【原创】Python 二手车之家车辆档案数据爬虫
| 本文仅供学习交流使用,如侵立删! |
二手车之家车辆档案数据爬虫
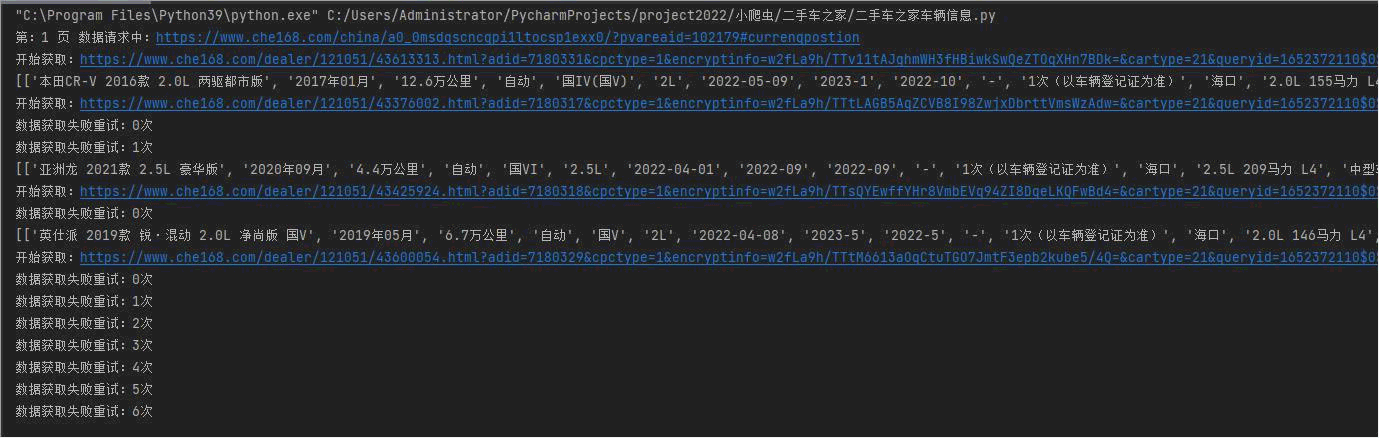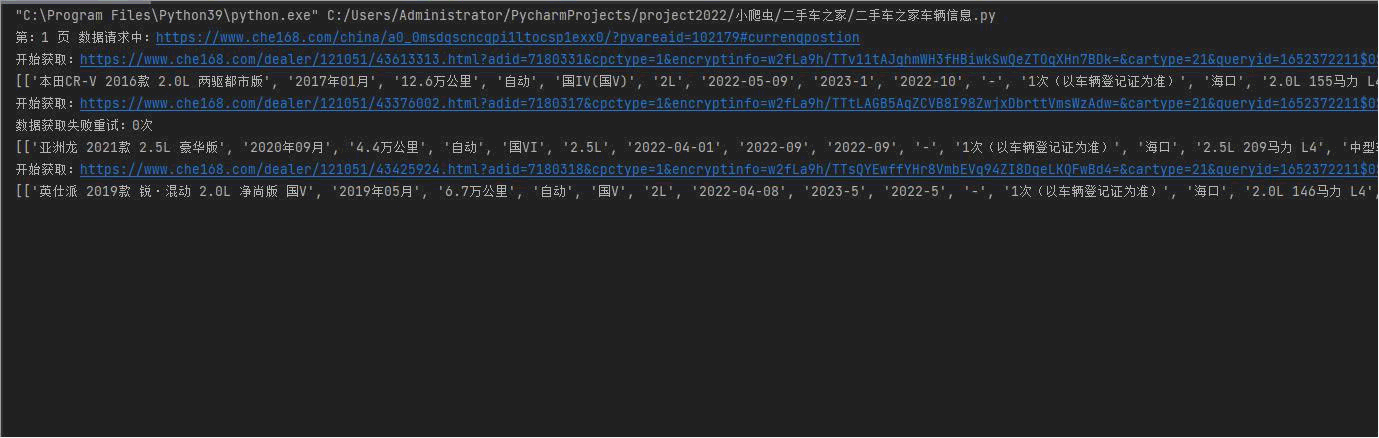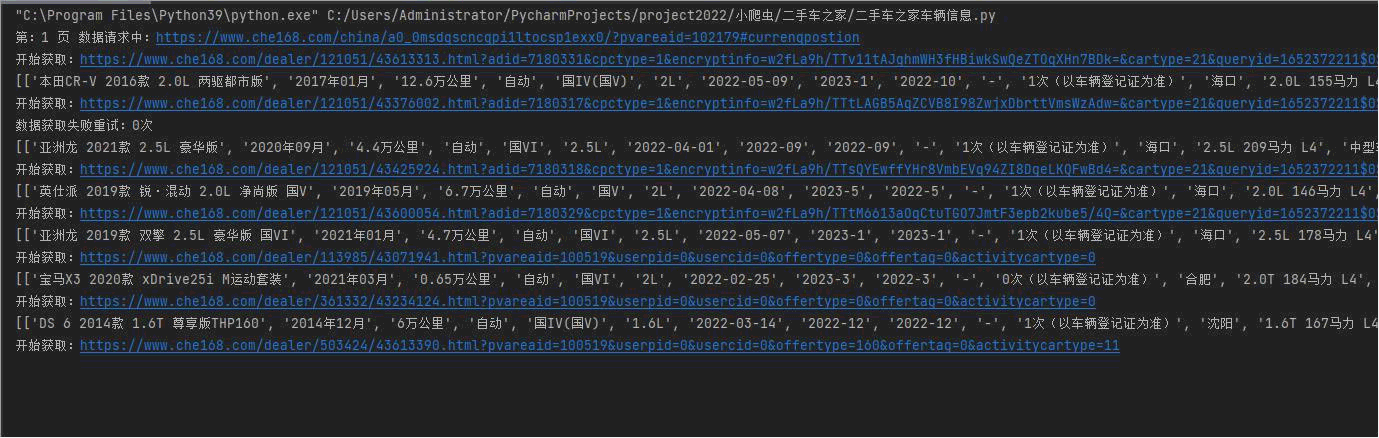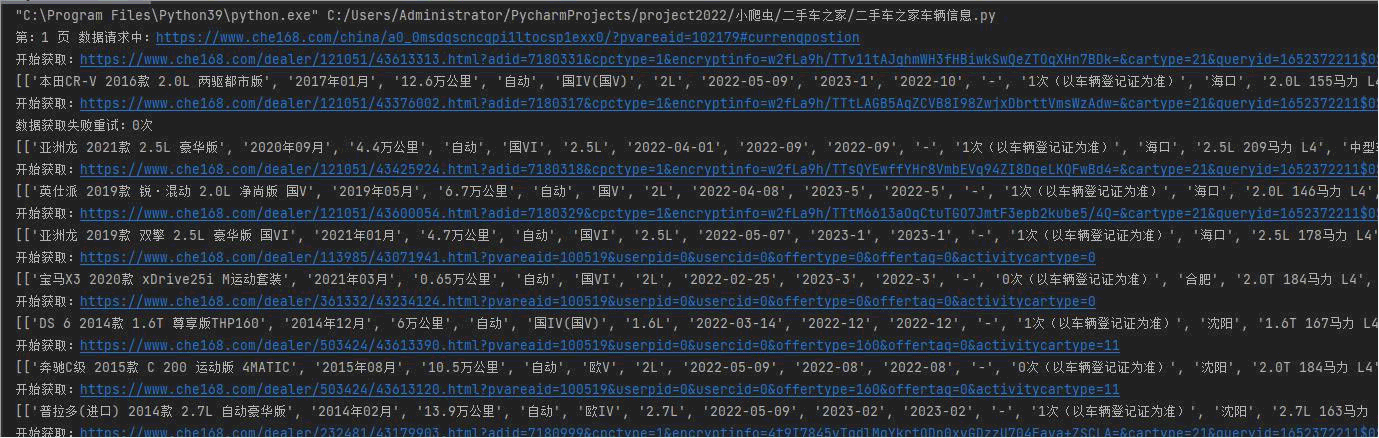
先上效果图

环境
- win10
- python3.9
- lxml、retrying、requests
需求分析
需求:
主要是需要车辆详情页中车辆档案的数据
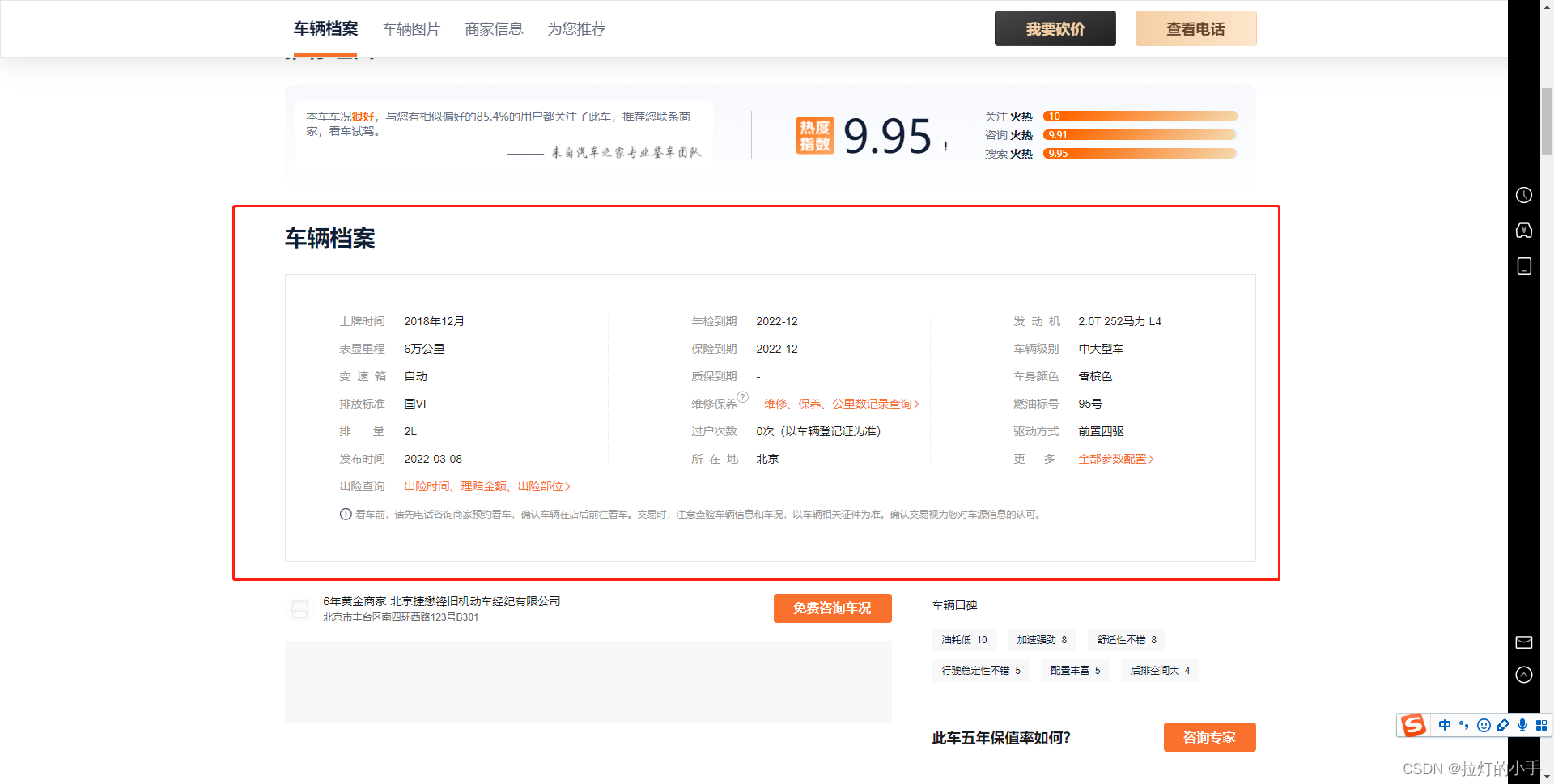
先抓包分析一波,网页抓包没有什么有用的,转战APP
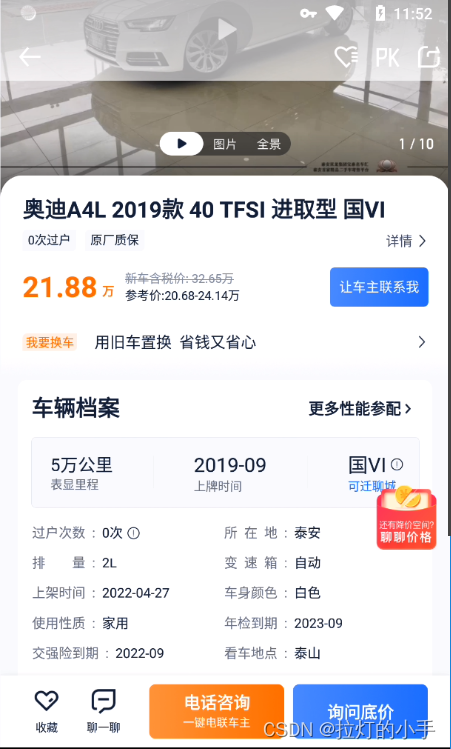
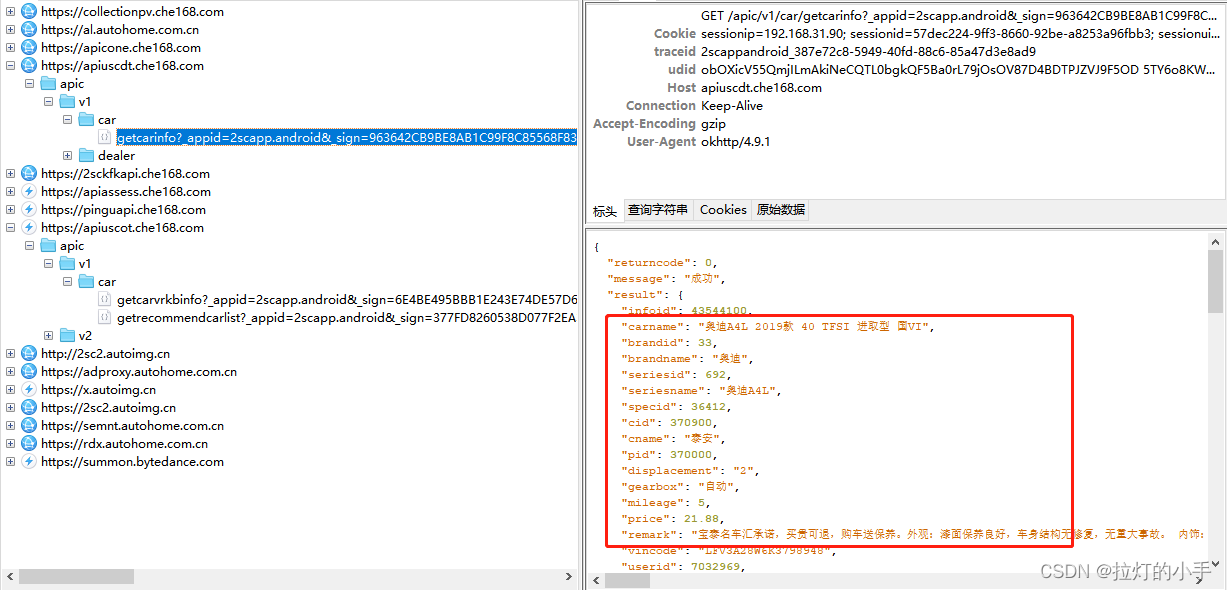
拿到数据接口就简单了,直接构造请求保存数据即可
获取车辆信息列表
def _get_car_list(self, _url: str):
"""
获取二手车信息列表
"""
res = self._parse_url(_url=_url)
ret = res.text # 解析获得字符串类型数据
result = etree.HTML(ret) # 转换数据类型为HTML,方便使用xpath
url_list = result.xpath('//*[@id="goodStartSolrQuotePriceCore0"]/ul/li/a/@href')
if not url_list:
print('获取完成!')
return
for i in url_list:
# 有些车型url直接是带域名的
if 'www.che168.com/' in i:
yield 'https://' + i[2:]
else:
yield 'https://www.che168.com' + i
获取车辆详情信息
def _get_car_info(self, _url: str):
"""
获取车辆详情信息
"""
res = self._parse_url(_url=_url)
ret = res.text # 解析获得字符串类型数据
result = etree.HTML(ret) # 转换数据类型为HTML,方便使用xpath
# 标题
title = result.xpath('//div[@class="car-box"]/h3//text()')
title = title[1].strip() if len(title) > 1 else title[0].strip()
# 上牌时间
play_time = result.xpath('//*[@id="nav1"]/div[1]/ul[1]/li[1]/text()')
play_time = play_time[0].strip() if play_time else '-'
# 表显里程
display_mileage = result.xpath('//*[@id="nav1"]/div[1]/ul[1]/li[2]/text()')
display_mileage = display_mileage[0].strip() if display_mileage else '-'
# 变速箱
gearbox = result.xpath('//*[@id="nav1"]/div[1]/ul[1]/li[3]/text()')
gearbox = gearbox[0].strip() if gearbox else '-'
# 排放标准
emission_standards = result.xpath('//*[@id="nav1"]/div[1]/ul[1]/li[4]/text()')
emission_standards = emission_standards[0].strip() if emission_standards else '-'
# 排量
displacement = result.xpath('//*[@id="nav1"]/div[1]/ul[1]/li[5]/text()')
displacement = displacement[0].strip() if displacement else '-'
# 发布时间
release_time = result.xpath('//*[@id="nav1"]/div[1]/ul[1]/li[6]/text()')
release_time = release_time[0].strip() if release_time else '-'
# 年检到期
annual_inspection_expires = result.xpath('//*[@id="nav1"]/div[1]/ul[2]/li[1]/text()')
annual_inspection_expires = annual_inspection_expires[0].strip() if annual_inspection_expires else '-'
# 保险到期
insurance_expires = result.xpath('//*[@id="nav1"]/div[1]/ul[2]/li[2]/text()')
insurance_expires = insurance_expires[0].strip() if insurance_expires else '-'
# 质保到期
warranty_expires = result.xpath('//*[@id="nav1"]/div[1]/ul[2]/li[3]/text()')
warranty_expires = warranty_expires[0].strip() if warranty_expires else '-'
# 过户次数
number_of_transfers = result.xpath('//*[@id="nav1"]/div[1]/ul[2]/li[5]/text()')
number_of_transfers = number_of_transfers[0].strip() if number_of_transfers else '-'
# 所在地
location = result.xpath('//*[@id="nav1"]/div[1]/ul[2]/li[6]/text()')
location = location[0].strip() if location else '-'
# 发动机
engine = result.xpath('//*[@id="nav1"]/div[1]/ul[3]/li[1]/text()')
engine = engine[0].strip() if engine else '-'
# 车辆级别
vehicle = result.xpath('//*[@id="nav1"]/div[1]/ul[3]/li[2]/text()')
vehicle = vehicle[0].strip() if vehicle else '-'
# 车身颜色
car_color = result.xpath('//*[@id="nav1"]/div[1]/ul[3]/li[3]/text()')
car_color = car_color[0].strip() if car_color else '-'
# 燃油标号
fuel_label = result.xpath('//*[@id="nav1"]/div[1]/ul[3]/li[4]/text()')
fuel_label = fuel_label[0].strip() if fuel_label else '-'
# 驱动方式
drive_mode = result.xpath('//*[@id="nav1"]/div[1]/ul[3]/li[5]/text()')
drive_mode = drive_mode[0].strip() if drive_mode else '-'
data = [[title, play_time, display_mileage, gearbox, emission_standards, displacement, release_time, annual_inspection_expires,
insurance_expires, warranty_expires, number_of_transfers, location, engine, vehicle, car_color, fuel_label, drive_mode, _url]]
print(data)
self._save_csv(data=data)
资源下载
https://download.csdn.net/download/qq_38154948/85358088
| 本文仅供学习交流使用,如侵立删! |
【原创】Python 二手车之家车辆档案数据爬虫的更多相关文章
- selenuim自动化爬取汽车在线谷米爱车网车辆GPS数据爬虫
#为了实时获取车辆信息,以及为了后面进行行使轨迹绘图,写了一个基于selelnium的爬虫爬取了车辆gps数据. #在这里发现selenium可以很好的实现网页解析和处理js处理 #导包 import ...
- Python爬取6271家死亡公司数据,一眼看尽十年创业公司消亡史!
小五利用python将其中的死亡公司数据爬取下来,借此来观察最近十年创业公司消亡史. 获取数据 F12,Network查看异步请求XHR,翻页. 成功找到返回json格式数据的url, 很多人 ...
- Python爬取6271家死亡公司数据,看十年创业公司消亡史
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 朱小五 凹凸玩数据 PS:如有需要Python学习资料的小伙伴可以加 ...
- TOP100summit:【分享实录】链家网大数据平台体系构建历程
本篇文章内容来自2016年TOP100summit 链家网大数据部资深研发架构师李小龙的案例分享. 编辑:Cynthia 李小龙:链家网大数据部资深研发架构师,负责大数据工具平台化相关的工作.专注于数 ...
- python3 爬取汽车之家所有车型数据操作步骤(更新版)
题记: 互联网上关于使用python3去爬取汽车之家的汽车数据(主要是汽车基本参数,配置参数,颜色参数,内饰参数)的教程已经非常多了,但大体的方案分两种: 1.解析出汽车之家某个车型的网页,然后正则表 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 使用 Python 抓取欧洲足球联赛数据
Web Scraping在大数据时代,一切都要用数据来说话,大数据处理的过程一般需要经过以下的几个步骤 数据的采集和获取 数据的清洗,抽取,变形和装载 数据的分析,探索和预测 ...
- 如何用python抓取js生成的数据 - SegmentFault
如何用python抓取js生成的数据 - SegmentFault 如何用python抓取js生成的数据 1赞 踩 收藏 想写一个爬虫,但是需要抓去的的数据是js生成的,在源代码里看不到,要怎么才能抓 ...
- [原创].NET 分布式架构开发实战之三 数据访问深入一点的思考
原文:[原创].NET 分布式架构开发实战之三 数据访问深入一点的思考 .NET 分布式架构开发实战之三 数据访问深入一点的思考 前言:首先,感谢园子里的朋友对文章的支持,感谢大家,希望本系列的文章能 ...
随机推荐
- Python写安全小工具-TCP全连接端口扫描器
通过端口扫描我们可以知道目标主机都开放了哪些服务,下面通过TCP connect来实现一个TCP全连接端口扫描器. 一个简单的端口扫描器 #!/usr/bin/python3 # -*- coding ...
- linux篇-linux 下建立多个tomcat
第一步:复制,解压 将准备好的tomcat压缩包复制到你准备安装的目录,我的tomcat压缩包名字是tomcat.tar.gz,我的安 装目录是 /usr/java/tomcat 第二步:解压tomc ...
- 好客租房40-react组件基础综合案例-案例需求分析
实现 案例的数据 渲染评论列表 有评论 没有评论 暂无评论 获取评论信息 包括评论人和受控组件 发表评论 更新评论 //导入react import React from 'react' import ...
- axios的请求参数格式(get、post、put、delete)
1.get请求方式: axios.get(url[, config]) // [字符拼接型]axios.get(url?id=123&status=0') // 等同于 axios.get(u ...
- Django对接支付宝Alipay支付接口
最新博客更新见我的个人主页: https://xzajyjs.cn 我们在使用Django构建网站时常需要对接第三方支付平台的支付接口,这里就以支付宝为例(其他平台大同小异),使用支付宝开放平台的沙箱 ...
- HMS Core新闻行业解决方案:让技术加上人文的温度
开发者们,你希望用户如何获取新闻? 有的人靠手机弹窗知天下事,有的人则在新闻应用中尽览每一篇文章:有的人一目十行,有的人则喜欢细细咀嚼:有的人主动探索,有的人则想要应用投其所好. 科技在不断刷新着用户 ...
- 机械硬盘和ssd固态硬盘的原理对比分析
固态硬盘和机械硬盘的区别 机械硬盘 磁头是不是直接和盘片接触的呢 磁盘中有几个盘片 机械硬盘的工作原理 固态硬盘的寻址方式 SMR叠瓦式真的比PMR优秀吗 固态硬盘 主控芯片 闪存颗粒 缓存单元 固态 ...
- c# 把网络图片http://....png 打包成zip文件
思路: 1.把网络图片下载到服务器本地. 2.读取服务器图片的文件流 3.使用zip帮助类,把图片文件流写进zip文件流. 4.如果是文件服务器,把zip文件流 推送文件服务器,生成zip的下载url ...
- sqlserver 把c#代码的string[] 的ids转换成一个数据table表
declare @string varchar(200),@sql varchar(1000)set @string = '1,2,3,4,5,6'set @sql = 'select code='' ...
- golang的超时处理使用技巧
原文链接:https://www.zhoubotong.site/post/57.html golang的超时处理 2天前Go实例技巧25 大家知道Select 是 Go 中的一个控制结构,每个 ...