最近在学习Oracle的统计信息这一块,收集统计信息的方法如下:
DBMS_STATS.GATHER_TABLE_STATS (
ownname VARCHAR2, ---所有者名字
tabname VARCHAR2, ---表名
partname VARCHAR2 DEFAULT NULL, ---要分析的分区名
estimate_percent NUMBER DEFAULT NULL, ---采样的比例
block_sample BOOLEAN DEFAULT FALSE, ---是否块分析
method_opt VARCHAR2 DEFAULT ‘FOR ALL COLUMNS SIZE 1’,---分析的方式
degree NUMBER DEFAULT NULL, ---分析的并行度
granularity VARCHAR2 DEFAULT ‘DEFAULT’, ---分析的粒度
cascade BOOLEAN DEFAULT FALSE, ---是否分析索引
stattab VARCHAR2 DEFAULT NULL, ---使用的性能表名
statid VARCHAR2 DEFAULT NULL, ---性能表标识
statown VARCHAR2 DEFAULT NULL, ---性能表所有者
no_invalidate BOOLEAN DEFAULT FALSE, ---是否验证游标依存关系
force BOOLEAN DEFAULT FALSE); ---强制分析,即使锁表
本文主要对参数granularity进行了一下验证,
granularity:数据分析的力度
--global ---全局
--partition ---只在分区级别做分析
--subpartition --只在子分区级别做分析
验证步骤如下:
一、创建一个分区表并插入两条数据,同时在字段ID上创建索引
drop table test purge;
create table test(id number) partition by range(id)
(partition p1 values less than (5),
partition p2 values less than (10)
) ;
insert into test values(1);
insert into test values(6);
commit;
create index ind_id on test(id);
二、收集表的统计信息
exec dbms_stats.gather_table_stats(user,'TEST',cascade=>true);
三、查询表的统计信息
select num_rows,blocks,last_analyzed from user_tables where table_name = 'TEST';
结果如下:

num_rows:表数据行数
blocks:数据块数
last_analyzed:最近分析时间
四、查询表分区信息
select partition_name,num_rows,blocks,last_analyzed from dba_tab_partitions where table_name ='TEST';

PARTITION_NAME:分区名称
NUM_ROWS:数据行数
BLOCKS:数据块数
last_analyzed:最近分析时间
五、查询索引统计信息
select num_rows,blevel,last_analyzed from user_indexes where index_name = 'IND_ID';

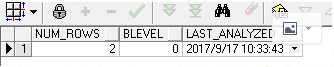
num_rows:索引数据行数
blevel:索引高度
last_analyzed:分析时间
六、新增一个分区
alter table test add partition pmax values less than(maxvalue);
七、往新的分区中插入10000条数据
begin for i in 1..10000 loop ---插入10000条数据
insert into test values(100);
end loop;
commit;
end;
八、创建一个倾斜度非常大的分区
update test set id=10000 where id=100 and rownum=1; ---创造一个非常倾斜的Pmax分区
Commit;
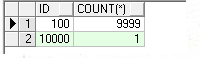
九、查询分区数据
select id,count(*) from test partition(pmax) group by id;
十、不做分析,再次查询表的统计信息
select num_rows,blocks,last_analyzed from user_tables where table_name = 'TEST';
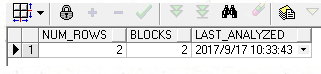
发现数据行数量和数据块数量没有发现变化
十一、查询id=100时执行计划
set autotrace traceonly
set linesize 1000
select * from test where id=100;
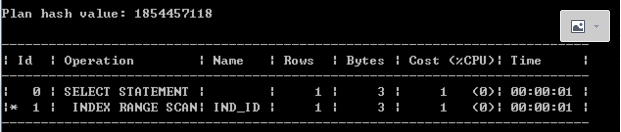
发现走了索引,正常情况下,因为id=100的数据在一个倾斜度非常高的分区pmax中,id为100的数据有9999条,走索引的代价会比走全表的代价还要高(因为走索引需要回表),如果统计信息正确,优化器应该会选择走全表,但是这里没走全表而是走了索引,这里怀疑是统计信息不正确导致,后面验证
十二、收集分区统计信息
exec dbms_stats.gather_table_stats(user,'TEST',partname => 'PMAX',granularity => 'PARTITION');
十三、再次查询表的统计信息和分区统计信息
select partition_name,num_rows,blocks,last_analyzed from dba_tab_partitions where table_name ='TEST';

发现和步骤四比较,分区信息有了变化,说明对分区进行统计信息收集后,分区信息进行了更新
select num_rows,blocks,last_analyzed from user_tables where table_name = 'TEST';

发现和步骤三想比,表的统计信息并没有发生变化,说明统计了分区信息后,表的统计信息么有更新
十四、再次查询id=100的数据

仍然走索引,说明在评估查询的时候,表的统计信息依然陈旧
十五、查询索引的统计信息
select num_rows,blevel,last_analyzed from user_indexes where index_name = 'IND_ID';

发现索引统计信息较步骤五没有变化,说明收集了分区的统计信息后,表的索引信息没有更新
十六、重新再次收集表的统计信息
exec dbms_stats.gather_table_stats(user,'TEST',cascade =>true);
十七、查询表的统计信息以及索引的统计信息
select num_rows,blocks,last_analyzed from user_tables where table_name = 'TEST';

表的统计信息已经更新
select num_rows,blevel,last_analyzed from user_indexes where index_name = 'IND_ID';

索引的统计信息也已经更新
十八、再次查询id=100的执行计划

这次发现走了全表,说明收集了全局的统计信息后,表的统计信息准确了,评估也就准确了。
- Oracle 分区表 收集统计信息 参数granularity
GRANULARITY Determines the granularity of statistics to collect. This value is only relevant for par ...
- ORACLE收集统计信息
1. 理解什么是统计信息 优化器统计信息就是一个更加详细描述数据库和数据库对象的集合,这些统计信息被用于查询优化器,让其为每条SQL语句选择最佳的执行计划.优化器统计信息包括: · ...
- ORACLE 收集统计信息
1. 理解什么是统计信息优化器统计信息就是一个更加详细描述数据库和数据库对象的集合,这些统计信息被用于查询优化器,让其为每条SQL语句选择最佳的执行计划.优化器统计信息包括: · ...
- Oracle收集统计信息的一些思考
一.问题 Oracle在收集统计信息时默认的采样比例是DBMS_STATS.AUTO_SAMPLE_SIZE,那么AUTO_SAMPLE_SIZE的值具体是多少? 假设采样比例为10%,那么在计算单个 ...
- Oracle 收集统计信息11g和12C在差异
Oracle 基于事务临时表11g和12C下,能看到临时表后收集的统计数据,前者记录被清除,后者没有,这是一个很重要的不同. 关于使用企业环境12C,11g,使用暂时表会造成时快时慢.之前我有帖子ht ...
- Oracle重建表索引及手工收集统计信息
Oracle重建所有表的索引的sql: SELECT 'alter index ' || INDEX_NAME || ' rebuild online nologging;' FROM USER_IN ...
- Oracle 手动收集统计信息
收集oracle统计信息 优化器统计范围: 表统计: --行数,块数,行平均长度:all_tables:NUM_ROWS,BLOCKS,AVG_ROW_LEN: 列统计: --列中唯一值的数量(NDV ...
- Oracle 判断 并 手动收集 统计信息 脚本
CREATE OR REPLACE PROCEDURE SchameB.PRC_GATHER_STATS AUTHID CURRENT_USER IS BEGIN SYS.DBMS_STATS.GAT ...
- oracle的统计信息的查看与收集
查看某个表的统计信息 SQL> alter session set NLS_DATE_FORMAT='YYYY-MM-DD HH24:MI:SS'; Session altered. SQL&g ...
随机推荐
- Javascript闭包与作用域this
闭包与this的一般用法 关于js函数与闭包的文章想必大家都是在熟悉不过的了,作为js核心亦即最强大的功能之一,每次回过头翻出来看一看,都会有不一样的收获与理解,经典的含义无非如此而已. 1.闭包 1 ...
- C#线程(二)
.cnblogs_code { background-color: #f5f5f5; font-family: Courier New !important; font-size: 12px !imp ...
- PhantomJS 与python的结合
待完善 一.简介 PhantomJS是一个基于webkit的JavaScript API.它使用QtWebKit作为它核心浏览器的功能,使用webkit来编译解释执行JavaScript代码.任何你可 ...
- mysql 中的socket 即 mysql.sock的作用
这个mysql.sock应该是mysql的主机和客户机在同一host上的时候,使用unix domain socket做为通讯协议的载体,它比tcp快.通常遇到这个问题的原因就是你的mysql ser ...
- RMAN基础恢复测试
--RMAN恢复测试实战 RMAN> list backup; using target database control file instead of recovery catalo ...
- 创建第一个简单的AI分类器
from sklearn import tree# 第一个简单的分类器features = [[140, 1], [130, 1], [150, 0], [170, 0]] #列表左边的变量代表水果的 ...
- SQL视图&触发器
SQL视图 在 SQL 中,视图是基于 SQL 语句的结果集的可视化的表. 视图包含行和列,就像一个真实的表.视图中的字段就是来自一个或多个数据库中的真实的表中的字段.我们可以向视图添加 SQL 函数 ...
- Linux命令的学习
mkdir -p 创建目录 (make directorys) p递归创建 ls -l(long)d(direcitory)显示目录或者文件 cd 切换目录 从"/"开始目录,/ ...
- css文本样式及控制文本的大小写
常用文本样式如下: <!DOCTYPE html> <html lang="en"> <head> <meta charset=" ...
- 遇到local variable 'e' referenced before assignment这样的问题应该如何解决
问题:程序报错:local variable 'e' referenced before assignment 解决:遇到这样的问题,说明你在声明变量e之前就已经对其进行了调用,定位到错误的地方,对变 ...