数据爬取后台(PHP+Python)联合作战
一. 项目声明
本项目从前端,到后台,以及分布式数据抓取,乃我一个人所写,因此项目并不太完善!在语义分析以及数据处理上并不能尽如意。但是极大的减轻了编辑的工作量!
二. 项目所用技术
本项目中前端采用bootstrap栅格系统布局,后台服务端语言采用PHP,数据抓取所用Python完成 (scrapy/requests/BeautifulSoup/threading/selenium/jieba)
三. 项目说明
1.拿到对应的关键词 -〉从百度知道 找出 对应的问题;
2.得到对应的问题 -〉搜全网,排名前10篇的文章(过滤掉百度知道的文章正文,通过特征库过滤一些官网与专题页面等)
3.得到的对应正文 -〉将得到的文章,进行去头,去尾。随机拼接!
4.数据处理-〉用遗忘算法,对处理数据进行筛选,过滤品牌词! (目前暂未完善,避免误删除,导致文本不通顺,目前只是标红,训练该特征模型)
5.本项目基于多线程!可扩展成多进程(因为不考虑效率,加之本机电脑配置较低,所以采用的是单进程下的多线程!)
四. 项目仍需完善之处
1.文本语义不通顺,不能完全机器识别运用(任然需要人工审核),特征库不完善。
2.过滤品牌词,仍然存在有一些特殊的品牌词过滤不掉的问题
3.没有实现无监督学习,对自然语言分析(NLP)任然不熟悉!导致这些问题,无法解决!
五.该项目需要准备
1.IP代理池来源于(免费IP提供商)
2.下载github开源的分词库(jieba)
3.采用selenium抓取,充分模拟浏览器行为,因此要有一个无头浏览器作为工具
六.项目截图:

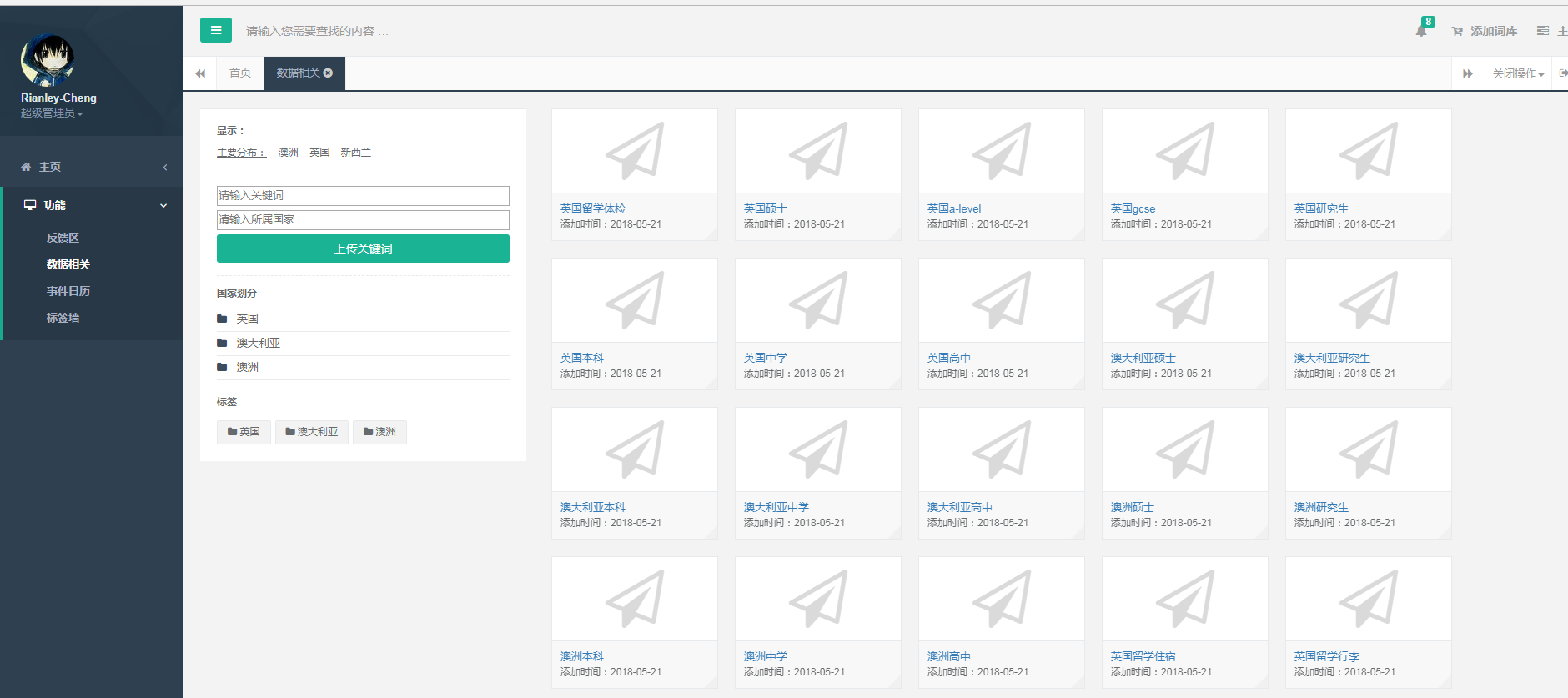
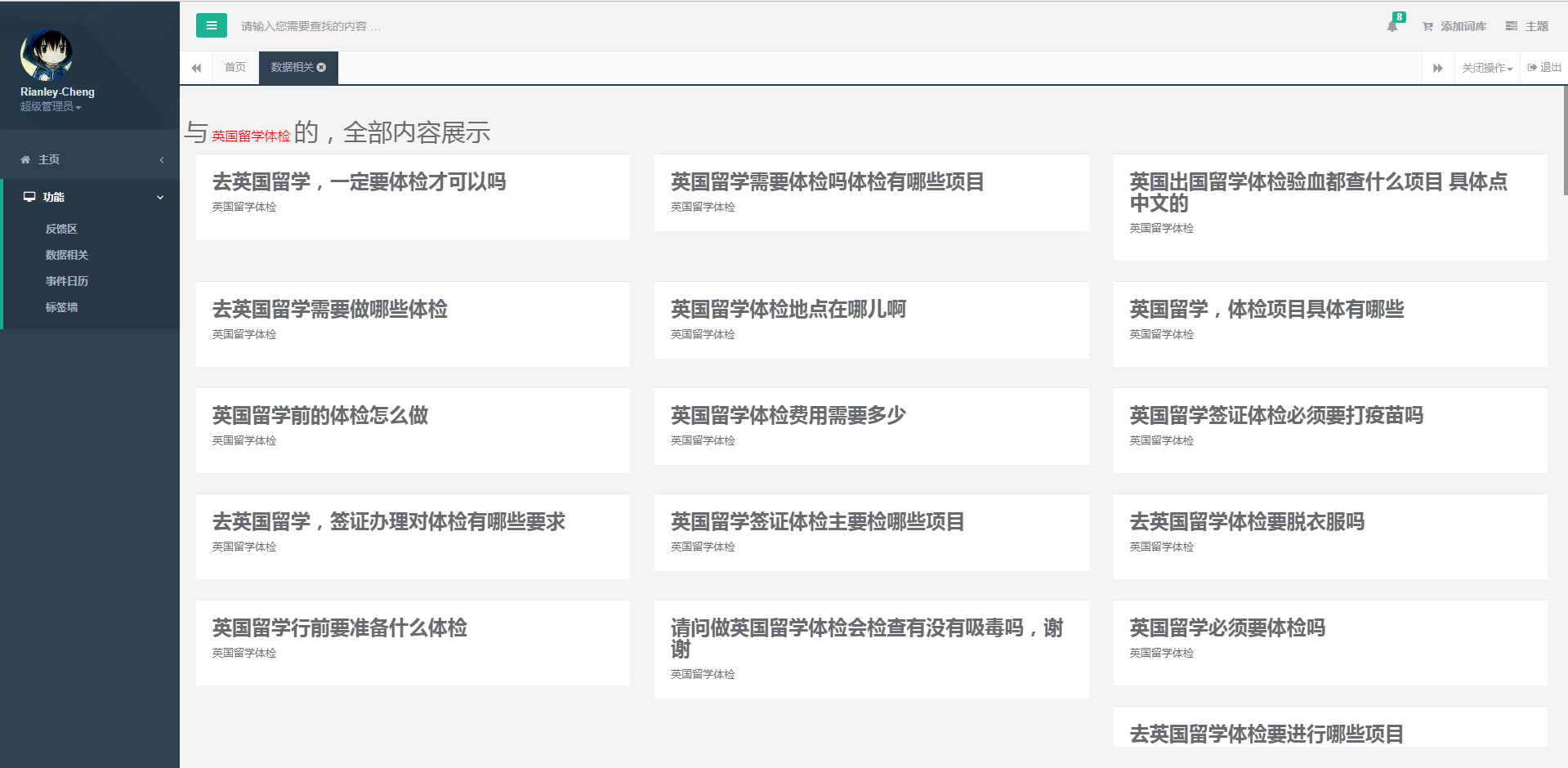
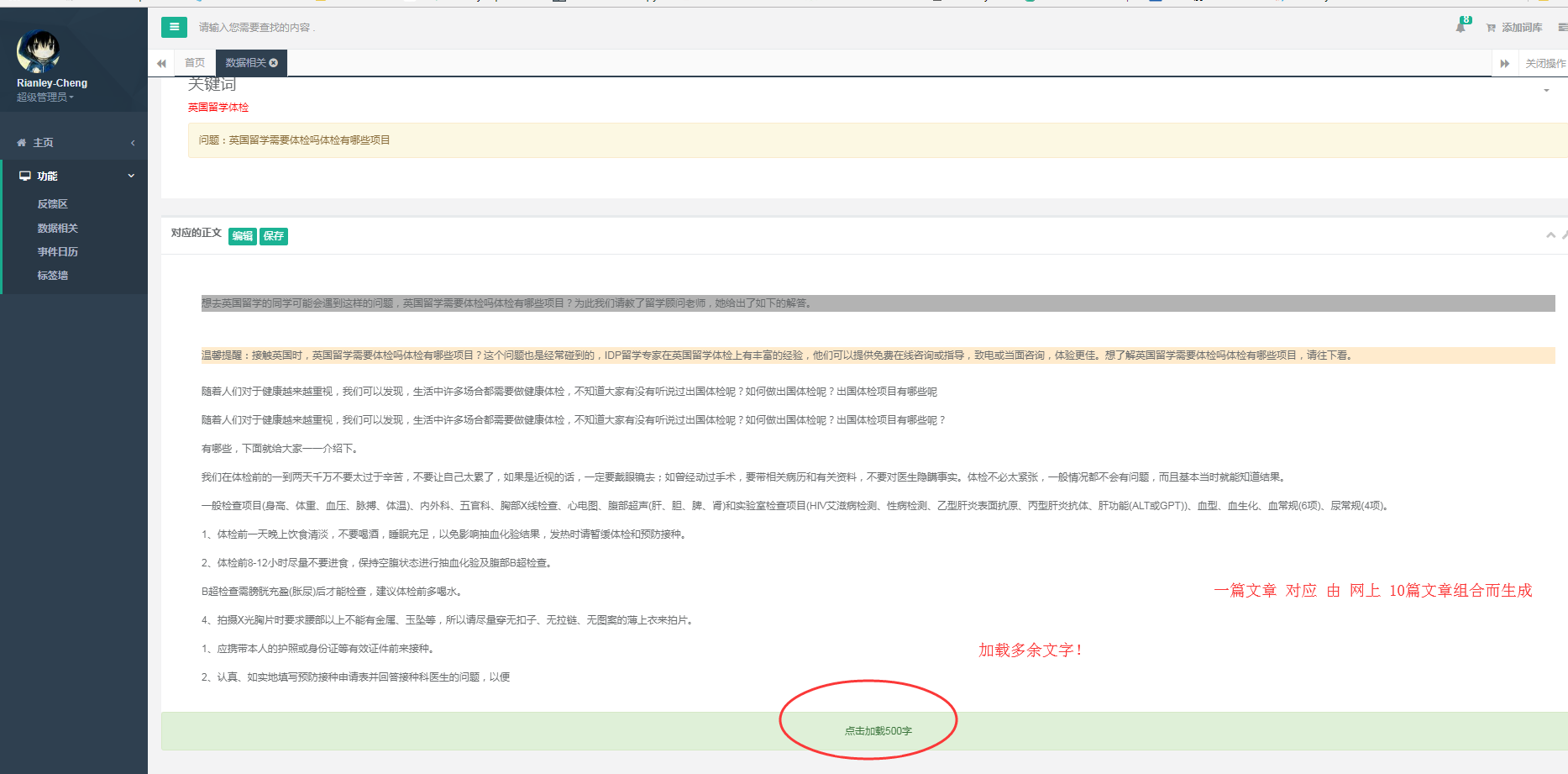
七.结言:
本项目仍处于开发阶段,希望各位自然语言处理的大佬,能给予一些数据清洗方面的帮助!感激不尽!
公司项目,暂不提供源码... 仅探讨思路!
联系Email:rianleycheng@gmail.com
联系QQ:2855132411
数据爬取后台(PHP+Python)联合作战的更多相关文章
- 人人贷网的数据爬取(利用python包selenium)
记得之前应同学之情,帮忙爬取人人贷网的借贷人信息,综合网上各种相关资料,改善一下别人代码,并能实现数据代码爬取,具体请看我之前的博客:http://www.cnblogs.com/Yiutto/p/5 ...
- python实现人人网用户数据爬取及简单分析
这是之前做的一个小项目.这几天刚好整理了一些相关资料,顺便就在这里做一个梳理啦~ 简单来说这个项目实现了,登录人人网并爬取用户数据.并对用户数据进行分析挖掘,终于效果例如以下:1.存储人人网用户数据( ...
- 芝麻HTTP:JavaScript加密逻辑分析与Python模拟执行实现数据爬取
本节来说明一下 JavaScript 加密逻辑分析并利用 Python 模拟执行 JavaScript 实现数据爬取的过程.在这里以中国空气质量在线监测分析平台为例来进行分析,主要分析其加密逻辑及破解 ...
- Python爬虫 股票数据爬取
前一篇提到了与股票数据相关的可能几种数据情况,本篇接着上篇,介绍一下多个网页的数据爬取.目标抓取平安银行(000001)从1989年~2017年的全部财务数据. 数据源分析 地址分析 http://m ...
- 用Python介绍了企业资产情况的数据爬取、分析与展示。
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:张耀杰 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自 ...
- Python爬虫入门教程 15-100 石家庄政民互动数据爬取
石家庄政民互动数据爬取-写在前面 今天,咱抓取一个网站,这个网站呢,涉及的内容就是 网友留言和回复,特别简单,但是网站是gov的.网址为 http://www.sjz.gov.cn/col/14900 ...
- requests模块session处理cookie 与基于线程池的数据爬取
引入 有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达不到我们想要的目的,例如: #!/usr/bin/ ...
- quotes 整站数据爬取存mongo
安装完成scrapy后爬取部分信息已经不能满足躁动的心了,那么试试http://quotes.toscrape.com/整站数据爬取 第一部分 项目创建 1.进入到存储项目的文件夹,执行指令 scra ...
- python3编写网络爬虫13-Ajax数据爬取
一.Ajax数据爬取 1. 简介:Ajax 全称Asynchronous JavaScript and XML 异步的Javascript和XML. 它不是一门编程语言,而是利用JavaScript在 ...
随机推荐
- stl sort使用不当造成崩溃
#include <iostream>#include <vector>#include <algorithm>using namespace std; bool ...
- 远程登录-出现身份验证错误[可能是由于CredSSP加密Oracle修正]
问题描述 远程桌面登录时,出现身份验证错误,要求的函数不正确,这可能是由于CredSSP加密Oracle修正. 原因,系统更新导致 CVE-2018-0886 的 CredSSP 更新 解决方法1 运 ...
- Oracle 数据库视图与基表的关系
本文转载自:http://www.linuxidc.com/Linux/2015-03/115165.htm 一:首先解释什么是视图: 视图其实就是一条查询sql语句,用于显示一个或多个表或其他视图中 ...
- Java 学习笔记1
最近开始学习Java. <%@ page language="java" import="java.util.*" pageEncoding=" ...
- node express 跨域问题
express = require('express'); var app = express(); //设置跨域访问 app.all('*', function(req, res, next) { ...
- phpcms利用表单向导创建留言板(可以回复)
这篇博客写的很详细,可跳转到如下链接: http://blog.aiwebcom.com/%E7%BD%91%E7%AB%99%E5%BB%BA%E8%AE%BE/phpcms/456.html 注: ...
- [转]解決 IE10 瀏覽器無法使用 ASP.NET 表單驗證登入的問題
今天凌晨在客戶端上線,當程式佈署到正式機後發現我們的網站唯獨只有 IE10 瀏覽器無法成功登入,任何其他瀏覽器版本或使用較低的 IE 版本都可以正常登入,使用 IE 相容性檢視也都可以正常登入,想說會 ...
- java 中的懒汉单例和饿汉单例模式
//-------------------------------------------------------------饿汉模式--开始----------------------------- ...
- 『ACM C++』 PTA 天梯赛练习集L1 | 042-43
记录刷题情况 ------------------------------------------------L1-042--------------------------------------- ...
- LAMP+Varnish的实现
基于Keepalived+Varnish+Nginx实现的高可用LAMP架构 注意:各节点的时间需要同步(ntpdate ntp1.aliyun.com),关闭firewalld(systemctl ...