IDEA Generate pojo(data first)基于 spring data jpa - code
基于 idea 的 pojo生成
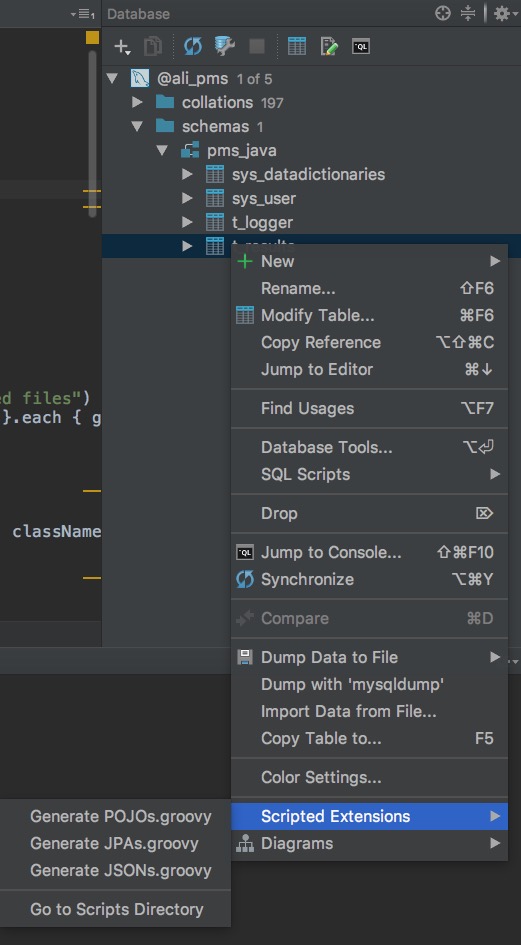
右侧菜单栏 Database->New( + 图标)->Data source-> mysql(根据自己的数据源选择)
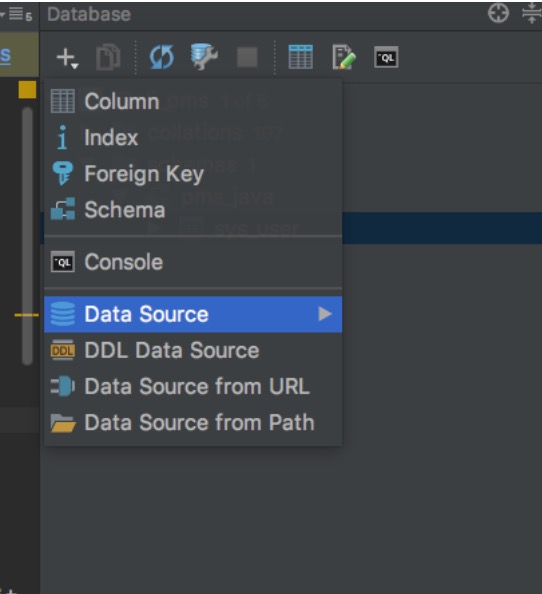

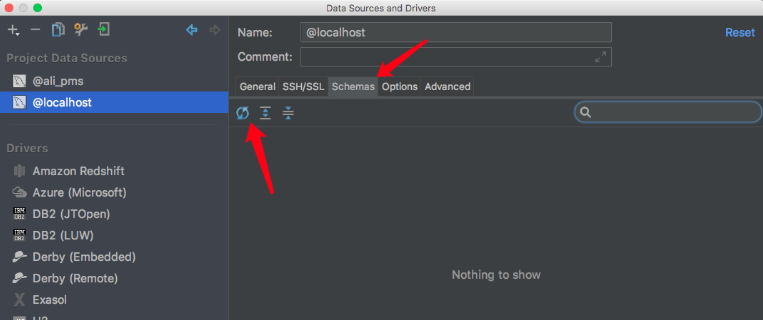
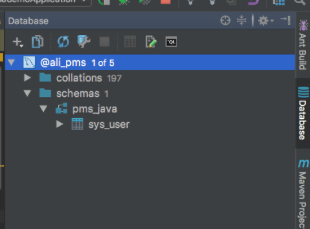
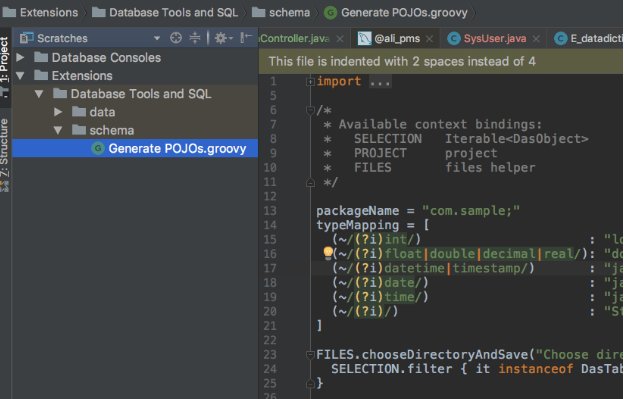
使用:
代码如下: POJOs.groovy
import com.intellij.database.model.DasTable
import com.intellij.database.model.ObjectKind
import com.intellij.database.util.Case
import com.intellij.database.util.DasUtil /*
* Available context bindings:
* SELECTION Iterable<DasObject>
* PROJECT project
* FILES files helper
*/ packageName = "com.sephiroth.jpademo.entity;"
typeMapping = [
(~/(?i)int/) : "long",
(~/(?i)float|double|decimal|real/): "double",
(~/(?i)datetime|timestamp/) : "java.sql.Timestamp",
(~/(?i)date/) : "java.sql.Date",
(~/(?i)time/) : "java.sql.Time",
(~/(?i)/) : "String"
] FILES.chooseDirectoryAndSave("Choose directory", "Choose where to store generated files") { dir ->
SELECTION.filter { it instanceof DasTable && it.getKind() == ObjectKind.TABLE }.each { generate(it, dir) }
} def generate(table, dir) {
def className = javaName(table.getName(), true)
def fields = calcFields(table)
new File(dir, "E_"+className + ".java").withPrintWriter { out -> generate(out, className, fields,table.getName()) }
} def generate(out, className, fields ,tablename) {
out.println "package $packageName"
out.println ""
out.println ""
// 引用映射
out.println "import org.hibernate.annotations.GenericGenerator;"
out.println ""
out.println "import javax.persistence.*;"
out.println "import java.io.Serializable;"
// jpa映射
out.println "@Entity"
out.println "@Table(name = \"$tablename\")"
// jpa映射end
out.println "public class E_$className implements Serializable {"
out.println ""
fields.each() {
if (it.annos != "") out.println " ${it.annos}"
// 列映射
// 主键映射
if (it.name == "id" && it.type == "String") {
out.println """ @GenericGenerator(name = "user-uuid", strategy = "uuid")
@GeneratedValue(generator = "user-uuid")
@Column(name = "id", nullable = false, length = 64)"""
}
else if(it.name == "id") {
out.println """ @GeneratedValue
@Column(name = \"$it.colname\")"""
}
else {
out.println " @Column(name = \"$it.colname\")"
}
out.println " private ${it.type} ${it.name};"
}
out.println ""
fields.each() {
out.println ""
out.println " public ${it.type} get${it.name.capitalize()}() {"
out.println " return ${it.name};"
out.println " }"
out.println ""
out.println " public void set${it.name.capitalize()}(${it.type} ${it.name}) {"
out.println " this.${it.name} = ${it.name};"
out.println " }"
out.println ""
}
out.println "}"
} def calcFields(table) {
DasUtil.getColumns(table).reduce([]) { fields, col ->
def spec = Case.LOWER.apply(col.getDataType().getSpecification())
def typeStr = typeMapping.find { p, t -> p.matcher(spec).find() }.value
fields += [[
name : javaName(col.getName(), false),
colname : col.getName(),
type : typeStr,
annos: """
/**
* $col.comment
*/"""]]
}
} def javaName(str, capitalize) {
def s = com.intellij.psi.codeStyle.NameUtil.splitNameIntoWords(str)
.collect { Case.LOWER.apply(it).capitalize() }
.join("")
.replaceAll(/[^\p{javaJavaIdentifierPart}[_]]/, "_")
capitalize || s.length() == 1? s : Case.LOWER.apply(s[0]) + s[1..-1]
}
IDEA Generate pojo(data first)基于 spring data jpa - code的更多相关文章
- 【Spring Data 系列学习】Spring Data JPA 基础查询
[Spring Data 系列学习]Spring Data JPA 基础查询 前面的章节简单讲解了 了解 Spring Data JPA . Jpa 和 Hibernate,本章节开始通过案例上手 S ...
- 【Spring Data 系列学习】Spring Data JPA @Query 注解查询
[Spring Data 系列学习]Spring Data JPA @Query 注解查询 前面的章节讲述了 Spring Data Jpa 通过声明式对数据库进行操作,上手速度快简单易操作.但同时 ...
- 【Spring Data 系列学习】Spring Data JPA 自定义查询,分页,排序,条件查询
Spring Boot Jpa 默认提供 CURD 的方法等方法,在日常中往往时无法满足我们业务的要求,本章节通过自定义简单查询案例进行讲解. 快速上手 项目中的pom.xml.application ...
- Spring Data ElasticSearch的使用
1.什么是Spring Data Spring Data是一个用于简化数据库访问,并支持云服务的开源框架.其主要目标是使得对数据的访问变得方便快捷,并支持map-reduce框架和云计算数据服务. S ...
- Spring Data JPA例子[基于Spring Boot、Mysql]
关于Spring Data Spring社区的一个顶级工程,主要用于简化数据(关系型&非关系型)访问,如果我们使用Spring Data来开发程序的话,那么可以省去很多低级别的数据访问操作,如 ...
- 转:使用 Spring Data JPA 简化 JPA 开发
从一个简单的 JPA 示例开始 本文主要讲述 Spring Data JPA,但是为了不至于给 JPA 和 Spring 的初学者造成较大的学习曲线,我们首先从 JPA 开始,简单介绍一个 JPA 示 ...
- 深入浅出学Spring Data JPA
第一章:Spring Data JPA入门 Spring Data是什么 Spring Data是一个用于简化数据库访问,并支持云服务的开源框架.其主要目标是使得对数据的访问变得方便快捷,并支持map ...
- 使用 Spring Data JPA 简化 JPA 开发
从一个简单的 JPA 示例开始 本文主要讲述 Spring Data JPA,但是为了不至于给 JPA 和 Spring 的初学者造成较大的学习曲线,我们首先从 JPA 开始,简单介绍一个 JPA 示 ...
- Spring Data Redis 让 NoSQL 快如闪电 (1)
[编者按]本文作者为 Xinyu Liu,详细介绍了 Redis 的特性,并辅之以丰富的用例.在本文的第一部分,将重点概述 Redis 的方方面面.文章系国内 ITOM 管理平台 OneAPM 编译呈 ...
随机推荐
- ping主机脚本
#!/bin/bash #ping net='172.16.1' uphosts=0 downhosts=0 for i in {1..254};do ping -c 1 -w 1 ${net}.${ ...
- 20145235李涛《网络对抗》逆向及Bof基础
上学期实验楼上做过这个实验 直接修改程序机器指令,改变程序执行流程 首先进行反汇编 我们所要修改的是,程序从foo返回,本来要返回到80484ba,而我们要把80484ba修改为getshell的 ...
- Python多类继承中,子类默认继承哪个父类的构造函数__init__
[1]python中如果子类有自己的构造函数,不会自动调用父类的构造函数,如果需要用到父类的构造函数,则需要在子类的构造函数中显式的调用. [2]如果子类没有自己的构造函数,则会直接从父类继承构造函数 ...
- java:java静态代理与动态代理简单分析
java静态代理与动态代理简单分析 转载自:http://www.cnblogs.com/V1haoge/p/5860749.html 1.动态代理(Dynamic Proxy) 代理分为静态代理和动 ...
- orecle常用函数
Oracle SQL 提供了用于执行特定操作的专用函数.这些函数大大增强了 SQL 语言的功能.函数可以接受零个或者多个输入参数,并返回一个输出结果. oracle 数据库中主要使用两种类型的函数 1 ...
- 有关写log的思考
前言 在软件开发过程中,log往往是不太引人注意的环节,大部分的log都只是开发人员为了调试bug临时加上的.这样出来的软件,最后的log往往杂乱无章没有系统性.我们判断一个软件系统的log写的好不好 ...
- UVA 1640 The Counting Problem(按位dp)
题意:给你整数a.b,问你[a,b]间每个数字分解成单个数字后,0.1.2.3.4.5.6.7.8.9,分别有多少个 题解:首先找到[0,b]与[0,a-1]进行区间减法,接着就只是求[0,x] 对于 ...
- maven项目Dao层优化
平时我们习惯一个实体类就对应一个dao类,这样做,增删改查都大同小异,只是实体类对象不一样而已,因此,我们可以把公用的方法抽取来,建立一个IBaseDao接口,如下: public interface ...
- Android -- junit测试框架,logcat获取log信息
1. 相关概念 白盒测试: 知道程序源代码. 根据测试的粒度分为不同的类型 方法测试 function test 单元测试 unit test 集成 ...
- 不常用的gcd公式
gcd(a^m-b^m,a^n-b^n)=a^(gcd(m,n))-b^(gcd(m,n))