python爬取大众点评并写入mongodb数据库和redis数据库
抓取大众点评首页左侧信息,如图:
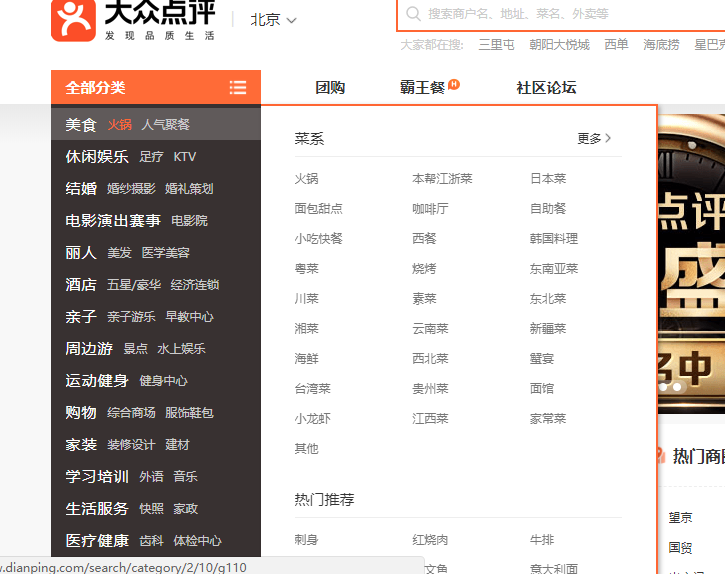
我们要实现把中文名字都存到mongodb,而每个链接存入redis数据库。
因为将数据存到mongodb时每一个信息都会有一个对应的id,那样就方便我们存入redis可以不出错。
# -*- coding: utf-8 -*-
import re
from urllib.request import urlopen
from urllib.request import Request
from bs4 import BeautifulSoup
from lxml import etree
import pymongo client = pymongo.MongoClient(host="127.0.0.1")
db = client.dianping #库名dianping
collection = db.classification #表名classification import redis #导入redis数据库
r = redis.Redis(host='127.0.0.1', port=6379, db=0) # client = pymongo.MongoClient(host="192.168.60.112")
# myip = client['myip'] # 给数据库命名
def secClassFind(selector, classid):
secItems = selector.xpath('//div[@class="sec-items"]/a')
for secItem in secItems:
url = secItem.get('href') #得到url
title = secItem.text
classid = collection.insert({'classname': title, 'pid': classid})
classurl = '%s,%s' % (classid, url) #拼串
r.lpush('classurl', classurl) #入库 def Public(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'} #协议头
req_timeout = 5
req = Request(url=url, headers=headers)
f = urlopen(req, None, req_timeout)
s = f.read()
s = s.decode("utf-8")
# beautifulsoup提取
soup = BeautifulSoup(s, 'html.parser')
links = soup.find_all(name='li', class_="first-item")
for link in links:
selector = etree.HTML(str(link))
# indexTitleUrls = selector.xpath('//a[@class="index-title"]/@href')
# # 获取一级类别url和title
# for titleurl in indexTitleUrls:
# print(titleurl)
indexTitles = selector.xpath('//a[@class="index-title"]/text()')
for title in indexTitles:
# 第二级url
print(title)
classid = collection.insert({'classname': title, 'pid': None})
secClassFind(selector, classid)
print('---------')
# secItems = selector.xpath('//div[@class="sec-items"]/a')
# for secItem in secItems:
# print(secItem.get('href'))
# print(secItem.text)
print('-----------------------------')
#
# myip.collection.insert({'name':secItem.text})
# r.lpush('mylist', secItem.get('href')) # collection.find_one({'_id': ObjectId('5a14c8916d123842bcea5835')}) # connection = pymongo.MongoClient(host="192.168.60.112") # 连接MongDB数据库 # post_info = connection.myip # 指定数据库名称(yande_test),没有则创建
# post_sub = post_info.test # 获取集合名:test
Public('http://www.dianping.com/')
python爬取大众点评并写入mongodb数据库和redis数据库的更多相关文章
- python爬取大众点评
拖了好久的代码 1.首先进入页面确定自己要抓取的数据(我们要抓取的是左侧分类栏-----包括美食.火锅)先爬取第一级分类(美食.婚纱摄影.电影),之后根据第一级链接爬取第二层(火锅).要注意第二级的p ...
- Python 爬取大众点评 50 页数据,最好吃的成都火锅竟是它!
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 胡萝卜酱 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- 用Python爬取大众点评数据,推荐火锅店里最受欢迎的食品
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:有趣的Python PS:如有需要Python学习资料的小伙伴可以加点 ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- python爬虫爬取大众点评并导入redis
直接上代码,导入redis的中文编码没有解决,日后解决了会第一时间上代码!新手上路,多多包涵! # -*- coding: utf-8 -*- import re import requests fr ...
- python 爬取段子网段子写入文件
import requests import re 进入网址 for i in range(1,5): page_url = requests.get(f"http://duanziwang ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- Python爬取豆瓣音乐存储MongoDB数据库(Python爬虫实战1)
1. 爬虫设计的技术 1)数据获取,通过http获取网站的数据,如urllib,urllib2,requests等模块: 2)数据提取,将web站点所获取的数据进行处理,获取所需要的数据,常使用的技 ...
- Python:将爬取的网页数据写入Excel文件中
Python:将爬取的网页数据写入Excel文件中 通过网络爬虫爬取信息后,我们一般是将内容存入txt文件或者数据库中,也可以写入Excel文件中,这里介绍关于使用Excel文件保存爬取到的网页数据的 ...
随机推荐
- caioj 1236 最近公共祖先 树倍增算法模版 倍增
[题目链接:http://caioj.cn/problem.php?id=1236][40eebe4d] 代码:(时间复杂度:nlogn) #include <iostream> #inc ...
- 【liferay】1、使用alloy-UI发送ajax请求
1.首先liferay要发送ajax请求,那么就需要在jsp中定义resourceURL <portlet:resourceURL var="workDeal" id=&qu ...
- python爬虫(二)_HTTP的请求和响应
HTTP和HTTPS HTTP(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收HTML页面的方法 HTTPS(HyperText Transfer Prot ...
- 机器学习实践之K-近邻算法实践学习
关于本文说明,本人原博客地址位于http://blog.csdn.net/qq_37608890,本文来自笔者于2017年12月04日 22:54:26所撰写内容(http://blog.csdn.n ...
- android boot.img
android在启动时uboot推断有没有组合健按下或者cache分区的升级文件来决定进入哪个系统(可能还有别的推断方式) 有组合健按下或者cache分区有升级文件,则载入recovery.img进入 ...
- POJ-1250
#include<iostream> #include<string> #include<list> #include<algorithm> using ...
- POJ3621 Sightseeing Cows(最优比率环)
题目链接:id=3621">http://poj.org/problem?id=3621 在一个有向图中选一个环,使得环上的点权和除以边权和最大.求这个比值. 经典的分数规划问题,我认 ...
- Caused by: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Query was empty
1 错误描写叙述 at org.springframework.web.method.support.InvocableHandlerMethod.invokeForRequest(Invocable ...
- 入门Webpack
---恢复内容开始--- 什么是WebPack,为什么要使用它? 为什要使用WebPack 现今的很多网页其实可以看做是功能丰富的应用,它们拥有着复杂的JavaScript代码和一大堆依赖包.为了简化 ...
- 【quickhybrid】API多平台支撑的实现
前言 在框架规划时,就有提到过这个框架的一些常用功能需要支持H5环境下的调用,也就是需要实现API的多平台支撑 为什么要多平台支撑?核心仍然是复用代码,比如在微信下,在钉钉下,在quick容器下, 如 ...