Gradient Optimization
Gradient Optimization
Gradient Descent
- Batch Gradient Descent
- Mini-Batch Gradient Descent
- Stochastic Gradient Descent
Mini-Batch Gradient Descent
- 参数
- Mini-Batch Size: 一个Batch样本所含的样本数
- 参数效果
- 通过设置Mini-Batch Size可以将Mini-Batch转为Stochastic Gradient Descent和Bath Gradient Descent
- 当Mini-Batch Size == m时, Mini-Batch Gradient Descent为Batch Gradient Descent; 当Mini-Batch Size == 1时, Mini-Batch Gradient Descent为Stochastic Gradient Descent; 一般Mini-Batch Size的大小为2的幂次方, 主要考虑到与计算机内存对齐, 一般Mini-Batch Size设置在64-512
- 特点对比
- Batch Gradient Descent: 当数据量大的时候程序运行很慢
- Stochastic Gradient Descent: 一般不采用此方法, 因为此Gradient Descent方法每迭代一个样本就会更新参数\(W\)和\(b\), 在梯度下降的时候有很多噪音; 但是它可以应用到在线学习上
- Mini-Batch Gradient Descent: 当数据量较大的时候可以加快收敛速度, 但是当在梯度下降的时候, 容易产生震荡(oscillate), 如图

- 其中, +表示\(J_{min}\), 在使用Mini-Batch Gradient Descent的时候, 容易在数值方向产生震荡, 我们期望的是缩小竖直方向上的震荡, 在水平方向上加快收敛的速率, 对于这个问题, 解决方案是在Update Parameters的时候, 采用Momentum, RMSProp或者Adam的方法更新参数\(W\)和\(b\), 在下面就会提到
处理震荡
- 指数权重均值(Exponentially Weighted Average, 简称EMA), 后面的Momentum, RMSProp和Adam都需要EMA
- 以一年的中所有天数的温度为例, 如图
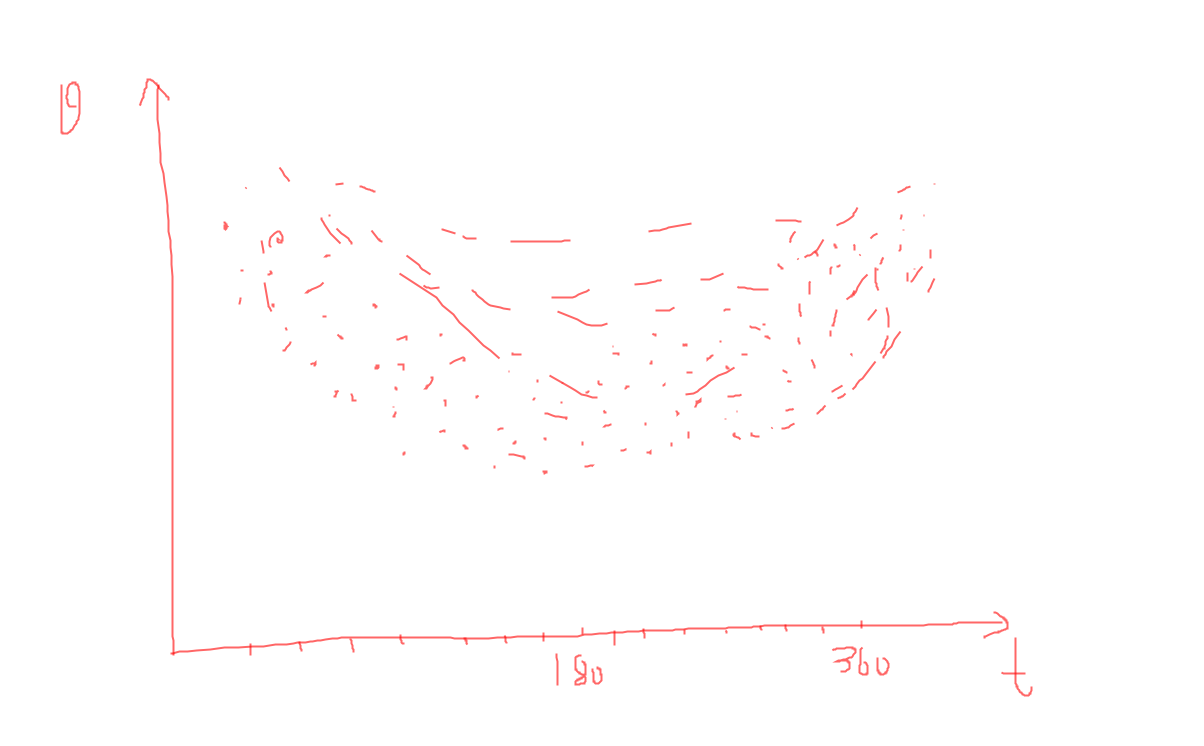
- 由上图可知, \(\theta\)为气温, \(t\)为天数, 总体来说中间时刻气温低一点, 两侧高一点
- 定义
- \(v_t=\beta{v_{t-1}}+(1-\beta)\theta_t\), 其中\(\beta\)为EMA中的一个参数, 一般他的取值范围在\(0.9\le \beta \le 0.99\); \(v_t\)表示的就是EMA; \(\theta_t\)为第\(t\)天的气温; \(\beta{v_t}\)表示的是前\(t\)天的关注度, 后面的\((1-\beta)\theta_t\)是对当前天气温的关注度, 最左侧的\(v_t\)才是我们对当前天的EMA; EMA公式有递归的感觉
Momentum
- 公式
- \(v_{dW^{[l]}}=\beta{v_{dW^{[l]}}}+(1-\beta)dW^{[l]}\), 其中, \(dW^{[l]}\)是第\(l\)层的梯度矩阵, 其他与EMA中的是一样的
- 返现与EMA中不同的是这里的\(\beta{v_{dW^{[l]}}}\)不是\(\beta{v_{dW^{[l-1]}}}\), 因为我们在实现该算法的时候采用先默认赋予0值, 再在每一次迭代时累加, 下面的RMSProp和Adam也是如此
- 更新参数
- \(W^{[l]}=W^{[l]}-\alpha{v_{dW^{[l]}}}\)
- 公式
RMSProp
- 公式
- \(s_{dW^{[l]}}=\beta{v_{dW^{[l]}}}+(1-\beta)(dW^{[l]})^2\), 其中, 与Momentum不同的就是此处\((dW^{[l]})^2\)
- 更新参数
- \(W^{[l]}=W^{[l]}-\alpha{dW^{[l]}\over{\sqrt{s_{dW^{[l]}}+\epsilon}}}\), 其中\(\epsilon \approx 10^{-8}\)
- 公式
Adam
- Adam算法是Momentum与RMSProp的结合
- 公式
- \(v_{dW^{[l]}}=\beta_1{v_{dW^{[l]}}}+(1-\beta_1)dW^{[l]}\)
- \(v^{correct}_{dW^{[l]}}={v_{dW^{[l]}}\over{1-(\beta_1)^t}}\), 其中t表示深度学习算法迭代到第t次, 这一步是\(v_{dW^{[l]}}\)的修正, 在后面即使使用\(v^{correct}_{dW^{[l]}}\)
- \(s_{dW^{[l]}}=\beta_2{v_dW^{[l]}}+(1-\beta_1)(dW^{[l]})^2\)
- \(s^{correct}_{dW^{[l]}}={s_{dW^{[l]}}}\over{1-(\beta_2)^t}\),其中t表示深度学习算法迭代到第t次, 这一步是\(s_{dW^{[l]}}\)的修正, 在后面即使使用\(s^{correct}_{dW^{[l]}}\)
- Adam结合了之前的Momentum与RMSProp算法, 同时增加了校正EMA的步骤, 因为在Momentum和RMSProp算法都有\(\beta\)和\(s\), 所有在这里为了区分, 使用了\(v\)与\(s\), \(\beta_1\)与\(\beta_2\)
- 更新参数
- \(W^{[l]}=W^{[l]}-\alpha{v_{dW^{[l]}}^{[l]}\over{\sqrt{s_{dW^{[l]}}+\epsilon}}}\), 其中\(\epsilon \approx 10^{-8}\)
使用代码实现的大致思路
- 选择Mini-Batch Gradient Descent
- Shuffle原始数据
- 选择Mini-Batch Size进行Gradient Descent
- 在迭代Update Parameters时, 先为Momentum, RMSProp或者Adam需要的\(v\), \(s\)变量赋予0值, 维度与对应的\(dW\)一致
- 迭代即可
学习率\(\alpha\)的衰减
- 一般来说我们只需要直接固定\(\alpha\)的值, 随后根据结果进行调整, 但是在数据量很大的时候就会比较浪费时间, 于是使用到了\(alpha\)的衰减
- 定义
- \(\alpha={1\over{1+decay\_rate\times{epoch}}}\alpha_0\)
Gradient Optimization的更多相关文章
- ( 转) Awesome Image Captioning
Awesome Image Captioning 2018-12-03 19:19:56 From: https://github.com/zhjohnchan/awesome-image-capti ...
- ICCV 2017论文分析(文本分析)标题词频分析 这算不算大数据 第一步:数据清洗(删除作者和无用的页码)
IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017. IEE ...
- 近年Recsys论文
2015年~2017年SIGIR,SIGKDD,ICML三大会议的Recsys论文: [转载请注明出处:https://www.cnblogs.com/shenxiaolin/p/8321722.ht ...
- SciPy和Numpy处理能力
1.SciPy和Numpy的处理能力: numpy的处理能力包括: a powerful N-dimensional array object N维数组: advanced array slicing ...
- [CS231n-CNN] Training Neural Networks Part 1 : activation functions, weight initialization, gradient flow, batch normalization | babysitting the learning process, hyperparameter optimization
课程主页:http://cs231n.stanford.edu/ Introduction to neural networks -Training Neural Network ________ ...
- (转) An overview of gradient descent optimization algorithms
An overview of gradient descent optimization algorithms Table of contents: Gradient descent variants ...
- An overview of gradient descent optimization algorithms
原文地址:An overview of gradient descent optimization algorithms An overview of gradient descent optimiz ...
- 【论文翻译】An overiview of gradient descent optimization algorithms
这篇论文最早是一篇2016年1月16日发表在Sebastian Ruder的博客.本文主要工作是对这篇论文与李宏毅课程相关的核心部分进行翻译. 论文全文翻译: An overview of gradi ...
- [CS231n-CNN] Linear classification II, Higher-level representations, image features, Optimization, stochastic gradient descent
课程主页:http://cs231n.stanford.edu/ loss function: -Multiclass SVM loss: 表示实际应该属于的类别的score.因此,可以发现,如果实际 ...
随机推荐
- Service Worker 缓存文件处理
交代背景 前段时间升级了一波Google Chrome,发现我的JulyNovel站点Ctrl+F5也刷新不了,后来发现是新的Chrome已经支持Service Worker,而我的JulyNovel ...
- Re:从零开始的Spring Security Oauth2(二)
本文开始从源码的层面,讲解一些Spring Security Oauth2的认证流程.本文较长,适合在空余时间段观看.且涉及了较多的源码,非关键性代码以…代替. 准备工作 首先开启debug信息: l ...
- c#实现高斯模糊
说说高斯模糊 高斯模糊的理论我这里就不太多费话了,百度下太多,都是抄来抄去. 主要用到二个函数“高斯函数” 一维形式为: 二维形式为: X,Y对应的一维二维坐标,σ表示模糊半径(半径* 2 + 1) ...
- 基于ZKEACMS的.Net Core多租户CMS建站系统
多租户架构 多租户技术或称多重租赁技术,简称SaaS,是一种软件架构技术,是实现如何在多用户环境下共用相同的系统或程序组件,并且可确保各用户间数据的隔离性.简单讲:在一台服务器上运行单个应用实例,它为 ...
- sqlserver 事务日志已满解决方案
sqlserver 事务日志已满解决方案 可参考这篇博客: https://www.cnblogs.com/strayromeo/p/6961758.html 一.删除日志文件:(不建议) 二.手动收 ...
- HAOI2014 遥感监测
题目链接:戳我 比较水的一个题,直接处理点,找在直线上的可以覆盖到它的区间,然后做最小线段覆盖即可: 代码如下: #include<iostream> #include<cstdio ...
- 二十、Node.js- WEB 服务器 (三)静态文件托管、 路 由
1.Nodejs 静态文件托管 上一讲的静态 web 服务器封装 项目结构: Web服务器封装成的模块:router.js代码: var http=require('http'); var fs=re ...
- WDF(Windows Driver Frameworks)驱动框架源码!!
微软官方提供源码:https://github.com/Microsoft/Windows-Driver-Frameworks
- 深入了解java虚拟机(JVM) 第六章 垃圾回收算法
一.标记清除算法 标记清除算法顾名思义,就是将需要回收的对象进行标记,然后进行清除.那么这个算法就有标记和清除两种过程.标记过程主要是通过可达性分析算法进行判断存活对象,然后遍历所有的对象来找到需要回 ...
- 8、insert、delete、update语句总结
insert常用语句 > insert into tb1 (name,age) values('tom',33); > insert into tb1 (name,age) values( ...