巨蟒python全栈开发-第8天 文件操作
一.文件操作
今日大纲:
1.文件操作->open()
open 打开
f=open(文件路径,mode='模式',encoding='编码格式')
#python最最底层操作的就是bytes
打开一个文件的时候获取到的是一个文件句柄(#相当于插了一根管子) 绝对路径
从磁盘根目录开始寻找
相对路径
相对于当前程序所在的文件夹
../上一层文件
文件夹/进入xxx文件夹
2.mode:
高频: r r+ rb
w wb
a
了解: w+ a+ ab
r+b w+b a=b
(1)r:读取,只读,读取文件的相关操作
1.read()
默认:读取全部文件内容
read(n) 读取n个字符
2.readline() 读取一行内容
3.readlines() 读取全部内容,返回列表
4.for line in f:每次读取一行内容:(最重要的)
(注意在这里打印出来的有一个空行,需要strip()去掉空行) (2)w:写入:写文件的相关操作
1.写入,只写
2.创建文件
3.会清空文件
(3)a:追加
1.也可以创建文件
2.追加写
(4)r+:
1.对于文件而言,应该有的操作就两个:读,写
2.读写操作
(5)w+:写读操作
(6)a+:追加写读
(7)所有带b的表示直接操作的是bytes,当处理非文本文件的时候
例如:rb/wb
ab:断点续传//别人写好来了专门的库,可以直接用
r+b w+b a+b
3.文件操作中关于文件句柄的相关操作
(1)seek() 移动光标
seek详解:
f.seek(0) 移动到开头(最多)
f.seek(0,2) 移动到结尾,seek的第二个参数表示的是从哪个位置进行偏移
默认是0,表示开头,1表示当前位置,2表示结尾
seek:两个参数
1.表示偏移量
2.从xxx开始偏移,默认0,开头位置 1 当前位置 2 末尾位置 f.seek(10,1) #从当前位置走10步
f.seek(10,2) #从末尾位置走10步 (2)tell:返回光标所在的位置
(3)seek/tell/truncate,这三个方法的参数,都是字节的
4.实际操作,文件修改(重点)
#python是最终是以字节形式操作文件的
DAY8-文件操作
本节主要内容:
(1)r模式初识
(2)文件路径的问题
(3)r模式
(4)w模式
(5)a模式
(6)+模式
(7)文件复制bytes rb/wb模式
(8)seek和tell
(9)文件修改
(10)水果统计 内容详解:
(1)r模式初识 r:read 只读
文件里的内容:alex周杰伦昆凌周润发
f=open('小护士模特主妇萝莉',mode='r',encoding='utf-8')
#读取内容
content=f.read()#全部都读取出来(最后光标就在末尾了)
print(content)
#坑:
c2=f.read() #注意:第二次读取,读取不到内容,因为上面已经读取完毕,光标在末尾
print('c2',c2) #结果显示的是第一个c2,第二个c2已经没有东西可读了
#良好的习惯
f.close() #关闭连接
#结果:alex周杰伦昆凌周润发
# c2
主要:f.close()的位置
(2)文件路径的问题
文件路径:
1.相对路径:相对于当前程序所在的文件夹,如果在文件夹内,随便找,直接写名字
如果不在这个文件夹内容,可能需要 出文件夹或者进文件夹
出文件夹 ../
进文件夹 文件夹/
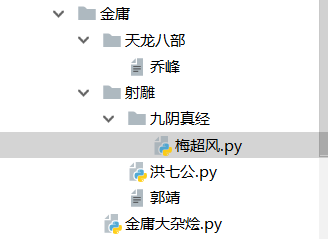
对上图进行解释:金庸是根目录,它的子目录包括:天龙八部,射雕,金庸大杂烩.py
天龙八部下面的文件是:乔峰
射雕下面的文件是:九阴真经,洪七公,郭靖
九阴真经下面的文件是:梅超风.py
对于同一根文件"金庸"下的,''金庸大杂烩.py'',我们,直接找并列的,兄弟文件就行
f = open("天龙八部/乔峰", mode="r", encoding="utf-8")
content = f.read()
print(content)
f = open("射雕/郭靖", mode="r", encoding="utf-8")
content = f.read()
print(content)
对于同一根文件'金庸'下的 '梅超风.py',找乔峰文件,按照上边的思维是应该按照上边的写法!!!!!!!
f = open("九阴真经/射雕/天龙八部/乔峰", mode="r", encoding="utf-8")
print(f.read())
f.close()
但是上边的写法是错误的,我们应该把往上层走的文件用../表示,所以应该是下面写法,并列走,不能替换,往下走也不能替换
f = open("../../天龙八部/乔峰", mode="r", encoding="utf-8")
print(f.read())
f.close()
同理,'洪七公.py'找'乔峰',应该往上走一层,再找兄弟,再往下走
f = open("../天龙八部/乔峰")
2.绝对路径:从磁盘根目录寻找路径(有问题)
只有在记录日志的时候可以用到绝对路径
日志:程序运行过程中记录的信息 (尤其是游戏公司)
绝对路径案例:
f=open('F:\spython\西游记\金角大王.txt',mode='r',encoding='gbk')
print(f.read())
f.close()
在windows10中,txt文件直接写的中文是gbk,所以写的是gbk,直接用gbk解码
(3)r模式
1.文件内容:alex周杰伦昆凌周润发
f=open('小护士模特主妇萝莉',mode='r',encoding='utf-8')
print(f.read()) #alex周杰伦昆凌周润发
f.close()
2.
f=open('小护士模特主妇萝莉',mode='r',encoding='utf-8')
print(f.read(5)) #读取5个字符 #结果:alex周
print(f.read(5)) #继续读取5个字符 #结果:杰伦昆凌周
f.close() 3.
f=open('小护士模特主妇萝莉',mode='r',encoding='utf-8')
print('xxxxx\n',end='') #结果:xxxxx #\n代表换行
print(f.readline()) #读一行: alex周杰伦昆凌周润发 结果:xxxxx
alex
4.文件内的\n打印出来的还是\n 5.最好用的方式,没有之一
#文件句柄是一个可迭代对象 f=open('小护士模特主妇萝莉',mode='r',encoding='utf-8')
for line in f: #从文件
print(line.strip())
# print(line) 6. print(f.readline().strip()) # 换行符为分割, strip()可以去掉换行. 读取到的内容第一件事就是去掉空白
print(f.readline()) # 换行符为分割 7.
print("周润发", end="胡辣汤")
print("周润发")
结果:周润发胡辣汤周润发
8.print(f.readlines()) # 一次性把文件中的内容读取到列表中.
9.
print("你叫什么名字?\n 我叫李嘉诚. 可能") # 换行
print("你叫什么名字?\\n 我叫李嘉诚. 可能") # 显示 \n
print("你叫什么名字?\\\\n 我叫李嘉诚. 可能") # 显示 \\n
结果:
你叫什么名字?
我叫李嘉诚. 可能
你叫什么名字?\n 我叫李嘉诚. 可能
你叫什么名字?\\n 我叫李嘉诚. 可能
(4)w模式
每次用w模式打开文件,都会清空这个文件(坑)
尤其是日志,不能用w模式写
f=open('胡辣汤',mode='w',encoding='utf-8') #可以帮我们创建文件
f.write('河南特色\n') #写一行就换行
f.write('东北特色\n')
f.write('陕西特色\n')
#好习惯
f.flush() #刷新管道,把数据写入文件
f.close()
(5)a模式
f=open('胡辣汤',mode='a',encoding='utf-8') #a,append 追加,在文件的末尾写入内容
f.read() #报错 not readable
f.write('你叫什么名字啊?')
f.close()
(6)+模式
r+
f=open('葫芦小金刚',mode='r+',encoding='utf-8')
content=f.read() #顺序必须先读,后写
#r+特有的深坑:不论读取内容的多少,只要你读了,写就是在末尾
f.write('五娃')
print(content)
w+
#w+一上来会清空文件. 没人用
f = open("葫芦小金刚", mode="w+", encoding="utf-8")
f.write("又能吐火的, 有能吐水的.")
# 移动光标
f.seek(0) # 移动到开头
s = f.read()
print("=========>", s)
a+
#a+追加写读,光标在末尾,所有的写都是在末尾
f=open('葫芦小金刚',mode='a+',encoding='utf-8')
f.write('丢丢丢,机器葫芦娃召唤神龙,高喊,我代表月亮消灭你!')
f.seek(0)
s=f.read()
print('===>',s)
(7)文件复制bytes
#注意这个路径的写法,我困在这个地方很久,如果不加/,在当前目录下创建一个新的一模一样的图片,必须在pycharm的文件路径下才能删除
f1=open('d:/huyifei.jpg',mode='rb')
f2=open('f:/huyifei.jpg',mode='wb')
for line in f1: #line是从f1中读取的内容 #里边会自己分行
f2.write(line) #把读取的内容原封不动的写出去
f1.close()
f2.flush()
f2.close()
(8)seek&tell
f = open("胡辣汤", mode="r+", encoding="utf-8")
# f.seek(0,2) # 移动到末尾
# content = f.read(5)
# print(content)
# f.seek(0) # 移动到开头
# print(f.read()) #读取全部内容
# print(f.tell()) # 字节
f.seek(3)
print(f.read())
tell和seek和truncate都是字节码个数
(9)文件修改:
文件内容:
alex是一个大好人
好人一生平安
好人是alex
你是一个好人
需求:把好人换成sb
必须做的事:
1.先从文件中读取内容
2.把要修改的内容进行修改
3.把修改好的内容写入一个新文件
4.删除掉原来的文件
5.把新文件重命名成原来的文件的名字
导入os模块//os模块表示操作系统 方法一:
#with会自动的帮我们关闭文件的链接
with open('夸一夸alex',mode='r',encoding='utf-8') as f,\
open('夸一夸alex_副本',mode='w',encoding='utf-8') as f1:
for line in f:
if 'sb' in line:
line=line.replace('sb','好人')
f1.write(line)
import os
import time time.sleep(3) #在删除程序之前,先让程序睡3s(程序暂停三秒)
os.remove('夸一夸alex') #删除原来文件
time.sleep(3) # 在pycharm中显示不明显,在原来的文件目录中可以明显观察到变化
os.rename('夸一夸alex_副本','夸一夸alex') #重命名副本为原来的文件
方法二:
f=open('夸一夸alex',mode='r',encoding='utf-8')
f2=open('夸一夸alex_副本',mode='w',encoding='utf-8')
for line in f:
if '好人' in line:
line=line.replace('好人','sb')
f2.write(line)
f.close()
f2.flush()
f2.close()
import os
import time
time.sleep(3) #在删除程序之前,先让程序睡3s(程序暂停三秒)
os.remove('夸一夸alex') #删除原来文件
time.sleep(3) # 在pycharm中显示不明显,在原来的文件目录中可以明显观察到变化
os.rename('夸一夸alex_副本','夸一夸alex') #重命名副本为原来的文件
(10)水果统计
文档:
1,香蕉,1.85,50
2,苹果,2.6,100
3,榴莲,25,800
4,木瓜,3.5,1000
处理一:
f=open('水果.txt',mode='r',encoding='utf-8')
for line in f: #1,香蕉,1.85,50
dic={} #每行都是一个字典
line=line.strip() #去掉空白 \n 1,香蕉,1.85,50
a,b,c,d=line.split(",") #[1,香蕉,1.85,50]
dic['id']=a
dic['name']=b
dic['price']=c
dic['totle']=d
print(dic)
# 结果:
# {'id': '1', 'name': '香蕉', 'price': '1.85', 'totle': '50'}
# {'id': '2', 'name': '苹果', 'price': '2.6', 'totle': '100'}
# {'id': '3', 'name': '榴莲', 'price': '25', 'totle': '800'}
# {'id': '4', 'name': '木瓜', 'price': '3.5', 'totle': '1000'}
处理二:
#把字典装到列表里
f=open('水果.txt',mode='r',encoding='utf-8')
lst=[]
for line in f: #1,香蕉,1.85,50
dic={} #每行都是一个字典
line=line.strip() #去掉空白 \n 1,香蕉,1.85,50
a,b,c,d=line.split(",") #[1,香蕉,1.85,50] #解构
dic['id']=a
dic['name']=b
dic['price']=c
dic['totle']=d
lst.append(dic)
print(lst)
#结果:
# [{'id': '1', 'name': '香蕉', 'price': '1.85', 'totle': '50'},
# {'id': '2', 'name': '苹果', 'price': '2.6', 'totle': '100'},
# {'id': '3', 'name': '榴莲', 'price': '25', 'totle': '800'},
# {'id': '4', 'name': '木瓜', 'price': '3.5', 'totle': '1000'}]
升级处理文档:
编号,名称,价格,重量
1,香蕉,1.85,50
2,苹果,2.6,100
3,榴莲,25,800
4,木瓜,3.5,1000
处理一:
f=open('水果.txt',mode='r',encoding='utf-8')
line=f.readline() #第一行内容,编号,名称,价格,数量
h,i,j,k=line.split(',')
lst=[]
for line in f: #1,香蕉,1.85,50
dic={} #每行都是一个字典
line=line.strip() #去掉空白 \n 1,香蕉,1.85,50
a,b,c,d=line.split(",") #[1,香蕉,1.85,50] #解构
dic[h]=a
dic[i]=b
dic[j]=c
dic[k]=d
lst.append(dic)
print(lst)
#结果:#结果多了一个\n
# [{'编号': '1', '名称': '香蕉', '价格': '1.85', '重量\n': '50'},
# {'编号': '2', '名称': '苹果', '价格': '2.6', '重量\n': '100'},
# {'编号': '3', '名称': '榴莲', '价格': '25', '重量\n': '800'},
# {'编号': '4', '名称': '木瓜', '价格': '3.5', '重量\n': '1000'}]
处理二:
#在第2行,添加 strip()
f=open('水果.txt',mode='r',encoding='utf-8')
line=f.readline().strip() #第一行内容,编号,名称,价格,数量
h,i,j,k=line.split(',')
lst=[]
for line in f: #1,香蕉,1.85,50
dic={} #每行都是一个字典
line=line.strip() #去掉空白 \n 1,香蕉,1.85,50
a,b,c,d=line.split(",") #[1,香蕉,1.85,50] #解构
dic[h]=a
dic[i]=b
dic[j]=c
dic[k]=d
lst.append(dic)
print(lst) # 结果
# [{'编号': '1', '名称': '香蕉', '价格': '1.85', '重量': '50'},
# {'编号': '2', '名称': '苹果', '价格': '2.6', '重量': '100'},
# {'编号': '3', '名称': '榴莲', '价格': '25', '重量': '800'},
# {'编号': '4', '名称': '木瓜', '价格': '3.5', '重量': '1000'}]
处理三:最终版本,提升了程序的可扩展性
#推导步骤#将解包转化为列表,将分解完的,合成一个
f=open('水果.txt',mode='r',encoding='utf-8')
line=f.readline().strip() #第一行的内容, 编号,名称,价格,重量,哈哈
title=line.split(',') #title是一个列表 [编号,名称,价格,重量,哈哈]
lst=[]
# print(title) #老师帮忙调试
for line in f: #1,香蕉,1.85,50
dic={} #每一行都是一个字典
line=line.strip() #去掉空白 \n 1,香蕉,1.85,50
date=line.split(',') #[1,香蕉,1.85,50]
# print(date) #老师帮忙调试
for i in range(len(title)):
#title[i] & date[i]
dic[title[i]]=date[i]
lst.append(dic)
print(lst) # [{'编号': '1', '名称': '香蕉', '价格': '1.85', '重量': '50'},
# {'编号': '2', '名称': '苹果', '价格': '2.6', '重量': '100'},
# {'编号': '3', '名称': '榴莲', '价格': '25', '重量': '800'},
# {'编号': '4', '名称': '木瓜', '价格': '3.5', '重量': '1000'}]
Day08今日作业:
1,有如下文件,a1.txt,里面的内容为: 老男孩是最好的培训机构,
全心全意为学生服务,
只为学生未来,不为牟利。
我说的都是真的。哈哈 分别完成以下的功能: a,将原文件全部读出来并打印。
with open('a1.txt',mode='r',encoding='utf-8') as f:
ff=f.read()
print(ff)
b,在原文件后面追加一行内容:信不信由你,反正我信了。
with open('a1.txt',mode='a',encoding='utf-8') as f:
ff=f.write('\n信不信由你,反正我信了。')
c,将原文件全部读出来,并在后面添加一行内容:信不信由你,反正我信了。
with open('a1.txt',mode='r+',encoding='utf-8')as f:
fk=f.read()
print(fk)
ff=f.write('\n信不信由你,反正我信了。')
d,将原文件全部清空,换成下面的内容: 每天坚持一点,
每天努力一点,
每天多思考一点,
慢慢你会发现,
你的进步越来越大。
with open('a1.txt',mode='w',encoding='utf-8')as f:
ff=f.write('每天坚持一点,'
'\n每天努力一点,'
'\n每天多思考一点,'
'\n慢慢你会发现,'
'\n你的进步越来越大。')
e,将原文件内容全部读取出来,并在‘我说的都是真的。哈哈’这一行的前面加一行,
‘你们就信吧~’然后将更改之后的新内容,写入到一个新文件:a1.txt。
重点题目!!!
import os
with open('a1.txt',mode='r+',encoding='utf-8')as f ,\
open('a.txt',mode='w',encoding='utf-8')as f2:
for line in f:
f2.write(line.replace('我说的都是真的。哈哈','你们就信吧~,\n我说的都是真的。哈哈'))
os.remove('a1.txt')
os.rename('a.txt','a1.txt')
2,有如下文件,t1.txt,里面的内容为: 葫芦娃,葫芦娃,
一根藤上七个瓜
风吹雨打,都不怕,
啦啦啦啦。
我可以算命,而且算的特别准:
上面的内容你肯定是心里默唱出来的,对不对?哈哈 分别完成下面的功能: a,以r+的模式打开原文件,判断原文件是否可读,是否可写。
重点:上课没有讲过的方法
with open('t1.txt',mode='r+',encoding='utf-8') as f:
print(f.writable())
print(f.readable())
b,以r的模式打开原文件,利用for循环遍历文件句柄。
with open('t1.txt',mode='r',encoding='utf-8') as f:
for i in f:
print(i.strip()) #(1)
print(i,end='') #(2)
上边(1)和(2)的作用是一样的,strip()和end=''的目的都是去除换行
c,以r的模式打开原文件,以readlines()方法读取出来,并循环遍历
readlines(),并分析b,与c 有什么区别?深入理解文件句柄与readlines()结果的区别。
with open('t1.txt',mode='r',encoding='utf-8') as f:
ff=f.readlines()
# print(ff)
for i in ff:
print(i.strip())
b是直接遍历句柄,读出来,
c是先用readlines把文件内的信息放到列表中,相当于我们再遍历列表中的信息
d,以r模式读取‘葫芦娃’前三个字符。
with open('t1.txt',mode='r',encoding='utf-8') as f:
s=f.read(3)
print(s)
e,以r模式读取第一行内容,并去除此行前后的空格,制表符,换行符。(换行符是\n,制表符是\t(tab).\r)
with open('t1.txt',mode='r',encoding='utf-8') as f:
# k=f.readline().strip() #测试(1)
k=f.readline() #测试(2)
print(k)
#测试的结果中(1)和(2)的结果是一样的

f,以r模式打开文件,从‘风吹雨打.....’开始读取,一直读到最后。
with open('t1.txt',mode='r',encoding='utf-8') as f:
for i in f:
if i.startswith('风吹雨打'): #如果开头是"风吹雨打
# print(i,end='') #(1)把后边的换行去掉
# print(i) #中间会空一行,应该把后边的换行去掉
print(i.strip()) #(2)把后边的换行去掉 ,注意(1)和(2)的效果一样
print(f.read()) #从风吹雨打这一行最末尾,开始读剩下的信息
g,以a+模式打开文件,先追加一行:‘老男孩教育’然后在从最开始将原内容全部读取出来。
with open('t1.txt',mode='a+',encoding='utf-8') as f:
f.write('\n老男孩教育')
f.seek(0)
ff=f.read()
print(ff)
h,截断原文件,留下内容:‘葫芦娃’
#方法一:
with open('t1.txt',mode='a+',encoding='utf-8') as f:
f.truncate(9) #注意这里的truncate是字节码的个数
f.seek((0))
print(f.read())
#方法二:
with open('t1.txt',mode='a+',encoding='utf-8') as f:
f.seek(9)
f.truncate()
f.seek(0)
print(f.read())
3.文件a.txt内容:每一行内容分别为商品名字,价钱,个数。 apple 10 3
tesla 100000 1
mac 3000 2
lenovo 30000 3
chicken 10 3 通过代码,将其构建成这种数据类型:
[{'name':'apple','price':10,'amount':3},{'name':'tesla','price':1000000,'amount':1}......]
并计算出总价钱。
with open('a.txt',mode='r',encoding='utf-8') as f:
lst=[]
for i in f:
dic = {}
s=i.split()
# print(s)
dic['name']=s[0]
dic['price']=s[1]
dic['amount']=s[2]
lst.append(dic)
# print(dic)
print(lst)
sum=0
for k in lst:
sum+=int(k['price'])*int(k['amount'])
print(sum)
4,有如下文件: alex是老男孩python发起人,创建人。
alex其实是人妖。
谁说alex是sb?
你们真逗,alex再牛逼,也掩饰不住资深屌丝的气质。 将文件中所有的alex都替换成大写的SB(文件的改的操作)。
with open('pythonalex',mode='r',encoding='utf-8') as f,\
open('pythonalex_911',mode='w',encoding='utf-8')as f1:
for i in f:
if 'alex' in i:
i=i.replace('alex','SB') #这个地方必须用等于
f1.write(i)
import os
os.remove('pythonalex')
os.rename('pythonalex_911','pythonalex')
5,文件a1.txt内容(升级题) name:apple price:10 amount:3 year:2012
name:tesla price:100000 amount:1 year:2013
....... 通过代码,将其构建成这种数据类型:
[{'name':'apple','price':10,'amount':3},
{'name':'tesla','price':1000000,'amount':1}......]
并计算出总价钱。
#我把文件名改成了b1
with open('b1',mode='r',encoding='utf-8') as f:
lst=[]
for i in f:
dic={}
s=i.split() #字符串切割成列表:[name:apple,price:10,amount:3,year:2012]
for k in s:
l=k.split(':') #[name,apple]
dic[l[0]]=l[1]
dic.pop('year')
lst.append(dic)
print(lst)
sum=0
for z in lst:
sum+=int(z['price'])*int(z['amount'])
print(sum)
6,文件a1.txt内容(升级题) 序号 部门 人数 平均年龄 备注
1 python 30 26 单身狗
2 Linux 26 30 没对象
3 运营部 20 24 女生多
....... 通过代码,将其构建成这种数据类型:
[{'序号':'1','部门':Python,'人数':30,'平均年龄':26,'备注':'单身狗'},......]
with open('c1.txt',mode='r+',encoding='utf-8') as f:
# ff=f.readline().strip()
ff=f.readline()
s=ff.split() #列表:[序号,部门,人数,平均年龄,备注]
# print(s)
# f3=f.read()
# print(f3)
# print(s)
li=[]
for i in f: #i是: 1 python 30 26 单身狗
dic={}
# print(i.strip())
i=i.strip()
ii=i.split()
for z in range(len(s)):
dic[s[z]]=ii[z] #重点注意:在这里分割的是用ii,不是li,在这个地方纠结了好长时间
li.append(dic)
print(li)
明日默写:
就是第4题的代码(课上讲过)。
巨蟒python全栈开发-第8天 文件操作的更多相关文章
- 巨蟒python全栈开发linux之centos2
1.一些命令回顾 在vm中,右击"打开终端",输入命令ifconfig,得到的下图算是一个终端,并且我们可以看到服务器的ip是192.168.34.128 我们通过windows上 ...
- 巨蟒python全栈开发-第5天 字典&集合
今日大纲: 1.什么是字典 字典是以key:value的形式来保存数据,用{}表示. 存储的是key:value 2.字典的增删改查(重点) (1) 添加 dic[新key] = 值 setdefau ...
- 巨蟒python全栈开发-第9天 初识函数
一.今日主要内容总览(重点) 1.什么是函数? f(x)=x+1 y=x+1 函数是对功能或者动作的封装2.函数的语法和定义 def 函数名(): 函数体 调用:函数名()3.关于函数的返回值 ret ...
- python 全栈开发,Day61(库的操作,表的操作,数据类型,数据类型(2),完整性约束)
昨日内容回顾 一.回顾 定义:mysql就是一个基于socket编写的C / S架构的软件 包含: ---服务端软件 - socket服务端 - 本地文件操作 - 解析指令(mysql语句) ---客 ...
- 巨蟒python全栈开发linux之centos1
1.linux服务器介绍 2.linux介绍 3.linux命令学习 linux默认有一个超级用户root,就是linux的皇帝 注意:我的用户名是s18,密码是centos 我们输入密码,点击解锁( ...
- 巨蟒python全栈开发-第20天 核能来袭-约束 异常处理 MD5 日志处理
一.今日主要内容 1.类的约束(对下面人的代码进行限制;项目经理的必备技能,要想走的长远) (1)写一个父类,父类中的某个方法要抛出一个异常 NotImplementedError(重点) (2)抽象 ...
- 巨蟒python全栈开发linux之centos6
1.nginx复习 .nginx是什么 nginx是支持反向代理,负载均衡,且可以实现web服务器的软件 在129服务器中查看,我们使用的是淘宝提供的tengine,也是一种nginx服务器 我们下载 ...
- 巨蟒python全栈开发linux之centos3
1.作业讲解 (1)递归创建文件夹/tmp/oldboy/python/{alex,wusir,nvshen,xiaofeng} 下面中的路径没有必要换,在哪里创建都行,根目录下或者tmp目录下或者其 ...
- 巨蟒python全栈开发django5:组件&&CBV&FBV&&装饰器&&ORM增删改查
内容回顾: 补充反向解析 Html:{% url ‘别名’ 参数 %} Views:reverse(‘别名’,args=(参数,)) 模板渲染 变量 {{ 变量名 }} 逻辑相关 {% %} 过滤器: ...
随机推荐
- python-数据结构Data Structure1
四种数据结构: 列表list = [val1,val2,val3,val4]字典dict = {key1:val1,key2:val2}元组tuple = (val2,val2,val3,val4)集 ...
- JS -判断、监听屏幕横竖屏切换事件
通过监听window.orientationchange事件,当横竖屏切换事件时触发 <!doctype html> <html> <head> <title ...
- unity, Destroy注意事项
Destroy不是立即发生作用,而是推迟到帧末,所以下面代码是错误的: void OnTriggerEnter(Collider other){ if (other.gameObject.tag ...
- 图片onerror事件,为图片加载指定默认图片
为图片指定加载失败时显示默认图片,js输出的img对象,onerror是事件,不是属性,所以这样写是不起作用的: var img = $(document.createElement("IM ...
- [Yii Framework] Share the session with memcache in Yii
When developing distributed applications with Yii, naturally, we will face that we have to share the ...
- 608. Two Sum - Input array is sorted【medium】
Given an array of integers that is already sorted in ascending order, find two numbers such that the ...
- lantin1
Latin1是ISO-8859-1的别名,有些环境下写作Latin-1. ISO-8859-1编码是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCI ...
- 0044 spring框架的applicationContext.xml的命名空间
Spring框架中,创建bean,装配bean,事务控制等,可以用xml配置或者注解扫描的方法实现.如果用注解扫描,在xml配置中得加上 <context:component-scan base ...
- C#中Equals和==的比较
一.值类型的比较 对于值类型来说 两者比较的都是”内容”是否相同,即 值 是否一样,很显然此时两者是划等号的. ; ; Console.WriteLine("i==j"+(i== ...
- Spark1.5堆内存分配
这是spark1.5及以前堆内存分配图 下边对上图进行更近一步的标注,红线开始到结尾就是这部分的开始到结尾 spark 默认分配512MB JVM堆内存.出于安全考虑和避免内存溢出,Spark只允许我 ...