Python3分析sitemap.xml抓取导出全站链接
最近网站从HTTPS转为HTTP,更换了网址,旧网址做了301重定向,折腾有点大,于是在百度站长平台提交网址,不管是主动推送还是手动提交,前提都是要整理网站的链接,手动添加太麻烦,效率低,于是就想写个脚本直接抓取全站链接并导出,本文就和大家一起分享如何使用python3实现抓取链接导出。
首先网站要有网站地图sitemap.xml文件地址,其次我这里用的是python3版本,如果你的环境是python2,需要对代码进行调整,因为python2和python3很多地方差别还是挺大的。
下面是python 3代码,将里面的链接地址换成你自己的网址即可:
#coding=utf-8
import urllib
import urllib.request import re
url='http://www.ranzhi.org/sitemap.xml'
html=urllib.request.urlopen(url).read()
html=html.decode('utf-8')
r=re.compile(r'(http://www.ranzhi.org.*?\.html)')
big=re.findall(r,html)
for i in big:
print(i)
op_xml_txt=open('xml.txt','a')
op_xml_txt.write('%s\n'%i)
我们能来看一下运行结果:
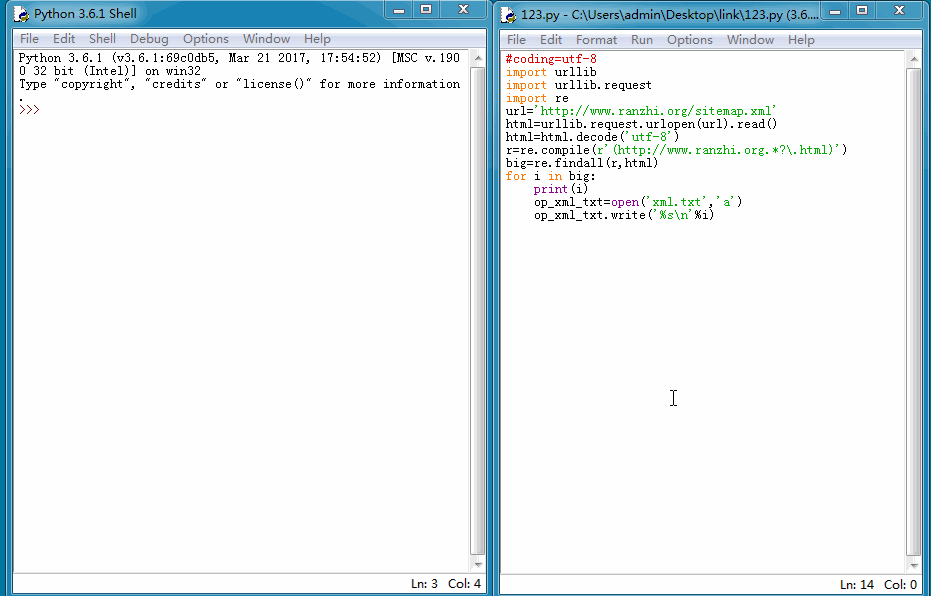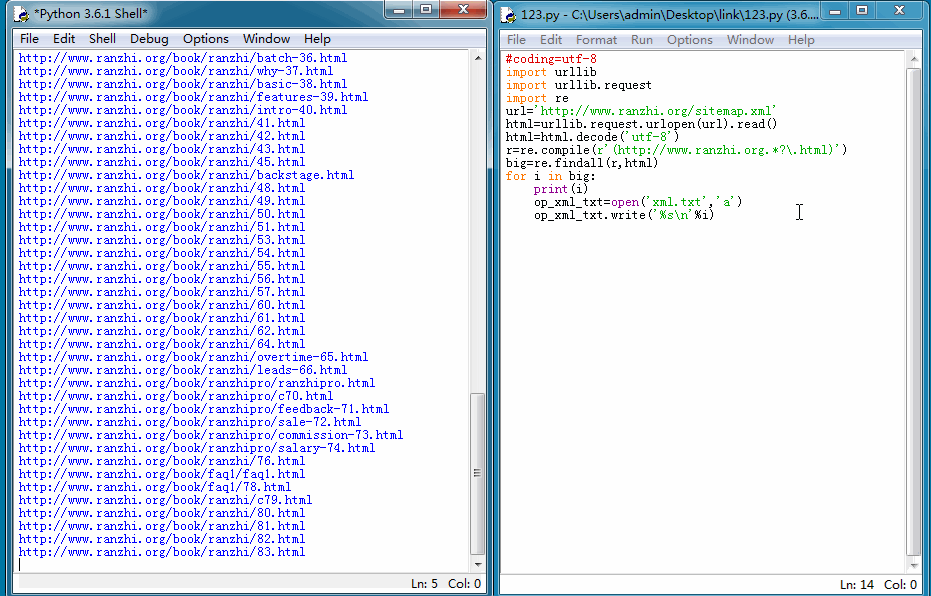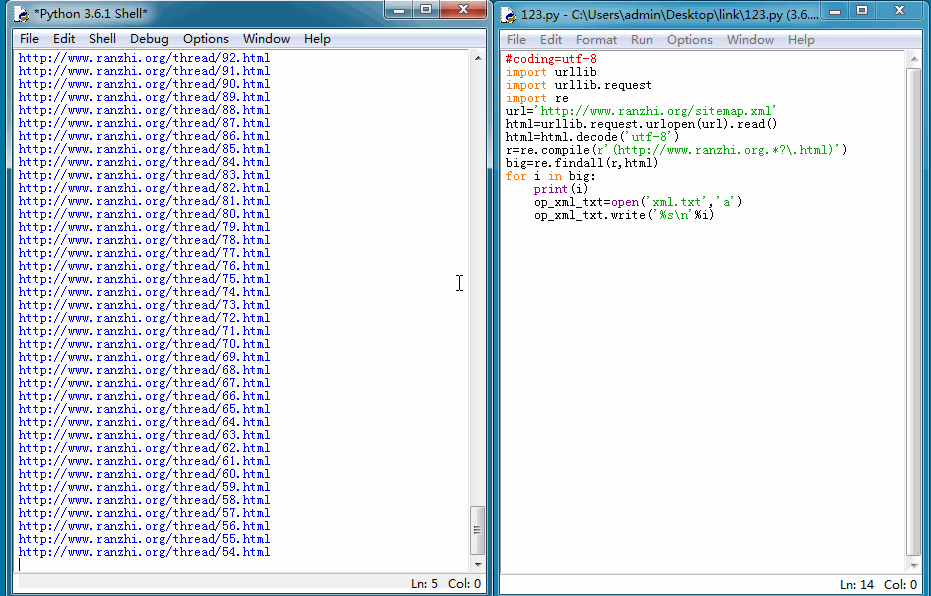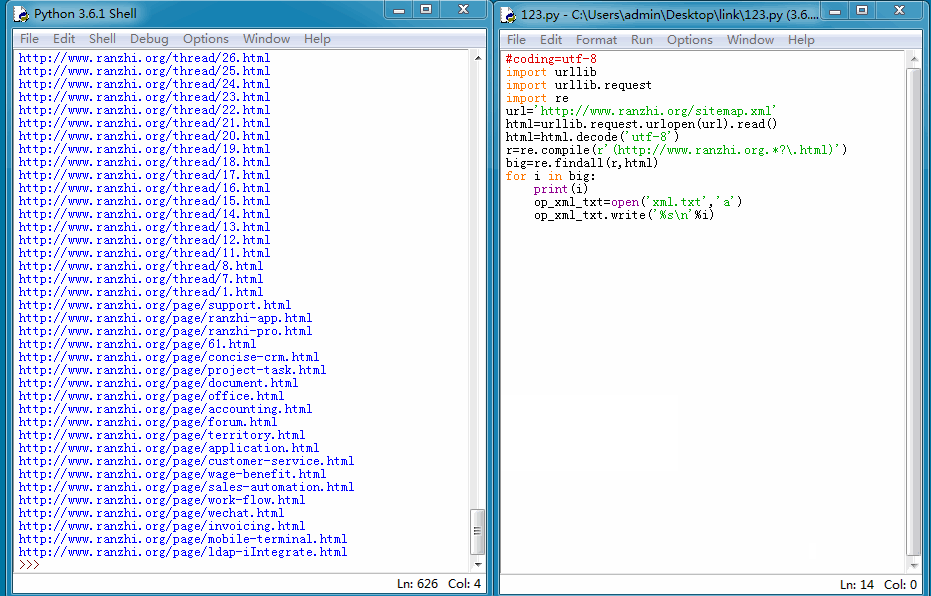
导出TXT格式文件后,再在百度站长平台手动提交就方便的多了。当然我们也可以使用更快的主动推送方式,因为我的然之网站是用PHP+mysql开发的,所以我们这里使用PHP脚本将上面抓取的链接再处理下,然后主动推送给百度,一遍加快爬虫抓取时间。
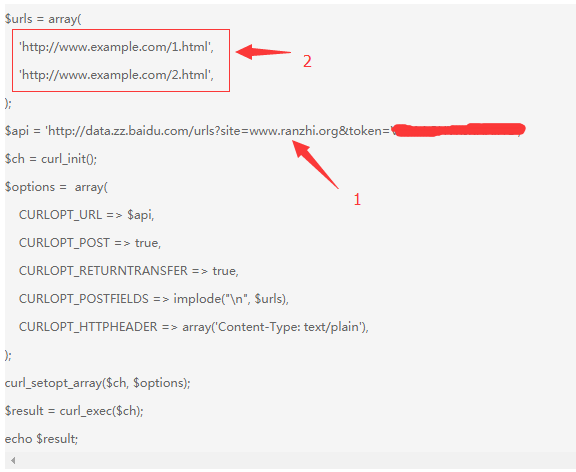
上面1是你的站点的主动推送API,这个可以在百度站长平台获取;2是要主动推送的网站地址,这里就可以用到我们上面抓取的全站链接了。将链接地址整理放到该数组中,运行一下个这个PHP脚本,就可以了。一键提交,及高效便捷,又能缩短爬虫爬去时间,有助于网站页面收录。
我们在平时的SEO或服务器运维工作中,时常会将重复工作自动化,复杂工作间变化,有助于提升效率,如果大家在操作过充中有何问题可以一起分享交流讨论。

Python3分析sitemap.xml抓取导出全站链接的更多相关文章
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- python爬虫---实现项目(二) 分析Ajax请求抓取数据
这次我们来继续深入爬虫数据,有些网页通过请求的html代码不能直接拿到数据,我们所需的数据是通过ajax渲染到页面上去的,这次我们来看看如何分析ajax 我们这次所使用的网络库还是上一节的Reques ...
- python3 - 通过BeautifulSoup 4抓取百度百科人物相关链接
导入需要的模块 需要安装BeautifulSoup from urllib.request import urlopen, HTTPError, URLError from bs4 import Be ...
- 控制台js常用解决方案,字符串替换和抓取列表页链接
抓取列表页链接 由于测试站没有jquery所以,我用了原生的js var obj = document.getElementsByClassName('class1'); for(let i = 0; ...
- Python3利用BeautifulSoup4批量抓取站点图片的代码
边学边写代码,记录下来.这段代码用于批量抓取主站下所有子网页中符合特定尺寸要求的的图片文件,支持中断. 原理很简单:使用BeautifulSoup4分析网页,获取网页<a/>和<im ...
- 我也来学着写写WINDOWS服务-解析xml抓取数据并插入数据库
项目告一段落,快到一年时间开发了两个系统,一个客户已经在试用,一个进入客户测试阶段,中间突然被项目经理(更喜欢叫他W工)分派一个每隔两小时用windows服务去抓取客户提供的外网xml,解析该xml, ...
- 分析ajax请求抓取今日头条关键字美图
# 目标:抓取今日头条关键字美图 # 思路: # 一.分析目标站点 # 二.构造ajax请求,用requests请求到索引页的内容,正则+BeautifulSoup得到索引url # 三.对索引url ...
- Python3的requests类抓取中文页面出现乱码的解决办法
这种乱码现象基本上都是编码造成的,我们要转到我们想要的编码,先po一个知识点,嵩天老师在Python网络爬虫与信息提取说到过的:response.encoding是指从HTTP的header中猜测 ...
- python学习(26)分析ajax请求抓取今日头条cosplay小姐姐图片
分析ajax请求格式,模拟发送http请求,从而获取网页代码,进而分析取出需要的数据和图片.这里分析ajax请求,获取cosplay美女图片. 登陆今日头条,点击搜索,输入cosplay 下面查看浏览 ...
随机推荐
- SQLite 之 C#版 System.Data.SQLite 使用
简介 SQLite简介 SQLite,是一款轻型的关系型数据库.它的设计目标是嵌入式. 它能够支持Windows/Linux/Unix等等主流的操作系统,同时能够跟很多程序语言相结合,比如 C++.C ...
- STM32采集电阻触摸贴膜
今天为了解决一个测量电阻屏压力的问题,自己直接用STM32做了一个测量电阻屏的程序(直接把触摸屏的四根线接到单片机引脚上),通过AD切换采集,采集X轴电压,Y轴电压,和压力..最后附上自己的程序 先说 ...
- centos永久修改主机名
永久修改主机名 以上的修改只是临时修改,重启后就恢复原样了. 步骤1: 修改/etc/sysconfig/network中的hostname vi /etc/sysconfig/network HOS ...
- bitnami gitlab 配置域名
正常安装完成以后gitlab的代码仓库域名的地址依然是IP,这样不便于我们记忆,所以我想给gitlab增加一个域名 找到gitlab.yml 配置文件,在gitlab 节点下的host 由IP变更为域 ...
- CMD和seaJS
前面的话 CMD(Common Module Definition)表示通用模块定义,该规范是国内发展出来的,由阿里的玉伯提出.就像AMD有个requireJS,CMD有个浏览器的实现SeaJS,Se ...
- hello Kotlin!
听说谷爹要把Kotlin作为了Android开发的一级语言,吓得我赶紧写个“Hello Kotlin!”压压惊! Kotlin是由JetBrains 公司开发的语言,并且已经开源.而JetBrains ...
- (中级篇 NettyNIO编解码开发)第八章-Google Protobuf 编解码-1
Google的Protobuf在业界非常流行,很多商业项目选择Protobuf作为编解码框架,这里一起回顾一下Protobuf 的优点.(1)在谷歌内部长期使用,产品成熟度高:(2)跨语言,支持 ...
- javaWeb学习总结(7)-关于session的实现:cookie与url重写
本文讨论的语境是java EE servlet.我们都知道session的实现主要两种方式:cookie与url重写,而cookie是首选(默认)的方式,因为各种现代浏览器都默认开通cookie功能, ...
- Gradle 使用Maven本地缓存
如果想使用Maven本地缓存,需要定义:build.gradle 文件下定义 build.gradle repositories { mavenLocal() } Gradle使用与Maven相同的策 ...
- php 二级级联菜单
找了很多个级联的菜单,都不好用,自己弄个简单点的,共享下,希望有朋友用得着 <?php //建立表country,有三个字段Id,parentId,area. $pro = $_POST['pr ...