关的算子执行代价越高的话,那么PTRC获取的性能提升也是越高的。
MariaDB的subquery cache是对重复扫描算子correlated subquery进行加速引入的一个特性,我们参照MariaDB的subquery cache测试样例,同样基于dbt-3 scale 1 数据集,测试PTRC对于correlated subquery的加速效果。
由于MySQL和MariaDB索引创建的不同,执行时间与MariaDB不同,这里只需要关注相对时间即可。测试结果如下表所示:
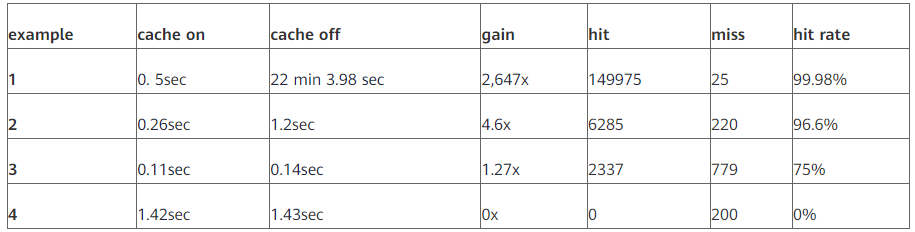
可以看出:上表中最后一行命中率为0的情况下,PTRC默认值检查如果miss了200条之后,会触发检查命中率,发现命中率太低了,所以PTRC自动失效了,所以可以看到miss列里只有200条。
MariaDB的测试样例和结果请参考:https://mariadb.com/kb/en/subquery-cache/#performance-impact。
PTRC对于参数化的重复扫描都可以进行适配,只要命中率足够,就可以加速执行。对于查询中的多种算子包括Correlated Subquery, Nested Loop Join, Semijoin, Antijoin都有加速作用。PTRC已经正式上线,欢迎大家使用。
GaussDB(for MySQL) :Partial Result Cache,通过缓存中间结果对算子进行加速的更多相关文章
- mysql query cache 查询缓存
查看本博文,并进行验证(验证结果与博文一致): https://blog.csdn.net/carmazhao/article/details/7088530 mysql默认是开启查询缓存的. 设置查 ...
- 011-MySQL Query Cache 查询缓存设置操作
一.概述 MySQL Query Cache 会缓存select 查询,安装时默认是开启的,但是如果对表进行INSERT, UPDATE, DELETE, TRUNCATE, ALTER TABLE, ...
- System.Web.Caching.Cache类 缓存
1.文件缓存依赖 public partial class _Default : System.Web.UI.Page { protected void Page_Load(object sender ...
- MySQL 之 query cache
早上一打开网站,就看到了Percona官网发布的最新的关于 mysql query cache的文章: https://www.percona.com/blog/2015/08/07/mysql-qu ...
- oracle 11g 之 result cache
oracle 11g 之 result cache 今天是2013-10-12,打算最近时间研究一下shared pool的相关原理以及awr报告分析.今天学习一下在oracle 11g shared ...
- System.Web.Caching.Cache类 缓存 各种缓存依赖
原文:System.Web.Caching.Cache类 缓存 各种缓存依赖 Cache类,是一个用于缓存常用信息的类.HttpRuntime.Cache以及HttpContext.Current.C ...
- Cache类缓存
此处主要总结System.Web.Caching.Cache类 该类是用于存储常用信息的类,HttpRuntime.Cache以及HttpContext.Current.Cache都是该类的实例. 该 ...
- Guava Cache 本地缓存组件浅析
cache组件中核心的类和接口列举如下: 接口: Cache 本地缓存的顶级接口,提供一些对缓存进行get,put的方法,以及获取缓存统计数据的方法等. LoadingCache 继承了Cache接口 ...
- lua模块demo(redis,http,mysql,cjson,本地缓存)
1. lua模块demo(redis,http,mysql,cjson,本地缓存) 1.1. 配置 在nginx.conf中设置lua_shared_dict my_cache 128m; 开启ngi ...
随机推荐
- 腾讯云服务器ssh登录老是自动断开链接的解决办法
vim /etc/ssh/sshd_config 找到下面两行 #ClientAliveInterval 0 #ClientAliveCountMax 3 去掉注释,改成 ClientAliveInt ...
- 4.25JMster环境搭建、webxml及测试平台练习
1.Java环境搭建 右击电脑属性--高级设置--环境变量--系统变量--新建(输入JAVA_HOME.C:\Program Files\Java\jdk1.8.0_91---CLASSPATH..; ...
- 宝藏发现之API接口高效协作神器Apifox
概述 背景 Apifox官方地址 https://www.apifox.cn/ 前面文章我们已经围绕微服务展开,缺少一个关键前置流程,那就是API接口设计,而在API接口设计开始前本篇先推荐一个非常好 ...
- Oracle 常用运维命令整理
点击上方"开源Linux",选择"设为星标" 回复"学习"获取独家整理的学习资料! 一.oracle建库与删库命令 (1)oracle11g ...
- CentOS 8 重启不能DHCP获取IP的解决方法
一个执着于技术的公众号 今天遇到一个神奇的现象,我对CentOS 8系统做初始化之后再重启系统,发现系统不能通过NetworkManager获取DHCP IP了 查了系统日志发现是: Apr 30 0 ...
- 【原创】ShellCode免杀的骚姿势
ShellCode免杀的骚姿势 常见的免杀手法: shellcode(攻击代码)和加载程序的分离: Lolbins白利用加载shellcode(白名单利用): shellcode混淆.编码解码: sh ...
- IOC创建对象的方式
1,采用无参构造创建(默认) 2,假设我们要使用有参构造创建对象 (1)下标赋值 <!--第一种 下标赋值 --><bean id="user" class=&q ...
- vscode修改括号对颜色,自定义括号颜色
新版的vscode 1.67(2022年4月更新的版本),自带括号颜色匹配,十分的方便. 至于怎么开启,已经有人写过,这里就不写了,更新到新版默认开启~ 括号颜色默认只有3种颜色,有时候感觉不够用. ...
- thusc2022游记
DAY -1: 刷往年相关的题 DAY 0: 刷会儿题了,搞电脑,下obs.不过,发现电脑出了很多问题. obs没有录频效果,因为卡,杀毒软件把vc++全都删了.因此无dll文件错误,搞了一晚上都没搞 ...
- B - A Simple Task
https://vjudge.net/contest/446582#problem/B 这道题是一道不错的线段树练代码能力的题. #include<bits/stdc++.h> using ...