Python (进阶 第二部)
目录
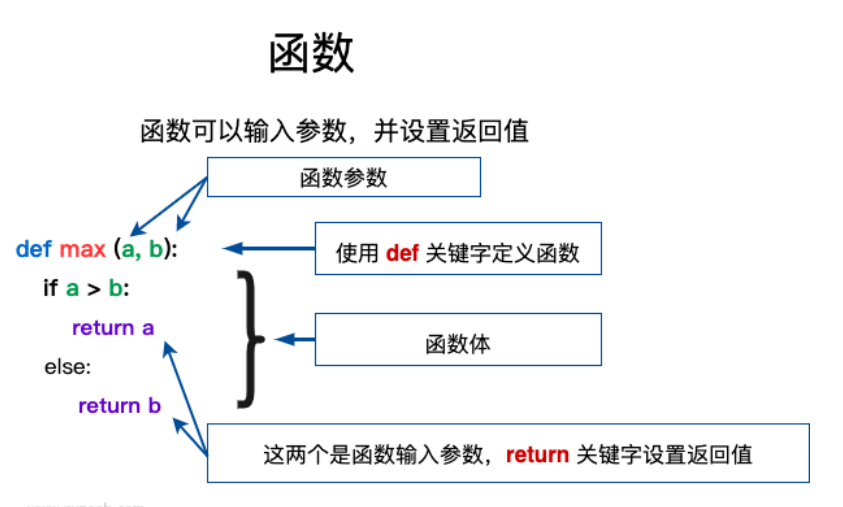
函数
函数的定义: 功能( 包括一部分代码,实现某种功能,达成某个目的)
函数的特点: 函数可以反复调用 ,提高代码的复用性,提高开发效率,便于维护和管理.
函数的基本格式:
# 定义一个函数 def 函数名():
code1
code2 # 函数的调用 函数名()
函数的命名规范:
字母数字下划线, 首字母不能为数字.
严格区分大小写, 且不能使用关键字.
函数命名有意义, 且不能使用中文.
函数的参数:( 参数:配合函数运算的值)
形参实参一一对应
形参: 形式参数,(在函数的定义处)
普通形参(位置) 默认形参 普通收集形参 命名关键字形参 关键字收集形参
实参: 实际参数,(在函数的调用处)
普通实参 关键字实参
普通形参
var = 你好
def func(var):
print(var) func(var)
默认形参
var = '你好' def func(var='大家好'):
print(var) func()
普通收集形参
list = ['徐峰','学峰','妮妮'] def func(*args):
print(list[:]) func(list)
命名关键字形参
命名关键字参数一般情况下跟在普通收集形参的后面, 在函数的调用时,必须使用命名关键子参数;来进行赋值
#方式一:
def func(a,b,*,d,c):
print(a,b) # 1 2
print(d) # 3
print(c) # 10 func(1,2,d = 3,c=10) 方式二:
def func(*args, c, **kwargs):
print(args) # (1, 2, 3, 4, 5, 6)
print(c) # 100
print(kwargs) # {'a': 1, 'b': 2, 'd': 6} func(1, 2, 3, 4, 5, 6, a=1, b=2, d=6, c=100)
关键字收集形参
def func(a,b,*,c,d):
print(a,b)
print(c,d)
dic = {"c":3,"d":4}
# **把字典里面的所有元素拿出来,拼装成键=值的参数形式,赋值给func进行调用
func(1,2,**dic,) # func( c=3, d=4 )
locals globals nonlocal (了解)
locals
locals 如果在全局,调用locals之后,获取的是打印之前的所有变量 返回字典,全局空间作用域.
def func():
ff = 123
a =1
b =2
res = locals()
c =3
print(res) #是一个大字典 截止到打印之前 c =4 # 打印之后的c 就获取不到
locals 如果在局部,调用locals之后, 获取的是调用之前的所有变量, 返回字典, 局部空间作用域.
a1 = 10 def func ():
a = 1
b = 2
res =locals()
c = 3
print(res) #截止到locals() 的调用之前( 就是locals之前的局部变量
d =4 # 获取不到
b2 =22 # 获取不到
func()
a3 =33 #获取不到
globals
globals如果在全局, 调用globals之后,获取的是打印之前的所有变量,返回字典,全局空间作用域
def func():
ff = 123
a =1
b =2
res= globals() # 获取打印之前的所有变量
c =3
print(res)
d =4 # c =4 将获取不到
globals 如果在局部, 调用globals之后,获取的是调用之前的所有变量,返回字典,全局空间作用域
a1 = 10
def func():
a =1
b =2
res=globals()
c =3
print(res)
d = 4
a2 =20
func() # 获取的是调用之前的所有变量 a3=30 # 获取不到
nonlocal
nonlocal遵循LEGB就近找变量的原则
- 找当前空间上一层的局部变量进行修改
- 找不到继续向再外一层找
- 最后一层也没有时,就会报错
1. 找当前空间上一层的局部变量进行修改
def outer():
a =100
def inner():
nonlocal a
a =200
print(a)
inner()
print(a)
outer() # outer层中的变量被inner中的nonlocal修改后,inner和outer在调用时都将得到的是修改之后的值
2. 如果找不到继续向上一层找
def outer():
a=10
def inner():
b=20
def func():
nonlocal a
a =1
print(a)
func()
print(a)
inner()
print(a)
outer() # func() 中的nonlocal 将 a 修改为1 在inner层中没有,就就找的outer中找到并修改 ,此时可以到的都是修改后的变量
3. 注意点: nonlocal只能修改局部变量
a =1
def outer():
b =2
def inner():
c = 3
def func():
nonlocal d
d =4
print(d)
func()
print(a)
inner()
print(a)
outer() # SyntaxError: no binding for nonlocal 'd' found
4. 不使用nonlocal 修改局部变量
def func():
lst = [1,2,3,4]
def inner():
lst[-1] = 10
inner()
print(lst)
func()
函数的嵌套
1. 函数之间可以互相嵌套
外层的函数叫做外函数,内层的叫做内函数
- (!)内部函数不可以在函数外部调用
- (2)调用外函数后, 内函数不可以在函数外部调用
- (3)内函数只能在函数内使用
- (4)内函数在函数内部调用时,必须先定义再使用
2. 外层是outer ,内层是inner ,最里层是smaller ,调用smaller 里面的所有代码
def outer():
def inner():
def smaller():
print('我是smaller函数')
smaller()
inner()
outer()
3. LEGB 原则(就近找变量原则)
B —— Builtin(Python);Python内置模块的命名空间 (内建作用域)
G —— Global(module); 函数外部所在的命名空间 (全局作用域)
E —— Enclosing function locals;外部嵌套函数的作用域(嵌套作用域)
L —— Local(function);当前函数内的作用域 (局部作用域)
依据就近原则,从下往上 从里向外 依次寻找
函数的返回值 return
自定义函数的返回值 return , 可以把值返回到函数的调用处
(1) return + 六大标准数据类型 , 类 , 对象,函数
如果不定义return ,默认返回的None
(2) 执行完return 之后, 立刻终止函数, 后面的代码将不会被执行
利用return 模拟简单
def func(sign,num1,num2):
if sign =='+':
res = num1 + num2
elif sign =='-':
res = num1 - num2
elif sign =='*':
res = num1 * num2
elif sign=='/':
if num2 ==0:
return '除数不能为0'
res = num1 / num2
else:
return '这个计算不出来'
return res
res = func("-",10,20)
print(res)
全局变量和局部变量
局部变量 : 在函数内部定义的变量(局部命名空间)
全局变量 : 在函数外部定义的或者使用global在函数内部定义(全局命名空间)
作用域: 作用的范围
局部变量作用域: 在函数的内部
全局变量作用域: 横跨整个文件
生命周期:
内置变量 > 全局变量 > 局部变量总结:
可以使用global 关键字在函数内部定义一个全局变量
也可以使用global关键字在函数内部修改一个全局变量
函数名的使用
函数名是个特殊的变量,可以当做变量赋值
a = “你好”
print(a)
a = func
a()函数可以像变量一样销毁
函数名可以作为容器类型数据的元素
函数名可以作为函数的参数
函数名可作为函数的返回值
闭包
如果内函数使用了外函数的局部变量,并且外函数把内函数返回的过程,叫做闭包.
被外函数返回出的函数就是闭包函数
基础语法
def songyunjie_family():
father = "王健林"
def f_hobby():
print("我们先顶一个小目标,比如赚它一个亿,这是我爸爸{}".format(father))
return f_hobby
func = songyunjie_family()
func()
obj = func.__closure__[0]
print(obj.cell_contents,"<111>")
复杂版
def mashengping_family():
father = "马云"
jiejie_name = "马蓉"
meimei_name = "马诺"
money = 1000
def jiejie():
nonlocal money
money -= 700
print("买包包,买名表,买首饰,把钱都败光了,家里的钱还剩下{}元".format(money))
def meimei():
nonlocal money
money -= 200
print("要找只找有钱人,宁愿在宝马里面哭,也不愿意在自行车上撒欢,家里的败光了还剩下{}元".format(money))
def big_master():
return (jiejie,meimei)
return big_master
func = mashengping_family()
print(func)
# 返回的是元组
tup = func() # big_master()
print(tup) # tup = (jiejie,meimei)
# 获取姐姐
jiejie = tup[0] # jiejie 函数
# 获取妹妹
meimei = tup[1] # meimei 函数
获取闭包函数使用的变量 closure
res= func.closure
print(res,'<222>')
cell_contents 用来获取单元格对象当中的闭包函数
jiejie = res[0].coll_contenrs
meimei = res[1].cell_contents
通过获取单元格对象 获取单元格对象中的内容 实际的调用
jiejie()
meimei()
print(jiejie.closure[0].coll_contents)
print(meimei.closure[1].coll_contents)
闭包的特征
内函数使用了外函数的局部变量 ,那么该函数与闭包函数就发生了绑定,延长了这个函数的生命周期
def outer(val):
def inner(num):
return val + num
return inner
func = outer(10) # func = inner
res = func(15) # res = func(15) = inner(15)
print(res)
闭包的意义
闭包可以优先使用外函数中的变量,并对闭包函数中的值起到了封装保护的作用,外部无法访问.
模拟鼠标点击次数
num = 0
def click_num():
global num
num += 1
print(num)
click_num()
click_num()
click_num()
num = 100
click_num()
click_num()
匿名函数
用一句话来表达只有返回值的函数
- 语法: lambda 参数: 返回zhi
- 追求代码简洁高效
- 无参的lambda表达式
def func():
return "123"
func = lambda : "123"
res = func()
print(res)
- 有参的lambda表达式
def func(n):
return type(n) func = lambda n : type(n)
print( func([1,2,3]) )
- 带有判断条件的lambda表达式
def func(n):
if n % 2 == 0:
return "偶数"
else:
return "奇数" func = lambda n : "偶数" if n % 2 == 0 else "奇数"
res = func(17)
print(res)
- 三元运算
n = 16
res = "偶数" if n % 2 == 0 else "奇数"
print(res) def func(x,y):
if x>y:
return x
else:
return y
func = lambda x,y : x if x>y else y
res = func(200,100)
print(res)
迭代器
能被next 调用,并不断返回下一个值的对象
迭代器的概念:迭代器指的就是迭代取值的工具,迭代是一个重复的过程,每一次迭代都是基于上一次的结果而继续的
迭代器的特征:不依赖索引,而是通过next 的指针迭代所有的数据,一次只能取一个值,大大节省了空间
dir 获取当前类型对象中的所有成员
“”“iter 方法用来判断是否是可迭代性数据”""
lst = dir(setvar)
print(dir(“123”))
res = “iter” in dir(setvar)
print(res)
迭代器
- for 循环能够遍历一切可迭代性数据的原因在于,底层调用了迭代器,
- 通过next方法中的指针实现数据的获取
- 可迭代对象 -> 迭代器 不能够被next直接调用 -> 可以被next直接调用的过程
- 如果是一个可迭代对象不一定是迭代器
- 但如果是一个迭代器就一定是一个可迭代对象
如何定义一个迭代器
setvar = {“a”,“b”,“c”,“d”}
it = iter(setvar)
print(it)
如何判断一个迭代器
print(dir(it))
res = “iter” in dir(it) and “next” in dir(it)
print(res)
如何来调用一个迭代器
“”“next在调用迭代器中的数据时,是单向不可逆,一条路走到黑的过程”""
res = next(it)
print(res)
res = next(it)
print(res)
res = next(it)
print(res)
res = next(it)
print(res)
“”"
#StopIteration 报错 停止迭代
res = next(it)
print(res)
“”"
重置迭代器
it = iter(setvar)
res = next(it)
print(res)
使用其他方法判断迭代器或者可迭代对象
“”“Iterator 迭代器 Iterable 可迭代对象”""
from … 从哪里 import 引入 …
from collections import Iterator,Iterable
from collections.abc import Iterator,Iterable python3.7
res = isinstance(it,Iterator)
print(res)
res = isinstance(it,Iterable)
print(res)
使用其他方法调用迭代器中的数据
for i in it:
print(i)
for+next
lst = [1,2,3,4,5,6,7,7,8,9,10]
it = iter(lst)
for i in range(10):
res = next(it)
print(res)
print(next(it))
print(next(it))
高阶函数
1. map 元素加工
map(func,lierable)
功能:处理数据
把iterable 中的数据一个一个取出来,放到func函数中进行加工处理后将结果放到迭代器当中,最后返回迭代器
参数: fuunc 自定义函数,或者内置函数
iterable: 可迭代性数据( 容器类,range,迭代器)
返回值: 迭代器
# 常规写法
lst_new = []
for i in lst:
lst_new.append(int(i))
print(lst_new)
# map改造
it = map(int,lst)
2. filter 数据过滤
filter(func, iterable)
功能: return Turn 当前这个数据保留
return False 当前这个数据舍弃
func: 自定义函数
iterable: 可迭代性数据( 容器型, range, 迭代器)
返回值: 迭代器
# 常规写法
lst_new = []
for i in lst:
if i % 2 == 0:
lst_new.append(i)
print(lst_new)
# filter改写
def func(i):
if i % 2 == 0:
return True
else:
return False
it = filter(func,lst)
# (1) next
res = next(it)
print(res)
3. reduce
reduce(func, iterable)
功能: 计算数据
先把iterable中的前俩个值取出,放到func中计算,把结算的结果和iterable中的第三个元素在放到func中计算,依次类推,直到所有结果都运算完毕,返回结果
func: 自定义函数
iterable: 可迭代数据(容器,range, 迭代器)
返回值: 计算之后的结果
# 常规写法
lst = [5,4,8,8] # => 整型5488
# 方法一
strvar = ""
for i in lst:
strvar += str(i)
print(strvar , type(strvar))
res = int(strvar)
print(res , type(res))
4. sorted
sorted( iterable , key=func,reverse = False)
功能 : 排序
iterable : 可迭代数据( 容器,range,迭代器)
key:指定自定义函数,内置函数
reverse: 代表升序或者降序默认是升序( 从小到大排序) reverse=False
返回值: 排序后的结果
# 1.默认是从小到大排序
lst = [1,2,3,4,5,-90,-4,-1,100]
res = sorted(lst)
print(res)
# 2.reverse 从大到小排序
res = sorted(lst,reverse=True)
print(res)
# 3.指定函数进行排序
# 按照绝对值排序 abs
lst = [-10,-1,3,5]
res = sorted(lst,key=abs)
"""
-1 => abs(-1) => 1
3 => abs(3) => 3
5 => abs(5) => 5
-10 => abs(-10) => 10
[-1, 3, 5, -10]
"""
print(res)
# 4.使用自定义函数进行排序
lst = [19,21,38,43,55]
def func(n):
return n % 10
lst = sorted(lst,key=func)
print(lst)
"""
21 => n % 10 => 1
43 => n % 10 => 3
55 => n % 10 => 5
38 => n % 10 => 8
19 => n % 10 => 9
21 43 55 38 19
"""
# ### sorted 和 sort 之间的区别
#字符串
container = "eadc"
#列表
container = [19,21,38,43,55]
#元组
container = (19,21,38,43,55)
#集合
container = {19,21,38,43,55}
#字典 (排序的是字典的键)
container = {"c":3,"a":1,"b":2}
container = {"王闻":3,"高云峰":2}
print("<===>")
res = sorted(container)
print(res)
#(1) sorted可以排序一切容器类型数据, sort只能排列表
#(2) sorted返回的是新列表,sort是基于原有的列表进行修改
#(3) 推荐使用sorted
推导式
语法:
val for val in iterable
三种推导式方式
[val for val initerable]
{val for val in iterable}
{ k:v for k,v in iterable }
1. 基础语法:
推导式的语法:
val for val in Iterable
三种方式:
[val for val in Iterable]
{val for val in Iterable}
{k:v for k,v in Iterable}
# 改写成推导式
lst = [i*3 for i in lst]
print(lst)
2. 带有判断条件的单循环推导式
# (2) 带有判断条件的单循环推导式 (只能是单项分支,接在for后面)
lst = [1,2,3,4,5,6,7,8]
lst_new = []
for i in lst:
if i % 2 == 1:
lst_new.append(i)
print(lst_new)
# 改写成推导式
lst = [i for i in lst if i % 2 == 1]
print(lst)
3. 双循环推导式
# (3) 双循环推导式
lst1 = ["李博伦","高云峰","孙致和","葛龙"]
lst2 = ["李亚","刘彩霞","刘子豪","刘昕"]
# "谁""谁"
lst_new = []
for i in lst1:
for j in lst2:
strvar = i + "" + j
lst_new.append(strvar)
print(lst_new)
# 改写成推导式
lst = [i + "" + j for i in lst1 for j in lst2]
print(lst)
4. 带有判断条件的双循环推导式
# (4) 带有判断条件的多循环推导式
lst_new = []
for i in lst1:
for j in lst2:
if lst1.index(i) == lst2.index(j):
strvar = i + "" + j
lst_new.append(strvar)
print(lst_new)
# 改写成推导式
lst = [ i + "" + j for i in lst1 for j in lst2 if lst1.index(i) == lst2.index(j) ]
print(lst)
集合推导式
常规写法
# 常规写法
setvar = set()
for i in listvar:
if 18 <= i["age"] <= 21 and 5000 <= i["money"] <= 5500:
res = "尊贵VIP卡老" + i["name"][0]
else:
res = "抠脚大汉卡老" + i["name"][0]
setvar.add(res)
print(setvar)
# 改写成集合推导式
# {三元运算符 + 推导式}
setvar = { "尊贵VIP卡老" + i["name"][0] if 18 <= i["age"] <= 21 and 5000 <= i["money"] <= 5500 else "抠脚大汉卡老" + i["name"][0] for i in listvar }
print(setvar)
字典推导式
enumerate
enumerate(iterable,[start=0])
功能:枚举 ; 将索引号和iterable中的值,一个一个拿出来配对组成元组放入迭代器中
参数:
iterable: 可迭代性数据 (常用:迭代器,容器类型数据,可迭代对象range)
start: 可以选择开始的索引号(默认从0开始索引)
返回值:迭代器
"""
from collections import Iterator
lst = ["东邪","西毒","南帝","北丐"]
# 基本使用
it = enumerate(lst)
print(isinstance(it,Iterator))
# for + next
for i in range(4):
print(next(it))
# list
"""start可以指定开始值,默认是0"""
it = enumerate(lst,start=1)
print(list(it))
# enumerate 形成字典推导式 变成字典
dic = { k:v for k,v in enumerate(lst,start=1) }
print(dic)
# dict 强制变成字典
dic = dict(enumerate(lst,start=1))
print(dic)
zip
"""
zip(iterable, ... ...)
功能: 将多个iterable中的值,一个一个拿出来配对组成元组放入迭代器中
iterable: 可迭代性数据 (常用:迭代器,容器类型数据,可迭代对象range)
返回: 迭代器
特征: 如果找不到对应配对的元素,当前元素会被舍弃
"""
# 基本使用
lst1 = ["晏国彰","刘子涛","郭凯","宋云杰"]
lst2 = ["刘有右柳翔","冯雍","孙志新"]
lst3 = ["周鹏飞","袁伟倬"]
# it = zip(lst1,lst2)
it = zip(lst1,lst2,lst3)
print(isinstance(it,Iterator))
print(list(it))
"""
[('晏国彰', '刘有右柳翔'), ('刘子涛', '冯雍'), ('郭凯', '孙志新')]
[('晏国彰', '刘有右柳翔', '周鹏飞'), ('刘子涛', '冯雍', '袁伟倬')]
"""
# zip 形成字典推导式 变成字典
lst1 = ["晏国彰","刘子涛","郭凯","宋云杰"]
lst2 = ["刘有右柳翔","冯雍","孙志新"]
dic = { k:v for k,v in zip(lst1,lst2) }
print(dic)
# dict 强制变成字典
dic = dict(zip(lst1,lst2))
print(dic)
生成器表达式
生成器本质就是迭代器, 允许自定义逻辑的迭代器
迭代器与生成器的区别:
迭代器本身是系统内置的,重写不了,而生成器是用户自定义的,可以重写迭代逻辑
生成器的俩种创建方式
1. 生成器表达式( 里面是推导式,外面用圆括号)
2. 生成器函数( 用def定义 ,里面含有yield)
from collections import Iterator,Iterable
# 生成器表达式
gen = (i*2 for i in range(1,11))
print(isinstance(gen,Iterator))
# next
res = next(gen)
print(res)
# for
for i in gen:
print(i)
# for + next
gen = (i*2 for i in range(1,11))
for i in range(3):
res = next(gen)
print(res)
# list
print("<=====>")
res = list(gen)
print(res)
生成器函数
yield 类似于 return
共同点: 执行到该点时,都会把值返回出去.
不同点: yield 每次返回时 ,会记住上次离开时执行的位置,下次在调用生成器,会从上次执行的位置继续向下执行,而return,会直接终止函数,不可以重头调用.
yield 6 和yield(6) 俩种写法都可以 yield 6 更像 return 6 的写法 ( 推荐使用)
生成器函数的基本用法
定义一个生成器函数
def mygen():
print(111)
yield 1
print(222)
yield 2
print(333)
yield 3
#初始化生成器函数,返回生成器对象,简称生成器
gen = mygen()
print(isinstance(gen,Iterator))
#使用next调用
res = next(gen)
print(res)
res = next(gen)
print(res)
res = next(gen)
print(res)
#res = next(gen) error
#print(res)
"""
代码解析:
初始化生成器函数 -> 生成器(通过next调用)
第一次调用生成器
res = next(gen) => print(111) yield 1 保存当前代码状态14行,并将1这个值返回 print(1) ,等待下一次调用
第二次调用生成器
res = next(gen) => 从上一次保存的状态14行继续向下执行
print(222) yield 2 保存当前代码状态17行,并将2这个值返回 print(2) ,等待下一次调用
第三次调用生成器
res = next(gen) => 从上一次保存的状态17行继续向下执行
print(333) yield 3 保存当前代码状态20行,并将3这个值返回 print(3) ,等待下一次调用
第四次调用生成器
因为没有更多yield返回数据了,所以直接报错.
"""
优化代码
def mygen():
for i in range(1,101):
yield “该球衣号码是{}”.format(i)
#初始化生成器函数 -> 生成器
gen = mygen()
#for + next 调用数据
for i in range(50):
res = next(gen)
print(res)
print("<====>")
for i in range(30):
res = next(gen)
print(res)
send 的用法
# 3.send 用法
"""
### send
# next和send区别:
next 只能取值
send 不但能取值,还能发送值
# send注意点:
第一个 send 不能给 yield 传值 默认只能写None
最后一个yield 接受不到send的发送值
send 是给上一个yield发送值
"""
def mygen():
print("process start")
res = yield 100
print(res,"内部打印1")
res = yield 200
print(res,"内部打印2")
res = yield 300
print(res,"内部打印3")
print("process end")
# 初始化生成器函数 -> 生成器
gen = mygen()
# 在使用send时,第一次调用必须传递的参数是None(硬性语法),因为第一次还没有遇到上一个yield
'''第一次调用'''
res = gen.send(None) #<=> next(gen)
print(res)
'''第二次调用'''
res = gen.send(101) #<=> next(gen)
print(res)
'''第三次调用'''
res = gen.send(201) #<=> next(gen)
print(res)
'''第四次调用, 因为没有更多的yield返回数据了,所以StopIteration'''
"""
res = gen.send(301) #<=> next(gen)
print(res)
"""
"""
# 代码解析:
初始化生成器函数,返回生成器对象
第一次调用时,
print("process start")
res = yield 100 记录当前代码状态81行,返回100,等待下一次调用
res = 100 print(100)
第二次调用时,
把101 发送给上一个yield保存的状态81行 res = 101 从81行继续往下走
print(101,"内部打印1")
res = yield 200 记录当前代码状态84行,返回200,等待下一次调用
res = 200 print(200)
第三次调用时,
把201 发送给上一个yield保存的状态84行 res = 201 从84行继续往下走
print(201,"内部打印2")
res = yield 300 记录当前代码状态87行,返回300,等待下一次调用
res = 300 print(300)
"""
yield from : 将一个迭代器对象变成一个迭代器返回
# 4.yield from : 将一个可迭代对象变成一个迭代器返回
def mygen():
yield from ["马生平","刘彩霞","余锐","晏国彰"]
gen = mygen()
print(next(gen))
print(next(gen))
print(next(gen))
print(next(gen))
# 5.用生成器描述斐波那契数列
"""1 1 2 3 5 8 13 21 34 ... """
"""
yield 1
a,b = b,a+b = 1,1
yield 1
a,b = b,a+b = 1,2
yield 2
a,b = b,a+b = 2,3
yield 3
a,b = b,a+b = 3,5
yield 5
....
"""
def mygen(maxlen):
a,b = 0,1
i = 0
while i < maxlen:
yield b
a,b = b,a+b
i+=1
# 初始化生成器函数 -> 生成器
gen = mygen(10)
for i in range(3):
print(next(gen))
递归函数
递归函数: 自己调用自己的函数就是递归函数( 递: 就是去 归: 就是回 一去一回就是递归)
def digui(n):
print(n,"<====1===>")
if n > 0:
digui(n-1)
print(n,"<====2===>")
digui(5)
"""
# 代码解析:
去的过程:
n = 5 print(5,"<====1===>") 5>0 条件成立-> digui(5-1) => digui(4) 代码阻塞在第13行
n = 4 print(4,"<====1===>") 4>0 条件成立-> digui(4-1) => digui(3) 代码阻塞在第13行
n = 3 print(3,"<====1===>") 3>0 条件成立-> digui(3-1) => digui(2) 代码阻塞在第13行
n = 2 print(2,"<====1===>") 2>0 条件成立-> digui(2-1) => digui(1) 代码阻塞在第13行
n = 1 print(1,"<====1===>") 1>0 条件成立-> digui(1-1) => digui(0) 代码阻塞在第13行
n = 0 print(0,"<====1===>") 0>0 条件不成立 print(0,"<====2===>")
当前这层空间代码已经执行结束
此刻触发回的过程
n = 1 从上一次13行的代码阻塞位置,继续向下执行 print(1,"<====2===>")
n = 2 从上一次13行的代码阻塞位置,继续向下执行 print(2,"<====2===>")
n = 3 从上一次13行的代码阻塞位置,继续向下执行 print(3,"<====2===>")
n = 4 从上一次13行的代码阻塞位置,继续向下执行 print(4,"<====2===>")
n = 5 从上一次13行的代码阻塞位置,继续向下执行 print(5,"<====2===>")
到此,递归函数彻底执行结束.
5 4 3 2 1 0 0
"""
每一次调用函数时 ,在内存中都会单独开辟一片空间,配合函数运行,这个空间叫做栈帧空间
1).递归是一去一回的过程,
调用函数时,会开辟栈帧空间,函数执行结束之后,会释放栈帧空间
递归实际上就是不停的开辟和释放栈帧空间的过程
每次开辟栈帧空间,都是独立的一份,其中的资源不共享
(2).触发回的过程
1.当最后一层栈帧空间全部执行结束的时候,会触底反弹,回到上一层空间的调用处
2.遇到return,会触底反弹,回到上一层空间的调用处,
(3).写递归时,必须给与递归跳出的条件,否则会发生内存溢出,蓝屏死机的情况.
如果递归层数过多,不推荐使用递归 """
# 官方说法:默认1000层,实际996层左右
"""
def func():
func()
func()
"""
递归阶乘
# (1) 用递归计算n的阶乘
# 常规方法
# 5! = 5*4*3*2*1
def func(n):
total = 1
for i in range(n,0,-1):
total *= i
return total
res = func(5)
print(res)
# 递归写法
def jiecheng(n):
if n <= 1:
return 1
return n*jiecheng(n-1)
res = jiecheng(5)
print(res)
"""
return 后面的表达式,一定是先计算完在返回
# 代码解析:
# 去的过程:
n = 5 return 5*jiecheng(5-1) => 5 * jiecheng(4)
n = 4 return 4*jiecheng(4-1) => 4 * jiecheng(3)
n = 3 return 3*jiecheng(3-1) => 3 * jiecheng(2)
n = 2 return 2*jiecheng(2-1) => 2 * jiecheng(1)
n = 1 return 1
# 回的过程:
n = 2 return 2*jiecheng(2-1) => 2 * jiecheng(1) => 2 * 1
n = 3 return 3*jiecheng(3-1) => 3 * jiecheng(2) => 3 * 2 * 1
n = 4 return 4*jiecheng(4-1) => 4 * jiecheng(3) => 4 * 3 * 2 * 1
n = 5 return 5*jiecheng(5-1) => 5 * jiecheng(4) => 5 * 4 * 3 * 2 * 1
return 5 * 4 * 3 * 2 * 1 => return 120
额外解析:
jiecheng(1) => 1
jiecheng(2) => 2*jiecheng(1) => 2*1
jiecheng(3) => 3*jiecheng(2) => 3*2*1
jiecheng(4) => 4*jiecheng(3) => 4*3*2*1
jiecheng(5) => 5*jiecheng(4) => 5* 4*3*2*1
"""
print(jiecheng(1))
尾递归
"""
自己调用自己,并且非表达式
计算的结果要在参数当中完成.
尾递归无论调用多少次函数,都只占用一份空间,但是目前cpython不支持.
"""
def jiecheng(n,endval):
if n <= 1:
return endval
return jiecheng(n-1,endval*n)
res = jiecheng(5,1)
print(res)
"""
# 代码解析:
去的过程
n=5 , endval=1 return jiecheng(5-1,endval*5) => jiecheng(4,1*5)
n=4 , endval=1*5 return jiecheng(4-1,endval*4) => jiecheng(3,1*5*4)
n=3 , endval=1*5*4 return jiecheng(3-1,endval*3) => jiecheng(2,1*5*4*3)
n=2 , endval=1*5*4*3 return jiecheng(2-1,endval*2) => jiecheng(1,1*5*4*3*2)
n=1 , endval=1*5*4*3*2 return 120
回的过程:
n=2 return 120
n=3 return 120
n=4 return 120
n=5 return 120
因为最后一层空间的返回值就是第一层空间的返回值,所有在使用尾递归的时候
不需要考虑回的逻辑过程,就能解决问题.推荐使用.
"""
# 优化1
def jiecheng(n,endval=1):
if n <= 1:
return endval
return jiecheng(n-1,endval*n)
res = jiecheng(5)
print(res,"<111>")
# 优化2
"""为了避免用户乱传参数,把endval这个参数隐藏起来"""
def outer(n):
def jiecheng(n,endval=1):
if n <= 1:
return endval
return jiecheng(n-1,endval*n)
return jiecheng(n) # jiecheng(n-1,endval*n)
res = outer(5)
print(res)
递归斐波那契数列
# 递归计算斐波那契数列
""" 1,1,2,3,5,8,13 ....
n = 3 => 2
n = 5 => 5
n = 6 => 8
"""
# 上一个 n-1 上上个 n-2
def feb(n):
# 递归跳出的条件
if n <= 2: # n == 1 or n == 2 => 1
return 1
return feb(n-1) + feb(n-2)
res = feb(5)
print(res)
"""
代码解析:
n = 5 return feb(5-1) + feb(5-2) => feb(4) + feb(3)
feb(4)->3 + feb(3)->2 => 5
feb(3) + feb(2) feb(2) + feb(1)
feb(2)+feb(1) | 1 1 + 1
2 + 1
"""
Python (进阶 第二部)的更多相关文章
- Python ( 高级 第二部)
目录 模块和包 面向对象 部分一: 面向对象程序开发 面向对象封装: 对象的相关操作 面向对象封装: 类的相关操作 实例化的对象/ 定义的类删除公有成员属性和公有成员方法 部分二: 单继承 多继承 菱 ...
- 第二篇 python进阶
目录 第二篇 python进阶 一 数字类型内置方法 二 字符串类型内置方法 三 列表类型内置方法(list) 四 元组类型内置方法(tuple) 五 字典内置方法 六 集合类型内置方法(self) ...
- Python进阶:函数式编程实例(附代码)
Python进阶:函数式编程实例(附代码) 上篇文章"几个小例子告诉你, 一行Python代码能干哪些事 -- 知乎专栏"中用到了一些列表解析.生成器.map.filter.lam ...
- Python进阶 - 对象,名字以及绑定
Python进阶 - 对象,名字以及绑定 1.一切皆对象 Python哲学: Python中一切皆对象 1.1 数据模型-对象,值以及类型 对象是Python对数据的抽象.Python程序中所有的数据 ...
- Python进阶-继承中的MRO与super
Python进阶-继承中的MRO与super 写在前面 如非特别说明,下文均基于Python3 摘要 本文讲述Python继承关系中如何通过super()调用"父类"方法,supe ...
- Python进阶 - 命名空间与作用域
Python进阶 - 命名空间与作用域 写在前面 如非特别说明,下文均基于Python3 命名空间与作用于跟名字的绑定相关性很大,可以结合另一篇介绍Python名字.对象及其绑定的文章. 1. 命名空 ...
- 【python进阶】深入理解系统进程2
前言 在上一篇[python进阶]深入理解系统进程1中,我们讲述了多任务的一些概念,多进程的创建,fork等一些问题,这一节我们继续接着讲述系统进程的一些方法及注意点 multiprocessing ...
- Python进阶:如何将字符串常量转化为变量?
前几天,我们Python猫交流学习群 里的 M 同学提了个问题.这个问题挺有意思,经初次讨论,我们认为它无解. 然而,我认为它很有价值,应该继续思考怎么解决,所以就在私密的知识星球上记录了下来. 万万 ...
- Python进阶之面向对象编程
面向对象编程——Object Oriented Programming,简称OOP,是一种程序设计思想.OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数. 面向过程的程序设计把计算机 ...
- Python进阶量化交易专栏场外篇7- 装饰器计算代码时间
欢迎大家订阅<教你用 Python 进阶量化交易>专栏!为了能够提供给大家更轻松的学习过程,笔者在专栏内容之外已陆续推出一些手记来辅助同学们学习本专栏内容,目前已推出如下扩展篇: 在第一篇 ...
随机推荐
- Qt多线程开发总览,既然用到了就记录一下
多线程 在LBD_VM_Intercom中使用的一个简单的实例 陶工给的dll需要进行异步操作才可以将视频画面附到窗体上,必须得在画面出现之后才可以附加画面,否则就有可能出现意外bug,所以需要在这个 ...
- TCP协议三握四挥、socket模块
目录 传输层之TCP与UDP协议 应用层 socket模块 socket代码简介 代码优化 半连接池的概念 传输层之TCP与UDP协议 用于应用程序之间的通信 TCP与UDP都是用来规定通信方式的 ...
- Jmeter之随机变量元件与用户自定义变量元件区别及使用
用随机变量(random variable)与用户自定义变量(User defined variables)的区别: 随机变量:在同个线程或者不同线程时,每个次循环执行时值都会重新生成 用户自定义变量 ...
- RSA_zd网校登录
网站 aHR0cHM6Ly91c2VyLndhbmd4aWFvLmNuL2xvZ2lu 点到密码登录,会返回验证码 输入错误的账号密码点登录抓包,可以看到密码是被加密的 initator点进去 简 ...
- C#代码扫描工具Sonarqube + Win10+SqlServer2017
在之前的公司, 看到有用过代码扫描工具, 扫描C#代码, 最近公司也有考虑做这个,于是我便独自研究了一下,这里给大家做个分享 网上找了很多资料, 主要有以下问题: 1. Sonarqube用的是 旧版 ...
- 【译】2022 年回顾:Web 性能有哪些新变化?
原文地址:https://www.debugbear.com/blog/2022-in-web-performance 若对文中提到的一些性能参数不太熟悉,可以参考我之前的一篇博文<性能参数和优 ...
- 使用IDEA创建一个maven的web项目并部署到tomcat上
目录 1.创建一个maven项目 2.为项目添加配置文件 3.创建一些类和jsp页面 4.将项目部署到tomcat 1.创建一个maven项目 打开IDEA,File--New--Project 选择 ...
- Kali Win-KeX SL
内容: 概述 先决条件 用法 开始 声音支持 多屏支持 停止 概述 无缝模式下的 Win-KeX 将在 Windows 桌面的屏幕顶部启动 Kali Linux 面板. 通过面板启动的应用程序将与 M ...
- 【CTF隐写工具】binwalk工具使用方法
工具简介 Binwalk 是一种快速.易于使用的工具,用于分析.逆向工程和提取固件映像. 工具环境 Linux Linux环境下安装 直接使用apt/yum进行安装 apt install binwa ...
- [OpenCV实战]48 基于OpenCV实现图像质量评价
本文主要介绍基于OpenCV contrib中的quality模块实现图像质量评价.图像质量评估Image Quality Analysis简称IQA,主要通过数学度量方法来评价图像质量的好坏. 本文 ...