初窥图像识别与k-means算法
前段时间做了一个车型识别的小项目,思路是利用k-means算法以及词袋模型来做的。
近年来图像识别的方法非常非常多,这边只记录一下我那个项目的思路,核心思想是k-means算法和词汇树。
很遗憾没有做详尽的开发前的思路文档,只能按照记忆进行大致总结。
项目分为三大模块:特征点抽取、训练词汇树、识别(利用训练好的词汇树)。
首先是特征点的抽取。我是用的OpenCV的框架来做的特征点抽取。这里提到两种特征点:SURF和SIFT。
关于这两种特征点提取算法,这里做简要介绍(其实我真的不太care,主要是看哪个的特性适合我的项目。单纯为了实现这个东西的话我觉得没必要太深究这个,当然如果你要把这个东西做透了,那肯定得好好研究,毕竟源码来看还是有很多可以优化的东西)。
SIFT特征是图像的局部特征,对平移、旋转、尺度缩放、亮度变化、遮挡和噪声等具有良好的不变性,对视觉变化、仿射变换也保持一定程度的稳定性。SIFT算法时间复杂度的瓶颈在于描述子的建立和匹配 ,如何优化对特征点的描述方法是提升SIFT效率的关键。
SURF算法的优点是速度远快于SIFT且稳定性好;在时间上,SURF运行速度大约为SIFT的3倍;在质量上,SURF的鲁棒性很好,特征点识别率较SIFT高,在视角、光照、尺度变化等情形下,大体上都优于SIFT。
这里要提到的一点就是SURF是64维的特征描述子,而SIFT是128维的特征描述子,简单点数说就是SIFT是X=(x1,x2,x3,...,x128)。而SURF是Y=(y1,y2,y3,...,y64)。从做k-means聚类的角度上来说我果断选择了SURF算法来提取(不过因为用的是OpenCV框架,所以几句代码的事。再提一句,OpenCV框架不止C有,Java也有,喜欢Java不喜欢C/C++的朋友可以尝试,我就是用的java代码)。
简单点说一幅图就是由N多个SURF特征点构成的,有点像像素点。每一个SURF特征点是一个64维的向量Y=(y1,y2,y3,...,y64),就像像素一样,一张图不也是由很多很多个像素点组成的吗,每一个像素点是一个三维向量(x,y,z),其中x,y,z都在0到255之间。
首先是SURF特征点的抽取,我们采用OpenCV框架来抽取每一张图的SURF特征点(当时大约10000张图),将所有图中抽出的SURF特征点都放在一起,形成一个特征点“池塘”,有大概几十亿个特征点。
第二步是词汇树的训练。我们把这个词汇树定义为一个深层次的二叉树,那么这个二叉树如何生成呢,这里首先要提到k-means聚类算法:
k-means聚类算法是一类无监督机器学习的算法。至于什么是机器学习,什么是有监督学习和无监督学习,这里简单介绍,具体可以查百度。
机器学习是一类算法的总称,通俗点来讲就是想让机器通过学习来拥有智慧(拥有决策能力),这和大多数的基本算法其实没啥区别,这里还要提到一点就是基于时代的背景,当下机器学习大势是在统计学习上的,至于什么是统计学习,什么是符号学习,这个是机器学习的一个发展史相关的东西,可以百度。也就是说我们根据现有的一些数据,通过一些手段来分析,能够得到一个决策的方法,来了一个新的数据我就知道该干什么(这跟我们人类的思维过程是一样的,我们也是小的时候学到了很多东西,后来遇到一件新的事情之后呢我们就能根据以往的经验来做出决策)。
有监督学习和无监督学习是机器学习中的两个大类,有监督学习是说我给定的一大堆数据,是人为标注好哪些数据属于哪一类的。而无监督学习是指我事先不加以人工干预,单纯凭借这一大批数据来进行一个分类或者说预测。
k-means算法的大致步骤,这里我用二维坐标系中的点的聚类来形象地表示:
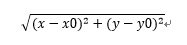
(不好意思自己弄得公示有点丑),(x0,y0)即质心。
从网上贴张图来表示k-means聚类的过程:
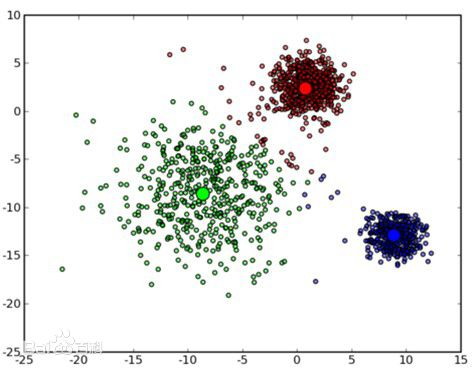
这是一种比较形象的聚类。可以看到图中三类点被聚到了3类中。
那么对于我们项目中的SURF特征点的聚类,实际上和上面提到的二维点聚类是一样的,只不过我们现在是一个64维的坐标系,每一个点是一个64维向量X=(x1,x2,x3,...,x64)
而计算距离就是变成了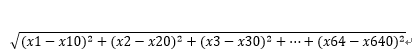 。而质心的坐标就是(x10,x20,x30,...,x640)。
。而质心的坐标就是(x10,x20,x30,...,x640)。
接下来就是建立二叉树的过程了,首先我们有一个根结点。我们对于那么多的特征点利用k-means算法分成两类。那么根结点的左右子树分别是我们分好类的A类和B类。紧接着,对于左右子树,我们分别对A类再分成A1,A2两类作为左子树的左右子树;对B类在分成B1,B2两类作为右子树的左右子树,一直迭代,直到迭代到我们需要的层数。我当时定了32层,于是在叶子节点处就有2^31个叶子节点,即有2^31类。然后对每一个叶子节点给一个符号。现在词汇树就建立完成了。
接下来就是图像识别。
现在我的词汇树已经训练完成,那么我要对我数据库里面的10000张图片做一个调整,毕竟图片是没啥东西可以抽取的,我们要转换成别的形式。于是我们数据库里的每一张图,现在我们来走一遍这个二叉树,就能将一张图片转化为一段文本。具体过程:遍历每一个SURF特征点,然后比较和A1,A2类哪个接近(用欧氏距离),假设离A1近,然后再到A1子树里,比较和A1的左子树,A1的右子树哪个近……就这样一直比较到最终的叶子节点,然后就把这个SURF特征点转化为一个符号(也就是一个文字)。接着我么把所有的数据库中的图片全部转化为文字。
然后我们再进一步转化,可以把一张图转化成一个多维向量!这个利用到文本挖掘里面的一点知识,大家可以自行百度,简单说就是由好多好多文本(每一段文本由不同的符号组成,相当于普通文本,每一段文本由不同的词组成嘛),然后选出一系列具有代表性的词(我们不需要选,因为我们只有2^31个词!那么就能转化成2^31维的向量)。
紧接着我们拍到了一张新的汽车的图片,我们利用相似的过程将一个新的汽车的图片转化成一个2^31维向量,然后根据已有的数据来匹配,最接近哪些车型?这个过程其实有很多办法,这里不详细展开了,最简单的一种办法就是像刚刚一样计算欧氏距离。
那么整个识别过程到这里就介绍完了,当中其实还有很多坑,比如说拍的汽车图片,周围是有很多背景的,在提取SURF特征点过程中,如何防止这些无用的背景的干扰,还有可否拍摄视频来识别?等等有很多问题需要解决,也有很多方法,就不在本文中描述了。
初窥图像识别与k-means算法的更多相关文章
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- js算法初窥05(算法模式02-动态规划与贪心算法)
在前面的文章中(js算法初窥02(排序算法02-归并.快速以及堆排)我们学习了如何用分治法来实现归并排序,那么动态规划跟分治法有点类似,但是分治法是把问题分解成互相独立的子问题,最后组合它们的结果,而 ...
- K-means算法
K-means算法很简单,它属于无监督学习算法中的聚类算法中的一种方法吧,利用欧式距离进行聚合啦. 解决的问题如图所示哈:有一堆没有标签的训练样本,并且它们可以潜在地分为K类,我们怎么把它们划分呢? ...
- 初窥Kaggle竞赛
初窥Kaggle竞赛 原文地址: https://www.dataquest.io/mission/74/getting-started-with-kaggle 1: Kaggle竞赛 我们接下来将要 ...
- iOS视频直播初窥:高仿<喵播APP>
视频直播初窥 视频直播,可以分为 采集,前处理,编码,传输, 服务器处理,解码,渲染 采集: iOS系统因为软硬件种类不多, 硬件适配性比较好, 所以比较简单. 而Android端市面上机型众多, 要 ...
- 初窥Flask
初窥Flask Flask是一个基于Python开发并且依赖jinja2模板和Werkzeug WSGI服务的一个微型框架,对于Werkzeug本质是Socket服务端,其用于接收http请求并对请求 ...
- 初窥css---包含一些概念和一些文字样式
初窥css CSS相关概念 全称是层叠式样式表.规定了html在网页上的显示样式.我们都知道css主要是负责装饰页面的,但是其实在HTML4之前,网页的样式与架构全部都是写在一起的,也是在HTML4之 ...
- 机器学习——KNN算法(k近邻算法)
一 KNN算法 1. KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分 ...
- 初窥ElasticSearch
初窥ElasticSearch 官网上面的,不知道讲的是什么.. youtube上面有一个start with,内容是在windows以下跑这个elastic search,然后用一个fidler工具 ...
随机推荐
- LPCTSTR LPCWSTR LPCSTR 含义
#ifdef UNICODE#define LPCTSTR LPCWSTR#else#define LPCTSTR LPCSTR#endif LPCTSTR A 32-bit pointer ...
- 深入浅出数据结构C语言版(22)——排序决策树与桶式排序
在(17)中我们对排序算法进行了简单的分析,并得出了两个结论: 1.只进行相邻元素交换的排序算法时间复杂度为O(N2) 2.要想时间复杂度低于O(N2),算法必须进行远距离的元素交换 而今天,我们将对 ...
- 我的第一篇blog—— 一起来赛马呀
作为一名大三的学生现在开始学习acm,或许太晚.感叹时光蹉跎....我的blog将以讲解的形式的发布,以专题的形式的形式介绍一些基本的知识和经典的题目.虽然感觉自己所剩时间无多,但也希望起到前人种 ...
- 【JAVA零基础入门系列】Day5 Java中的运算符
运算符,顾名思义就是用于运算的符号,比如最简单的+-*/,这些运算符可以用来进行数学运算,举个最简单的栗子: 已知长方形的长为3cm,高为4cm,求长方形的面积. 好,我们先新建一个项目,命名为Rec ...
- PHP合并两张图片(水印)
$dst_im = "http://img6.cache.netease.com/photo/0001/2016-04-15/BKMTUO8900AP0001.jpg"; $src ...
- Node.js之循环依赖
在Node.js中有可能会出现循环依赖的问题,在此做一个简单的记录 假如有一个模块A: exports.loaded = false; const b = require('./b'); module ...
- Android使用RxJava+Retrofit2+Okhttp+MVP练习的APP
Android使用RxJava+Retrofit2+Okhttp+MVP练习的APP 项目截图 这是我的目录结构 五步使用RxJava+Retrofit2+Okhttp+RxCache 第一步 ...
- Django安装Xadmin步骤
在Django中安装Xadmin替换原始的admin,下面介绍两种方法安装 第一种方法:pip安装 第一步: 直接pip安装xadmin pip install xadmin pip会同时安装上面三个 ...
- 为啥REST如此重要?
摘要:REST——表征状态转移,由于REST模式的Web服务更加简洁,越来越多的Web服务开始采用REST风格设计和实现.例如,Amazon.com提供接近REST风格的Web服务进行图书查找:雅虎提 ...
- NDK Jni 开发(1)
1. 学习地址 http://my.oschina.net/lifj/blog/177087 http://www.cnblogs.com/devinzhang/archive/2012/02/29/ ...