第6章 HDFS HA配置
在Hadoop 2.0.0之前,一个HDFS集群中只有一个单一的NameNode,如果NameNode所在的节点宕机了或者因服务器软件升级导致NameNode进程不可用,则将导致整个集群无法访问,直到NameNode被重新启动。
HDFS高可用性(HDFS High Availability)解决了上述问题,它提供了一个选项,可以在同一个集群中运行两个NameNode,其中一个处于活动状态,另一个处于备用状态。当活动状态的NameNode崩溃时,HDFS集群可以快速切换到备用的NameNode,这样也就实现了故障转移功能。
为了使备用节点保持与活动节点同步的状态,两个节点都与一组称为“日志节点”(JournalNodes)的独立守护进程通信。当活动状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。备份状态的NameNode有能力读取JournalNodes中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。
本例中,各节点的角色分配如下表所示:
| 节点 | 角色 |
|---|---|
| centos01 | NameNode DataNode JournalNode |
| centos02 | NameNode DataNode JournalNode |
| centos03 | DataNode JournalNode |
配置之前最好将三个节点的$HADOOP_HOME/etc/hadoop文件夹与$HADOOP_HOME/tmp文件夹备份一下。备份命令如下:
[hadoop@centos01 etc]$ cp -r hadoop/ backup-hadoop
[hadoop@centos01 hadoop-2.7.1]$ cp -r tmp/ backup-tmp
注意:本例配置的总体思路是,先在centos01节点上配置完毕之后,再将改动的配置文件发送到centos02、centos03节点上。
6.1 hdfs-site.xml文件配置
要配置HA NameNodes,必须向hdfs-site.xml文件添加一些配置选项,设置这些配置的顺序并不重要,但是需要为选项dfs.nameservice和dfs. namenodes (nameservice ID)设置一个值,这个值将被后面的选项所引用。因此,在设置其他配置选项之前,应该先设置这些值。
向hdfs-site.xml文件加入以下内容(在之前配置的基础上追加):
<property>
<name>dfs.nameservices</name>
<value>mycluster</value><!--mycluster为自定义的值,下方配置要使用该值-->
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>centos01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>centos02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>centos01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>centos02:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://centos01:8485;centos02:8485;centos03:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/modules/hadoop-2.7.1/tmp/dfs/jn</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value><!--hadoop为当前用户名-->
</property>
上述参数解析如下:
dfs.nameservices:为nameservice设置一个逻辑名称ID(nameservice ID),名称ID可以自定义,例如mycluster。并使用这个逻辑名称ID作为配置选项的值。后续配置选项将引用该ID。
dfs.ha.namenodes.mycluster:nameservice中每个NameNode的唯一标识符。选项值是一个以逗号分隔的NameNode id列表。这将被DataNodes用于确定集群中的所有NameNodes。例如,本例中使用“mycluster”作为nameservice ID,并且使用“nn1”和“nn2”作为NameNodes的单个ID。需要注意的是,当前每个nameservice只能配置最多两个NameNodes。
dfs.namenode.rpc-address.mycluster.nn1:设置NameNode的RPC监听地址,需要设置NameNode进程的完整地址和RPC端口。
dfs.namenode.rpc-address.mycluster.nn2:设置另一个NameNode的RPC监听地址,需要设置NameNode进程的完整地址和RPC端口。
dfs.namenode.http-address.mycluster.nn1:设置NameNode的HTTP Web端监听地址,类似于上面的RPC地址,可以通过浏览器端访问NameNode。
dfs.namenode.http-address.mycluster.nn2:设置另一个NameNode的HTTP Web端监听地址,类似于上面的RPC地址,可以通过浏览器端访问NameNode。
dfs.namenode.shared.edits.dir:设置一组 JournalNode 的 URI 地址,活动状态的NameNode将 edit log 写入这些JournalNode,而备份状态的 NameNode 则读取这些 edit log,并作用在内存的目录树中。如果JournalNode有多个节点则使用分号分割。该属性值应符合以下格式:qjournal://host1:port1;host2:port2;host3:port3/nameservice ID。
dfs.journalnode.edits.dir: JournalNode所在节点上的一个目录,用于存放 edit log和其他状态信息。
dfs.client.failover.proxy.provider.mycluster:客户端与活动状态的NameNode 进行交互的 Java 实现类,DFS 客户端通过该类寻找当前的活动NameNode。目前Hadoop的唯一实现是ConfiguredFailoverProxyProvider类,除非我们自己对其定制,否则应该使用这个类。
dfs.ha.fencing.methods:解决HA集群脑裂问题(即出现两个 master 同时对外提供服务,导致系统处于不一致状态)。在 HDFS HA中,JournalNode只允许一个 NameNode 写数据,不会出现两个活动NameNode 的问题,但是,当主备切换时,之前的 活动 NameNode 可能仍在处理客户端的 RPC 请求,为此,需要增加隔离机制(fencing)将之前的活动NameNode 杀死。常用的fence方法是sshfence,使用ssh需要指定ssh通讯使用的密钥文件。
dfs.ha.fencing.ssh.private-key-files:指定上述选项ssh通讯使用的密钥文件在系统中的位置。
6.2 core-site.xml文件配置
修改core-site.xml文件中的fs.defaultFS属性值,为Hadoop客户端配置默认的访问路径,以使用新的支持HA的逻辑URI。将之前配置的hdfs://centos01:9000改为hdfs://mycluster,其中的mycluster为hdfs-site.xml中定义的nameservice ID值。内容如下:
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
文件hdfs-site.xml与core-site.xml都配置完成后,需要将这两个文件重新发送到集群其它的节点中,并覆盖原来的文件。
进入Hadoop安装目录,执行以下命令:
scp etc/hadoop/hdfs-site.xml hadoop@centos02:/opt/modules/hadoop-2.7.1/etc/hadoop/
scp etc/hadoop/hdfs-site.xml hadoop@centos03:/opt/modules/hadoop-2.7.1/etc/hadoop/
scp etc/hadoop/core-site.xml hadoop@centos02:/opt/modules/hadoop-2.7.1/etc/hadoop/
scp etc/hadoop/core-site.xml hadoop@centos03:/opt/modules/hadoop-2.7.1/etc/hadoop/
6.3 启动与测试
HDFS HA配置完成后,下面我们将集群启动,进行测试:
(1)删除各个节点的$HADOOP_HOME/tmp目录下的所有文件。在各个节点分别执行下面命令,启动三台JournalNode :
sbin/hadoop-daemon.sh start journalnode
(2)在centos01节点上执行namenode格式化,如果没有启动JournalNode,格式化将失败。
bin/hdfs namenode -format
出现如下输出代表格式化成功:
18/03/15 14:14:45 INFO common.Storage: Storage directory /opt/modules/hadoop-2.7.1/tmp/dfs/name has been successfully formatted.
(3)在centos01节点上执行如下命令,启动namenode:
sbin/hadoop-daemon.sh start namenode
启动namenode后会生成images元数据。
(4)在centos02上执行以下命令,将centos01上的NameNode元数据拷贝到centos02上(也可以直接将centos01上的$HADOOP_HOME/tmp目录拷贝到centos02上):
bin/hdfs namenode -bootstrapStandby
输出以下信息代表拷贝成功:
18/03/15 14:28:01 INFO common.Storage: Storage directory /opt/modules/hadoop-2.7.1/tmp/dfs/name has been successfully formatted.
(5)在centos02上执行以下命令,启动namenode2(备份的NameNode):
sbin/hadoop-daemon.sh start namenode
启动后,在浏览器中输入网址http://centos01:50070 查看namenode1(活动的NameNode)的状态。namenode1的状态显示,如下图所示。

在浏览器中输入网址http://centos02:50070 查看namenode2的状态。Namenode2的状态显示,如下图所示。
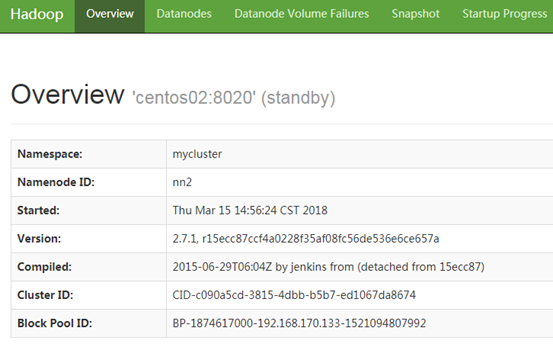
可以看到,此时两个namenode的状态都为standby。接下来我们需要将namenode1的状态设置为active。
(6)在centos01上执行如下命令,将namenode1的状态置为active:
bin/hdfs haadmin -transitionToActive nn1
上述代码中,nn1为hdfs-site.xml中设置的节点centos01上的namenode的ID标识符。
上述代码执行完毕后,刷新浏览器,可以看到namenode1的状态已经变为了active,如下图所示:
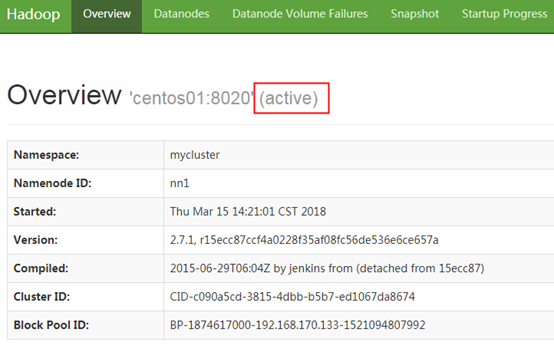
(7)重新启动HDFS
停止HDFS:
sbin/stop-dfs.sh
启动HDFS:
sbin/start-dfs.sh
(8)重启以后,NameNode、DataNode等进程都已经启动了,但两个NameNode的状态仍然都为standby,需要再次执行步骤(6)的命令,将namenode1的状态置为active。
(9)在各节点中执行jps命令,查看各节点启动的Java进程:
centos01节点上的Java进程:
[hadoop@centos01 hadoop-2.7.1]$ jps
8996 DataNode
9221 JournalNode
9959 Jps
8877 NameNode
centos02节点上的Java进程:
[hadoop@centos02 hadoop-2.7.1]$ jps
8162 NameNode
8355 JournalNode
8565 Jps
8247 DataNode
centos03节点上的Java进程:
[hadoop@centos03 hadoop-2.7.1]$ jps
7144 DataNode
7256 JournalNode
7371 Jps
(10)上传一个文件到HDFS,测试HDFS是否正常运行。若一切正常,接下来测试NameNode故障转移功能,首先将namenode1进程杀掉:
[hadoop@centos01 hadoop-2.7.1]$ jps
8996 DataNode
10452 Jps
9221 JournalNode
8877 NameNode
[hadoop@centos01 hadoop-2.7.1]$ kill -9 8877
然后查看namenode2的状态,发现仍然是standby,没有自动切换到active,此时需要手动执行步骤(6)的命令,将namenode2的状态切换为active。再次进行HDFS文件系统的测试,发现一切正常。
以上描述了如何配置手动故障转移。在该模式下,即使活动节点失败,系统也不会自动触发从active到备用NameNode的故障转移。这样手动切换NameNode虽然能解决故障问题,但是还是比较麻烦,可不可以自动切换呢?答案是肯定的。下一节讲解HDFS结合ZooKeeper进行自动故障转移。
6.4 结合ZooKeeper进行自动故障转移
自动故障转移为HDFS部署添加了两个新组件:一个ZooKeeper quorum和ZKFailoverController流程(缩写为ZKFC)。
Apache ZooKeeper是一种高度可用的服务,用于维护少量的协调数据,通知客户数据的变化,并监控客户的失败。自动HDFS故障转移的实现主要依赖于ZooKeeper的如下功能:
* 故障检测——集群中的每个NameNode机器都在ZooKeeper中维护一个持久会话。如果机器崩溃,ZooKeeper会话将过期,通知另一个NameNode,它将触发故障转移。
* 活动的NameNode选举——ZooKeeper提供了一个简单的机制来专门选择一个活动的节点。如果当前活动的NameNode崩溃,另一个节点可能会在ZooKeeper中使用一个特殊的独占锁,这表明它应该成为下一个活 动。
* ZKFailoverController (ZKFC)是一个新的组件,它是一个ZooKeeper客户端,它也监视和管理NameNode的状态。每个运行NameNode的机器都运行一个ZKFC。
* 健康监测——ZKFC以健康检查命令定期对本地的NameNode进行检测。只要NameNode能及时地以健康的状态做出反应,ZKFC就认为该节点是健康的。如果该节点崩溃、冻结或进入不健康状态,健康监控器将标记为不健康状态。
有关自动故障转移设计的更多细节,请参考Apache HDFS JIRA上的HDFS-2185的设计文档。
本例中,各节点的角色分配如下表:
| 节点 | 角色 |
|---|---|
| centos01 | NameNode DataNode JournalNode ZKFC QuorumPeerMain |
| centos02 | NameNode DataNode JournalNode ZKFC QuorumPeerMain |
| centos03 | DataNode JournalNode QuorumPeerMain |
HDFS集成ZooKeeper来实现NameNode的自动故障转移,操作步骤如下:
(1)修改hdfs-site.xml文件,加入以下内容:
<!--开启自动故障转移,mycluster为自定义配置的nameservice ID值-->
<property>
<name>dfs.ha.automatic-failover.enabled.mycluster</name>
<value>true</value>
</property>
(2)修改core-site.xml文件,加入以下内容,指定ZooKeeper集群:
<property>
<name>ha.zookeeper.quorum</name>
<value>centos01:2181,centos02:2181,centos03:2181</value>
</property>
(3)发送修改好的hdfs-site.xml、core-site.xml文件到集群其它节点,覆盖原来的文件(这一步容易被忽略)。
(4)停止HDFS集群:
sbin/stop-dfs.sh
(5)启动ZooKeeper集群:
分别进入每个节点的安装目录,执行如下命令:
bin/zkServer.sh start
(6)初始化HA在ZooKeeper中的状态:
在centos01节点上执行如下命令,将在ZooKeeper中创建一个znode,存储自动故障转移系统的数据:
bin/hdfs zkfc -formatZK
(7)启动HDFS集群:
sbin/start-dfs.sh
(8)由于我们是手动管理集群上的服务,所以需要手动启动运行NameNode的每个机器上的zkfc守护进程。分别在centos01和centos02上执行以下命令,启动zkfc进程(先在哪个节点上启动,哪个节点的namenode状态就是active):
sbin/hadoop-daemon.sh start zkfc
(或者执行bin/hdfs start zkfc也可以,两种启动方式。)
(9)上传文件到HDFS进行测试。
在centos01中上传一个文件,然后停止namenode1,读取刚才上传的文件内容。相关命令及输出如下:
[hadoop@centos01 hadoop-2.7.1]$ jps
13105 QuorumPeerMain
13523 DataNode
13396 NameNode
13753 JournalNode
13882 DFSZKFailoverController
14045 Jps
[hadoop@centos01 hadoop-2.7.1]$ kill -9 13396
[hadoop@centos01 hadoop-2.7.1]$ jps
13105 QuorumPeerMain
14066 Jps
13523 DataNode
13753 JournalNode
13882 DFSZKFailoverController
[hadoop@centos01 hadoop-2.7.1]$ hdfs dfs -cat /input/*
如果仍能成功读取文件内容,说明自动故障转移配置成功。此时我们在浏览器中访问namenode2,可以看到namenode2的状态变为了active。

查看各节点的Java进程,命令及输出结果如下:
[hadoop@centos01 hadoop-2.7.1]$ jps
3360 QuorumPeerMain
4080 DFSZKFailoverController
3908 JournalNode
3702 DataNode
4155 Jps
3582 NameNode
[hadoop@centos02 hadoop-2.7.1]$ jps
3815 DFSZKFailoverController
3863 Jps
3480 NameNode
3353 QuorumPeerMain
3657 JournalNode
3563 DataNode
[hadoop@centos03 zookeeper-3.4.9]$ jps
3496 JournalNode
3293 QuorumPeerMain
3390 DataNode
3583 Jps
原创文章,转载请注明出处!!
第6章 HDFS HA配置的更多相关文章
- 第7章 YARN HA配置
目录 7.1 yarn-site.xm文件配置 7.2 测试YARN自动故障转移 ResourceManager (RM)负责跟踪集群中的资源,以及调度应用程序(例如,MapReduce作业).在Ha ...
- 3.16 使用Zookeeper对HDFS HA配置自动故障转移及测试
一.说明 从上一节可看出,虽然搭建好了HA架构,但是只能手动进行active与standby的切换: 接下来看一下用zookeeper进行自动故障转移: # 在启动HA之后,两个NameNode都是s ...
- 3.配置HDFS HA
安装zookeeper下载zookeeper编辑zookeeper配置文件创建myid文件启动zookeeper配置HDFS HA配置手动HA配置自动HA启动HDFS HA namenode负责管理整 ...
- [转]HDFS HA 部署安装
1. HDFS 2.0 基本概念 相比于 Hadoop 1.0,Hadoop 2.0 中的 HDFS 增加了两个重大特性,HA 和 Federaion.HA 即为 High Availability, ...
- 第九章 搭建Hadoop 2.2.0版本HDFS的HA配置
Hadoop中的NameNode好比是人的心脏,非常重要,绝对不可以停止工作.在hadoop1时代,只有一个NameNode.如果该NameNode数据丢失或者不能工作,那么整个集群就不能恢复了.这是 ...
- 使用QJM实现HDFS的HA配置
使用QJM实现HDFS的HA配置 1.背景 hadoop 2.0.0之前,namenode存在单点故障问题(SPOF,single point of failure),如果主机或进程不可用时,整个集群 ...
- CentOS7安装CDH 第七章:CDH集群Hadoop的HA配置
相关文章链接 CentOS7安装CDH 第一章:CentOS7系统安装 CentOS7安装CDH 第二章:CentOS7各个软件安装和启动 CentOS7安装CDH 第三章:CDH中的问题和解决方法 ...
- 部署hadoop2.7.2 集群 基于zookeeper配置HDFS HA+Federation
转自:http://www.2cto.com/os/201605/510489.html hadoop1的核心组成是两部分,即HDFS和MapReduce.在hadoop2中变为HDFS和Yarn.新 ...
- HAWQ配置之HDFS HA
一.在ambari管理界面启用HDFS HA 在ambari中这步很简单,在所有安装的服务都正常之后,在HDFS的服务界面中,点击下拉菜单“Actions”,选择启用HDFS HA项 “Enable ...
随机推荐
- 如何让LoadRunner实现多个场景运行?
如何让LoadRunner实现多个场景运行? 发布时间: 2013-11-29 10:59 作者: stevenlee 来源: 51Testing软件测试网博客 字体: 小 中 大 ...
- linux定时备份MySQL数据库并删除七天前的备份文件
1.创建备份文件夹 #cd /bak#mkdir mysqldata 2.编写运行脚本 #nano -w /usr/sbin/bakmysql.sh 注:如使用nano编辑此代码需在每行尾添加’&am ...
- eclipse tomcat jdk 版本引用
今日遇到一个问题,因为比较难找,所以记录下来,方便日后查阅,也许也可以帮助同行. 一个Java project工程,使用了solr6.2,所以需要引用jdk8才可以正常使用. 代码编写好了,已经提交s ...
- 使用Python批量合并PDF文件(带书签功能)
网上找了几个合并pdf的软件,发现不是很好用,一般都没有添加书签的功能. 又去找了下python合并pdf的脚本,发现也没有添加书签的功能的. 于是自己动手编写了一个小工具,使用了PyPDF2. 下面 ...
- 对EJB的认识
对EJB的认识 接触EJB以来有一段时间了,走马观花一样把它所涉及到的东西看了一遍,随着深入了解越来越感觉到ejb的很强大,用了java后觉的java好用.学历SSH觉的比java好用.学了ejb觉的 ...
- nginx里配置跨域
发布于 881天前 作者 wendal 1404 次浏览 复制 上一个帖子 下一个帖子 标签: nginx 跨域 if ($request_method = OPTIONS ) { add ...
- postgresql+postgis+pgrouting实现最短路径查询(3)--流程图
项目结束,做一个项目的总结汇报,就把最短路径查询的实现流程图画了一下,现在补出来:
- Android(java)学习笔记209:Android线程形态之 HandlerThread
1. HandlerThread Android HandlerThread 完全解析 Handler与HandlerThread区别,HandlerThread应用(对比AsyncTask) 备注 ...
- 如何用jstl的select标签做二级联动下拉列表框??
下拉列表框的多级联动早就会了.但是用jstl的select标签做下拉列表框的做二级联动的时候还是遇到了些问题.主要问题在用Ajax查询到的数据如何拼成下拉选项的时候.其实很简单,但我还是折腾了好久.所 ...
- PHP使用in_array函数检查数组中是否存在某个值
PHP使用 in_array() 函数检查数组中是否存在某个值,如果存在则返回 TRUE ,否则返回 FALSE. bool in_array( mixed needle, array array [ ...