Centos7完全分布式搭建Hadoop2.7.3
(一)软件准备
1,hadoop-2.7.3.tar.gz(包)
2,三台机器装有cetos7的机子
(二)安装步骤
1,给每台机子配相同的用户
进入root : su root
创建用户s: useradd s
修改用户密码:passwd s
2.关闭防火墙及修改每台机的hosts(root 下)
vim /etc/hosts 如:(三台机子都一样)

vim /etc/hostsname:如修改后参看各自的hostname



关闭防火墙:
systemctl stop firewalld.service
禁用防火墙:systemctl disable firewalld.service
查看防火墙状态firewall-cmd --state
重启 reboot
3,为每台机的用户s配置ssh,以用户s身份登录 (一定要相同的用户,因为ssh通信默认使用相同用户身份访问另一台机子)
1,root 用户下修改: vim /etc/ssh/sshd_config,设置这三项后,执行service sshd restart

2,退出root,在用户s下操作
生成密钥对: ssh-keygen -t dsa(一路回车即可)
转入ssh目录下:cd .ssh
导入公钥: cat id_dsa.pub >> authorized_keys
修改authorized_keys权限:chmod 644
authorized_keys (修改权限,保证自己免密码能登入)
验证 ssh Master (在三台机都执行相同的操作)
3,实现master-slave免密码登录
在master 上执行: cat ~/.ssh/id_dsa.pub | ssh s@Slave1 'cat - >> ~/.ssh/authorized_keys'
cat ~/.ssh/id_dsa.pub | ssh s@Slave2 'cat - >> ~/.ssh/authorized_keys '
验证 :ssh Slave1
(三 )配置Hadoop集群
1,解压hadoop和建立文件
root用户下:tar zxvf /home/hadoop/hadoop-2.7.3.tar.gz -C /usr/
重命名:mv hadoop-2.7.3 hadoop
授权给s: chown -R s /usr/hadoop
2,创建hdfs相关文件(三台机子都需要操作)
创建存储hadoop数据文件的目录: mkdir /home/hadoopdir
存储临时文件,如pid:mkdir /home/hadoopdir/tmp
创建dfs系统使用的dfs系统名称hdfs-site.xml使用:mkdir /home/hadoopdir/dfs/name
创建dfs系统使用的数据文件hdfs-site.xml文件使用:mkdir /home/hadoopdir/dfs/data
授权给s: chown -R s /home/hadoopdir
3,配置环境变量(三台机子都需要操作)
root用户下:vim /etc/profile 添加如图: 保存退出后:source /etc/profile
验证:hadoop version(这里要修改 /usr/hadoop/etc/hadoop/hadoop-env.sh,即export JAVA_HOME=/usr/lib/jvm/jre)

4,配置hadoop文件内容
4.1 修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoopdir/tmp/</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
4.2 修改hdfs-site.xml文件
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoopdir/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoopdir/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
4.3 修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>Master:50030</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>Master:9001</value>
</property>
</configuration>
4.4 修改 yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>Master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Master:8088</value>
</property>
</configuration>
4.5,修改 slaves文件

5,搭建集群(普通用户s)
格式hadoop文件:hadoop namenode -format (最后出现“util.ExitUtil: Exiting with status 0”,表示成功)
发送dfs内容给Slave1:scp -r /home/hadoopdir/dfs/* Slave1:/home/hadoopdir/dfs
发给dfs内容给Slave2:scp -r /home/hadoopdir/dfs/* Slave2:/home/hadoopdir/dfs
发送hadoop文件给数据节点:scp -r /usr/hadoop/* Slave1:/usr/hadoop/ scp -r /usr/hadoop/* Slave2:/usr/hadoop/
6,启动集群
./sbin/start-all.sh
1,jps(centos 7 默认没有,可以参照这里安装)查看:Master和Slave中分别出现如下所示:


2,离开安全模式(master): hadoop dfsadmin safemode leave
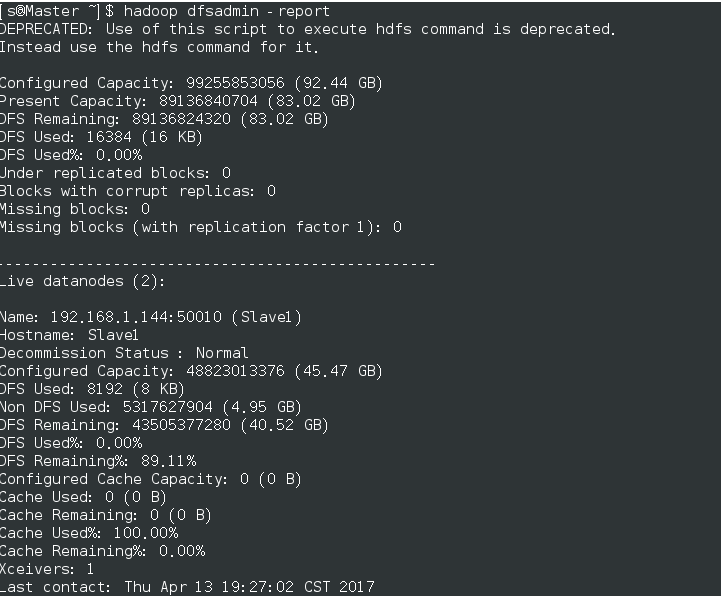
查看结果:hadoop dfsadmin -report,如图
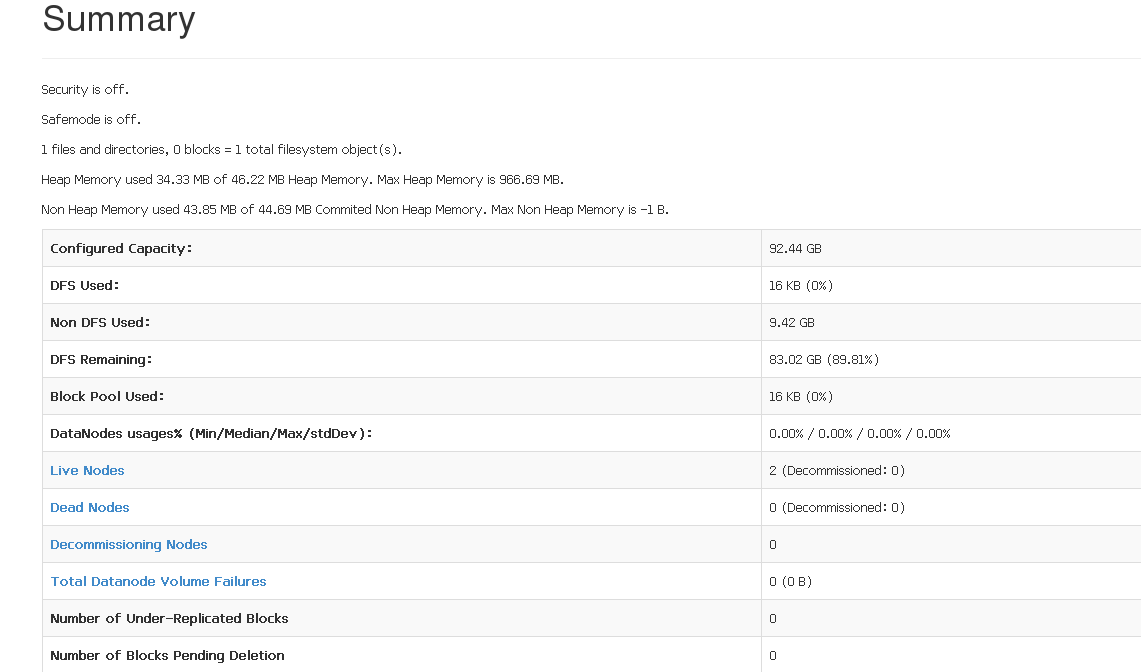
3,登录网页查看:http://Master:50070 (查看live node) 查看yarn环境(http://Master/8088)
(四) 参考网页:
3,SSH集群搭建
Centos7完全分布式搭建Hadoop2.7.3的更多相关文章
- hbase2.1.9 centos7 完全分布式 搭建随记
hbase2.1.9 centos7 完全分布式 搭建随记 这里是当初在三个ECS节点上搭建hadoop+zookeeper+hbase+solr的主要步骤,文章内容未经过润色,请参考的同学搭配其他博 ...
- zookeeper3.5.5 centos7 完全分布式 搭建随记
zookeeper3.5.5 centos7 完全分布式 搭建随记 这里是当初在三个ECS节点上搭建hadoop+zookeeper+hbase+solr的主要步骤,文章内容未经过润色,请参考的同学搭 ...
- 大数据环境完全分布式搭建 hadoop2.4.1
(如果想要安装视频及相关软件可以博私聊我 qq 731487514) hadoop2.0已经发布了稳定版本了,增加了很多特性,比如HDFS HA.YARN等.最新的hadoop-2.4.1又增加了YA ...
- centos7搭建hadoop2.10完全分布式
本篇介绍在centos7中大家hadoop2.10完全分布式,首先准备4台机器:1台nn(namenode);3台dn(datanode) IP hostname 进程 192.168.30.141 ...
- hadoop2.8 集群 1 (伪分布式搭建)
简介: 关于完整分布式请参考: hadoop2.8 ha 集群搭建 [七台机器的集群] Hadoop:(hadoop2.8) Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户 ...
- Hadoop2.7.7 centos7 完全分布式 配置与问题随记
Hadoop2.7.7 centos7 完全分布式 配置与问题随记 这里是当初在三个ECS节点上搭建hadoop+zookeeper+hbase+solr的主要步骤,文章内容未经过润色,请参考的同学搭 ...
- Docker中自动化搭建Hadoop2.6完全分布式集群
这一节将在<Dockerfile完成Hadoop2.6的伪分布式搭建>的基础上搭建一个完全分布式的Hadoop集群. 1. 搭建集群中需要用到的文件 [root@centos-docker ...
- Dockerfile完成Hadoop2.6的伪分布式搭建
在 <Docker中搭建Hadoop-2.6单机伪分布式集群>中在容器中操作来搭建伪分布式的Hadoop集群,这一节中将主要通过Dokcerfile 来完成这项工作. 1 获取一个简单的D ...
- 32位Ubuntu12.04搭建Hadoop2.5.1完全分布式环境
准备工作 1.准备安装环境: 4台PC,均安装32位Ubuntu12.04操作系统,统一用户名和密码 交换机1台 网线5根,4根分别用于PC与交换机相连,1根网线连接交换机和实验室网口 2.使用ifc ...
随机推荐
- Junit使用教程
Junit是Java的单元测试工具,同时也是极限编程的好帮手.Junit4借助于Java5的Annotation(标注类)和静态导入的新特性,与Junit3有很大的区别,所以建议初学者直接使用Juni ...
- Oracle 字符集设置
因为装Linux系统时选择的是英文版,所以当需要测试中文数据库时会出现乱码,这里记录一下我修改字符集的操作. 一些命令: 1.查看sqlplus客户编码: $ echo $NLS_LANG 2.查看 ...
- 为什么Node.JS会受到青睐?
为什么会是Node.JS? 从技术上讲,Node.JS不是一个非常好的项目,Node.JS只是把一个烂想法实现到了可以接受的程度. 但是人们为什么愿意用Node.JS? 从历史看来,成功的项目从来都不 ...
- JSP中列表展示,隔行变色以及S标签的使用
1.java代码 /** * 列表展示,隔行变色以及S标签的使用 * * @return */ public String list() { List<User> list = new A ...
- 多线程爬坑之路-ThreadLocal源码及原理的深入分析
ThreadLocal<T>类:以空间换时间提供一种多线程更快捷访问变量的方式.这种方式不存在竞争,所以也不存在并发的安全性问题. This class provides thread-l ...
- Archlinux 的U盘自动装载(二)升级到 udisks2
在安装 mysql-gui-tools 过程中,发现需要用到 udisks2.udisks和udisks2可以互相替换也可以共用.最后决定换用 udisks2 安装 先卸载原来的软件,如果有的话. p ...
- Spring-boot中使用@ConditionalOnExpression注解,在特定情况下初始化bean
想要实现的功能: 我想在配置文件中设置一个开关,enabled,在开关为true的时候才实例化bean,进行相关业务逻辑的操作. 具体实现: 1:要实例化的bean 2. 配置类 代码: 想要实例化的 ...
- yii2.0框架where条件的使用
在yii框架中,where条件的使用多种多样,下面就和大家介绍几种常用有效的使用方法 1. ['type' => 1, 'status' => 2] //等于 (type = 1) AND ...
- TCP的连接和建立 图解
前言 在没有理解TCP连接是如何建立和终止之前,我想你可能并不会使用connect,accept,close这三个函数并且使用netstat程序来调试应用.所以掌握TCP连接的建立和终止势在必行. 三 ...
- java对String进行sha1加密
1.使用apache的codec jar包对string进行加密,先下载并引入jar包: http://commons.apache.org/proper/commons-codec/ 2.生成: S ...