Java的HashMap实现原理整理总结
通过Debug 探寻Java-HashMap 实现原理:
一个简单的例子,代码如下,
测试方法 main:
public static void main(String[] args) {
KeyObj obj1 = new KeyObj("AAAA");
KeyObj obj2 = new KeyObj("BBBB");
KeyObj obj3 = new KeyObj("CCCCC");
KeyObj obj4 = new KeyObj("DDDDD");
HashMap<KeyObj, String> hashMap = new HashMap<KeyObj, String>();
hashMap.put(obj1, "aaaa");
hashMap.put(obj2, "bbbb");
hashMap.put(obj3, "ccccc");
hashMap.put(obj4, "ddddd");
System.out.println(hashMap.values());
}
KeyObj.java
public class KeyObj {
String keyStr;
public KeyObj(String keyStr) {
super();
this.keyStr = keyStr;
}
public String getKeyStr() {
return keyStr;
}
public void setKeyStr(String keyStr) {
this.keyStr = keyStr;
}
@Override
// 覆盖hashCode方法,使得key的单双数分别获得一致的hash值,方便测试
public int hashCode() {
if (keyStr.length() % 2 == 0) {
return 31;
}
return 95;
}
@Override
public boolean equals(Object obj) {
KeyObj obj1 = (KeyObj) obj;
if (this.keyStr.equalsIgnoreCase(obj1.keyStr))
return true;
return false;
}
}
运行测试方法main,Debug查看HashMap:
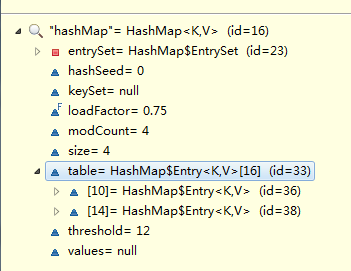
1.可以看到HashMap其实是有一个名称为table的Entry数组,我们使用HashMap的put方法,本质是把我们的Key-Value作为Entry对象放入到HashMap中。
2.HashMap的table数组初始大小为16.
3.为何我们put了4个对象却只使用了table[10] 与 table[14]?
查看put方法JDK代码:
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold); // 3.1 table若为空创建table,16大小
}
if (key == null)
return putForNullKey(value); // 3.2 key若为空放入table[0]
int hash = hash(key); // 3.3 计算放入key的hash,值为调用KeyObj的hashcode方法,再hash
int i = indexFor(hash, table.length);
// 3.4 计算当前put的Enrty在table数组中精确位置(int i),跟踪代码可以很容易看出:
// 3.4.1 精确位置i是由key的hash值与table.length取模
for (Entry<K,V> e = table[i]; e != null; e = e.next) { // 3.5 遍历table[i]的Entry
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { // 3.6 若put相同key的KeyObj,则替换旧值
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);// 3.7 创建Entry,当前table[i]的首节点变为当前put节点Entry对象的next节点,注:JDK8之前每一个table[i]上的Entry使用单链表存储的
return null;
}
理解了put,查看HashMap的get方法就很简单了:
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
继续查看第四行getEntry方法:
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)]; // 找到table[i],并便利该位置节点
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) // 找到,返回
return e;
}
return null;
}
其他:
在put函数代码中有一个注释:
JDK8之前每一个table[i]上的Entry使用单链表存储的
一直到JDK7为止,HashMap的结构都是这么简单,基于一个数组以及多个链表的实现,hash值冲突的时候,就将对应节点以链表的形式存储。
这样子的HashMap性能上就抱有一定疑问,如果说成百上千个节点在hash时发生碰撞,存储一个链表中,那么如果要查找其中一个节点,那就不可避免的花费O(N)的查找时间,这将是多么大的性能损失。这个问题终于在JDK8中得到了解决。再最坏的情况下,链表查找的时间复杂度为O(n),而红黑树一直是O(logn),这样会提高HashMap的效率。
所以在JDK8中,当同一个hash值的节点数不小于8时,将不再以单链表的形式存储了,会被调整成一颗红黑树。
Java的HashMap实现原理整理总结的更多相关文章
- 【JAVA】HashMap的原理及多线程下死循环的原因
再次翻到以前工作中遇到的一个问题,HashMap在多线程下会出现死循环的问题,以前只是知道会死循环,导致CPU100%把机器拖跨,今天来彻底看看 首先来看下,HashMap的原理:HashMap是一个 ...
- Java面试& HashMap实现原理分析
1. HashMap的数据结构 数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端. 数组 数组存储区间是连续的,占用内存严重,故空间复杂的很大.但数组的二分查找时间复杂度小,为O( ...
- 详解 Java 8 HashMap 实现原理
HashMap 是 Java 开发过程中常用的工具类之一,也是面试过程中常问的内容,此篇文件通过作者自己的理解和网上众多资料对其进行一个解析.作者本地的 JDK 版本为 64 位的 1.8.0_171 ...
- 1.Java集合-HashMap实现原理及源码分析
哈希表(Hash Table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常 ...
- 【Java】HashMap实现原理---数据结构
作为一个程序猿,特别是Java后端的,应该全部人都用过HashMap,也都知道HaspMap是一个用于存储Key-Value键值对的集合.与此同时我们把每一个键值对也叫做 Entry. 而这些Entr ...
- Java中HashMap实现原理
类声明: 概述: 线程不安全: <Key, Value>两者都可以为null: 不保证映射的顺序,特别是它不保证该顺序恒久不变: HashMap使用Iterator: HashMap中ha ...
- Java中HashMap的实现原理
最近面试中被问及Java中HashMap的原理,瞬间无言以对,因此痛定思痛觉得研究一番. 一.Java中的hashCode和equals 1.关于hashCode hashCode的存在主要是用于查找 ...
- HashMap的原理与实 无锁队列的实现Java HashMap的死循环 red black tree
http://www.cnblogs.com/fornever/archive/2011/12/02/2270692.html https://zh.wikipedia.org/wiki/%E7%BA ...
- java 关于 hashmap 的实现原理的测试
网上关于HashMap的工作原理的文章多了去了,所以我也不打算再重复别人的文章.我就是有点好奇,我怎么样能更好的理解他的原理,或者说使用他的特性呢?最好的开发就是测试~ 虽说不详讲hashmap的工作 ...
随机推荐
- org.apache.hadoop.security.AccessControlException: Permission denied: user=?, access=WRITE, inode="/":hadoop:supergroup:drwxr-xr-x 异常解决
进行如下更改:vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml[我的hadoop目录在/usr/local下,具体的是修改你的hadoop目录中的/etc/ ...
- springboot用thymeleaf模板的paginate分页
本文根据一个简单的user表为例,展示 springboot集成mybatis,再到前端分页完整代码(新手自学,不足之处欢迎纠正): 先看java部分 pom.xml 加入 <!--支持 Web ...
- 初学Python(五)——元组
初学Python(五)——元组 初学Python,主要整理一些学习到的知识点,这次是元组. #-*- coding:utf-8 -*- #定义元素 t = (1,2,3) #添加元素 #删除元素 #更 ...
- kafka生产实践
最近接触到一个APP流量分析的项目,类似于友盟.涉及到几个C端高并发的接口,这几个接口主要用于C端数据的提交.在没有任何缓冲的情况下,一个接口涉及到5张表的提交.压测的结果很不理想,主要瓶颈就在与RD ...
- 6步就能搞出个react网站哈,玩一把!
1.安装mk-tools命令行工具 $ npm i -g mk-tools 2.创建空website $ mk website myDemo $ cd myDemo 3.clone应 ...
- 数据结构随笔-php实现栈
栈(Stack)满足后进先出(LIFO)的原则: 下面利用php实现栈的相关操作: 本实例栈的基本操作: 入栈(push):向栈内压入一个元素,栈顶指针指向栈顶元素 出栈(pop): 从栈顶去除元素, ...
- nginx实现wap移动端和PC端业务分离
随着移动互联网时代的来临,很多WEB网站都已经推出了基于手机,Ipad等移动客户端的页面访问,这里介绍一下如何利用用户UA实现用户不同终端下的用户访问: $http_user_agent 为ngin ...
- [js高手之路]es6系列教程 - 解构详解
解构通俗点说,就是通过一种特定格式,快捷的读取对象/数组中的数据的方法, es6之前,我们通过对象名称[键] 读取数据 var User = { 'name' : 'ghostwu', 'age' : ...
- Oracle数据库常用关键字以及函数
常用关键字 insert into---插入数据 delete---删除数据 update---更新一条数据 select---实际工作中尽量不要写* set---设置某些属性 where---给执行 ...
- 【NO.10】Jmeter - 一个完整的录制脚本的过程
上1篇介绍了"使用Jmeter对一个接口地址或者一个页面地址执行N次请求",也就是你自己干了一件从"零"开始的事情. 那么这1篇介绍"如何使用Jmeter录制'访问一个接口地址或者一个页面地址'的脚本 ...