[翻译]Review——How to do Speech Recognition with Deep Learning
原文地址:https://medium.com/@ageitgey/machine-learning-is-fun-part-6-how-to-do-speech-recognition-with-deep-learning-28293c162f7a
How to do Speech Recognition with Deep Learning
如何用深度学习做语音识别
Andrew Ng 说语音识别从让人恼怒的不可靠到令人难以置信的有用中间只有4%的距离,是深度学习让这一切成为可能。
机器学习的过程不总是黑盒,我们将语音记录喂给神经网络,就可以得到纯文本输出。其过程如下如所示:

但问题是,每个人发音的习惯不同,同样说‘Hello’,有人语速极快,有人说的很慢。因此建立可靠的识别模型就需要一些小技巧。
一、将声音转换成比特
我们可以记录声波,然后将其用数字形式表示,并形成二维数组。
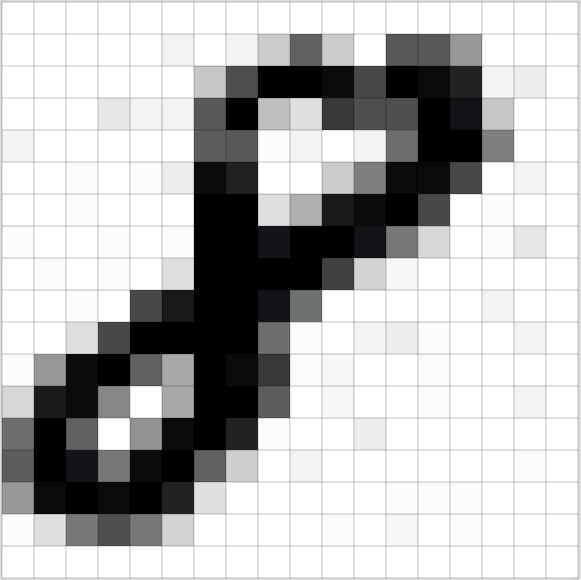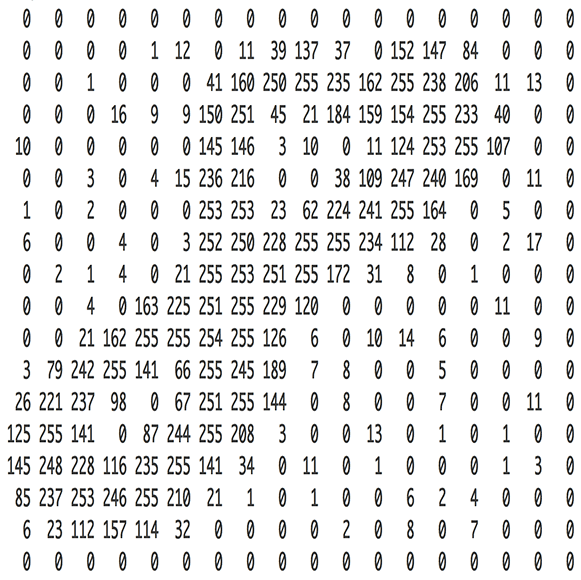
上面是最终效果。但声音被采集的原始形式是声波,比如下图就是‘Hello’的声音片段。

‘Hello’的声音片段比较复杂,先看一个简单的声音片段:
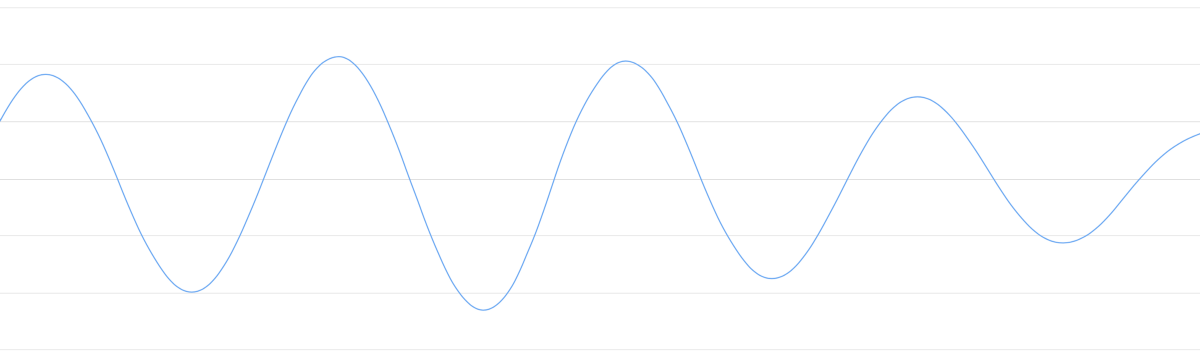
虽然声音是一维的,但加上时间属性后,我们可以将它转为二维图像:

这就是“采样”。我们对样本进行每秒千次的阅读便可以准确的记录它的数据。下图是“Hello”的前100个采样数据:

但又有一个问题,采样的数据就一定等于原数据吗?

理论上来说,只要以我们所需采集的数据最高频的两倍来采集数据,就可以完美呈现近似原音的效果。很多人以为采集数据次数越多,数据点越紧密效果越高,其实这是错误的。
二、预处理声音数据
拿到数据后,我们要对其进行预处理,这个过程会面临很多问题。比如,声音片段并不都是纯粹的标准样本,现实环境复杂多变,说话者可能是在嘈杂的环境下讲话,并且伴有严重的连读和口音,这都给语音识别增加了困难。
首先来看看我们以1/16,000次每秒为间隔采集到的数据:
在坐标系里绘制这些点集,可以得到近似原声波的图:

这个声音片段是由不同频率的声音复杂组合而成。为了使它更容易被神经网络处理,我们将其分离出低音部分,再分离出下一个低音部分,以此类推。然后将(从低到高)每个频段(frequency band)中的能量相加,我们就为各个类别的音频片段创建了一个指纹(fingerprint)。就像把一段音乐分离成一个个单独的音符一般。
这时需要借助傅里叶变换,它将复杂的声波分解为简单的声波,每一份频段所包含的能量不同,将能量相加,就能得到从低音到高音,每个频率范围的重要程度。以每 50hz 为一个频段的话,我们这 20 毫秒的音频所含有的能量从低频到高频就可以表示为下面的列表:
将其绘成声音图谱:

重复这个过程,最终会得到一个频谱图:

这样你能更清楚的发现声音模式,神经网络也更容易接收它。
三、从短声音里识别字符
经过处理的声音数据更容易被训练。将20毫秒的声音切片喂给神经网络,它会输出单个字母:
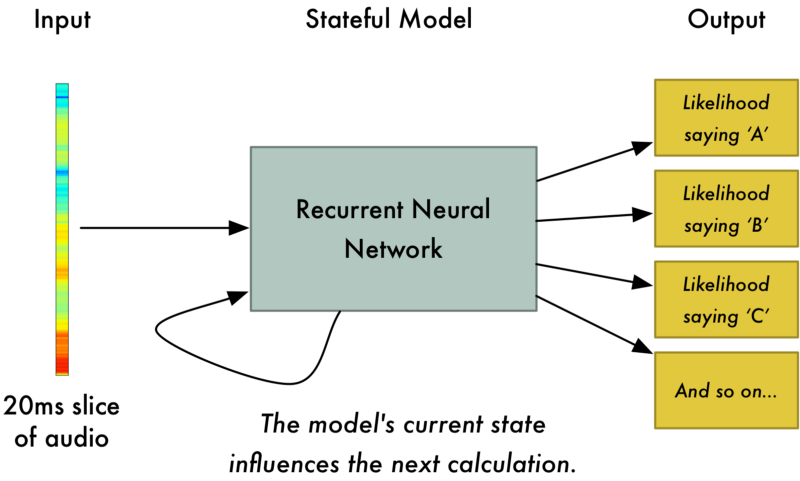
我们使用循环神经网络来处理数据,它具有预测功能。当我们将每个声音切片都依次喂给循环神经网络后,会得到如下映射:
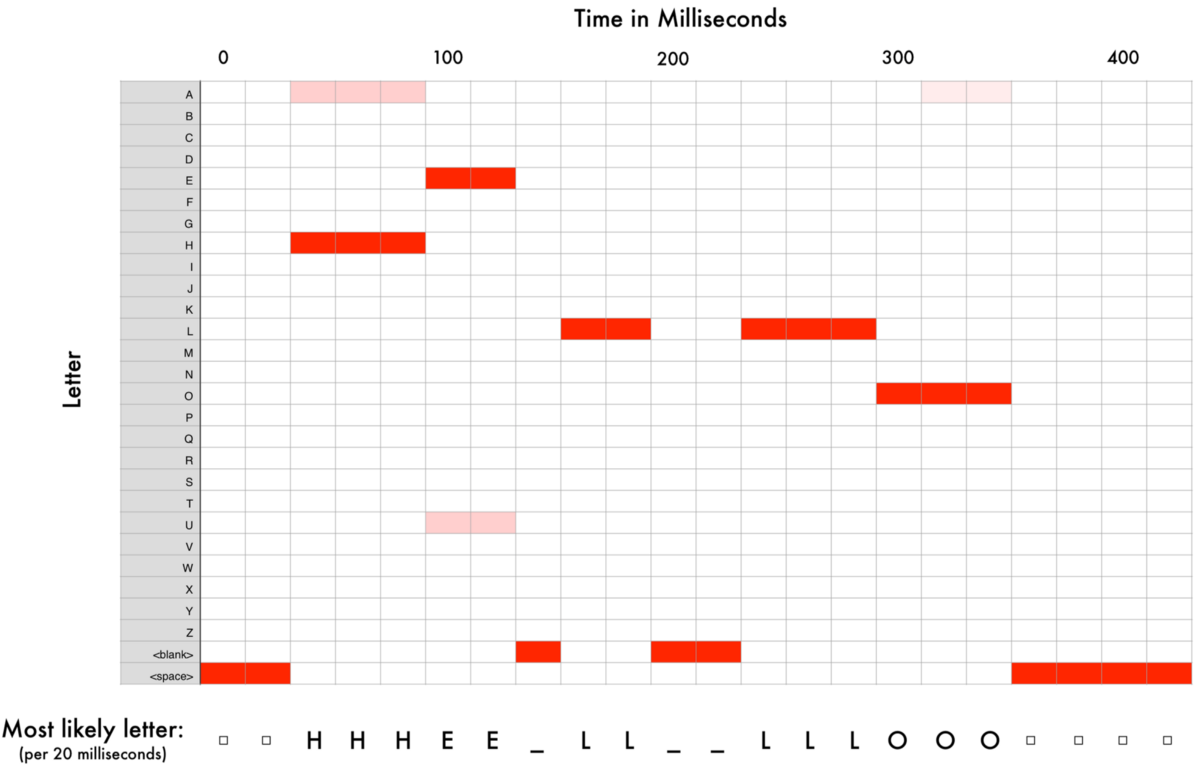
其中每一列的红色块代表了每个声音切片最有可能对应的字母。
然后我们拿到的数据可能是这样的:
- HHHEE_LL_LLLOOO becomes HE_L_LO
- HHHUU_LL_LLLOOO becomes HU_L_LO
- AAAUU_LL_LLLOOO becomes AU_L_LO
先去掉下划线:
- HE_L_LO becomes HELLO
- HU_L_LO becomes HULLO
- AU_L_LO becomes AULLO
剩下的三种可能输出都是神经网络对于声音纯粹的解读。此时我们需要用到自然语言处理的数据库,基于大数据做训练匹配,从而选出出现可能性最大的词。但有时,可能性最大的词也许并不是你想要的结果。因此,此处仍有待完善的地方。
四、训练自己的语音识别模型
你得克服几乎无穷无尽的挑战:劣质麦克风、背景噪音、混响和回声、口音差异等等。你的训练数据需要囊括这所有的一切,才能确保神经网络可以接受它们。
[翻译]Review——How to do Speech Recognition with Deep Learning的更多相关文章
- 论文翻译:2015_DNN-Based Speech Bandwidth Expansion and Its Application to Adding High-Frequency Missing Features for Automatic Speech Recognition of Narrowband Speech
论文地址:基于DNN的语音带宽扩展及其在窄带语音自动识别中加入高频缺失特征的应用 论文代码:github 博客作者:凌逆战 博客地址:https://www.cnblogs.com/LXP-Never ...
- 论文阅读笔记“Attention-based Audio-Visual Fusion for Rubust Automatic Speech recognition”
关于论文的阅读笔记 论文的题目是“Attention-based Audio-Visual Fusion for Rubust Automatic Speech recognition”,翻译成中文为 ...
- 论文翻译:2020_TinyLSTMs: Efficient Neural Speech Enhancement for Hearing Aids
论文地址:TinyLSTMs:助听器的高效神经语音增强 音频地址:https://github.com/Bose/efficient-neural-speech-enhancement 引用格式:Fe ...
- Utterance-Wise Recurrent Dropout And Iterative Speaker Adaptation For Robust Monaural Speech Recognition
单声道语音识别的逐句循环Dropout迭代说话人自适应 WRBN(wide residual BLSTM network,宽残差双向长短时记忆网络) [2] J. Heymann, L. Dr ...
- FPGA 17最佳论文导读 ESE: Efficient Speech Recognition Engine with Compressed LSTM on FPGA
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.机器学习技术感兴趣的同学加入. 后面陆续写一些关于神经网络加 ...
- Speech Recognition Grammar Specification Version 1.0 JavaScript TTS 文本发音
Speech Recognition Grammar Specification Version 1.0 https://www.w3.org/TR/speech-grammar/ W3C Recom ...
- Speech Recognition Java Code - HMM VQ MFCC ( Hidden markov model, Vector Quantization and Mel Filter Cepstral Coefficient)
Hi everyone,I have shared speech recognition code inhttps://github.com/gtiwari333/speech-recognition ...
- C#的语音识别 using System.Speech.Recognition;
using System; using System.Collections.Generic; using System.Linq; using System.Speech.Recognition; ...
- 第三篇:ASR(Automatic Speech Recognition)语音识别
ASR(Automatic Speech Recognition)语音识别: 百度语音--语音识别--python SDK文档: https://ai.baidu.com/docs#/ASR-Onli ...
随机推荐
- css里面鼠标的形状-----》easyui哪点事
用css控制鼠标样式的语法如下:<span style="cursor:*">文本或其它页面元素</span>把 * 换成如下15个效果的一种: 下面是对这 ...
- UITextInputMode
An instance of the UITextInputMode class represents the current text-input mode. You can use this ob ...
- 机器学习中的范数规则化之 L0、L1与L2范数、核范数与规则项参数选择
装载自:https://blog.csdn.net/u012467880/article/details/52852242 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理 ...
- [BZOJ 5074][Lydsy1710月赛]小B的数字
传送门 \(\color{green}{solution}\) 设 \[b_{i}=2^{w_{i}},sum= \sum_{i=1}^{n}{w_{i}}\] 则对于任意\(a_{i}\)都有 \[ ...
- centeros7安装docker
一.官方安装 https://docs.docker.com/install/linux/docker-ce/centos/#upgrade-docker-after-using-the-conven ...
- 2017 FVDI2 ABRITES Commander with 18 Softwares FULL Version + FLY OBD Terminator + J2534 DrewTech Softwares
Highlights of FVDI2 Abrites Commander Full Version: 1.Free update online. 2.This is full version FVD ...
- TR-069_Amendment-4:附录G.穿越NAT网关的连接请求方式
注意:这种机制只适用于RFC 3489[21]中定义的经典STUN,RFC 5389引入后,这个机制已经过时.这个机制不是设计用于RFC 5389中定义的STUN.IPv6部署要么不使用NAT,要么以 ...
- GoldenGate安装配置
GOLDENGATE安装 1. 下载与数据库对应版本的goldengate安装介质. 2. 创建goldengate系统用户,设置用户环境变量,如果是oracle,建议直接使用oracle作为用户安装 ...
- Git创建版本库和添加文件
创建版本库: 首先新建一个目录,然后通过 $ git init命令把这个目录变成Git可管理的仓库,例如: 在"C:\AmyPersonal\AmyGit"路径下新建文件夹Git1 ...
- CSAPP阅读笔记-变长栈帧,缓冲区溢出攻击-来自第三章3.10的笔记-P192-P204
一.几个关于指针的小知识点: 1. malloc是在堆上动态分配内存,返回的是void *,使用时会配合显式/隐式类型转换,用完后需要用free手动释放. alloca是标准库函数,可以在栈上分配任 ...